Create Spark cluster in HDInsight on AKS (Preview)
Important
Azure HDInsight on AKS retired on January 31, 2025. Learn more with this announcement.
You need to migrate your workloads to Microsoft Fabric or an equivalent Azure product to avoid abrupt termination of your workloads.
Important
This feature is currently in preview. The Supplemental Terms of Use for Microsoft Azure Previews include more legal terms that apply to Azure features that are in beta, in preview, or otherwise not yet released into general availability. For information about this specific preview, see Azure HDInsight on AKS preview information. For questions or feature suggestions, please submit a request on AskHDInsight with the details and follow us for more updates on Azure HDInsight Community.
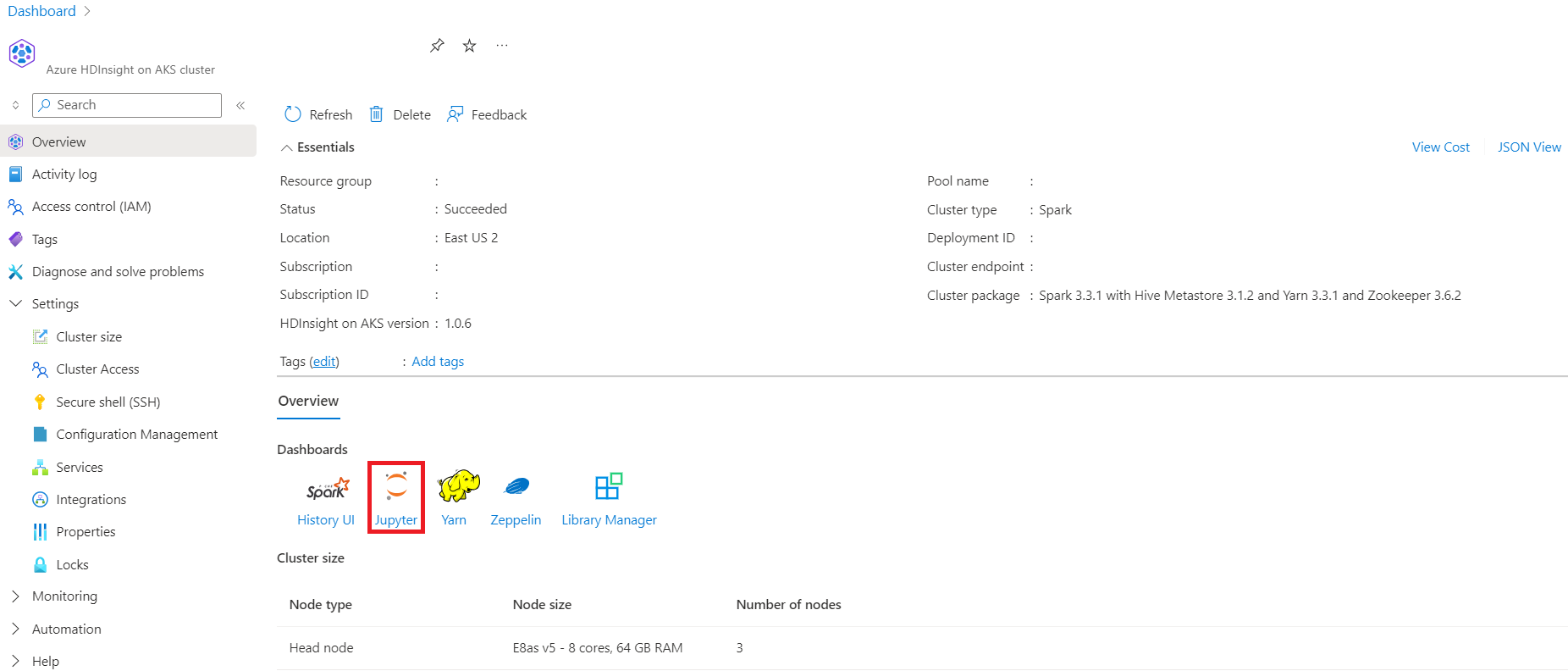
Once the subscription prerequisites and resource prerequisites steps are complete, and you have a cluster pool deployed, continue to use the Azure portal to create a Spark cluster. You can use the Azure portal to create an Apache Spark cluster in cluster pool. You can then create a Jupyter Notebook and use it to run Spark SQL queries against Apache Hive tables.
In the Azure portal, type cluster pools, and select cluster pools to go to the cluster pools page. On the cluster pools page, select the cluster pool in which you can add a new Spark cluster.
On the specific cluster pool page, click + New cluster.
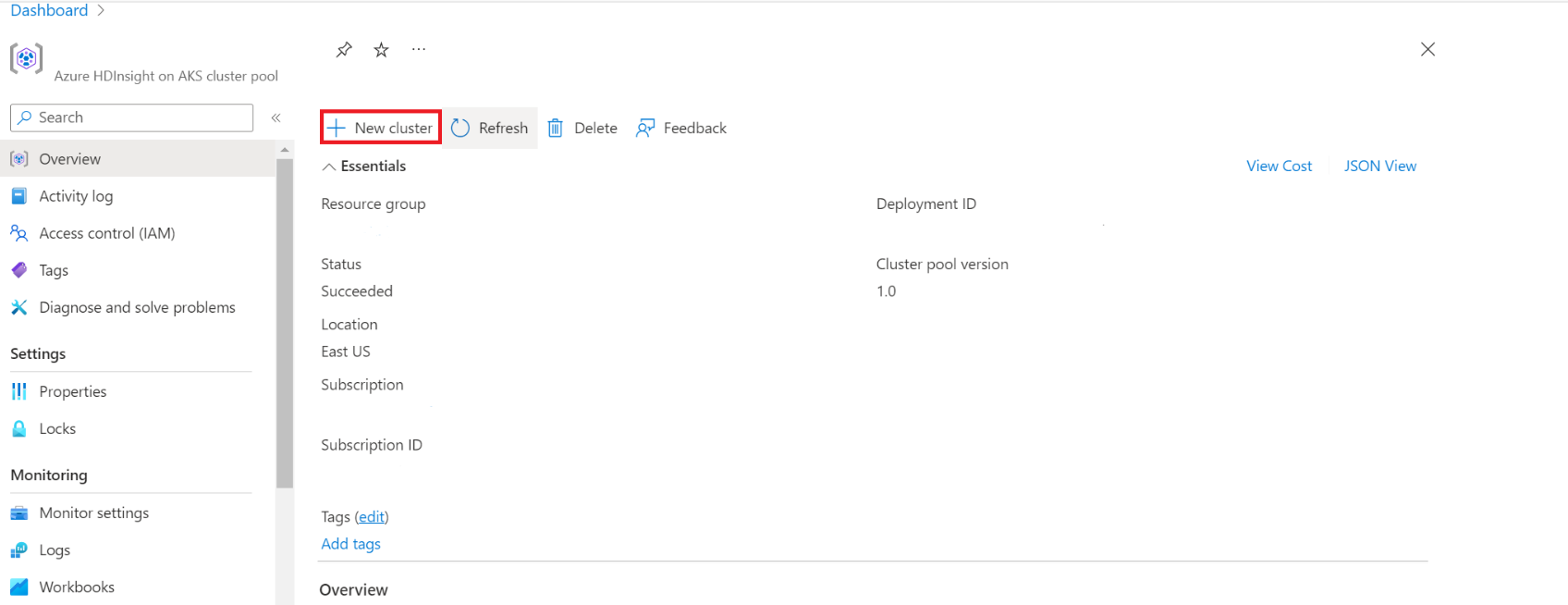
This step opens the cluster create page.
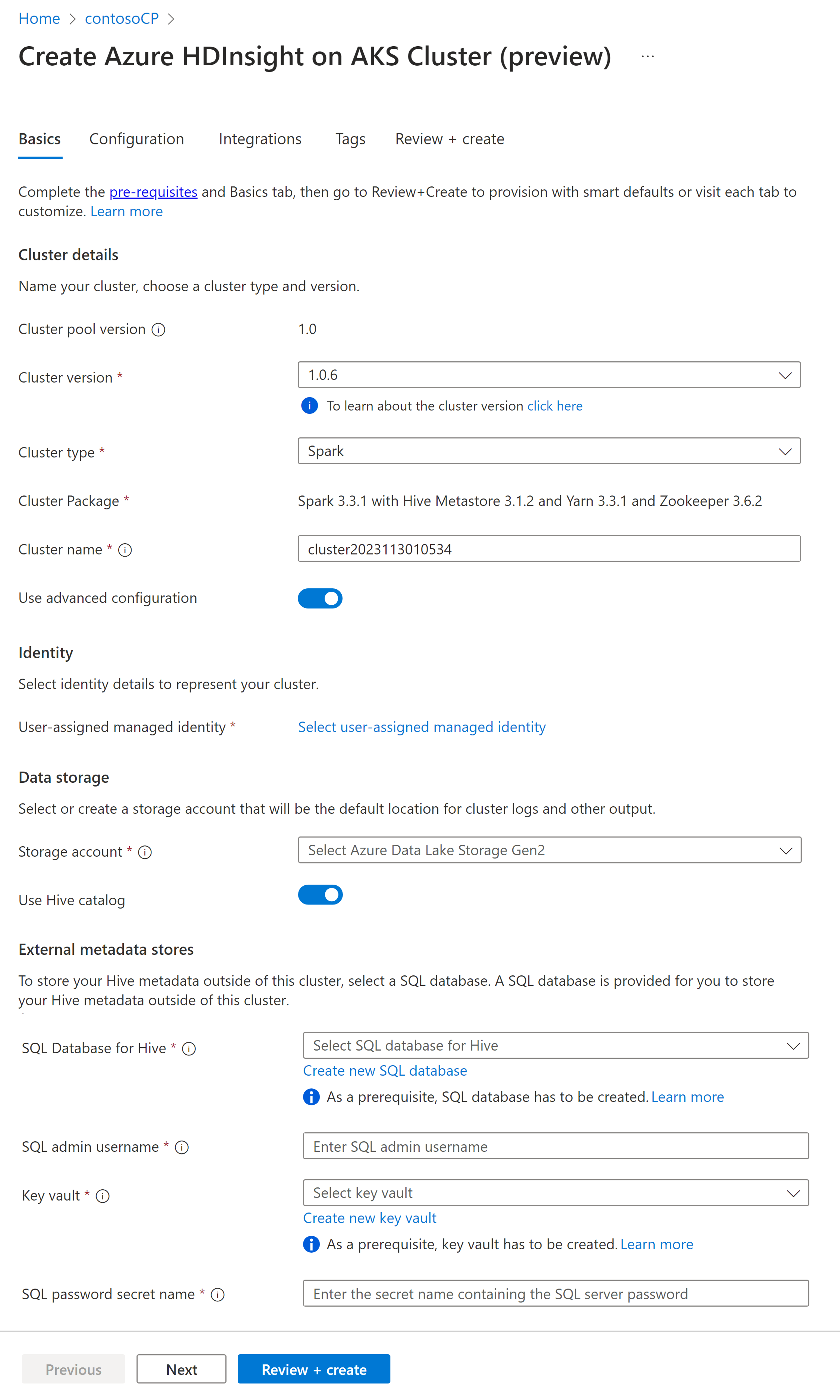
Property Description Subscription The Azure subscription that was registered for use with HDInsight on AKS in the Prerequisites section with be prepopulated Resource Group The same resource group as the cluster pool will be pre populated Region The same region as the cluster pool and virtual will be pre populated Cluster pool The name of the cluster pool will be pre populated HDInsight Pool version The cluster pool version will be pre populated from the pool creation selection HDInsight on AKS version Specify the HDI on AKS version Cluster type From the drop-down list, select Spark Cluster Version Select the version of the image version to use Cluster name Enter the name of the new cluster User-assigned managed identity Select the user assigned managed identity which will work as a connection string with the storage Storage Account Select the pre created storage account which is to be used as primary storage for the cluster Container name Select the container name(unique) if pre created or create a new container Hive Catalog (optional) Select the pre created Hive metastore(Azure SQL DB) SQL Database for Hive From the drop-down list, select the SQL Database in which to add hive-metastore tables. SQL admin username Enter the SQL admin username Key vault From the drop-down list, select the Key Vault, which contains a secret with password for SQL admin username SQL password secret name Enter the secret name from the Key Vault where the SQL DB password is stored Note
- Currently HDInsight support only MS SQL Server databases.
- Due to Hive limitation, "-" (hyphen) character in metastore database name is not supported.
Select Next: Configuration + pricing to continue.
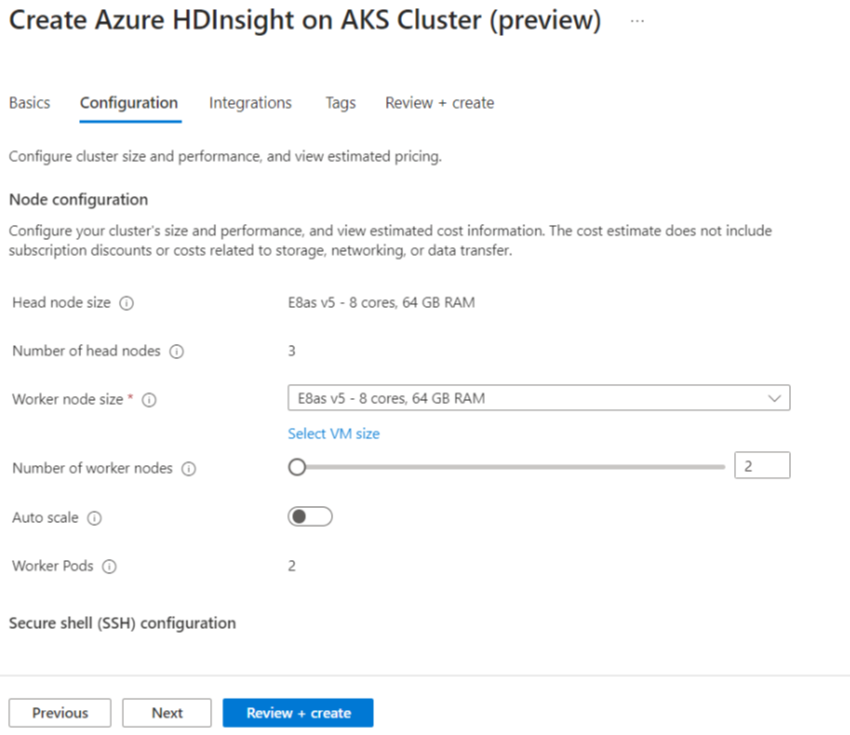
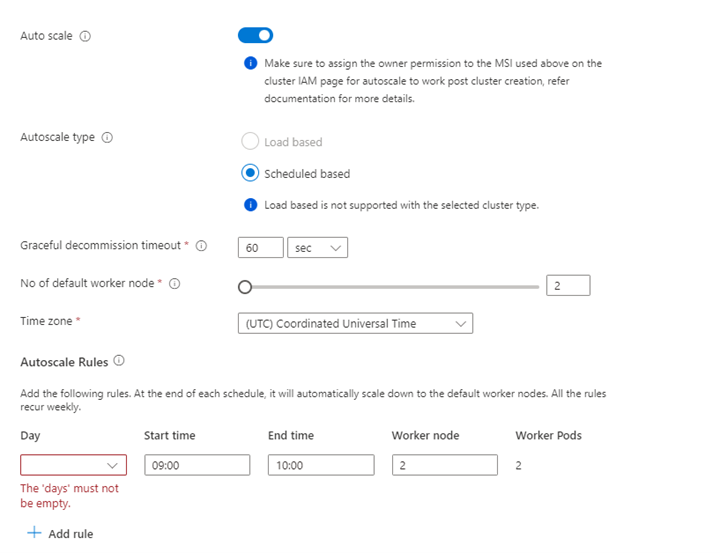
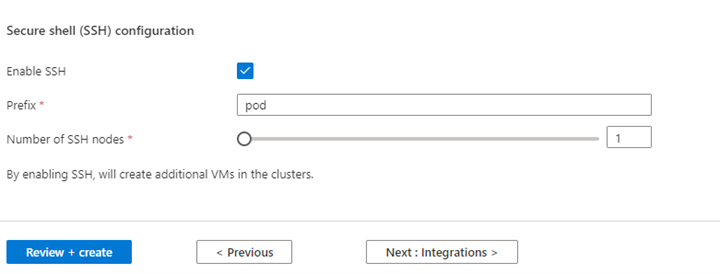
Property Description Node size Select the node size to use for the Spark nodes Number of worker nodes Select the number of nodes for Spark cluster. Out of those, three nodes are reserved for coordinator and system services, remaining nodes are dedicated to Spark workers, one worker per node. For example, in a five-node cluster there are two workers Autoscale Click on the toggle button to enable Autoscale Autoscale Type Select from either load based or schedule based autoscale Graceful decommission timeout Specify Graceful decommission timeout No of default worker node Select the number of nodes for autoscale Time Zone Select the time zone Autoscale Rules Select the day, start time, end time, no. of worker nodes Enable SSH If enabled, allows you to define Prefix and Number of SSH nodes Click Next : Integrations to enable and select Log Analytics for Logging.
Azure Prometheus for monitoring and metrics can be enabled post cluster creation.
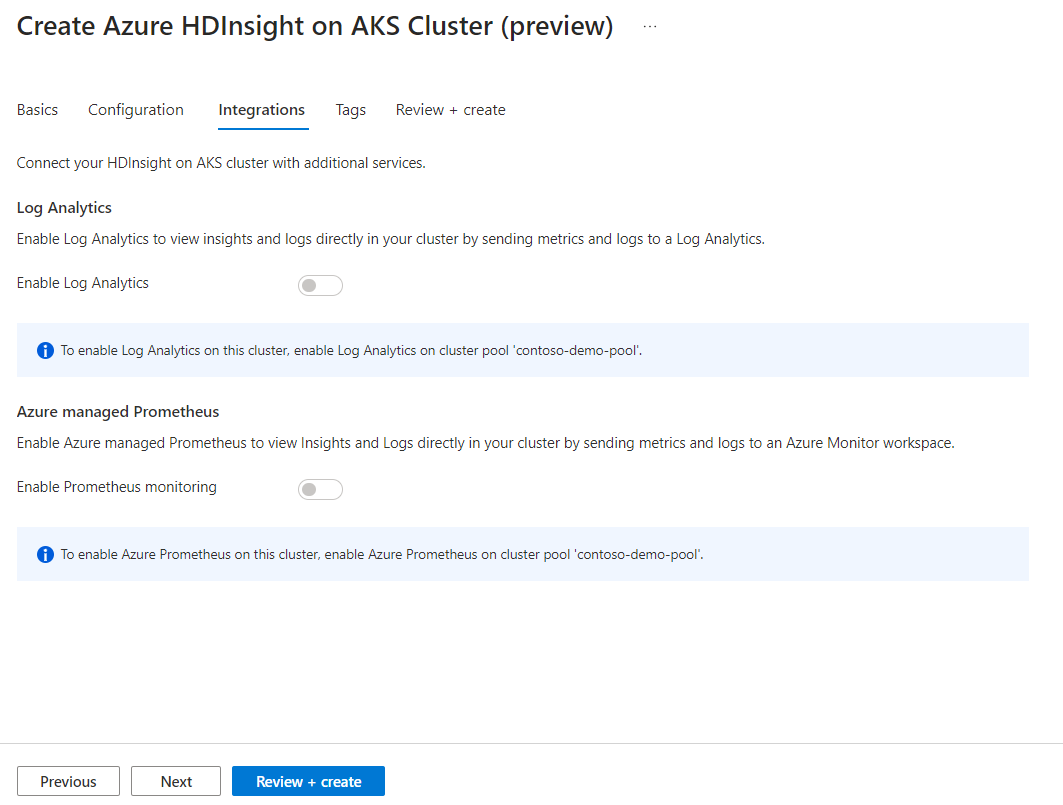
Click Next: Tags to continue to the next page.

On the Tags page, enter any tags you wish to add to your resource.
Property Description Name Optional. Enter a name such as HDInsight on AKS Private Preview to easily identify all resources associated with your resources Value Leave this blank Resource Select All resources selected Click Next: Review + create.
On the Review + create page, look for the Validation succeeded message at the top of the page and then click Create.
The Deployment is in process page is displayed which the cluster is created. It takes 5-10 minutes to create the cluster. Once the cluster is created, Your deployment is complete message is displayed. If you navigate away from the page, you can check your Notifications for the status.
Go to the cluster overview page, you can see endpoint links there.