Apache Flink® Configuration management in HDInsight on AKS
Note
We will retire Azure HDInsight on AKS on January 31, 2025. Before January 31, 2025, you will need to migrate your workloads to Microsoft Fabric or an equivalent Azure product to avoid abrupt termination of your workloads. The remaining clusters on your subscription will be stopped and removed from the host.
Only basic support will be available until the retirement date.
Important
This feature is currently in preview. The Supplemental Terms of Use for Microsoft Azure Previews include more legal terms that apply to Azure features that are in beta, in preview, or otherwise not yet released into general availability. For information about this specific preview, see Azure HDInsight on AKS preview information. For questions or feature suggestions, please submit a request on AskHDInsight with the details and follow us for more updates on Azure HDInsight Community.
HDInsight on AKS provides a set of default configurations of Apache Flink for most properties and a few based on common application profiles. However, in case you're required to tweak Flink configuration properties to improve performance for certain applications with state usage, parallelism, or memory settings, you can change Flink job configuration using Flink Jobs Section in HDInsight on AKS cluster.
Go To Settings > Flink Jobs > Click on Update.
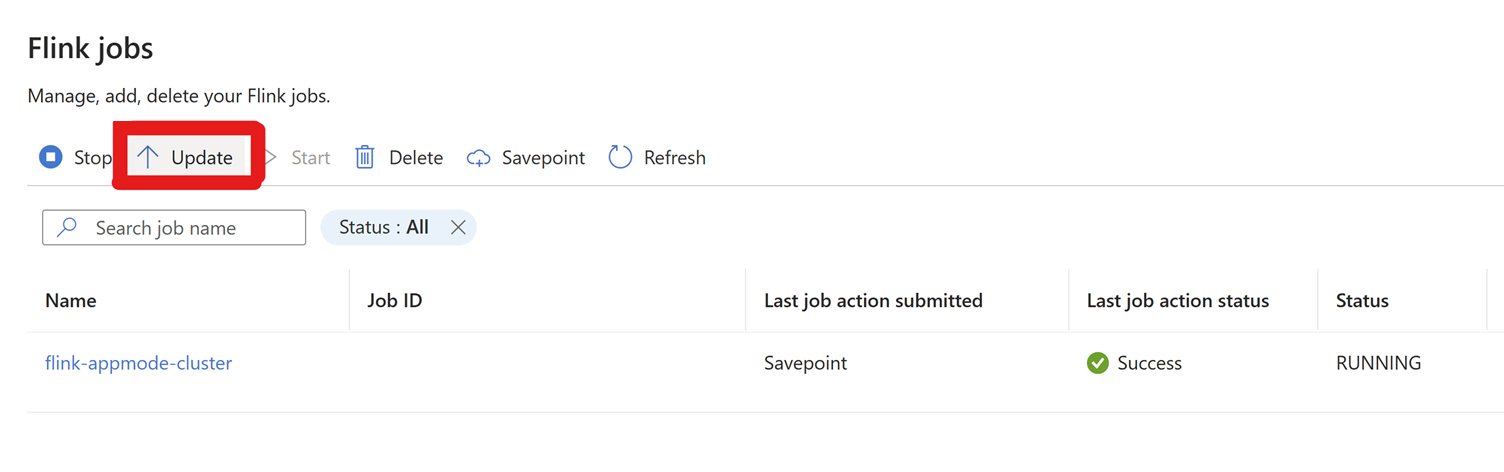
Click on + Add a row to edit configuration.
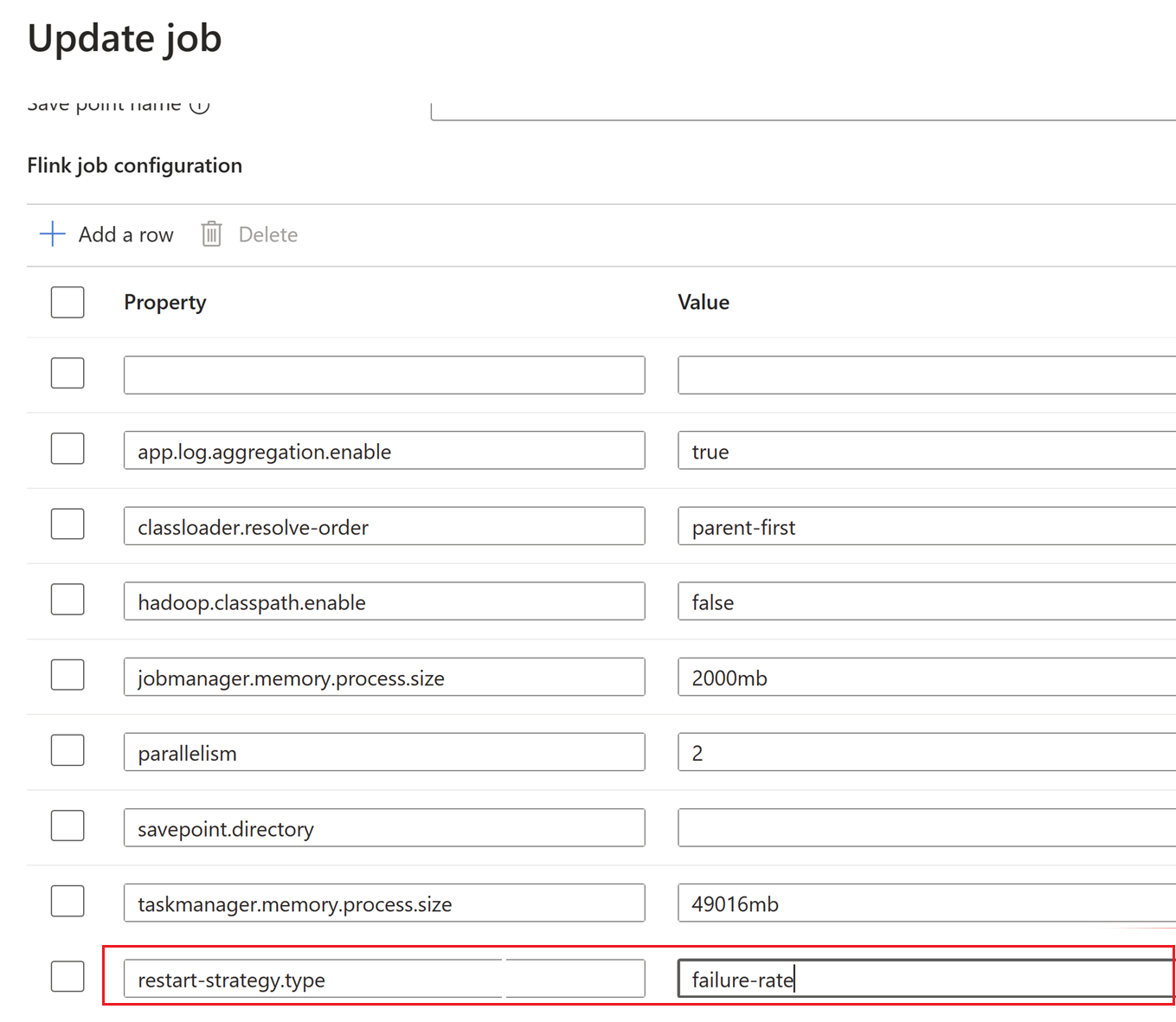
Here the checkpoint interval is changed at Cluster level.
Update the changes by clicking OK and then Save.
Once saved, the new configurations get updated in a few minutes (~5 minutes).
Configurations, which can be updated using Configuration Management Settings.
processMemory size:The default settings for the process memory size of or job manager and task manager would be the memory configured by the user during cluster creation.
This size can be configured by using the below configuration property. In-order to change task manager process memory, use this configuration.
taskmanager.memory.process.size : <value>Example:
taskmanager.memory.process.size : 2000mbFor job manager
jobmanager.memory.process.size : <value>Note
The maximum configurable process memory is equal to the memory configured for
jobmanager/taskmanager.


Checkpoint Interval
The checkpoint interval determines how often Flink triggers a checkpoint. Defined in milliseconds and can be set using the following configuration property
execution.checkpoint.interval: <value>
Default setting is 60,000 milliseconds (1 min), this value can be changed as desired.
State Backend
The state backend determines how Flink manages and persists the state of your application. It impacts how checkpoints stored. You can configure the `state backend using the following property:
state.backend: <value>
By default Apache Flink clusters in HDInsight on AKS use Rocks DB.
Checkpoint Storage Path
We allow persistent checkpoints by default by storing the checkpoints in abfs storage as configured by the user. Even if the job fails, since the checkpoints are persisted, it can be easily started with the latest checkpoint.
state.checkpoints.dir: <path>
Replace <path> with the desired path where the checkpoints stored.
By default, stored in the storage account (ABFS), configured by the user. This value can be changed to any path desired as long as the Flink pods can access it.
Maximum Concurrent Checkpoints
You can limit the maximum number of concurrent checkpoints by setting the following property:
checkpoint.max-concurrent-checkpoints: <value>
Replace <value> with the desired maximum number of concurrent checkpoints. For example, 1 to allow only one checkpoint at a time.
Maximum retained checkpoints
You can limit the maximum number of checkpoints to be retained by setting the following property:
state.checkpoints.num-retained: <value>
Replace <value> with desired maximum number. By default we retain maximum five checkpoints.
Savepoint Storage path
We allow persistent savepoints by default by storing the savepoints in abfs storage (as configured by the user). If the user wants to stop and later start the job with a particular savepoint, they can configure this location.
state.checkpoints.dir: <path>
Replace <path> with the desired path where the savepoints stored.
By default, stored in the storage account, configured by the user. (We support ABFS). This value can be changed to any path desired as long as the Flink pods can access it.
Job manager high availability
In HDInsight on AKS, Flink uses Kubernetes as backend. Even if the Job Manager fails in between due to any known/unknown issue, the pod is restarted within a few seconds. Hence, even if the job restarts due to this issue, the job is recovered back from the latest checkpoint.
FAQ
Why does the Job failure in between? Even if the jobs fail abruptly, if the checkpoints are happening continuously, then the job is restarted by default from the latest checkpoint.
Change the job strategy in between? There are use cases, where the job needs to be modified while in production due to some job level bug. During that time, the user can stop the job, which would automatically take a savepoint and save it in savepoint location.
Click on
savepointand wait forsavepointto be completed.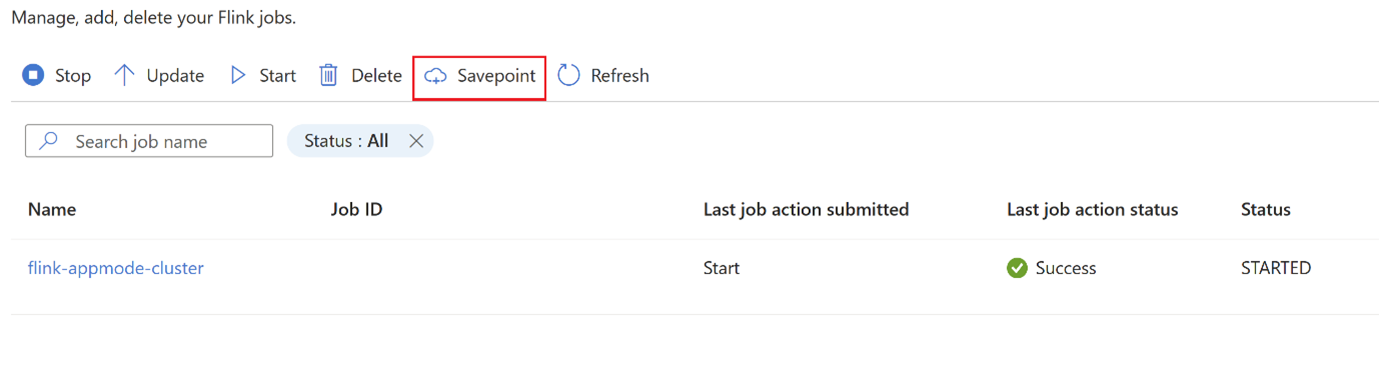
After savepoint completion, click on start and Start Job Tab will appear. Select the savepoint name from the dropdown. Edit any configurations if necessary. And click OK.
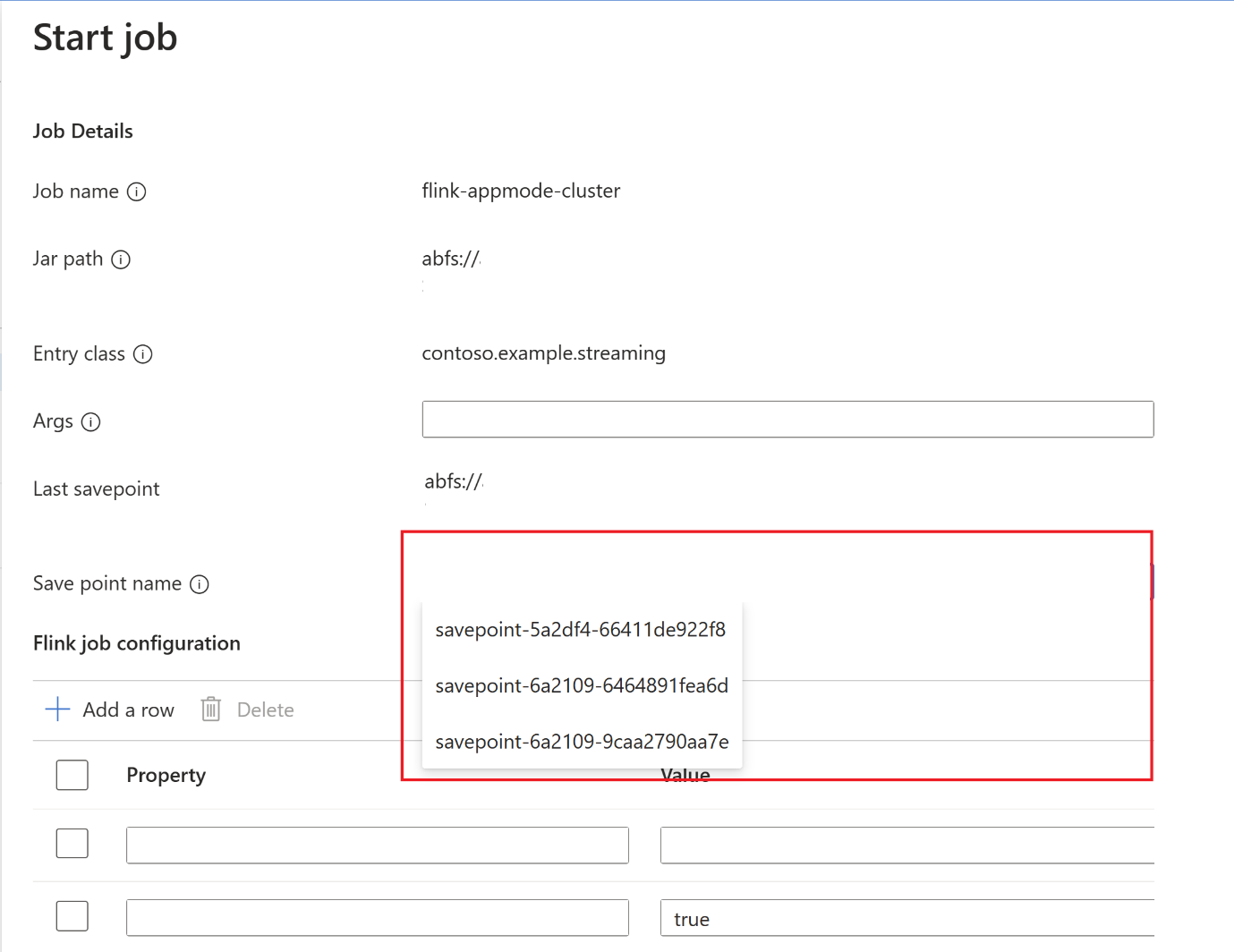


Since savepoint is provided in the job, the Flink knows from where to start processing the data.
Reference
- Apache Flink Configurations
- Apache, Apache Kafka, Kafka, Apache Flink, Flink, and associated open source project names are trademarks of the Apache Software Foundation (ASF).