Apache Flink Application Mode cluster on HDInsight on AKS
Important
Azure HDInsight on AKS retired on January 31, 2025. Learn more with this announcement.
You need to migrate your workloads to Microsoft Fabric or an equivalent Azure product to avoid abrupt termination of your workloads.
Important
This feature is currently in preview. The Supplemental Terms of Use for Microsoft Azure Previews include more legal terms that apply to Azure features that are in beta, in preview, or otherwise not yet released into general availability. For information about this specific preview, see Azure HDInsight on AKS preview information. For questions or feature suggestions, please submit a request on AskHDInsight with the details and follow us for more updates on Azure HDInsight Community.
HDInsight on AKS now offers a Flink Application mode cluster. This cluster lets you manage cluster Flink application mode lifecycle using the Azure portal with easy-to-use interface and Azure Resource Management Rest APIs. Application mode clusters are designed to support large and long-running jobs with dedicated resources, and handle resource-intensive or extensive data processing tasks.
This deployment mode enables you to assign dedicated resources for specific Flink applications, ensuring that they have enough computing power and memory to handle large workloads efficiently.

Advantages
Simplified cluster deployment with Job jar.
User friendly REST API: HDInsight on AKS provides user friendly ARM Rest APIs to manage app mode job operation like Update, Savepoint, Cancel, Delete.
Easy to manage Job Updates and State Management: The native Azure portal integration provides a hassle-free experience for updating jobs and restoring them to their last saved state (savepoint). This functionality ensures continuity and data integrity throughout the job lifecycle.
Automate Flink Job(s) using Azure Pipelines or other CI/CD tools: Using HDInsight on AKS, Flink users have access to user-friendly ARM Rest API, you can seamlessly integrate Flink job operations into your Azure Pipeline or other CI/CD tools.
Key features
Stop and Start Jobs with Savepoints: Users can gracefully stop and start their Flink AppMode jobs from their previous state (Savepoint). Savepoints ensure that job progress is preserved, enabling seamless resumptions.
Job Updates: User can update the running AppMode job after updating the jar on storage account. This update automatically takes the savepoint and starts the AppMode job with a new jar.
Stateless Updates: Performing a fresh restart for a AppMode job is simplified through stateless updates. This feature allows users to initiate a clean restart using updated job jar.
Savepoint Management: At any given moment, users can create savepoints for their running jobs. These savepoints can be listed and used to restart the job from a specific checkpoint as needed.
Cancel: Cancels the job permanently.
Delete: Delete AppMode cluster.
How to create Flink Application cluster
Prerequisites
Complete the prerequisites in the following sections:
Add job jar in Storage Account.
Before setting up a Flink App Mode Cluster, several preparatory steps required. One of these steps involves placing the App Mode job JAR in the cluster's storage account.
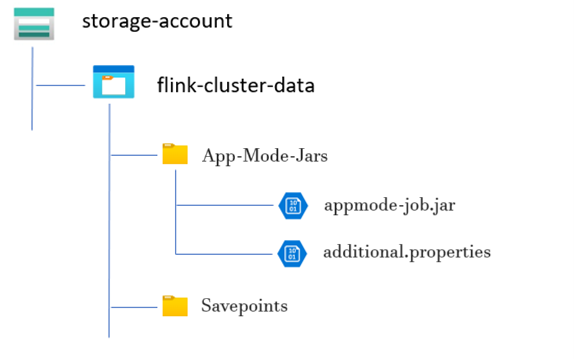
Create a Directory for App Mode Job JAR:
Inside the dedicated containers, create a directory where you upload the App Mode job JAR file. This directory serves as the location for storing JAR files that you want to include in the classpath of the Flink cluster or job.
Savepoints Directory (Optional):
If users intend to take savepoints during job execution, create a separate directory within the storage account for storing these savepoints. This directory used to store checkpoint data and metadata for savepoints.
Example directory structure:

Create Flink App Mode Cluster
Flink AppMode clusters can be created once cluster pool deployment completed, let us go over the steps in case you're getting started with an existing cluster pool.
In the Azure portal, type HDInsight cluster pools/HDInsight/HDInsight on AKS and select Azure HDInsight on AKS cluster pools to go to the cluster pools page. On the HDInsight on AKS cluster pools page, select the cluster pool in which you want to create a new Flink cluster.

On the specific cluster pool page, click + New cluster and provide the following information:
Property Description Subscription This field autopopulated with the Azure subscription that was registered for the Cluster Pool. Resource Group This field autopopulates and shows the resource group on the cluster pool. Region This field autopopulates and shows the region selected on the cluster pool. Cluster Pool This field autopopulates and shows the cluster pool name on which the cluster is now getting created. To create a cluster in a different pool, find the cluster pool in the portal and click + New cluster. HDInsight on AKS Pool Version This field autopopulates and shows the cluster pool version on which the cluster is now getting created. HDInsight on AKS Version Select the minor or patch version of the HDInsight on AKS of the new cluster. Cluster type From the drop-down list, select Flink. Cluster name Enter the name of the new cluster. User-assigned managed identity From the drop-down list, select the managed identity to use with the cluster. If you're the owner of the Managed Service Identity (MSI), and the MSI doesn't have Managed Identity Operator role on the cluster, click the link below the box to assign the permission needed from the AKS agent pool MSI. If the MSI already has the correct permissions, no link is shown. See the Prerequisites for other role assignments required for the MSI. Storage account From the drop-down list, select the storage account to associate with the Flink cluster and specify the container name. The managed identity is further granted access to the specified storage account, using the 'Storage Blob Data Owner' role during cluster creation. Virtual network The virtual network for the cluster. Subnet The virtual subnet for the cluster. Enabling Hive catalog for Flink SQL:
Property Description Use Hive catalog Enable this option to use an external Hive metastore. SQL Database for Hive From the drop-down list, select the SQL Database in which to add hive-metastore tables. SQL admin username Enter the SQL server admin username. This account is used by metastore to communicate to SQL database. Key vault From the drop-down list, select the Key Vault, which contains a secret with password for SQL server admin username. You need to set up an access policy with all required permissions such as key permissions, secret permissions, and certificate permissions to the MSI, which is being used for the cluster creation. The MSI needs a Key Vault Administrator role. Add the required permissions using IAM. SQL password secret name Enter the secret name from the Key Vault where the SQL database password is stored. 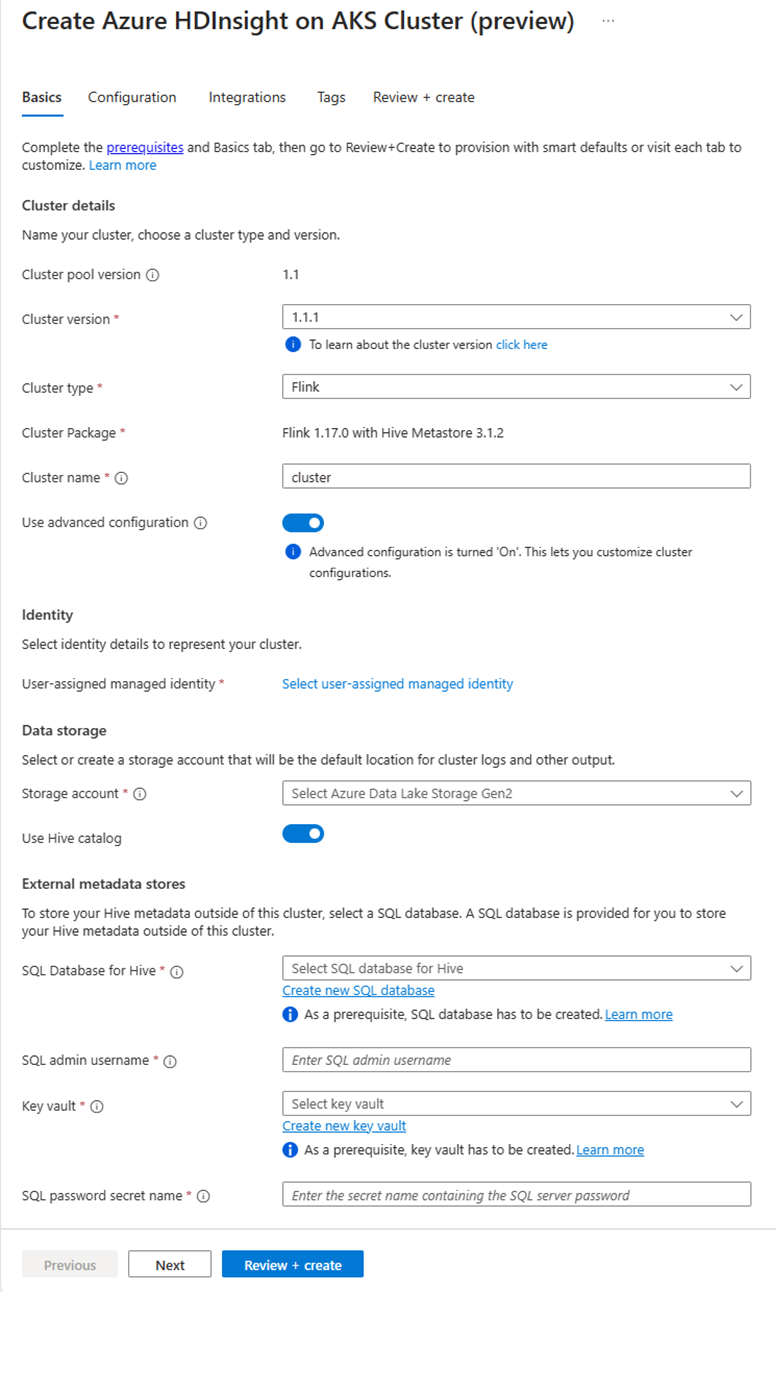
Note
By default we use the Storage account for Hive catalog same as the storage account and container used during cluster creation.
Select Next: Configuration to continue.
On the Configuration page, provide the following information:
Property Description Node size Select the node size to use for the Flink nodes both head and worker nodes. Number of nodes Select the number of nodes for Flink cluster; by default head nodes are two. The worker nodes sizing helps determine the task manager configurations for the Flink. The job manager and history servers are on head nodes. On the Deployment section, choose deployment type as Application Mode provide the following information:
Property Description Jar Path Give the ABFS (Storage) path for your job jar. For example, abfs://flink@teststorage.dfs.core.windows.net/appmode/job.jarEntry class (Optional) Main class for your application mode cluster. Ex: com.microsoft.testjob Args (Optional) Argument for your job main class. Save point name Name of old savepoint, which you want to use for launching job Upgrade mode Select default Upgrade option. This option used when major version upgrade is happening for cluster. There are three options available. UPDATE: Used when a user wants to recover from the last savepoint after upgrade. STATELESS_UPDATE: Used when a user wants fresh restart for job after upgrade. LAST_STATE_UPDATE: Used when a user wants to recover job from last checkpoint after upgrade Flink job configuration Add add more configuration required for Flink job. Select 'Job log aggregation.' Check box if you want to upload your job log to remote storage. It helps debugging the job issues. Default location for job log is 'StorageAccount/Container/DeploymentId/logs.' You can change the default log directory by configuring “pipeline.remote.log.dir.” Default interval for log collection is 600 sec. User can change by configuring “pipeline.log.aggregation.interval”.
On the Service Configuration section, provide the following information:
Property Description Task manager CPU Integer. Enter the size of the Task manager CPUs (in cores). Task manager memory in MB Enter the Task manager memory size in MB. Min of 1,800 MB. Job manager CPU Integer. Enter the number of CPUs for the Job manager (in cores). Job manager memory in MB Enter the memory size in MB. Minimum of 1,800 MB. History server CPU Integer. Enter the number of CPUs for the Job manager (in cores). History server memory in MB Enter the memory size in MB. Minimum of 1,800 MB. 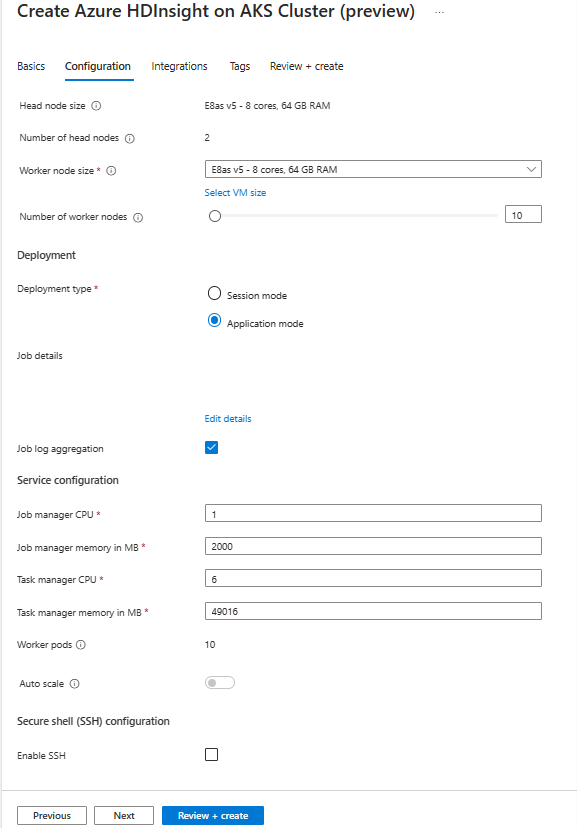
Click Next: Integration button to continue to the next page.
On the Integration page, provide the following information:
Property Description Log analytics This feature is available only if the cluster pool associated log analytics workspace, once enabled the logs to collect can be selected. Azure Prometheus This feature is to view Insights and Logs directly in your cluster by sending metrics and logs to Azure Monitor workspace. 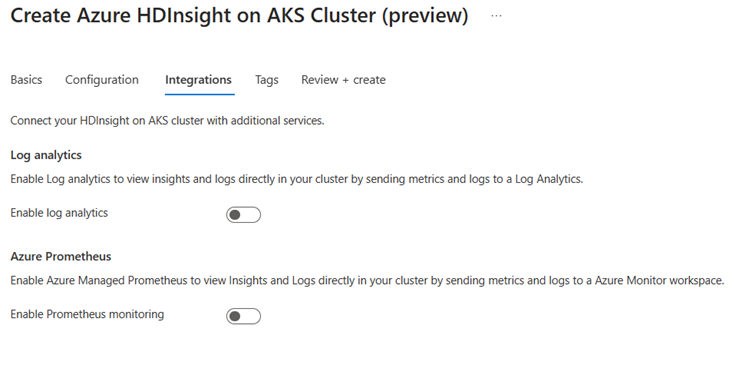
Click the Next: Tags button to continue to the next page.
On the Tags page, provide the following information:
Property Description Name Optional. Enter a name such as HDInsight on AKS to easily identify all resources associated with your cluster resources. Value You can leave this blank. Resource Select All resources selected. Select Next: Review + create to continue.
On the Review + create page, look for the Validation succeeded message at the top of the page and then click Create.




The Deployment in process page displayed which the cluster is created. It takes 5-10 minutes to create the cluster. Once the cluster is created, the "Your deployment is complete" message is displayed. If you navigate away from the page, you can check your Notifications for the current status.
Manage Application Job in from Portal
HDInsight AKS provides ways to manage Flink jobs. You can relaunch a failed job. Restart the job from portal.
To run the Flink job from portal, go to:
Portal > HDInsight on AKS Cluster Pool > Flink Cluster > Settings > Flink Jobs.

Stop: Stop job didn't require any parameters. User can stop the job by selecting the action. Once the job is stopped, the job status on the portal to be STOPPED.
Start: Starts the job from savepoint. To start the job, select the stopped job and start it.
Update: Update helps to restart jobs with updated job code. Users need to update the latest job jar in storage location and update the job from portal. This action stops the job with savepoint and start again with latest jar.
Stateless Update: Stateless is like an update, but it involves a fresh restart of the job with the latest code. Once the job is updated, the job status on the portal a shows as Running.
Savepoint: Take the savepoint for the Flink Job.
Cancel: Terminate the job.
Delete: Delete AppMode cluster.
View Job Details: To view the job detail user can click on job name, it gives the details about the job and last action result.
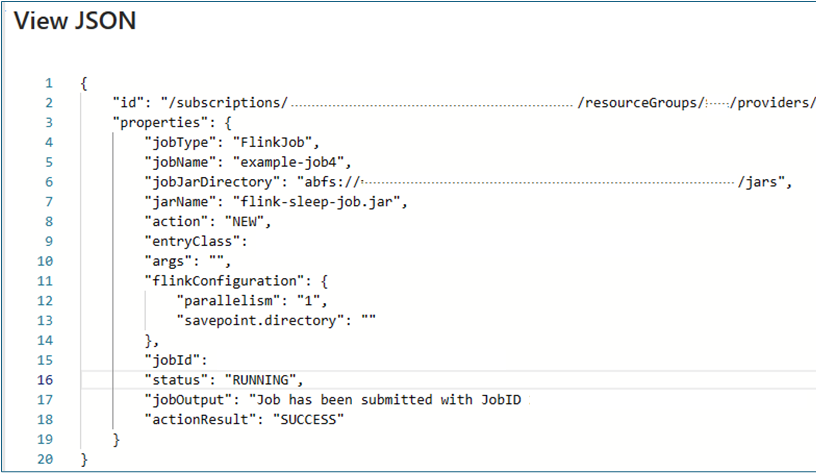

For any failed action, this json view gives detailed exceptions and reasons for the failure.