Quickstart: Get started using GPT-35-Turbo and GPT-4 with Azure OpenAI Service in IntelliJ
This article shows you how to get started with Azure OpenAI Service in IntelliJ IDEA. It shows you how to use chat models such as GPT-3.5-Turbo and GPT-4 to test and experiment with different parameters and data sources.
Prerequisites
A supported Java Development Kit (JDK). For more information about the JDKs available for use when developing on Azure, see Java support on Azure and Azure Stack.
IntelliJ IDEA, Ultimate or Community Edition.
The Azure Toolkit for IntelliJ. For more information, see Install the Azure Toolkit for IntelliJ. You also need to sign in to your Azure account for the Azure Toolkit for IntelliJ. For more information, see Sign-in instructions for the Azure Toolkit for IntelliJ.
An Azure subscription - Create one for free.
Access granted to Azure OpenAI in the desired Azure subscription.
Currently, access to this service is granted only by application. You can apply for access to Azure OpenAI by completing the form at Request Access to Azure OpenAI Service.
An Azure OpenAI Service resource with either the
gpt-35-turboor thegpt-4models deployed. For more information about model deployment, see Create and deploy an Azure OpenAI Service resource.
Install and sign-in
The following steps walk you through the Azure sign-in process in your IntelliJ development environment:
If you don't have the plugin installed, see Azure Toolkit for IntelliJ.
To sign in to your Azure account, navigate to the left-hand Azure Explorer sidebar, and then select the Azure Sign In icon. Alternatively, you can navigate to Tools, expand Azure, and then select Azure Sign in.
In the Azure Sign In window, select OAuth 2.0, and then select Sign in. For other sign-in options, see Sign-in instructions for the Azure Toolkit for IntelliJ.
In the browser, sign in with your account that has access to your OpenAI resource and then go back to IntelliJ. In the Select Subscriptions dialog box, select the subscription that you want to use, then select Select.

Create and deploy an Azure OpenAI Service resource
After the sign-in workflow, right-click the Azure OpenAI item in Azure Explorer and select Create Azure OpenAI Service.
In the Create Azure OpenAI Service dialog box, specify the following information and then select OK:
- Name: A descriptive name for your Azure OpenAI Service resource, such as MyOpenAIResource. This name is also your custom domain name in your endpoint. Your resource name can only include alphanumeric characters and hyphens, and can't start or end with a hyphen.
- Region: The location of your instance. Certain models are only available in specific regions. For more information, see Azure OpenAI Service models.
- Sku: Standard Azure OpenAI resources are billed based on token usage. For more information, see Azure OpenAI Service pricing.
Before you can use chat completions, you need to deploy a model. Right-click your Azure OpenAI instance, and select Create New Deployment. In the pop-up Create Azure OpenAI Deployment dialog box, specify the following information and then select OK:
- Deployment Name: Choose a name carefully. The deployment name is used in your code to call the model by using the client libraries and the REST APIs.
- Model: Select a model. Model availability varies by region. For a list of available models per region, see the Model summary table and region availability section of Azure OpenAI Service models.
The toolkit displays a status message when the deployment is complete and ready for use.
Interact with Azure OpenAI using prompts and settings
Right-click your Azure OpenAI resource and then select Open in AI Playground.
You can start exploring OpenAI capabilities through the Azure OpenAI Studio Chat playground in IntelliJ IDEA.


To trigger the completion, you can input some text as a prompt. The model generates the completion and attempts to match your context or pattern.
To start a chat session, follow these steps:
In the chat session pane, you can start with a simple prompt like this one: "I'm interested in buying a new Surface." After you type the prompt, select Send. You receive a response similar to the following example:
Great! Which Surface model are you interested in? There are several options available such as the Surface Pro, Surface Laptop, Surface Book, Surface Go, and Surface Studio. Each one has its own unique features and specifications, so it's important to choose the one that best fits your needs.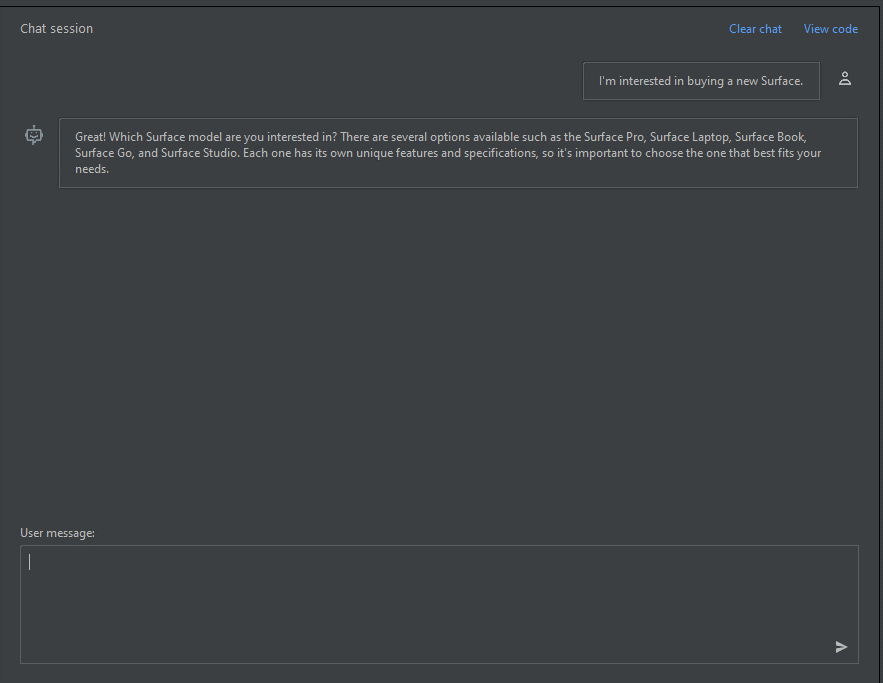
Enter a follow-up question like: "Which models support GPU?" and select Send. You receive a response similar to the following example:
Most Surface models come with an integrated GPU (Graphics Processing Unit), which is sufficient for basic graphics tasks such as video playback and casual gaming. However, if you're looking for more powerful graphics performance, the Surface Book 3 and the Surface Studio 2 come with dedicated GPUs. The Surface Book 3 has an NVIDIA GeForce GTX GPU, while the Surface Studio 2 has an NVIDIA GeForce GTX 1060 or 1070 GPU, depending on the configuration.
Now that you have a basic conversation, select View code from the pane, and you have a replay of the code behind the entire conversation so far. You can see the code samples based on Java SDK, curl, and JSON that correspond to your chat session and settings, as shown in the following screenshot:

You can then select Copy to take this code and write an application to complete the same task you're currently performing with the playground.



Settings
You can select the Configuration tab to set the following parameters:
| Name | Description |
|---|---|
| Max response | Sets a limit on the number of tokens per model response. The API supports a maximum of 4096 tokens shared between the prompt (including system message, examples, message history, and user query) and the model's response. One token is roughly four characters for typical English text. |
| Temperature | Controls randomness. Lowering the temperature means that the model produces more repetitive and deterministic responses. Increasing the temperature results in more unexpected or creative responses. Try adjusting temperature or Top probabilities, but not both. |
| Top probabilities | Similar to temperature, controls randomness but uses a different method. Lowering the Top probabilities value narrows the model's token selection to likelier tokens. Increasing the value lets the model choose from tokens with both high and low likelihood. Try adjusting temperature or Top probabilities, but not both. |
| Stop sequences | Makes the model end its response at a desired point. The model response ends before the specified sequence, so it doesn't contain the stop sequence text. For GPT-35-Turbo, using <|im_end|> ensures that the model response doesn't generate a follow-up user query. You can include as many as four stop sequences. |
| Frequency penalty | Reduces the chance of repeating a token proportionally based on how often it appears in the text so far. This action decreases the likelihood of repeating the exact same text in a response. |
| Presence penalty | Reduces the chance of repeating any token that appears in the text at all so far. This increases the likelihood of introducing new topics in a response. |
Clean up resources
After you're done testing out the chat playground, if you want to clean up and remove an OpenAI resource, you can delete the resource or resource group. Deleting the resource group also deletes any other resources associated with it. Use the following steps to clean up resources:
To delete your Azure OpenAI resources, navigate to the left-hand Azure Explorer sidebar and locate the Azure OpenAI item.
Right-click the Azure OpenAI service you'd like to delete and then select Delete.
To delete your resource group, visit the Azure portal and manually delete the resources under your subscription.
Next steps
For more information, see Learn how to work with the GPT-35-Turbo and GPT-4 models.
For more examples, check out the Azure OpenAI Samples GitHub repository.