Augment large language models with retrieval-augmented generation or fine-tuning
In a series of articles, we discuss the knowledge retrieval mechanisms that large language models (LLMs) use to generate responses. By default, an LLM has access only to its training data. But you can augment the model to include real-time data or private data.
The first mechanism is retrieval-augmented generation (RAG). RAG is a form of preprocessing that combines semantic search with contextual priming. Contextual priming is discussed in detail in Key concepts and considerations for building generative AI solutions.
The second mechanism is fine-tuning. In fine-tuning, an LLM is further trained on a specific dataset after its initial broad training. The goal is to adapt the LLM to perform better on tasks or to understand concepts that are related to the dataset. This process helps the model specialize or improve its accuracy and efficiency in handling specific types of input or domains.
The following sections describe these two mechanisms in more detail.
Understanding RAG
RAG is often used to enable the "chat over my data" scenario. In this scenario, an organization has a potentially large corpus of textual content, like documents, documentation, and other proprietary data. It uses this corpus as the basis for answers to user prompts.
At a high level, you create a database entry for each document or for a portion of a document called a chunk. The chunk is indexed on its embedding, that is, a vector (array) of numbers that represent facets of the document. When a user submits a query, you search the database for similar documents, and then submit the query and the documents to the LLM to compose an answer.
Note
We use the term retrieval-augmented generation (RAG) accommodatively. The process of implementing a RAG-based chat system as outlined in this article can be applied whether you want to use external data in a supportive capacity (RAG) or as the centerpiece of the response (RCG). The nuanced distinction is not addressed in most reading related to RAG.
Creating an index of vectorized documents
The first step to creating a RAG-based chat system is to create a vector data store that contains the vector embedding of the document or chunk. Consider the following diagram, which outlines the basic steps to creating a vectorized index of documents.

The diagram represents a data pipeline. The pipeline is responsible for the ingestion, processing, and management of data that the system uses. The pipeline includes preprocessing data to be stored in the vector database and ensuring that the data that's fed into the LLM is in the correct format.
The entire process is driven by the notion of an embedding, which is a numerical representation of data (typically words, phrases, sentences, or even entire documents) that captures the semantic properties of the input in a way that can be processed by machine learning models.
To create an embedding, you send the chunk of content (sentences, paragraphs, or entire documents) to the Azure OpenAI Embeddings API. The API returns a vector. Each value in the vector represents a characteristic (dimension) of the content. Dimensions might include topic matter, semantic meaning, syntax and grammar, word and phrase usage, contextual relationships, style, or tone. Together, all the values of the vector represent the content's dimensional space. If you think of a 3D representation of a vector that has three values, a specific vector is in a specific area of the plane of the XYZ plane. What if you have 1,000 values, or even more? Although it's not possible for humans to draw a 1,000-dimension graph on a sheet of paper to make it more understandable, computers have no problem understanding that degree of dimensional space.
The next step of the diagram depicts storing the vector and the content (or a pointer to the content's location) and other metadata in a vector database. A vector database is like any type of database, but with two differences:
- Vector databases use a vector as an index to search for data.
- Vector databases implement an algorithm called cosine similar search, also called nearest neighbor. The algorithm uses vectors that most closely match the search criteria.
With the corpus of documents stored in a vector database, developers can build a retriever component to retrieve documents that match the user's query. The data is used to supply the LLM with what it needs to answer the user's query.
Answering queries by using your documents
A RAG system first uses semantic search to find articles that might be helpful to the LLM when it composes an answer. The next step is to send the matching articles with the user's original prompt to the LLM to compose an answer.
Consider the following diagram as a simple RAG implementation (sometimes called naive RAG):
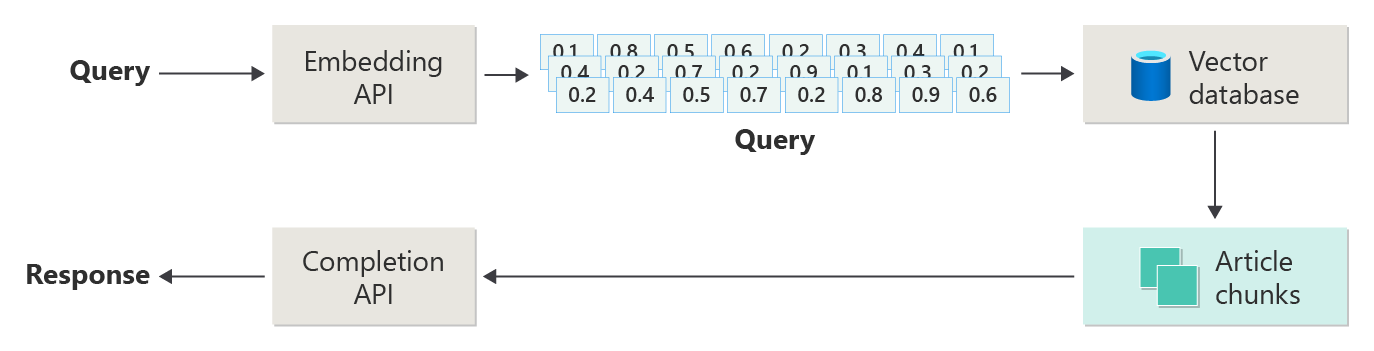
In the diagram, a user submits a query. The first step is to create an embedding for the user's prompt to return a vector. The next step is to search the vector database for those documents (or portions of documents) that are a nearest neighbor match.
Cosine similarity is a measure that helps determine how similar two vectors are. Essentially the metric assesses the cosine of the angle between them. A cosine similarity that's close to 1 indicates a high degree of similarity (a small angle). A similarity near -1 indicates dissimilarity (an angle of nearly 180 degrees). This metric is crucial for tasks like document similarity, where the goal is to find documents that have similar content or meaning.
Nearest neighbor algorithms work by finding the closest vectors (neighbors) for a point in vector space. In the k-nearest neighbors (KNN) algorithm, k refers to the number of nearest neighbors to consider. This approach is widely used in classification and regression, where the algorithm predicts the label of a new data point based on the majority label of its k nearest neighbors in the training set. KNN and cosine similarity are often used together in systems like recommendation engines, where the goal is to find items most similar to a user's preferences, represented as vectors in the embedding space.
You take the best results from that search and send the matching content with the user's prompt to generate a response that (hopefully) is informed by matching content.
Challenges and considerations
A RAG system has its set of implementation challenges. Data privacy is paramount. The system must handle user data responsibly, especially when it retrieves and processes information from external sources. Computational requirements can also be significant. Both the retrieval process and the generative processes are resource intensive. Ensuring accuracy and relevance of responses while managing biases in the data or model is another critical consideration. Developers must navigate these challenges carefully to create efficient, ethical, and valuable RAG systems.
Build advanced retrieval-augmented generation systems gives you more information about building data and inference pipelines to enable a production-ready RAG system.
If you want to start experimenting with building a generative AI solution immediately, we recommend taking a look at Get started with the chat using your own data sample for Python. The tutorial is also available for .NET, Java, and JavaScript.
Fine-tuning a model
In the context of an LLM, fine-tuning is the process of adjusting the model's parameters by training it on a domain-specific dataset after the LLM was initially trained on a large, diverse dataset.
LLMs are trained (pretrained) on a broad dataset, grasping language structure, context, and a wide array of knowledge. This stage involves learning general language patterns. Fine-tuning is adding more training to the pretrained model based on a smaller, specific dataset. This secondary training phase aims to adapt the model to perform better on particular tasks or understand specific domains, enhancing its accuracy and relevance for those specialized applications. During fine-tuning, the model's weights are adjusted to better predict or understand the nuances of this smaller dataset.
A few considerations:
- Specialization: Fine-tuning tailors the model to specific tasks, such as legal document analysis, medical text interpretation, or customer service interactions. This specialization makes the model more effective in those areas.
- Efficiency: It's more efficient to fine-tune a pretrained model for a specific task than to train a model from scratch. Fine-tuning requires less data and fewer computational resources.
- Adaptability: Fine-tuning allows for adaptation to new tasks or domains that weren't part of the original training data. The adaptability of LLMs makes them versatile tools for various applications.
- Improved performance: For tasks that are different from the data the model was originally trained on, fine-tuning can lead to better performance. Fine-tuning adjusts the model to understand the specific language, style, or terminology that's used in the new domain.
- Personalization: In some applications, fine-tuning can help personalize the model's responses or predictions to fit the specific needs or preferences of a user or organization. However, fine-tuning has specific downsides and limitations. Understanding these factors can help you decide when to opt for fine-tuning versus alternatives like RAG.
- Data requirement: Fine-tuning requires a sufficiently large and high-quality dataset that is specific to the target task or domain. Gathering and curating this dataset can be challenging and resource intensive.
- Risk of overfitting: Overfitting is a risk, especially with a small dataset. Overfitting makes the model perform well on the training data but poorly on new, unseen data. Generalizability is reduced when overfitting occurs.
- Cost and resources: Although less resource intensive than training from scratch, fine-tuning still requires computational resources, especially for large models and datasets. The cost might be prohibitive for some users or projects.
- Maintenance and updating: Fine-tuned models might need regular updates to remain effective as domain-specific information changes over time. This ongoing maintenance requires extra resources and data.
- Model drift: Because the model is fine-tuned for specific tasks, it might lose some of its general language understanding and versatility. This phenomenon is called model drift.
Customize a model through fine-tuning explains how to fine-tune a model. At a high level, you provide a JSON dataset of potential questions and preferred answers. The documentation suggests that there are noticeable improvements by providing 50 to 100 question-and-answer pairs, but the right number varies greatly on the use case.
Fine-tuning vs. RAG
On the surface, it might seem like there's quite a bit of overlap between fine-tuning and RAG. Choosing between fine-tuning and retrieval-augmented generation depends on the specific requirements of your task, including performance expectations, resource availability, and the need for domain specificity versus generalizability.
When to use fine-tuning instead of RAG:
- Task-specific performance: Fine-tuning is preferable when high performance on a specific task is critical, and there exists sufficient domain-specific data to train the model effectively without significant overfitting risks.
- Control over data: If you have proprietary or highly specialized data that significantly differs from the data the base model was trained on, fine-tuning allows you to incorporate this unique knowledge into the model.
- Limited need for real-time updates: If the task doesn't require the model to be constantly updated with the latest information, fine-tuning can be more efficient since RAG models typically need access to up-to-date external databases or the internet to pull in recent data.
When to prefer RAG over fine-tuning:
- Dynamic content or evolving content: RAG is more suitable for tasks where having the most current information is critical. Because RAG models can pull in data from external sources in real-time, they're better suited for applications like news generation or answering questions on recent events.
- Generalization over specialization: If the goal is to maintain strong performance across a wide range of topics rather than excelling in a narrow domain, RAG might be preferable. It uses external knowledge bases, allowing it to generate responses across diverse domains without the risk of overfitting to a specific dataset.
- Resource constraints: For organizations with limited resources for data collection and model training, using a RAG approach might offer a cost-effective alternative to fine-tuning, especially if the base model already performs reasonably well on the desired tasks.
Final considerations for application design
Here's a short list of things to consider and other takeaways from this article that might influence your application design decisions:
- Decide between fine-tuning and RAG based on your application's specific needs. Fine-tuning might offer better performance for specialized tasks, while RAG might provide flexibility and up-to-date content for dynamic applications.