sparklyr
Azure Databricks supports sparklyr in notebooks, jobs, and RStudio Desktop. This article describes how you can use sparklyr and provides example scripts that you can run. See R interface to Apache Spark for more information.
Requirements
Azure Databricks distributes the latest stable version of sparklyr with every Databricks Runtime release. You can use sparklyr in Azure Databricks R notebooks or inside RStudio Server hosted on Azure Databricks by importing the installed version of sparklyr.
In RStudio Desktop, Databricks Connect allows you to connect sparklyr from your local machine to Azure Databricks clusters and run Apache Spark code. See Use sparklyr and RStudio Desktop with Databricks Connect.
Connect sparklyr to Azure Databricks clusters
To establish a sparklyr connection, you can use "databricks" as the connection method in spark_connect().
No additional parameters to spark_connect() are needed, nor is calling spark_install() needed because Spark is already installed on an Azure Databricks cluster.
# Calling spark_connect() requires the sparklyr package to be loaded first.
library(sparklyr)
# Create a sparklyr connection.
sc <- spark_connect(method = "databricks")
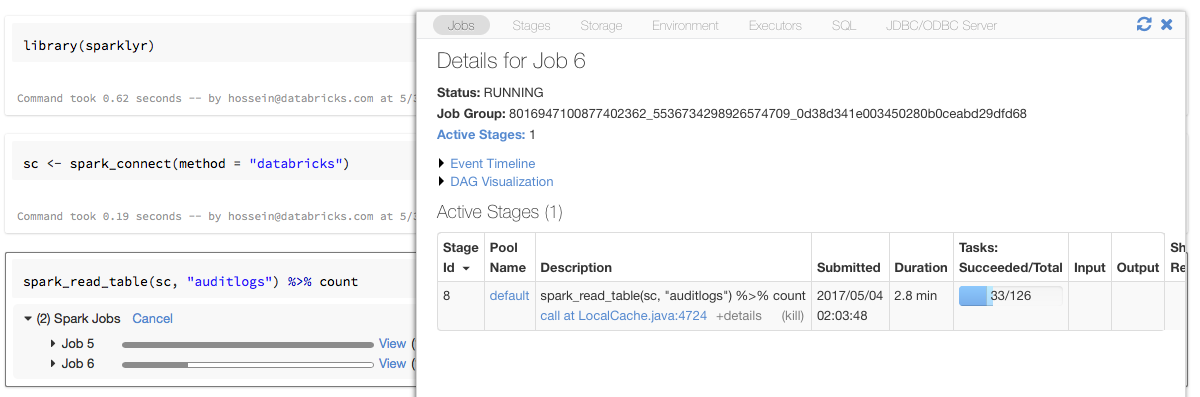
Progress bars and Spark UI with sparklyr
If you assign the sparklyr connection object to a variable named sc as in the above example,
you will see Spark progress bars in the notebook after each command that triggers Spark jobs.
In addition, you can click the link next to the progress bar to view the Spark UI associated with
the given Spark job.
Use sparklyr
After you install sparklyr and establish the connection, all other sparklyr API work as they normally do. See the example notebook for some examples.
sparklyr is usually used along with other tidyverse packages such as dplyr. Most of these packages are preinstalled on Databricks for your convenience. You can simply import them and start using the API.
Use sparklyr and SparkR together
SparkR and sparklyr can be used together in a single notebook or job. You can import SparkR along with sparklyr and use its functionality. In Azure Databricks notebooks, the SparkR connection is pre-configured.
Some of the functions in SparkR mask a number of functions in dplyr:
> library(SparkR)
The following objects are masked from ‘package:dplyr’:
arrange, between, coalesce, collect, contains, count, cume_dist,
dense_rank, desc, distinct, explain, filter, first, group_by,
intersect, lag, last, lead, mutate, n, n_distinct, ntile,
percent_rank, rename, row_number, sample_frac, select, sql,
summarize, union
If you import SparkR after you imported dplyr, you can reference the functions in dplyr by using
the fully qualified names, for example, dplyr::arrange().
Similarly if you import dplyr after SparkR, the functions in SparkR are masked by dplyr.
Alternatively, you can selectively detach one of the two packages while you do not need it.
detach("package:dplyr")
See also Comparing SparkR and sparklyr.
Use sparklyr in spark-submit jobs
You can run scripts that use sparklyr on Azure Databricks as spark-submit jobs, with minor code modifications. Some of the instructions above do not apply to using sparklyr in spark-submit jobs on Azure Databricks. In particular, you must provide the Spark master URL to spark_connect. For example:
library(sparklyr)
sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>")
...
Unsupported features
Azure Databricks does not support sparklyr methods such as spark_web() and spark_log() that require a
local browser. However, since the Spark UI is built-in on Azure Databricks, you can inspect Spark jobs and logs easily.
See Compute driver and worker logs.
Example notebook: Sparklyr demonstration
Sparklyr notebook
For additional examples, see Work with DataFrames and tables in R.