Conduct your own LLM endpoint benchmarking
This article provides a Databricks recommended notebook example for benchmarking an LLM endpoint. It also includes a brief introduction to how Databricks performs LLM inference and calculates latency and throughput as endpoint performance metrics.
LLM inference on Databricks measures tokens per second for provisioned throughput mode for Foundation Model APIs. See What do tokens per second ranges in provisioned throughput mean?.
Benchmarking example notebook
You can import the following notebook into your Databricks environment and specify the name of your LLM endpoint to run a load test.
Benchmarking an LLM endpoint
LLM inference introduction
LLMs perform inference in a two-step process:
- Prefill, where the tokens in the input prompt are processed in parallel.
- Decoding, where text is generated one token at a time in an auto-regressive manner. Each generated token is appended to the input and fed back into the model to generate the next token. Generation stops when the LLM outputs a special stop token or when a user-defined condition is met.
Most production applications have a latency budget, and Databricks recommends you maximize throughput given that latency budget.
- The number of input tokens has a substantial impact on the required memory to process requests.
- The number of output tokens dominates overall response latency.
Databricks divides LLM inference into the following sub-metrics:
- Time to first token (TTFT): This is how quickly users start seeing the model’s output after entering their query. Low waiting times for a response are essential in real-time interactions, but less important in offline workloads. This metric is driven by the time required to process the prompt and then generate the first output token.
- Time per output token (TPOT): Time to generate an output token for each user that is querying the system. This metric corresponds with how each user perceives the “speed” of the model. For example, a TPOT of 100 milliseconds per token would be 10 tokens per second, or ~450 words per minute, which is faster than a typical person can read.
Based on these metrics, total latency and throughput can be defined as follows:
- Latency = TTFT + (TPOT) * (the number of tokens to be generated)
- Throughput = number of output tokens per second across all concurrency requests
On Databricks, LLM serving endpoints are able to scale to match the load sent by clients with multiple concurrent requests. There is a trade-off between latency and throughput. This is because, on LLM serving endpoints, concurrent requests can be and are processed at the same time. At low concurrent request loads, latency is the lowest possible. However, if you increase the request load, latency might go up, but throughput likely also goes up. This is because two requests worth of tokens per second can be processed in less than double the time.
Therefore, controlling the number of parallel requests into your system is core to balancing latency with throughput. If you have a low latency use case, you want to send fewer concurrent requests to the endpoint to keep latency low. If you have a high throughput use case, you want to saturate the endpoint with lots of concurrency requests, since higher throughput is worth it even at the expense of latency.
Databricks benchmarking harness
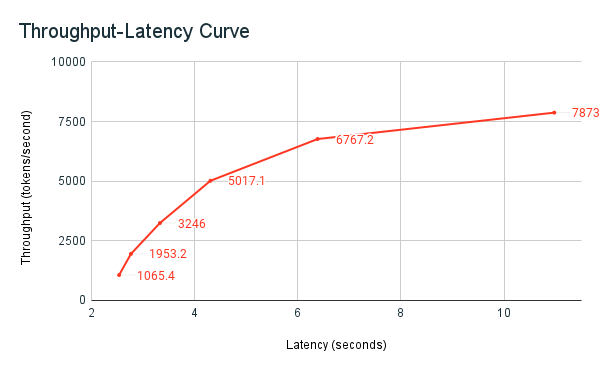
The previously shared benchmarking example notebook is Databricks’ benchmarking harness. The notebook displays the latency and throughput metrics, and plots the throughput versus latency curve across different numbers of parallel requests. Databricks endpoint autoscaling is based on a “balanced” strategy between latency and throughput. In the notebook, you observe that as more concurrent users are querying the endpoint at the same time latency goes up as well as throughput.
More details on the Databricks philosophy about LLM performance benchmarking is described in the LLM Inference Performance Engineering: Best Practices blog.