View, manage, and analyze Foundation Model Fine-tuning runs
Important
This feature is in Public Preview in the following regions: centralus, eastus, eastus2, northcentralus, and westus.
This article describes how to view, manage, and analyze Foundation Model Fine-tuning (now part of Mosaic AI Model Training) runs using APIs or using the UI.
For information on creating runs, see Create a training run using the Foundation Model Fine-tuning API and Create a training run using the Foundation Model Fine-tuning UI.
Use Foundation Model Fine-tuning APIs to view and manage training runs
The Foundation Model Fine-tuning APIs provide the following functions for managing your training runs.
Get a run
Use the get() function to return a run by name or run object you have launched.
from databricks.model_training import foundation_model as fm
fm.get('<your-run-name>')
List runs
Use the list() function to see the runs you have launched. The following table lists the optional filters you can specify.
| Optional filter | Definition |
|---|---|
finetuning_runs |
A list of runs to get. Defaults to selecting all runs. |
user_emails |
If shared runs is enabled for your workspace, you can filter results by the user who submitted the training run. Defaults to no user filter. |
before |
A datetime or datetime string to filter runs before. Defaults to all runs. |
after |
A datetime or datetime string to filter runs after. Defaults to all runs. |
from databricks.model_training import foundation_model as fm
fm.list()
# filtering example
fm.list(before='2023-01-01', limit=50)
Cancel training runs
To cancel a single training run, use the cancel() function and pass in the run name.
from databricks.model_training import foundation_model as fm
run_to_cancel = '<name-of-run-to-cancel>'
fm.cancel(run_to_cancel)
To cancel multiple training runs, pass in the specific run names as a list.
from databricks.model_training import foundation_model as fm
runs_to_cancel = ['<run_1>, <run_2>, <run_3>']
fm.cancel(runs=runs_to_cancel)
To cancel all training runs in an experiment, pass in the experiment ID.
from databricks.model_training import foundation_model as fm
experiment_to_cancel = '<experiment-id-to-cancel>'
fm.cancel(experiment_id=experiment_to_cancel)
Review status of training runs
The following table lists the events created by a training run. Use the get_events() function anytime during your run to see your run’s progress.
Note
Foundation Model Fine-tuning enforces a limit of 10 active runs. These runs that are either in queue, running, or finishing up. Runs are no longer considered active after they are in the COMPLETED, FAILED, or STOPPED state.
| Event type | Example event message | Definition |
|---|---|---|
CREATED |
Run created. | Training run was created. If resources are availabe, the run starts. Otherwise, it enters the Pending state. |
STARTED |
Run started. | Resources have been allocated, and the run has started. |
DATA_VALIDATED |
Training data validated. | Validated that training data is correctly formatted. |
MODEL_INITIALIZED |
Model data downloaded and initialized for base model meta-llama/Llama-2-7b-chat-hf. |
Weights for the base model have been downloaded, and training is ready to begin. |
TRAIN_UPDATED |
[epoch=1/1][batch=50/56][ETA=5min] Train loss: 1.71 | Reports the current training batch, epoch, or token, estimated time for training to finish (not including checkpoint upload time) and train loss. This event is updated when each batch ends. If the run configuration specifies max_duration in tok units, progress is reported in tokens. |
TRAIN_FINISHED |
Training completed. | Training has finished. Checkpoint uploading begins. |
COMPLETED |
Run completed. Final weights uploaded. | Checkpoint has been uploaded, and the run has been completed. |
CANCELED |
Run canceled. | The run is canceled if fm.cancel() is called on it. |
FAILED |
One or more train dataset samples has unknown keys. Please check the documentation for supported data formats. | The run failed. Check event_message for actionable details, or contact support. |
from databricks.model_training import foundation_model as fm
fm.get_events()
Use the UI to view and manage runs
To view runs in the UI:
Click Experiments in the left nav bar to display the Experiments page.
In the table, click the name of your experiment to display the experiment page. The experiment page lists all runs associated with the experiment.
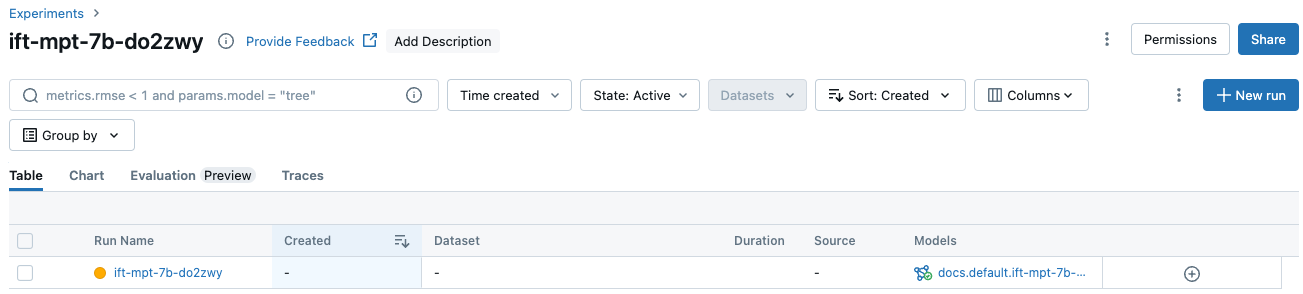
To display additional information or metrics in the table, click
 and select the items to display from the menu:
and select the items to display from the menu:
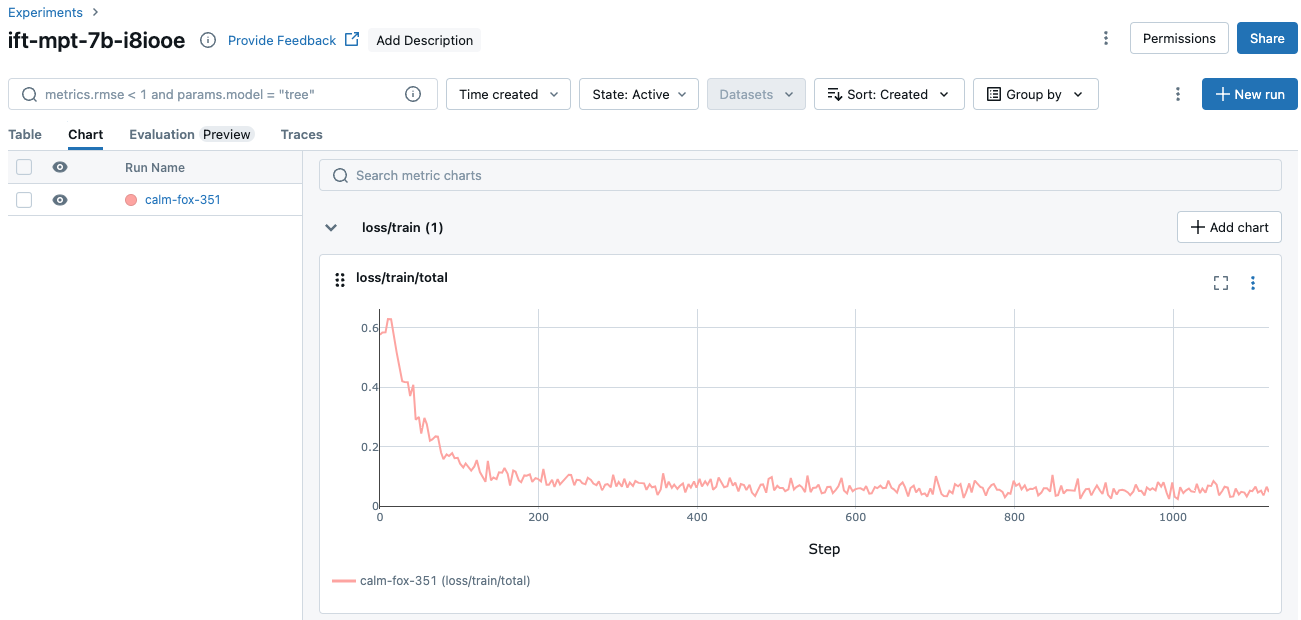
Additional run information is available in the Chart tab:
You can also click on the name of the run to display the run screen. This screen gives you access to additional details about the run.
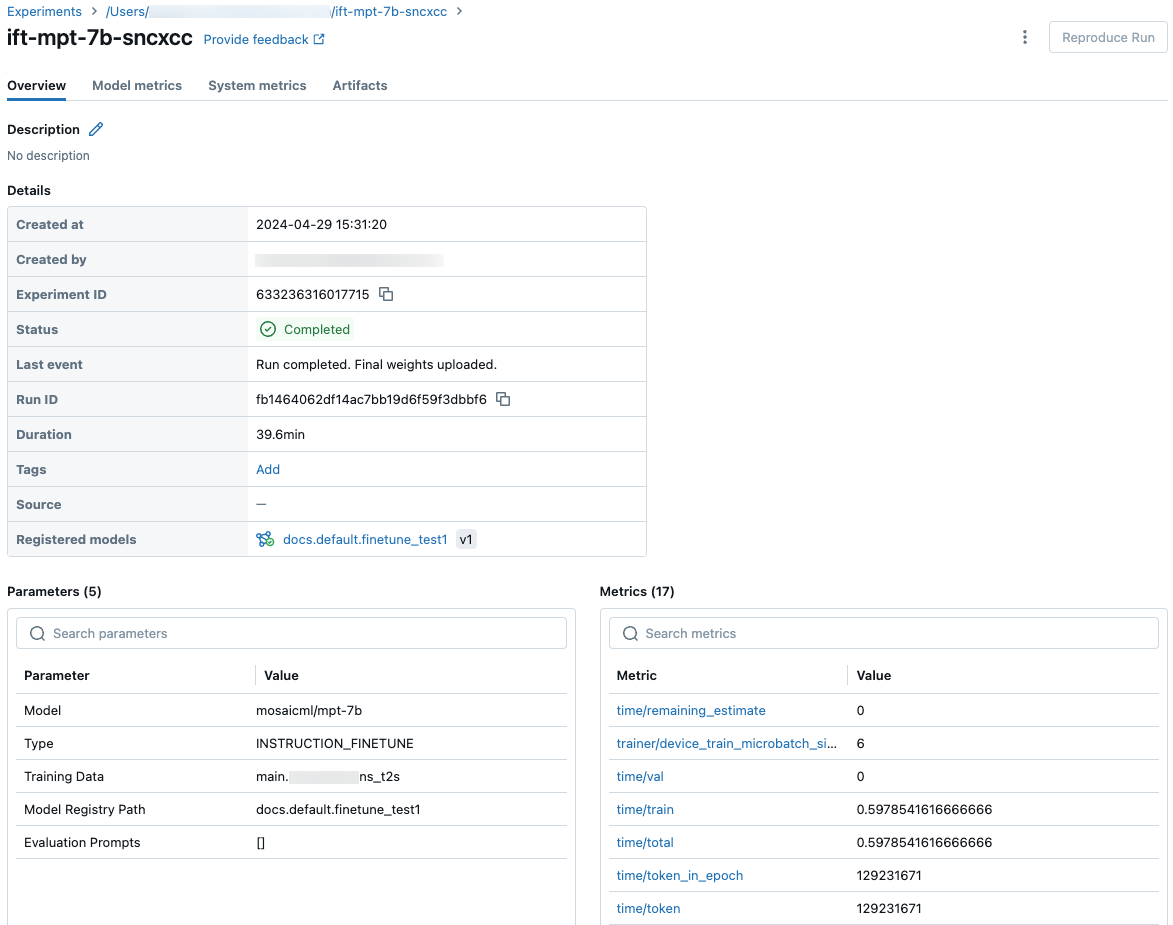
Checkpoints
To access the checkpoint folder, click the Artifacts tab on the run screen. Open the experiment name, and then open the checkpoints folder. These artifact checkpoints are not the same as the registered model at the end of a training run.
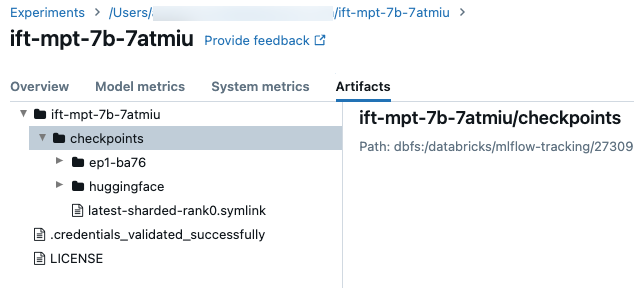
There a few directories in this folder:
- The epoch folders (named
ep<n>-xxx) contain the weights and model states at each Composer checkpoint. Composer checkpoints are saved periodically through training, these are used for resuming a fine-tuning training run and continued fine-tuning. This checkpoint is the one you pass in as thecustom_weights_pathto start another training run from those weights, see Build on custom model weights. - In the
huggingfacefolder, Hugging Face checkpoints are also saved periodically through training. After you download the content in this folder, you can load these checkpoints like you would with any other Hugging Face checkpoint usingAutoModelForCausalLM.from_pretrained(<downloaded folder>). - The
checkpoints/latest-sharded-rank0.symlinkis a file that holds the path to the latest checkpoint, that you can use to resume training.
You can also get the Composer checkpoints for a run after they are saved using get_checkpoints(run). This function takes the run object as the input. If checkpoints do not exist yet, you are prompted to try again after checkpoints are saved.