Create an AI agent
Important
This feature is in Public Preview.
This article introduces the process of creating AI agents on Azure Databricks and outlines the available methods for creating agents.
To learn more about agents, see What are compound AI systems and AI agents?.
Author an agent in code
Mosaic AI Agent Framework and MLflow provide tools to help you author enterprise-ready agents in Python.
Databricks supports authoring agents using third-party agent authoring libraries like LangGraph/LangChain, LlamaIndex, or custom Python implementations.
To learn how to create AI agents on Databricks, see Author AI agents in code.
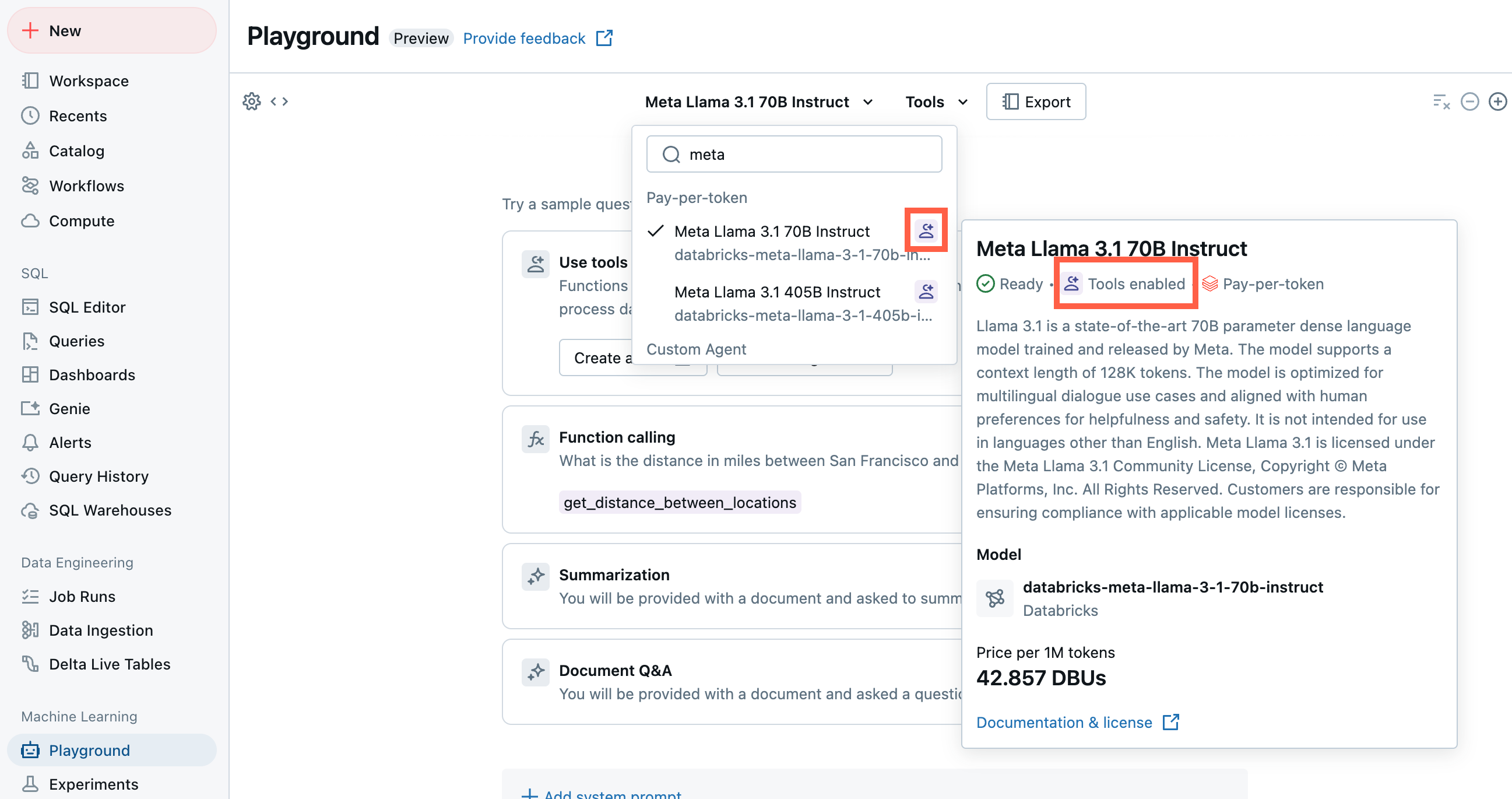
Prototype agents with AI Playground
The AI Playground is the easiest way to get started creating an agent on Azure Databricks. AI Playground lets you select from various LLMs and quickly add tools to the LLM using a low-code UI. You can then chat with the agent to test its responses and then export the agent to code for deployment or further development.
See Prototype tool-calling agents in AI Playground.
Understand model signatures to ensure compatibility with Databricks features
Mosaic AI uses MLflow Model Signatures to define the input and output schema requirements for agents. The model signature tells internal and external components how to interact with your agent and validates that they adhere to the schema.
To ensure compatibility with Databricks and MLflow features, your agent must conform to OpenAI’s ChatCompletionRequest and ChatCompletionResponse signatures, which are open-source and widely compatible with other platforms.
Additionally, Databricks supports custom input and output fields that extend these schemas. To facilitate this, MLflow offers ChatModel, which adds custom fields by default.
This ensures that any agent created using the ChatModel interface will be automatically compliant with the chat completion interface and the broader Databricks toolset.