Attribute usage using tags
This article explains how to use custom and default tags to attribute workloads to specific workspaces, teams, projects, and users.
To monitor cost and accurately attribute Azure Databricks usage to your organization’s business units and teams (for chargebacks, for example), you can tag workspaces (resource groups) and compute resources. These tags propagate to detailed cost analysis reports that you can access in the Azure portal. Note: Tag data may be replicated globally. Do not use tag names or values that could compromise the security of your resources. For example, do not use tag names that contain personal or sensitive information.
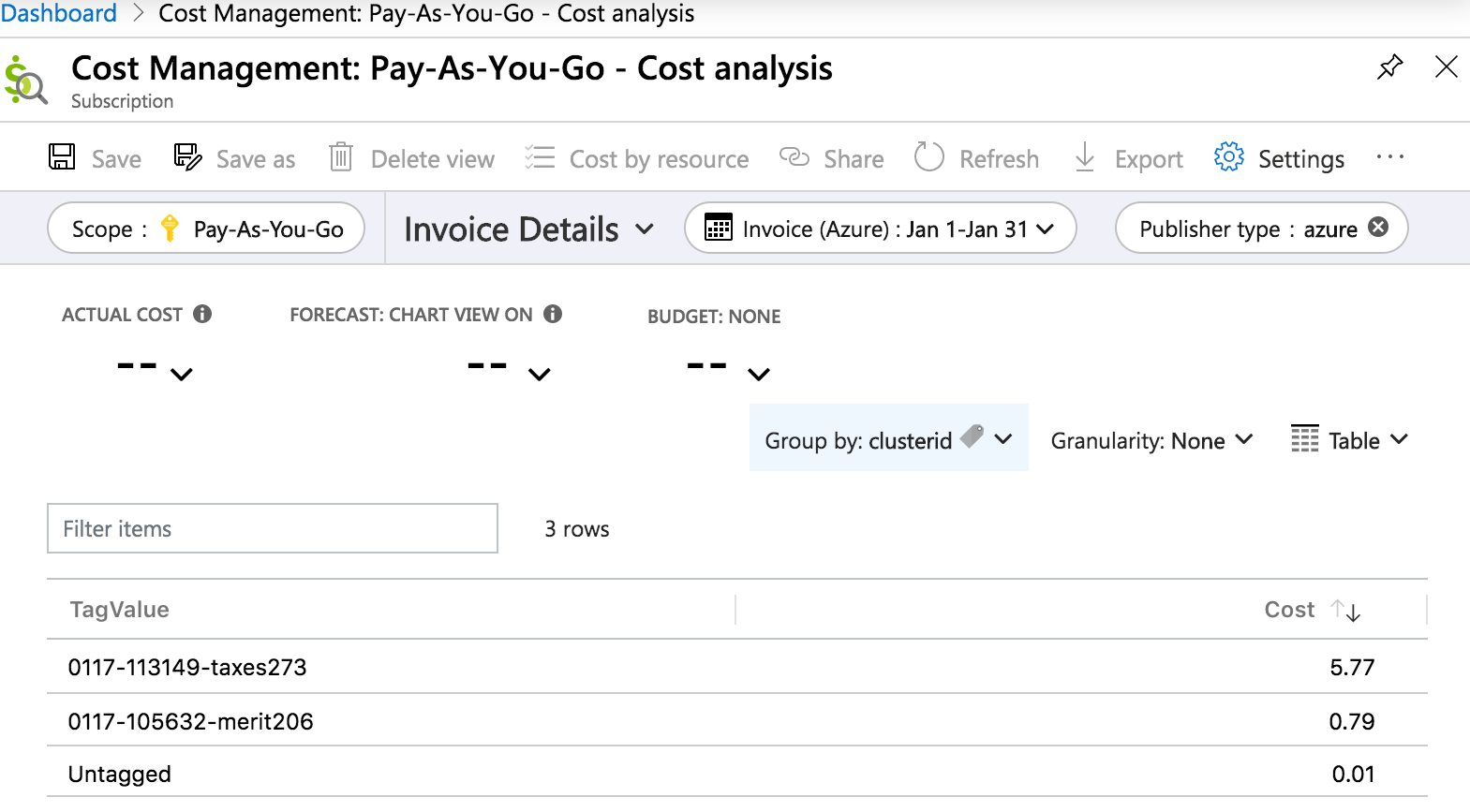
Here is a cost analysis invoice details report in the Azure portal that details cost by clusterid tag over a one-month period:
Tagged objects and resources
| Object | Tagging interface (UI) | Tagging interface (API) |
|---|---|---|
| Workspace | Azure Portal | Azure Resources API |
| Pool | Pools UI in the Azure Databricks workspace | Instance Pool API |
| All-purpose and job compute | Compute UI in the Azure Databricks workspace | Clusters API |
| SQL warehouse | SQL warehouse UI in the Azure Databricks workspace | Warehouses API |
Warning
Do not assign a custom tag with the key Name to a cluster. Every cluster has a tag Name whose value is set by Azure Databricks. If you change the value associated with the key Name, the cluster can no longer be tracked by Azure Databricks. As a consequence, the cluster might not be terminated after becoming idle and will continue to incur usage costs.
Default tags
Azure Databricks adds the following default tags to all-purpose compute:
| Tag key | Value |
|---|---|
Vendor |
Constant value: Databricks |
ClusterId |
Azure Databricks internal ID of the cluster |
ClusterName |
Name of the cluster |
Creator |
Username (email address) of the user who created the cluster |
On job clusters, Azure Databricks also applies the following default tags:
| Tag key | Value |
|---|---|
RunName |
Job name |
JobId |
Job ID |
Azure Databricks adds the following default tags to all pools:
| Tag key | Value |
|---|---|
Vendor |
Constant value: Databricks |
DatabricksInstancePoolCreatorId |
Azure Databricks internal ID of the user who created the pool |
DatabricksInstancePoolId |
Azure Databricks internal ID of the pool |
On compute used by Lakehouse Monitoring, Azure Databricks also applies the following tags:
| Tag key | Value |
|---|---|
LakehouseMonitoring |
true |
LakehouseMonitoringTableId |
ID of the monitored table |
LakehouseMonitoringWorkspaceId |
ID of the workspace where the monitor was created |
LakehouseMonitoringMetastoreId |
ID of the metastore where the monitored table exists |
Tag serverless compute workloads
Important
This feature is in Public Preview.
To attribute serverless compute usage to users, groups, or projects, you can use budget policies. When a user is assigned a budget policy, their serverless usage is automatically tagged with their policy’s tags. See Attribute serverless usage with budget policies.
Tag propagation
Workspace, pool, and cluster tags are aggregated by Azure Databricks and propagated to Azure VMs for cost analysis reporting. But pool and cluster tags are propagated differently from each other.
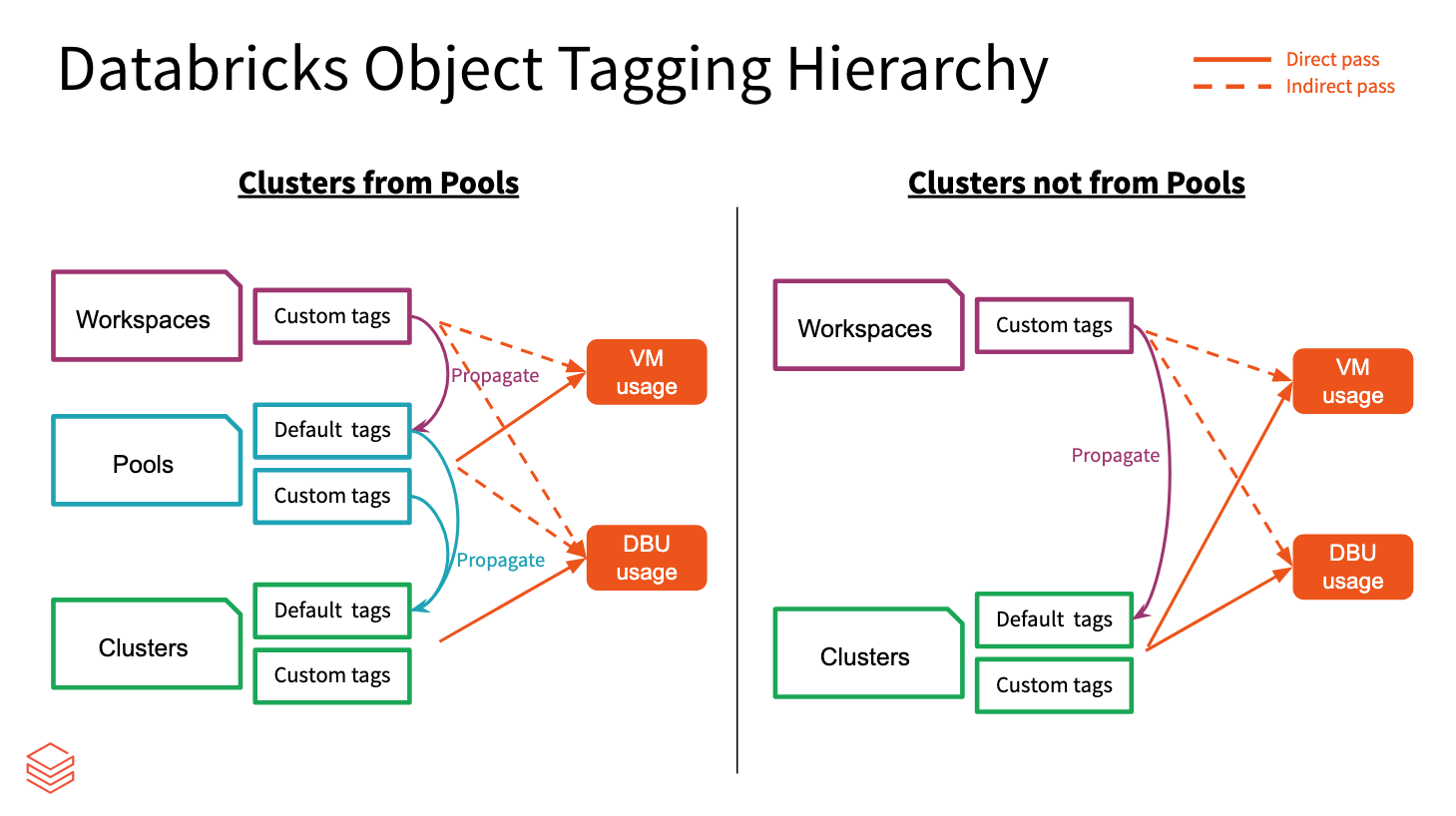
Workspace and pool tags are aggregated and assigned as resource tags of the Azure VMs that host the pools.
Workspace and cluster tags are aggregated and assigned as resource tags of the Azure VMs that host the clusters.
When clusters are created from pools, only workspace tags and pool tags are propagated to the VMs. Cluster tags are not propagated, in order to preserve pool cluster startup performance.
Tag conflict resolution
If a custom cluster tag, pool tag, or workspace tag has the same name as an Azure Databricks default cluster or pool tag, the custom tag is prefixed with an x_ when it is propagated.
For example, if a workspace is tagged with vendor = Azure Databricks, that tag will conflict with the default cluster tag vendor = Databricks. The tags will therefore be propagated as x_vendor = Azure Databricks and vendor = Databricks.
Limitations
- It can take up to one hour for custom workspace tags to propagate to Azure Databricks after any change.
- No more than 50 tags can be assigned to an Azure resource. If the overall count of aggregated tags exceeds this limit,
x_-prefixed tags are evaluated in alphabetical order and those that exceed the limit are ignored. If allx_-prefixed tags are ignored and the count is till over the limit, the remaining tags are evaluated in alphabetical order and those that exceed the limit are ignored. - Tag keys and values can only contain letters, spaces, numbers, or the characters
+,-,=,.,_,:,/,@. Tags containing other characters are invalid. - If you change tag key names or values, these changes apply only after cluster restart or pool expansion.
- If the cluster’s custom tags conflict with a pool’s custom tags, the cluster can’t be created.
- Newly added workspace tags do not automatically propogate to existing compute resources. To get new tags to propogate, open the compute resource’s details page, click Edit, and then Confirm and restart.
Tagging best practices
- Because tags can be entered manually, your organization should standardize its key-value pairs. Databricks recommends developing a business policy for key and value naming that you can share with all users.
- All resources should be tagged with general keys that attribute the usage to a business unit or project. For example, a job compute resource created by the finance team for their annual budget might include the tags
business-unit:financeandproject:annual-budget. - For more granular insights, assign tags using high-specificity keys. For example, you might create keys based on roles, products, services, or customers.
- When applicable, workspace admins should enforce tags using compute policies and budget policies. See Custom tag enforcement.