Assert transformation in mapping data flow
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
Data flows are available both in Azure Data Factory and Azure Synapse Pipelines. This article applies to mapping data flows. If you are new to transformations, please refer to the introductory article Transform data using a mapping data flow.
The Assert transformation enables you to build custom rules inside your mapping data flows for data quality and data validation. You can build rules that determine whether values meet an expected value domain. Additionally, you can build rules that check for row uniqueness. The Assert transformation helps to determine if each row in your data meets a set of criteria. The Assert transformation also allows you to set custom error messages when data validation rules aren't met.
Configuration
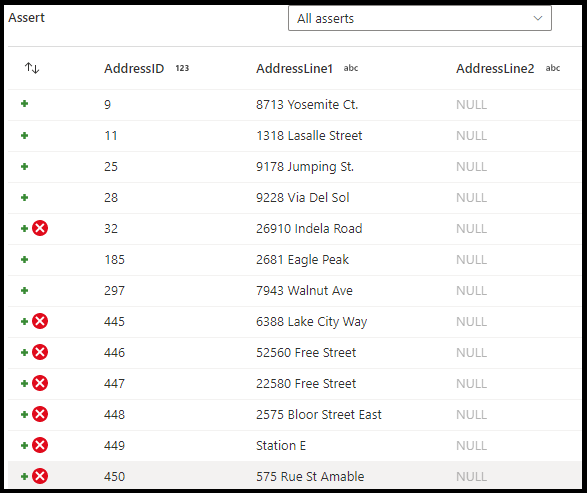
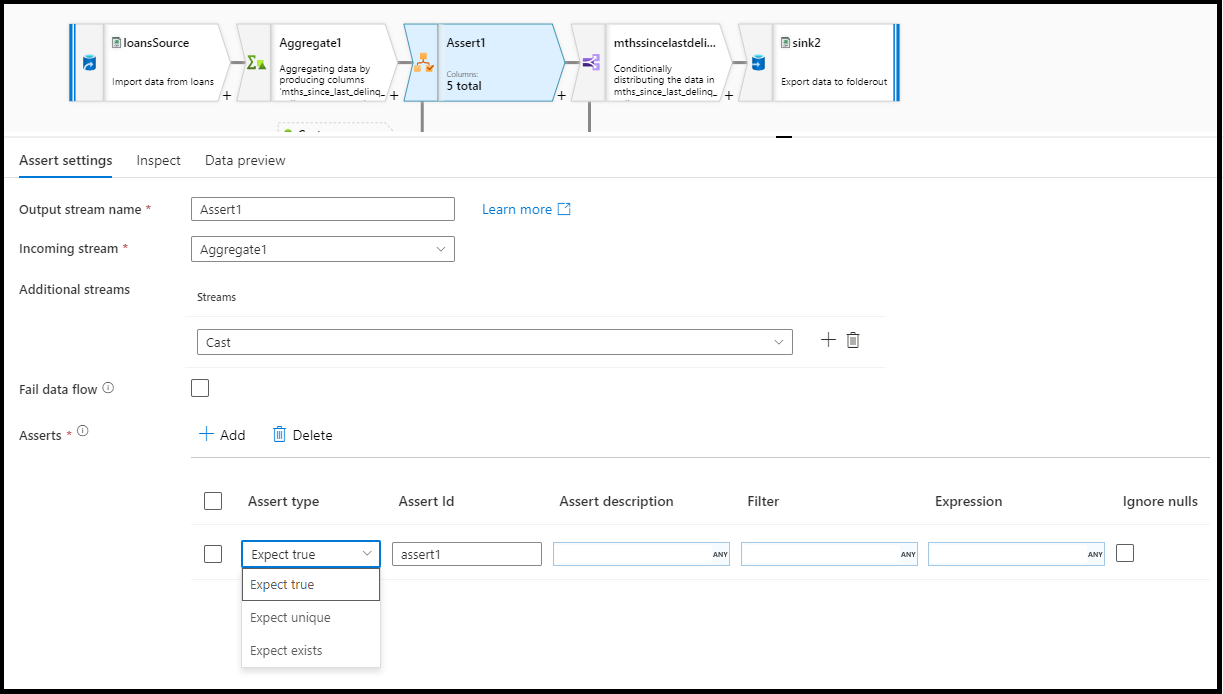
In the assert transformation configuration panel, you choose the type of assert, provide a unique name for the assertion, optional description, and define the expression and optional filter. The data preview pane indicates which rows failed your assertions. Additionally, you can test each row tag downstream using isError() and hasError() for rows that failed assertions.
Assert type
- Expect true: The result of your expression must evaluate to a boolean true result. Use this setting to validate domain value ranges in your data.
- Expect unique: Set a column or an expression as a uniqueness rule in your data. Use this setting to tag duplicate rows.
- Expect exists: This option is only available when you selected a second incoming stream. Exists looks at both streams and determine if the rows exist in both streams based on the columns or the expressions that you specified. To add the second stream for exists, select
Additional streams.
Fail data flow
Select fail data flow if you wish to have your data flow activity fail immediately as soon as the assertion rule fails.
Assert ID
Assert ID is a property where you enter a (string) name for your assertion. You are able to use the identifier later downstream in your data flow using hasError() or to output the assertion failure code. Assert IDs must be unique within each dataflow.
Assert description
Enter a string description for your assertion here. You can use expressions and row-context column values here as well.
Filter
Filter is an optional property where you can filter the assertion to only a subset of rows based on your expression value.
Expression
Enter an expression for evaluation for each of your assertions. You can have multiple assertions for each assert transformation. Each type of assertion requires an expression that ADF needs to evaluate to test if the assertion passed.
Ignore NULLs
By default, the assert transformation includes NULLs in row assertion evaluation. You can choose to ignore NULLs with this property.
Direct assert row failures
When an assertion fails, you can optionally direct those error rows to a file in Azure by using the "Errors" tab on the sink transformation. You also have an option on the sink transformation to not output rows with assertion failures at all by ignoring error rows.
Examples
source(output(
AddressID as integer,
AddressLine1 as string,
AddressLine2 as string,
City as string,
StateProvince as string,
CountryRegion as string,
PostalCode as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source(output(
CustomerID as integer,
AddressID as integer,
AddressType as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source2
source1, source2 assert(expectExists(AddressLine1 == AddressLine1, false, 'nonUS', true(), 'only valid for U.S. addresses')) ~> Assert1
Data flow script
Examples
source1, source2 assert(expectTrue(CountryRegion == 'United States', false, 'nonUS', null, 'only valid for U.S. addresses'),
expectExists(source1@AddressID == source2@AddressID, false, 'assertExist', StateProvince == 'Washington', toString(source1@AddressID) + ' already exists in Washington'),
expectUnique(source1@AddressID, false, 'uniqueness', null, toString(source1@AddressID) + ' is not unique')) ~> Assert1
Related content
- Use the Select transformation to select and validate columns.
- Use the Derived column transformation to transform column values.