Integration runtime in Azure Data Factory
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
The Integration Runtime (IR) is the compute infrastructure used by Azure Data Factory and Azure Synapse pipelines to provide the following data integration capabilities across different network environments:
- Data Flow: Execute a Data Flow in a managed Azure compute environment.
- Data movement: Copy data across data stores in a public or private networks (for both on-premises or virtual private networks). The service provides support for built-in connectors, format conversion, column mapping, and performant and scalable data transfer.
- Activity dispatch: Dispatch and monitor transformation activities running on a variety of compute services such as Azure Databricks, Azure HDInsight, ML Studio (classic), Azure SQL Database, SQL Server, and more.
- SSIS package execution: Natively execute SQL Server Integration Services (SSIS) packages in a managed Azure compute environment.
In Data Factory and Synapse pipelines, an activity defines the action to be performed. A linked service defines a target data store or a compute service. An integration runtime provides the bridge between activities and linked services. It's referenced by the linked service or activity, and provides the compute environment where the activity is either run directly or dispatched. This allows the activity to be performed in the closest possible region to the target data store or compute service to maximize performance while also allowing flexibility to meet security and compliance requirements.
Integration runtimes can be created in the Azure Data Factory and Azure Synapse UI via the management hub directly, as well as from any activities, datasets, or data flows that reference them.
Integration runtime types
Data Factory offers three types of Integration Runtime (IR), and you should choose the type that best serves your data integration capabilities and network environment requirements. The three types of IR are:
- Azure
- Self-hosted
- Azure-SSIS
Note
Synapse pipelines currently only support Azure or self-hosted integration runtimes.
The following table describes the capabilities and network support for each of the integration runtime types:
| IR type | Public Network Support | Private Link Support |
|---|---|---|
| Azure | Data Flow Data movement Activity dispatch |
Data Flow Data movement Activity dispatch |
| Self-hosted | Data movement Activity dispatch |
Data movement Activity dispatch |
| Azure-SSIS | SSIS package execution | SSIS package execution |
Note
Outbound controls vary by service for Azure IR. In Synapse, workspaces have options to limit outbound traffic from the managed virtual network when utilizing Azure IR. In Data Factory, all ports are opened for outbound communications when utilizing Azure IR. Azure-SSIS IR can be integrated with your vNET to provide outbound communications controls.
Azure integration runtime
An Azure integration runtime can:
- Run Data Flows in Azure
- Run copy activities between cloud data stores
- Dispatch the following transform activities in a public network:
- .NET custom activity
- Azure Function activity
- Databricks Notebook/ Jar/ Python activity
- Data Lake Analytics U-SQL activity
- Get Metadata activity
- HDInsight Hive activity
- HDInsight Pig activity
- HDInsight MapReduce activity
- HDInsight Spark activity
- HDInsight Streaming activity
- Lookup activity
- Machine Learning Studio (classic) Batch Execution activity
- Machine Learning Studio (classic) Update Resource activity
- Stored Procedure activity
- Validation activity
- Web activity
Azure IR network environment
Azure Integration Runtime supports connecting to data stores and computes services with public accessible endpoints. Enabling Managed Virtual Network, Azure Integration Runtime supports connecting to data stores using private link service in private network environment. In Synapse, workspaces have options to limit outbound traffic from the IR managed virtual network. In Data Factory, all ports are opened for outbound communications. The Azure-SSIS IR can be integrated with your vNET to provide outbound communications controls.
Azure IR compute resource and scaling
Azure integration runtime provides a fully managed, serverless compute in Azure. You don't have to worry about infrastructure provision, software installation, patching, or capacity scaling. In addition, you only pay for the duration of the actual utilization.
Azure integration runtime provides the native compute to move data between cloud data stores in a secure, reliable, and high-performance manner. You can set how many data integration units to use on the copy activity, and the compute size of the Azure IR is elastically scaled up accordingly without requiring you to explicitly adjust the size of the Azure Integration Runtime.
Activity dispatch is a lightweight operation to route the activity to the target compute service, so there isn't need to scale up the compute size for this scenario.
For information about creating and configuring an Azure IR, see How to create and configure Azure Integration Runtime.
Note
Azure Integration runtime has properties related to Data Flow runtime, which defines the underlying compute infrastructure that would be used to run the data flows.
Self-hosted integration runtime
A self-hosted IR is capable of:
- Running copy activity between a cloud data stores and a data store in private network.
- Dispatching the following transform activities against compute resources in on-premises or Azure Virtual Network:
- Azure Function activity
- Custom activity (runs on Azure Batch)
- Data Lake Analytics U-SQL activity
- Get Metadata activity
- HDInsight Hive activity (BYOC-Bring Your Own Cluster)
- HDInsight Pig activity (BYOC)
- HDInsight MapReduce activity (BYOC)
- HDInsight Spark activity (BYOC)
- HDInsight Streaming activity (BYOC)
- Lookup activity
- Machine Learning Studio (classic) Batch Execution activity
- Machine Learning Studio (classic) Update Resource activity
- Machine Learning Execute Pipeline activity
- Stored Procedure activity
- Validation activity
- Web activity
Note
Use self-hosted integration runtime to support data stores that require bring-your-own driver, such as SAP Hana, MySQL, etc. For more information, see supported data stores.
Note
The Java Runtime Environment (JRE) is a dependency of the Self Hosted IR. Please make sure you have the JRE installed on the same host.
Self-hosted IR network environment
If you want to perform data integration securely in a private network environment that doesn't have a direct line-of-sight from the public cloud environment, you can install a self-hosted IR in your on-premises environment behind a firewall, or inside a virtual private network. The self-hosted integration runtime only makes outbound HTTP-based connections to the internet.
Self-hosted IR compute resource and scaling
Install a Self-hosted IR on an on-premises machine or a virtual machine inside a private network. Currently, the self-hosted IR is only supported on a Windows operating system.
For high availability and scalability, you can scale out the self-hosted IR by associating the logical instance with multiple on-premises machines in active-active mode. For more information, see the article on how to create and configure a self-hosted IR for details.
Azure-SSIS integration runtime
To lift and shift existing SSIS workload, you can create an Azure-SSIS IR to natively execute SSIS packages.
Azure-SSIS IR network environment
The Azure-SSIS IR can be provisioned in either public network or private network. On-premises data access is supported by joining Azure-SSIS IR to a virtual network that is connected to your on-premises network.
Azure-SSIS IR compute resource and scaling
The Azure-SSIS IR is a fully managed cluster of Azure VMs dedicated to run your SSIS packages. You can bring your own Azure SQL Database or SQL Managed Instance for the catalog of SSIS projects/packages (SSISDB). You can scale up the power of the compute by specifying node size and scale it out by specifying the number of nodes in the cluster. You can manage the cost of running your Azure-SSIS Integration Runtime by stopping and starting it as your requirements demand.
For more information, see How to create and configure the Azure-SSIS IR. Once created, you can deploy and manage your existing SSIS packages with little to no change using familiar tools such as SQL Server Data Tools (SSDT) and SQL Server Management Studio (SSMS), just like using SSIS on-premises.
For more information about the Azure-SSIS runtime, see the following articles:
- Tutorial: deploy SSIS packages to Azure. This article provides step-by-step instructions to create an Azure-SSIS IR and uses an Azure SQL Database to host the SSIS catalog.
- How to: Create an Azure-SSIS integration runtime. This article expands on the tutorial and provides instructions on using SQL Managed Instance and joining the IR to a virtual network.
- Monitor an Azure-SSIS IR. This article shows you how to retrieve information about an Azure-SSIS IR and provides descriptions of statuses in the returned information.
- Manage an Azure-SSIS IR. This article shows you how to stop, start, or remove an Azure-SSIS IR. It also shows you how to scale out your Azure-SSIS IR by adding more nodes to the IR.
- Join an Azure-SSIS IR to a virtual network. This article provides conceptual information about joining an Azure-SSIS IR to an Azure virtual network. It also provides steps to use the Azure portal to configure a virtual network and join an Azure-SSIS IR to it.
Integration runtime location
Relationship between factory location and IR location
When you create an instance of Data Factory or a Synapse Workspace, you need to specify its location. The metadata for the instance is stored here, and triggering of the pipeline is initiated from here. Metadata is only stored in the chosen region and will not be stored in other regions.
Meanwhile, a pipeline can access data stores and compute services in other Azure regions to move data between data stores or process data using compute services. This behavior is realized through the globally available IR to ensure data compliance, efficiency, and reduced network egress costs.
The IR Location defines the location of its back-end compute, and where the data movement, activity dispatching, and SSIS package execution are performed. The IR location can be different from the location of the Data Factory it belongs to.
Azure IR location
You can set the location region of an Azure IR, in which case the activity execution or dispatch will happen in the selected region.
The default is to auto-resolve the Azure IR in the public network. With this option:
For copy activity, a best effort is made to automatically detect your sink data store's location, then use the IR in either the same region, if available, or the closest one in the same geography, otherwise; if the sink data store's region is not detectable, the IR in the instance's region is used instead.
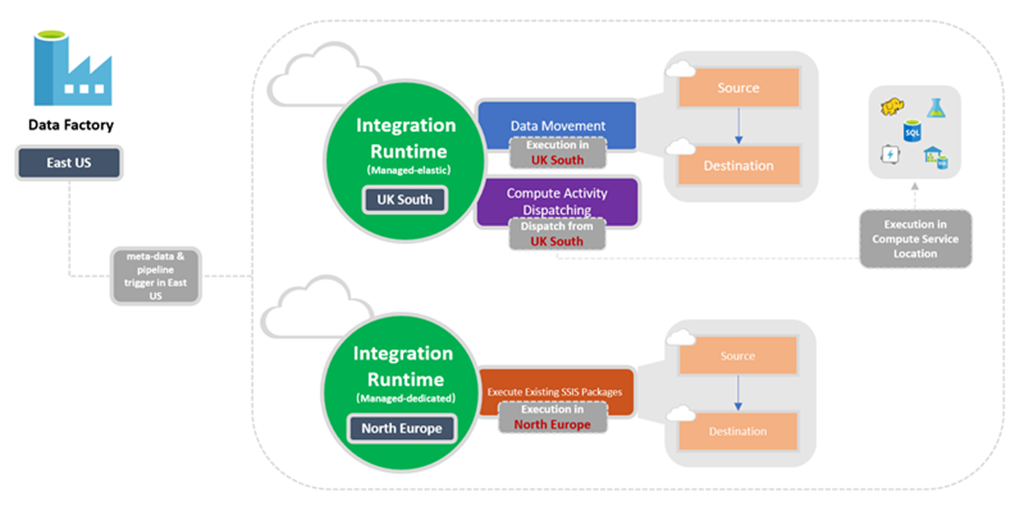
For example, a Data Factory or Synapse Workspace was created in East US,
- When copying data to an Azure Blob in West US, if the blob is detected to be in the West US region, the copy activity is executed on the IR in West US; if region detection fails, the copy activity is executed on the IR in East US.
- When copying data to Salesforce, for which the region is not detectable, the copy activity is executed on the IR in East US.
Tip
If you have strict data compliance requirements and need to ensure that data do not leave a certain geography, you can explicitly create an Azure IR in a certain region and point the Linked Service to this IR using the ConnectVia property. For example, if you want to copy data from a blob in UK South to an Azure Synapse workspace in UK South and want to ensure data does not leave the UK, create an Azure IR in UK South and link both Linked Services to this IR.
For Lookup/GetMetadata/Delete activity execution (Pipeline activities), transformation activity dispatching (External activities), and authoring operations (test connection, browse folder list and table list, and preview data), the IR in the same region as the Data Factory or Synapse Workspace is used.
For Data Flow, the IR in the Data Factory or Synapse Workspace region is used.
Tip
A best practice is to ensure data flows run in the same region as your corresponding data stores when possible. You can either achieve this with auto-resolve for the Azure IR (if the data store location is the same as the Data Factory or Synapse Workspace location), or by creating a new Azure IR instance in the same region as your data stores and then executing the data flows on it.
If you enable Managed Virtual Network with auto-resolve for the Azure IR, the IR in the Data Factory or Synapse Workspace region is used.
You can monitor which IR location takes effect during activity execution in pipeline activity monitoring view in the Data Factory Studio or Synapse Studio, or in the activity monitoring payload.
Self-hosted IR location
The self-hosted IR is logically registered to the Data Factory or Synapse Workspace and the compute used to support its functionalities is provided by you. Therefore there is no explicit location property for self-hosted IR.
When used to perform data movement, the self-hosted IR extracts data from the source and writes into the destination.
Azure-SSIS IR location
Note
Azure-SSIS integration runtimes are not currently supported in Synapse pipelines.
Selecting the right location for your Azure-SSIS IR is essential to achieve high performance in your extract-transform-load (ETL) workflows.
- The location of your Azure-SSIS IR does not need to be the same as the location of your Data Factory, but it should be the same as the location of your own Azure SQL Database or SQL Managed Instance where SSISDB is located. This way, your Azure-SSIS Integration Runtime can easily access the SSISDB without incurring excessive traffic between different locations.
- If you do not have an existing SQL Database or SQL Managed Instance, but you have on-premises data sources/destinations, you should create a new Azure SQL Database or SQL Managed Instance in the same location of a virtual network connected to your on-premises network. This way, you can create your Azure-SSIS IR using the new Azure SQL Database or SQL Managed Instance, and join that virtual network. Everything will be in the same location, minimizing data movement and associated costs, while maximizing performance.
- If the location of your existing Azure SQL Database or SQL Managed Instance is not the same as the location of a virtual network connected to your on-premises network, first create your Azure-SSIS IR using an existing Azure SQL Database or SQL Managed Instance and join another virtual network in the same location. Then configure a virtual network to virtual network connection between the different locations.
The following diagram shows the location settings for Data Factory and its integration runtimes:
Determining which IR to use
If an activity associates with more than one type of integration runtime, it will resolve to one of them. The self-hosted integration runtime takes precedence over the Azure integration runtime in Azure Data Factory or Synapse Workspace instances using a managed virtual network. And the latter takes precedence over the global Azure integration runtime.
For example, one copy activity is used to copy data from source to sink. The global Azure integration runtime is associated with the linked service to source and an Azure integration runtime in an Azure Data Factory managed virtual network associates with the linked service for sink, then the result is that both source and sink linked services use the Azure integration runtime in the Azure Data Factory managed virtual network. But if a self-hosted integration runtime associates the linked service for source, then both source and sink linked service use the self-hosted integration runtime.
Copy activity
The Copy activity requires both source and sink linked services to define the direction of data flow. The following logic is used to determine which integration runtime instance is used to perform the copy:
- Copying between two cloud data sources: if both source and sink linked services are using Azure IR, the regional Azure IR is used if it was specified, or the location of the Azure IR is automatically determined if the auto-resolve IR (default) option was chosen as described in the Integration runtime location section.
- Copying between a cloud data source and a data source in a private network: if either the source or sink linked service points to a self-hosted IR, the copy activity is executed on the self-hosted IR.
- Copying between two data sources in a private network: both the source and sink linked service must point to the same instance of the integration runtime, and that IR is used to execute the copy activity.
Lookup and GetMetadata activity
The Lookup and GetMetadata activity is executed on the integration runtime associated to the data store linked service.
External transformation activity
Each external transformation activity that utilizes an external compute engine has a target compute linked service, which points to an integration runtime. This IR instance determines the location from where that external hand-coded transformation activity is dispatched.
Data Flow activity
Data Flow activities are executed on their associated Azure integration runtime. The Spark compute utilized by Data Flows are determined by the data flow properties in your Azure IR, and are fully managed by the service.
Integration Runtime in CI/CD
Integration runtimes don't change often and are similar across all stages in your CI/CD. Data Factory requires you to have the same name and type of integration runtime across all stages of CI/CD. If you want to share integration runtimes across all stages, consider using a dedicated factory just to contain the shared integration runtimes. You can then use this shared factory in all of your environments as a linked integration runtime type.
Related content
See the following articles:
- Create Azure integration runtime
- Create self-hosted integration runtime
- Create an Azure-SSIS integration runtime. This article expands on the tutorial and provides instructions on using SQL Managed Instance and joining the IR to a virtual network.