This article answers common questions about backing up SAP HANA databases using the Azure Backup service.
Backup
How many backups are supported per day?
You can have one schedule full backup and multiple on-demand backups in a day.
| Backup types | Scheduled backup | On-demand backups |
|---|---|---|
| Full | Only one supported in a day. | Multiple times in a day supported. |
| Delta (differential/incremental) | Only one supported in a day. Note Delta backups can be scheduled only when no full backup is scheduled for the particular day. Also, only one delta backup type (differential/ incremental) can be scheduled in a backup policy. |
Multiple times in a day supported. |
Where can I find backup related alerts?
Today, successful backup jobs don’t generate alerts. Alerts are generated only for backup jobs that fail. Learn how to use the Azure portal to view Backup alerts.
How do I check if my backup (scheduled/on-demand) is executed successfully?
You can check the status of your backups (scheduled/on-demand) from any of the following locations:
Backup jobs: Azure Backup shows all manually triggered jobs in the Backup jobs section in the Azure portal.
The jobs you see in the Azure portal includes database discovery and registering operations, and backup and restore operations. Scheduled jobs, including log backups aren't shown in this section. Manually triggered backups from the SAP HANA native clients (Studio/Cockpit/DBA Cockpit), are also not shown here.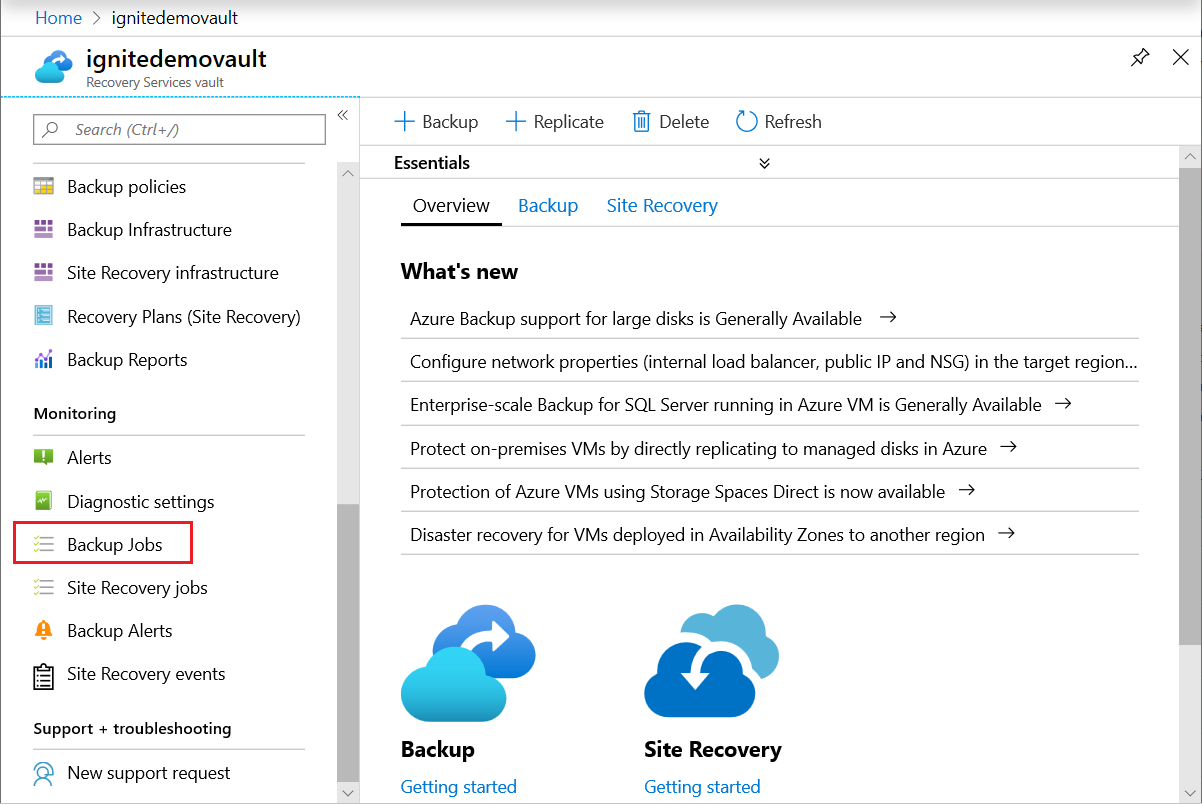
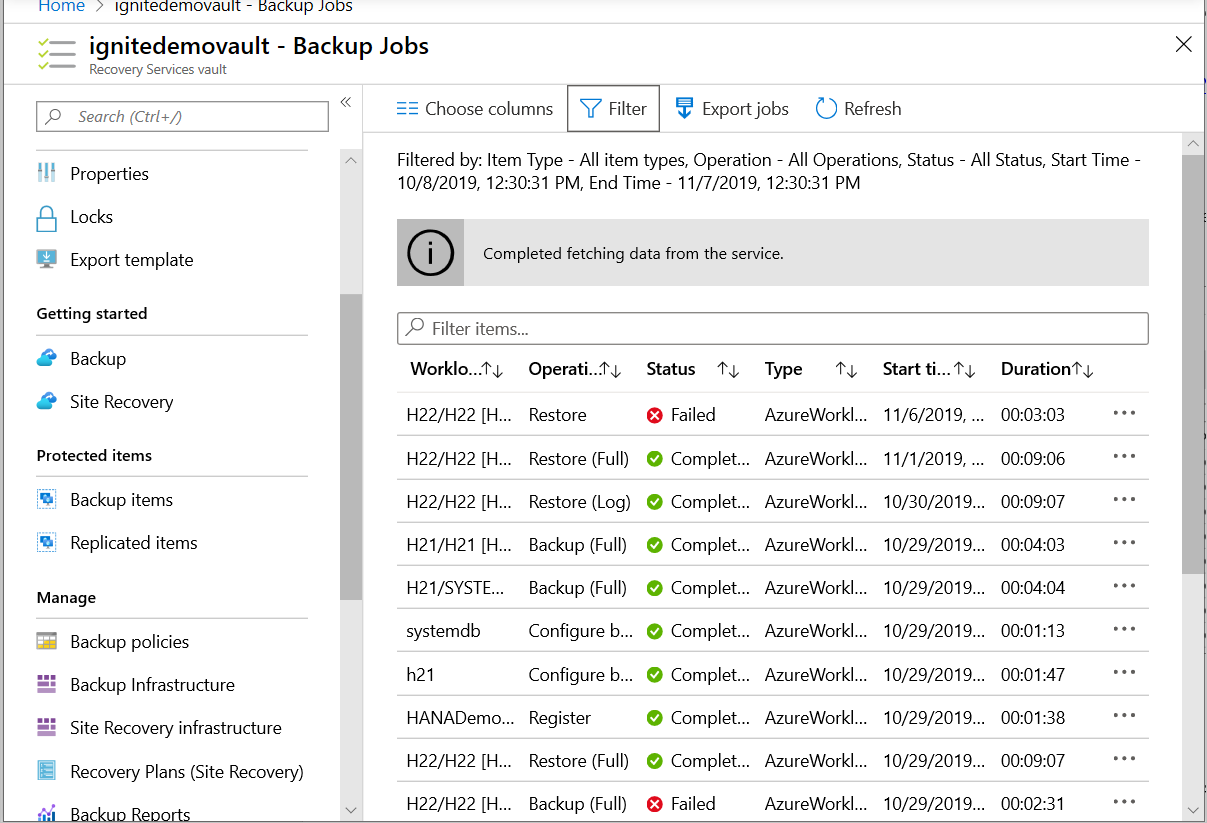
Backup alerts: Alerts help you monitor backups of SAP HANA databases. These help you to focus on the required events, thus eliminating the effort to frequently check multitude of events that a backup generates. For more details, see View backup alerts.
Backup Reports: Reports are another way to view the status of your backup jobs. Your reports will be as follows:
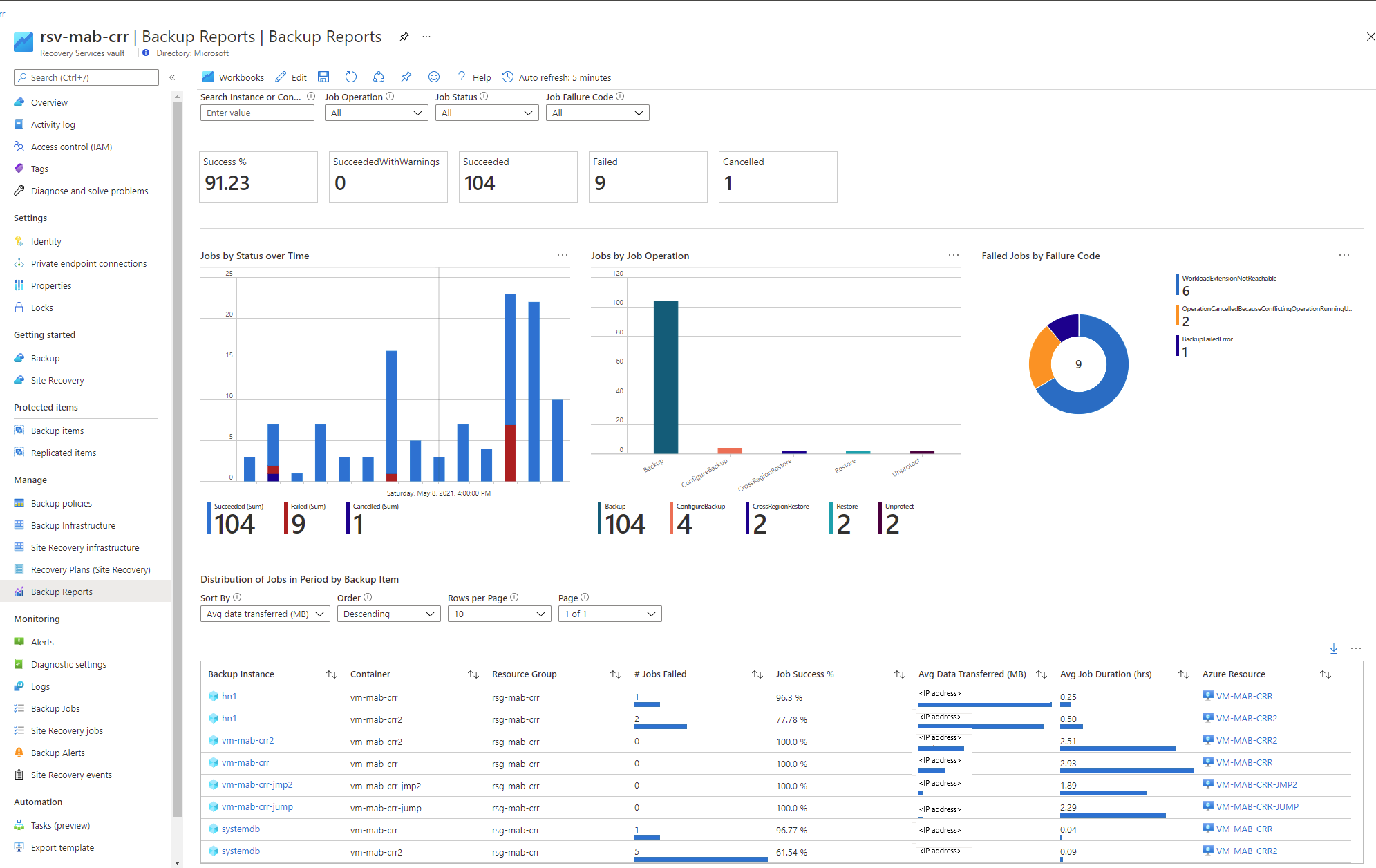
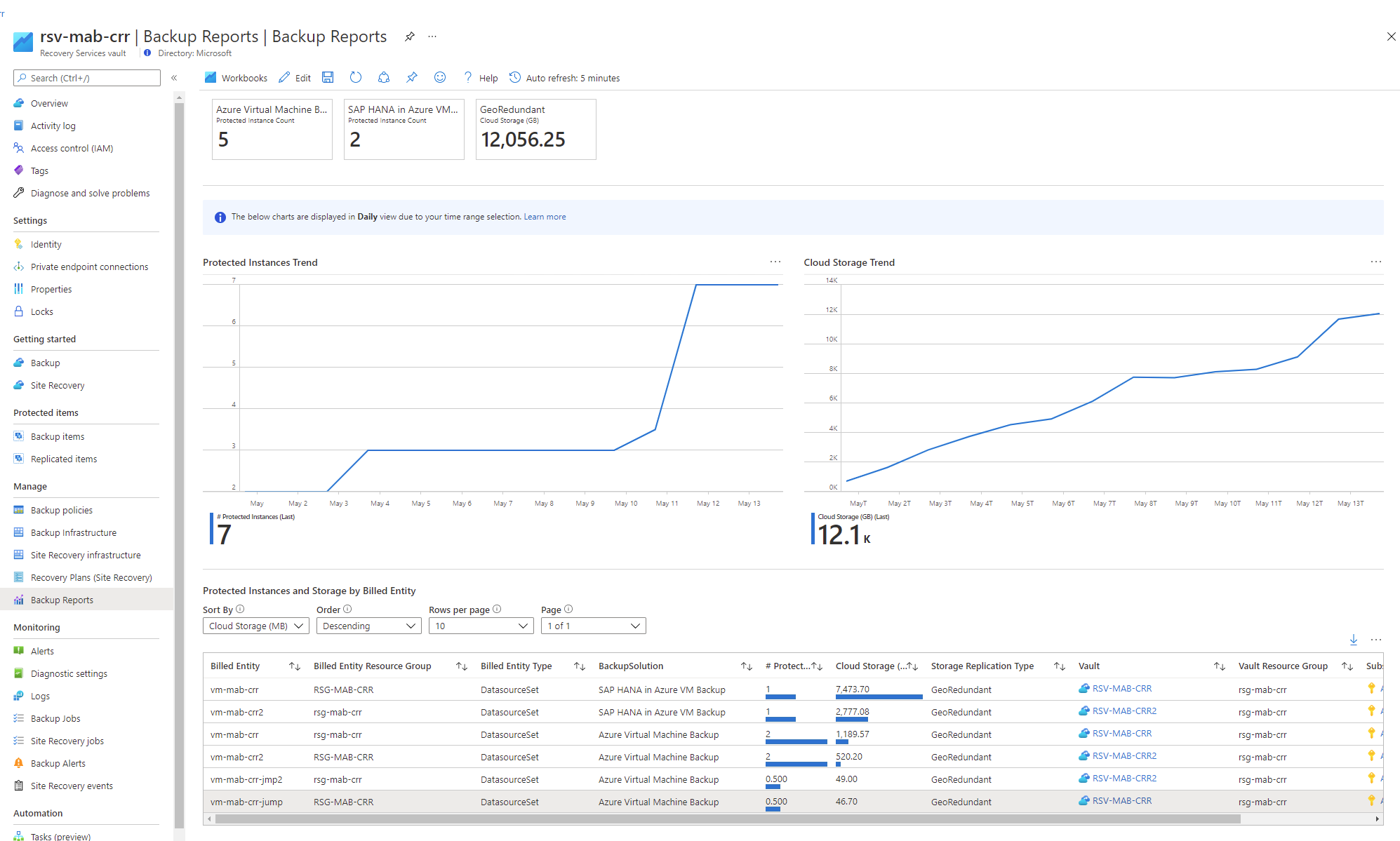
Learn about how to configure Azure Backup reports.
SAP HANA Native clients: If you're an SAP HANA customer, you can also use HANA Studio, one of the most common HANA clients. In this client, navigate to Backup Console -> Backup Catalog to see the Backup status.
Can I see scheduled backup jobs in the Backup Jobs menu?
The Backup Job menu will only show on-demand backup jobs that are either in progress, have succeeded or failed. For scheduled jobs, use Azure Monitor.
What’s the retention period of Auto-heal full backups triggered due to the LSNValidation errors?
Azure Backup doesn’t set an explicit retention period on the Auto-heal full backups. This backup is retained until the time you retain the dependent Delta (differential or incremental) and Log backups. Once you delete the last dependent backup on this Auto-heal backup, the Auto-heal backup is also deleted.
Can a full backup and a log backup run simultaneously?
Yes, a full backup and a log backup can run simultaneously. This instance occurs in one of the following ways:
- Full backup is in progress and a log backup is triggered: The log backup should succeed irrespective of an ongoing full backup. Unless the full backup that's triggered was a remedial full to handle any LSN chain-break.
- Log backup is in progress, and a full backup is triggered: Both backups should run simultaneously and succeed.
Are future databases automatically added for backup?
No, this isn't currently supported.
If I delete a database from an instance, what will happen to the backups?
If a database is dropped from an SAP HANA instance, the database backups are still attempted. This implies that the deleted database begins to show up as unhealthy under Backup Items and is still protected. The correct way to stop protecting this database is to perform Stop Backup with delete data on this database.
If I change the name of the database after it has been protected, what will the behavior be?
A renamed database is treated as a new database. Therefore, the service will treat this situation as if the database weren't found and will fail the backups. The renamed database will appear as a new database and must be configured for protection.
How do I get started with backing up my SAP HANA databases using Azure Backup?
Refer to the tutorial for a step-by-step guide to get started with Azure Backup for SAP HANA databases. You can also use CLI to configure and manage backups.
Are there any prerequisites for backing up SAP HANA databases using Azure Backup?
Refer to the prerequisites for using Azure Backup with SAP HANA.
Will backups work after migrating SAP HANA from SDC to MDC?
Refer to this section of the troubleshooting guide.
How do I ensure that Backups continue after upgrading my HANA instance within the same HANA version?
Refer to this section in the troubleshooting guide.
Can I set up the backup of Azure HANA against a virtual IP (load balancer) and not a virtual machine?
Currently we don't have the capability to set up the solution against a virtual IP or Proxy. We need a virtual machine to execute the solution.
How can I move on-demand backups (triggered from HANA native clients) to the local file system instead of the Azure vault?
You can trigger an on-demand backup using SAP HANA native clients to local file-system instead of Backint. Learn more how to manage operations using SAP native clients.
How can I manage or clean up the HANA catalog for database with the Azure Backup enabled?
You can prune the HANA catalog using SAP recommended methods, such as BACKUP CATALOG DELETE statements or HANA Studio/Cockpit. Learn more how to manage operations using SAP native clients.
What happens if I don’t Stop protection (with retain data) on the secondary/inactive node on the HSR set-up?
For HANA system replication (HSR), the secondary node doesn’t accept any connections at all. Once the backup is configured, the Azure Backup service pings periodically and fails. Sometimes, these failed attempts reflect on the primary node. After multiple failures, the user is locked, and then the primary node starts to fail with ODBCConnectionError.
We’ve observed that all users don’t experience this issue. We recommend you/SAP to investigate the cause of users getting locked in the primary node when user connection fails on the secondary node.Once you run the pre-registration script, the user information is updated with new password on the primary node. Then the connection to attempt backup will be re-established. But, you might again experience the same scenario.
Also, the backups (full backups) that fail on the secondary node create alerts.
To avoid the above issues, we recommend you to stop protection for a node after it becomes secondary (so that connections aren’t attempted and user is not locked) and resume protection on it, once it becomes primary. If you don’t face this locking situation on their HSR setups and are comfortable with alerts being raised, you can configure backups on both the nodes so that the service handles the take-over and fail-back.
What’s the backup and restore throughput performance that Azure Backup provides and how to set up my HANA system to use this maximum throughput?
Refer to the backup and restore throughput performance that Azure Backup provides for HANA workloads.
To set up your HANA system to leverage the improved performance, use the following resources:
- Select a disk type for Azure IaaS VMs - managed disks
- Performance tiers for Azure managed disks
- M-series
- SAP HANA Azure virtual machine storage configurations
Note
You can also limit the backup throughput performance. Learn more.
Can I change the backup performance by editing the "parallel_backup_using_backint" property in SAP HANA "global.ini" file?
Currently, Azure Backup for SAP HANA accepts 1 as the value of the parallel_backup_using_backint property. However, Azure Backup splits that single stream in multiple streams for better performance.
Does HSR support database instances backup using snapshots?
Currently, only Backint-based backups are supported for HSR. Snapshots aren't yet.
Do I need to run the instance re-detection only on the server marked "Ready", or also on the one marked "Not Ready"?
You need to run the instance re-detection on the server that is marked "Not Ready" to update its status.
Connecting the Azure environment to on-premises network using ExpressRoute and configured forced tunneling directs all the traffic to the on-premises network. How can I configure the settings so that Azure SAP HANA Server workload backup traffic will not pass through the on-premises network and directly connect to Recovery Services vault?
During the backup operation, the backup job connects to three Service Endpoints - AzureBackup, AzureStorage, and Microsoft Entra ID. In this scenario, we recommend you to configure the Service Endpoint to AzureStorage`, which helps to send the traffic from the Virtual Network to the Storage directly. For Azure Backup and Microsoft Entra ID, you can configure UDR over service tags so that the traffic travels to backbone network instead of on-premises.
Why West US region node is showing under East US region Recovery Services vault?
The Recovery Services vault shows all the nodes that are part of the SAP HANA System Replication. All the nodes are listed here as per the hdbnsutil output. However as per the expected behavior, only configured node in this vault is registered.
When a file starting with "hdbbackint" under "/var/tmp generated" and how it's used?
When you trigger the backup job using the hdbbackint Backint agent, it writes information to the /var/tmp directory. For example, if an error occurs during the backup process, the error message is written to a file in the /var/tmp directory. The file name gets created in the format hdbbackint_<SID>.<random_string>, where <SID> is the System ID of the SAP HANA instance and <random_string> is a randomly generated string.
What happens if I delete the hdbbackint file in the /var/tmp?
The backup process is not affected if you delete the hdbbackint file in the /var/tmp directory. However, it might remove any error messages that were written to the file during the backup process.
Restore
How many restore are supported per day?
You can perform a maximum of 10 restores per HANA system or instance in a day. Note that if a restore is canceled or fails, it's also considered as a restore attempt.
Why can't I see the HANA system I want my database to be restored to?
Check if all the prerequisites for the restore to target SAP HANA instance are met. For more information, see Prerequisites - Restore SAP HANA databases in Azure VM.
Why is the Overwrite DB restore failing for my database?
Ensure that the Force Overwrite option is selected while restoring.
Why do I see the "Source and target systems for restore are incompatible" error?
Refer to the SAP HANA Note 1642148 to see what restore types are currently supported.
Can I use a backup of a database running on SLES to restore to an RHEL HANA system or vice versa?
Yes, you can use streaming backups triggered on a HANA database running on SLES to restore it to an RHEL HANA system and vice versa. That is, cross OS restore is possible using streaming backups. However, you'll have to ensure that the HANA system you want to restore to, and the HANA system used for restore, are both compatible for restore according to SAP. Refer to SAP HANA Note 1642148 to see which restore types are compatible.
Can I download only a subset of files during restore as files?
Yes, you can download files partially as documented here.
Do I have to disable the HSR on SAP HANA native environment during "SYSTEMDB + Tenant DB" restore for HSR setup?
Yes, you need to disable the HANA System Replication (HSR) on target system, and then perform restore. You can't restore an HSR-enabled system, as per SAP.
Policy
Different options available during creation of a new policy for SAP HANA backup
Before creating a policy, you should be clear on the requirements of RPO and RTO and its relevant cost implications.
RPO (Recovery-point-objective) indicates how much data loss is acceptable for the user/customer. This is determined by the log backup frequency. More frequent log backups indicate lower RPO and the minimum value supported by Azure Backup service is 15 minutes. So log backup frequency can be 15 minutes or higher.
RTO (Recovery-time-objective) indicates how fast the data should be restored to the last available point-in-time after a data loss scenario. This depends on the recovery strategy employed by HANA, which is usually dependent on how many files are required for restore. This has cost implications as well, and the following table should help in understanding all scenarios and their implications.
| Backup policy | RTO | Cost |
|---|---|---|
| Daily Full + logs | Fastest, since we need only one full copy + required logs for point-in-time restore | Costliest option since a full copy is taken daily and so more and more data is accumulated in backend until the retention time |
| Weekly Full + daily differential + logs | Slower than the above option, but faster than the next option since we require one full copy + one differential copy + logs for point-in-time restore | Less expensive option since the daily differential is usually smaller than full and a full copy is taken only once a week |
| Weekly Full + daily incremental + logs | Slowest since we need one full copy + 'n' incrementals + logs for point-in-time recovery | Least expensive option since the daily incremental will be smaller than differential and a full copy is taken only weekly |
Note
The above options are the most common, but not the only options. For example, you can have a weekly full backup + differentials twice a week + logs.
Therefore, you can select the policy variant based on RPO and RTO objectives and cost considerations.
Impact of modifying a policy
A few principles should be kept in mind when determining the impact of switching a backup item's policy from Policy 1 (P1) to Policy 2 (P2) or of editing Policy 1 (P1).
- All changes are also applied retroactively. The latest backup policy is applied on the recovery points taken earlier as well. For example, assume that the daily full retention is 30 days and 10 recovery points were taken according to the currently active policy. If the daily full's retention is changed to 10 days, then the previous point's expiry time is also recalculated as start time + 10 days and deleted if they're expired.
- The scope of change also includes day of backup, type of backup along with retention. For example: If a policy is changed from daily full to weekly full on Sundays, all earlier fulls that aren't on Sundays will be marked for deletion.
- A parent isn't deleted until the child is active/not-expired. Every backup type has an expiration time according to the currently active policy. But a full backup type is considered as parent to subsequent 'differentials', 'incrementals' and 'logs'. A 'differential' and a 'log' aren't parents to anyone else. An 'incremental' can be a parent to subsequent 'incremental'. Even if a 'parent' is marked for deletion, it's not actually deleted if the child 'differentials' or 'logs' aren't expired. For example, if a policy is changed from daily full to weekly full on Sundays, all earlier fulls that aren't on Sundays will be marked for deletion. But they aren't actually deleted until the logs that were taken daily earlier are expired. In other words, they're retained according to the latest log duration. Once the logs expire, both the logs and these fulls will be deleted.
With these principles, you can read the following table to understand the implications of a policy change.
| Old policy/ New policy | Daily fulls + logs | Weekly fulls + daily differentials + logs | Weekly fulls + daily incrementals + logs |
|---|---|---|---|
| Daily fulls + logs | - | The previous fulls that aren't on the same day of the week are marked for deletion but kept until the log retention period | The previous fulls that aren't on the same day of the week are marked for deletion but kept until the log retention period |
| Weekly fulls + daily differentials + logs | The previous weekly fulls retention is recalculated as per latest policy. The previous differentials are immediately deleted | - | The previous differentials are immediately deleted |
| Weekly fulls + daily incrementals + logs | The previous weekly fulls retention is recalculated as per latest policy. The previous incrementals are immediately deleted | The previous incrementals are immediately deleted | - |
How can I manage the size of /opt/msawb folder created in the root partition?
You could manage the space in the root folder using one of the following options:
- Create an own LV for /opt/msawb.
- Create a soft link/symlink to another location/folder on the same/different disk.
- Increase the space on the root partition.
Next steps
- Learn how to back up SAP HANA databases running on Azure VMs.
- Learn how to troubleshoot SAP HANA database backup.