Accelerate real-time big data analytics using the Spark connector
Applies to: ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Note
As of Sep 2020, this connector is not actively maintained. However, Apache Spark Connector for SQL Server and Azure SQL is now available, with support for Python and R bindings, an easier-to use interface to bulk insert data, and many other improvements. We strongly encourage you to evaluate and use the new connector instead of this one. The information about the old connector (this page) is only retained for archival purposes.
The Spark connector enables databases in Azure SQL Database, Azure SQL Managed Instance, and SQL Server to act as the input data source or output data sink for Spark jobs. It allows you to utilize real-time transactional data in big data analytics and persist results for ad hoc queries or reporting. Compared to the built-in JDBC connector, this connector provides the ability to bulk insert data into your database. It can outperform row-by-row insertion with 10x to 20x faster performance. The Spark connector supports authentication with Microsoft Entra ID (formerly Azure Active Directory) to connect to Azure SQL Database and Azure SQL Managed Instance, allowing you to connect your database from Azure Databricks using your Microsoft Entra account. It provides similar interfaces with the built-in JDBC connector. It is easy to migrate your existing Spark jobs to use this new connector.
Note
Microsoft Entra ID was previously known as Azure Active Directory (Azure AD).
Download and build a Spark connector
The GitHub repo for the old connector previously linked to from this page is not actively maintained. Instead, we strongly encourage you to evaluate and use the new connector.
Official supported versions
| Component | Version |
|---|---|
| Apache Spark | 2.0.2 or later |
| Scala | 2.10 or later |
| Microsoft JDBC Driver for SQL Server | 6.2 or later |
| Microsoft SQL Server | SQL Server 2008 or later |
| Azure SQL Database | Supported |
| Azure SQL Managed Instance | Supported |
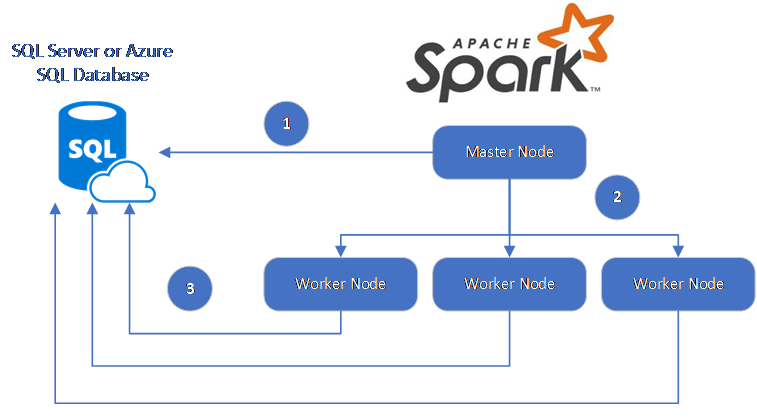
The Spark connector utilizes the Microsoft JDBC Driver for SQL Server to move data between Spark worker nodes and databases:
The dataflow is as follows:
- The Spark master node connects to databases in SQL Database or SQL Server and loads data from a specific table or using a specific SQL query.
- The Spark master node distributes data to worker nodes for transformation.
- The Worker node connects to databases that connect to SQL Database and SQL Server and writes data to the database. User can choose to use row-by-row insertion or bulk insert.
The following diagram illustrates the data flow.
Build the Spark connector
Currently, the connector project uses maven. To build the connector without dependencies, you can run:
- mvn clean package
- Download the latest versions of the JAR from the release folder
- Include the SQL Database Spark JAR
Connect and read data using the Spark connector
You can connect to databases in SQL Database and SQL Server from a Spark job to read or write data. You can also run a DML or DDL query in databases in SQL Database and SQL Server.
Read data from Azure SQL and SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Read data from Azure SQL and SQL Server with specified SQL query
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"queryCustom" -> "SELECT TOP 100 * FROM dbo.Clients WHERE PostalCode = 98074" //Sql query
"user" -> "username",
"password" -> "*********",
))
//Read all data in table dbo.Clients
val collection = sqlContext.read.sqlDB(config)
collection.show()
Write data to Azure SQL and SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Aquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
Run DML or DDL query in Azure SQL and SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
Connect from Spark using Microsoft Entra authentication
You can connect to SQL Database and SQL Managed Instance using Microsoft Entra authentication. Use Microsoft Entra authentication to centrally manage identities of database users and as an alternative to SQL authentication.
Connecting using ActiveDirectoryPassword Authentication Mode
Setup requirement
If you are using the ActiveDirectoryPassword authentication mode, you need to download microsoft-authentication-library-for-java and its dependencies, and include them in the Java build path.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"authentication" -> "ActiveDirectoryPassword",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Connecting using an access token
Setup requirement
If you are using the access token-based authentication mode, you need to download microsoft-authentication-library-for-java and its dependencies, and include them in the Java build path.
See Use Microsoft Entra authentication to learn how to get an access token to your database in Azure SQL Database or Azure SQL Managed Instance.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"accessToken" -> "access_token",
"hostNameInCertificate" -> "*.database.windows.net",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Write data using bulk insert
The traditional jdbc connector writes data into your database using row-by-row insertion. You can use the Spark connector to write data to Azure SQL and SQL Server using bulk insert. It significantly improves the write performance when loading large data sets or loading data into tables where a columnstore index is used.
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.
Next steps
If you haven't already, download the Spark connector from azure-sqldb-spark GitHub repository and explore the additional resources in the repo:
You might also want to review the Apache Spark SQL, DataFrames, and Datasets Guide and the Azure Databricks documentation.