Resource management in Azure SQL Database
Applies to: ![]() Azure SQL Database
Azure SQL Database
This article provides an overview of resource management in Azure SQL Database. It provides information on what happens when resource limits are reached, and describes resource governance mechanisms that are used to enforce these limits.
For specific resource limits per pricing tier for single databases, refer to either:
For elastic pool resource limits, refer to either:
For Azure Synapse Analytics dedicated SQL pool limits, refer to:
Subscription vCore limits per region
Starting March 2024, subscriptions have the following vCore limits per region per subscription:
| Subscription type | Default vCore limits |
|---|---|
| Enterprise Agreement (EA) | 2000 |
| Free trials | 10 |
| Microsoft for startups | 100 |
| MSDN / MPN / Imagine / AzurePass / Azure for Students | 40 |
| Pay-as-you-go (PAYG) | 150 |
Consider the following:
- These limits are applicable to new and existing subscriptions.
- Databases and elastic pools provisioned with the DTU purchasing model are counted against the vCore quota, and vice-versa. Each vCore consumed is considered equivalent to 100 DTUs consumed for the server-level quota.
- Default limits include both the vCores configured for provisioned compute databases / elastic pools, and the max vCores configured for serverless databases.
- You can use the Subscription Usages - Get REST API call to determine your current vCore usage for your subscription.
- To request a higher vCore quota than the default, submit a new support request in the Azure portal. For more information, see Request quota increases for Azure SQL Database and SQL Managed Instance.
Logical server limits
| Resource | Limit |
|---|---|
| Databases per logical server | 5000 |
| Default number of logical servers per subscription in a region | 250 |
| Max number of logical servers per subscription in a region | 250 |
| Max elastic pools per logical server | Limited by number of DTUs or vCores. For example, if each pool is 1000 DTUs, then a server can support 54 pools. |
Important
As the number of databases approaches the limit per logical server, the following can occur:
- Increasing latency in running queries against the
masterdatabase. This includes views of resource utilization statistics such assys.resource_stats. - Increasing latency in management operations and rendering portal viewpoints that involve enumerating databases in the server.
What happens when resource limits are reached
Compute CPU
When database compute CPU utilization becomes high, query latency increases, and queries can even time out. Under these conditions, queries might be queued by the service and are provided resources for execution as resources become free.
If you observe high compute utilization, mitigation options include:
- Increasing the compute size of the database or elastic pool to provide the database with more compute resources. See Scale single database resources and Scale elastic pool resources.
- Optimizing queries to reduce CPU resource utilization of each query. For more information, see Query Tuning/Hinting.
Storage
When data space used reaches the maximum data size limit, either at the database level or at the elastic pool level, inserts and updates that increase data size fail, and clients receive an error message. SELECT and DELETE statements remain unaffected.
In Premium and Business Critical service tiers, clients also receive an error message if combined storage consumption by data, transaction log, and tempdb for a single database or an elastic pool exceeds maximum local storage size. For more information, see Storage space governance.
If you observe high storage space utilization, mitigation options include:
- Increase maximum data size of the database or elastic pool, or scale up to a service objective with a higher maximum data size limit. See Scale single database resources and Scale elastic pool resources.
- If the database is in an elastic pool, then alternatively the database can be moved outside of the pool, so that its storage space isn't shared with other databases.
- Shrink a database to reclaim unused space. For more information, see Manage file space for databases.
- In elastic pools, shrinking a database provides more storage for other databases in the pool.
- Check if high space utilization is due to a spike in the size of Persistent Version Store (PVS). PVS is a part of each database, and is used to implement Accelerated database recovery. To determine current PVS size, see Troubleshoot accelerated database recovery. A common reason for large PVS size is a transaction that is open for a long time (hours), preventing cleanup of row older versions in PVS.
- For databases and elastic pools in Premium and Business Critical service tiers that consume large amounts of storage, you might receive an out-of-space error even though used space in the database or elastic pool is below its maximum data size limit. This can happen if
tempdbor transaction log files consume a large amount of storage toward the maximum local storage limit. Fail over the database or elastic pool to resettempdbto its initial smaller size, or shrink transaction log to reduce local storage consumption.
Sessions, workers, and requests
Sessions, workers, and requests are defined as follows:
- A session represents a process connected to the database engine.
- A request is the logical representation of a query or batch. A request is issued by a client connected to a session. Over time, multiple requests can be issued on the same session.
- A worker thread, also known as a worker or thread, is a logical representation of an operating system thread. A request can have many workers when executed with a parallel query execution plan, or a single worker when executed with a serial (single threaded) execution plan. Workers are also required to support activities outside of requests: for example, a worker is required to process a login request as a session connects.
For more information about these concepts, see the Thread and task architecture guide.
The maximum number of workers is determined by the service tier and compute size. New requests are rejected when session or worker limits are reached, and clients receive an error message. While the number of connections can be controlled by the application, the number of concurrent workers is often harder to estimate and control. This is especially true during peak load periods when database resource limits are reached and workers pile up due to longer running queries, large blocking chains, or excessive query parallelism.
Note
The initial offering of Azure SQL Database supported only single threaded queries. At that time, the number of requests was always equivalent to the number of workers. Error message 10928 in Azure SQL Database contains the wording The request limit for the database is *N* and has been reached for backward compatibility purposes only. The limit reached is actually the number of workers.
If your max degree of parallelism (MAXDOP) setting is equal to zero or is greater than one, the number of workers can be much higher than the number of requests, and the limit might be reached much sooner than when MAXDOP is equal to one.
- Learn more about error 10928 in Resource governance errors.
- Learn more about request limit exhaustion in Errors 10928 and 10936.
You can mitigate approaching or hitting worker or session limits by:
- Increasing the service tier or compute size of the database or elastic pool. See Scale single database resources and Scale elastic pool resources.
- Optimizing queries to reduce resource utilization if the cause of increased workers is contention for compute resources. For more information, see Query Tuning/Hinting.
- Optimizing the query workload to reduce the number of occurrences and duration of query blocking. For more information, see Understand and resolve blocking problems.
- Reducing the MAXDOP setting when appropriate.
Find worker and session limits for Azure SQL Database by service tier and compute size:
- Resource limits for single databases using the vCore purchasing model
- Resource limits for elastic pools using the vCore purchasing model
- Resource limits for single databases using the DTU purchasing model
- Resource limits for elastic pools using the DTU purchasing model
Learn more about troubleshooting specific errors for session or worker limits in Resource governance errors.
External connections
The number of concurrent connections to external endpoints done via sp_invoke_external_rest_endpoint are capped to 10% of worker threads, with a hard cap of max 150 workers.
Memory
Unlike other resources (CPU, workers, storage), reaching the memory limit doesn't negatively affect query performance, and doesn't cause errors and failures. As described in detail in Memory management architecture guide, the database engine often uses all available memory, by design. Memory is used primarily for caching data, to avoid slower storage access. Thus, higher memory utilization usually improves query performance due to faster reads from memory, rather than slower reads from storage.
After database engine startup, as the workload starts reading data from storage, the database engine aggressively caches data in memory. After this initial ramp-up period, it's common and expected to see the avg_memory_usage_percent and avg_instance_memory_percent columns in sys.dm_db_resource_stats, and the sql_instance_memory_percent Azure Monitor metric to be close to 100%, particularly for databases that aren't idle, and don't fully fit in memory.
Note
The sql_instance_memory_percent metric reflects the total memory consumption by the database engine. This metric might not reach 100% even when high intensity workloads are running. This is because a small portion of available memory is reserved for critical memory allocations other than the data cache, such as thread stacks and executable modules.
Besides the data cache, memory is used in other components of the database engine. When there's demand for memory and all available memory has been used by the data cache, the database engine reduces data cache size to make memory available to other components, and dynamically grows data cache when other components release memory.
In rare cases, a sufficiently demanding workload might cause an insufficient memory condition, leading to out-of-memory errors. Out-of-memory errors can happen at any level of memory utilization between 0% and 100%. Out-of-memory errors are more likely to occur on smaller compute sizes that have proportionally smaller memory limits, and / or with workloads using more memory for query processing, such as in dense elastic pools.
If you get out-of-memory errors, mitigation options include:
- Review the details of the OOM condition in sys.dm_os_out_of_memory_events.
- Increasing the service tier or compute size of the database or elastic pool. See Scale single database resources and Scale elastic pool resources.
- Optimizing queries and configuration to reduce memory utilization. Common solutions are described in the following table.
| Solution | Description |
|---|---|
| Reduce the size of memory grants | For more information about memory grants, see the Understanding SQL Server memory grants blog post. A common solution to avoid excessively large memory grants is to keep statistics up to date. This results in more accurate estimates of memory consumption by the query engine, avoiding large memory grants. By default, in databases using compatibility level 140 and above, the database engine can automatically adjust memory grant size using Batch mode memory grant feedback. Similarly, in databases using compatibility level 150 and above, the database engine also uses Row mode memory grant feedback, for more common row mode queries. This built-in functionality helps avoid out-of-memory errors due to large memory grants. |
| Reduce the size of query plan cache | The database engine caches query plans in memory, to avoid compiling a query plan for every query execution. To avoid query plan cache bloat caused by caching plans that are only used once, make sure to use parameterized queries, and consider enabling OPTIMIZE_FOR_AD_HOC_WORKLOADS database-scoped configuration. |
| Reduce the size of lock memory | The database engine uses memory for locks. When possible, avoid large transactions that might acquire a large number of locks and cause high lock memory consumption. |
Resource consumption by user workloads and internal processes
Azure SQL Database requires compute resources to implement core service features such as high availability and disaster recovery, database backup and restore, monitoring, Query Store, Automatic tuning, etc. The system sets aside a limited portion of the overall resources for these internal processes using resource governance mechanisms, making the remainder of resources available for user workloads. At times when internal processes aren't using compute resources, the system makes them available to user workloads.
Total CPU and memory consumption by user workloads and internal processes is reported in the sys.dm_db_resource_stats and sys.resource_stats views, in avg_instance_cpu_percent and avg_instance_memory_percent columns. This data is also reported via the sql_instance_cpu_percent and sql_instance_memory_percent Azure Monitor metrics, for single databases and elastic pools at the pool level.
Note
The sql_instance_cpu_percent and sql_instance_memory_percent Azure Monitor metrics are available since July 2023. They are fully equivalent to the previously available sqlserver_process_core_percent and sqlserver_process_memory_percent metrics, respectively. The latter two metrics remain available, but will be removed in the future. To avoid an interruption in database monitoring, do not use the older metrics.
These metrics are not available for databases using Basic, S1, and S2 service objectives. The same data is available in the following dynamic management views.
CPU and memory consumption by user workloads in each database is reported in the sys.dm_db_resource_stats and sys.resource_stats views, in avg_cpu_percent and avg_memory_usage_percent columns. For elastic pools, pool-level resource consumption is reported in the sys.elastic_pool_resource_stats view (for historical reporting scenarios) and in sys.dm_elastic_pool_resource_stats for real-time monitoring. User workload CPU consumption is also reported via the cpu_percent Azure Monitor metric, for single databases and elastic pools at the pool level.
A more detailed breakdown of recent resource consumption by user workloads and internal processes is reported in the sys.dm_resource_governor_resource_pools_history_ex and sys.dm_resource_governor_workload_groups_history_ex views. For details on resource pools and workload groups referenced in these views, see Resource governance. These views report on resource utilization by user workloads and specific internal processes in the associated resource pools and workload groups.
Tip
When monitoring or troubleshooting workload performance, it's important to consider both user CPU consumption (avg_cpu_percent, cpu_percent), and total CPU consumption by user workloads and internal processes (avg_instance_cpu_percent,sql_instance_cpu_percent). Performance might be noticeably affected if either of these metrics is in the 70-100% range.
User CPU consumption is defined as a percentage toward the user workload CPU limit in each service objective. Likewise, total CPU consumption is defined as the percentage toward the CPU limit for all workloads. Because the two limits are different, the user and total CPU consumption are measured on different scales, and aren't directly comparable with each other.
If user CPU consumption reaches 100%, it means that the user workload is fully using the CPU capacity available to it in the selected service objective, even if total CPU consumption remains below 100%.
When total CPU consumption reaches the 70-100% range, it's possible to see user workload throughput flattening and query latency increasing, even if user CPU consumption remains significantly below 100%. This is more likely to occur when using smaller service objectives with a moderate allocation of compute resources, but relatively intense user workloads, such as in dense elastic pools. This can also occur with smaller service objectives when internal processes temporarily require more resources, for example when creating a new replica of the database, or backing up the database.
Likewise, when user CPU consumption reaches the 70-100% range, user workload throughput flattens and query latency increases, even if total CPU consumption is well below its limit.
When either user CPU consumption or total CPU consumption is high, mitigation options are the same as noted in the Compute CPU section, and include service objective increase and/or user workload optimization.
Note
Even on a completely idle database or elastic pool, total CPU consumption is never at zero because of background database engine activities. It can fluctuate in a wide range depending on the specific background activities, compute size, and previous user workload.
Resource governance
To enforce resource limits, Azure SQL Database uses a resource governance implementation that is based on SQL Server Resource Governor, modified and extended to run in the cloud. In SQL Database, multiple resource pools and workload groups, with resource limits set at both pool and group levels, provide a balanced Database-as-a-Service. User workload and internal workloads are classified into separate resource pools and workload groups. User workload on the primary and readable secondary replicas, including geo-replicas, is classified into the SloSharedPool1 resource pool and UserPrimaryGroup.DBId[N] workload groups, where [N] stands for the database ID value. In addition, there are multiple resource pools and workload groups for various internal workloads.
In addition to using Resource Governor to govern resources within the database engine, Azure SQL Database also uses Windows Job Objects for process level resource governance, and Windows File Server Resource Manager (FSRM) for storage quota management.
Azure SQL Database resource governance is hierarchical in nature. From top to bottom, limits are enforced at the OS level and at the storage volume level using operating system resource governance mechanisms and Resource Governor, then at the resource pool level using Resource Governor, and then at the workload group level using Resource Governor. Resource governance limits in effect for the current database or elastic pool are reported in the sys.dm_user_db_resource_governance view.
Data I/O governance
Data I/O governance is a process in Azure SQL Database used to limit both read and write physical I/O against data files of a database. IOPS limits are set for each service level to minimize the "noisy neighbor" effect, to provide resource allocation fairness in a multitenant service, and to stay within the capabilities of the underlying hardware and storage.
For single databases, workload group limits are applied to all storage I/O against the database. For elastic pools, workload group limits apply to each database in the pool. Additionally, the resource pool limit additionally applies to the cumulative I/O of the elastic pool. In tempdb, I/O is subject to workload group limits, except for Basic, Standard, and General Purpose service tier, where higher tempdb I/O limits apply. In general, resource pool limits might not be achievable by the workload against a database (either single or pooled), because workload group limits are lower than resource pool limits and limit IOPS/throughput sooner. However, pool limits can be reached by the combined workload against multiple databases in the same pool.
For example, if a query generates 1000 IOPS without any I/O resource governance, but the workload group maximum IOPS limit is set to 900 IOPS, the query can't generate more than 900 IOPS. However, if the resource pool maximum IOPS limit is set to 1500 IOPS, and the total I/O from all workload groups associated with the resource pool exceeds 1500 IOPS, then the I/O of the same query might be reduced below the workgroup limit of 900 IOPS.
The IOPS and throughput max values returned by the sys.dm_user_db_resource_governance view act as limits/caps, not as guarantees. Further, resource governance doesn't guarantee any specific storage latency. The best achievable latency, IOPS, and throughput for a given user workload depend not only on I/O resource governance limits, but also on the mix of I/O sizes used, and on the capabilities of the underlying storage. SQL Database uses I/O operations that vary in size between 512 bytes and 4 MB. For the purposes of enforcing IOPS limits, every I/O is accounted regardless of its size, except for databases with data files in Azure Storage. In that case, IOs larger than 256 KB are accounted as multiple 256-KB I/Os, to align with Azure Storage I/O accounting.
For Basic, Standard, and General Purpose databases, which use data files in Azure Storage, the primary_group_max_io value might not be achievable if a database doesn't have enough data files to cumulatively provide this number of IOPS, or if data isn't distributed evenly across files, or if the performance tier of underlying blobs limits IOPS/throughput below the resource governance limits. Similarly, with small log I/O operations generated by frequent commits of transactions, the primary_max_log_rate value might not be achievable by a workload due to the IOPS limit on the underlying Azure Storage blob. For databases using Azure Premium Storage, Azure SQL Database uses sufficiently large storage blobs to obtain needed IOPS/throughput, regardless of database size. For larger databases, multiple data files are created to increase total IOPS/throughput capacity.
Resource utilization values such as avg_data_io_percent and avg_log_write_percent, reported in the sys.dm_db_resource_stats, sys.resource_stats, sys.dm_elastic_pool_resource_stats, and sys.elastic_pool_resource_stats views, are calculated as percentages of maximum resource governance limits. Therefore, when factors other than resource governance limit IOPS/throughput, it's possible to see IOPS/throughput flattening out and latencies increasing as the workload increases, even though reported resource utilization remains below 100%.
To monitor the read and write IOPS, throughput, and latency per database file, use the sys.dm_io_virtual_file_stats() function. This function surfaces all I/O against the database, including background I/O that isn't accounted toward avg_data_io_percent, but uses IOPS and throughput of the underlying storage, and can impact observed storage latency. The function reports additional latency that can be introduced by I/O resource governance for reads and writes, in the io_stall_queued_read_ms and io_stall_queued_write_ms columns respectively.
Transaction log rate governance
Transaction log rate governance is a process in Azure SQL Database used to limit high ingestion rates for workloads such as bulk insert, SELECT INTO, and index builds. These limits are tracked and enforced at the subsecond level to the rate of log record generation, limiting throughput regardless of how many IOs can be issued against data files. Transaction log generation rates currently scale linearly up to a point that is hardware-dependent and service tier-dependent.
Log rates are set such that they can be achieved and sustained in various scenarios, while the overall system can maintain its functionality with minimized impact to the user load. Log rate governance ensures that transaction log backups stay within published recoverability SLAs. This governance also prevents an excessive backlog on secondary replicas that could otherwise lead to longer than expected downtime during failovers.
The actual physical IOs to transaction log files aren't governed or limited. As log records are generated, each operation is evaluated and assessed for whether it should be delayed in order to maintain a maximum desired log rate (MB/s per second). The delays aren't added when the log records are flushed to storage, rather log rate governance is applied during log rate generation itself.
The actual log generation rates imposed at run time are also influenced by feedback mechanisms, temporarily reducing the allowable log rates so the system can stabilize. Log file space management, avoiding running into out of log space conditions and data replication mechanisms can temporarily decrease the overall system limits.
Log rate governor traffic shaping is surfaced via the following wait types (exposed in the sys.dm_exec_requests and sys.dm_os_wait_stats views):
| Wait Type | Notes |
|---|---|
LOG_RATE_GOVERNOR |
Database limiting |
POOL_LOG_RATE_GOVERNOR |
Pool limiting |
INSTANCE_LOG_RATE_GOVERNOR |
Instance level limiting |
HADR_THROTTLE_LOG_RATE_SEND_RECV_QUEUE_SIZE |
Feedback control, availability group physical replication in Premium/Business Critical not keeping up |
HADR_THROTTLE_LOG_RATE_LOG_SIZE |
Feedback control, limiting rates to avoid an out of log space condition |
HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO |
Geo-replication feedback control, limiting log rate to avoid high data latency and unavailability of geo-secondaries |
When encountering a log rate limit that is hampering desired scalability, consider the following options:
- Scale up to a higher service level in order to get the maximum log rate of a service tier, or switch to a different service tier. The Hyperscale service tier provides 100-MB/s log rate per database and 125 MB/s per elastic pool, regardless of chosen service level. Log generation rate of 150 MB/s is available as an opt-in preview feature. For more information and to opt in to 150 MB/s, see Blog: November 2024 Hyperscale enhancements.
- If data being loaded is transient, such as staging data in an ETL process, it can be loaded into
tempdb(which is minimally logged). - For analytic scenarios, load into a clustered columnstore table, or a table with indexes that use data compression. This reduces the required log rate. This technique does increase CPU utilization and is only applicable to data sets that benefit from clustered columnstore indexes or data compression.
Storage space governance
In Premium and Business Critical service tiers, customer data including data files, transaction log files, and tempdb files, is stored on the local SSD storage of the machine hosting the database or elastic pool. Local SSD storage provides high IOPS and throughput, and low I/O latency. In addition to customer data, local storage is used for the operating system, management software, monitoring data and logs, and other files necessary for system operation.
The size of local storage is finite and depends on hardware capabilities, which determine the maximum local storage limit, or local storage set aside for customer data. This limit is set to maximize customer data storage, while ensuring safe and reliable system operation. To find the maximum local storage value for each service objective, see resource limits documentation for single databases and elastic pools.
You can also find this value, and the amount of local storage currently used by a given database or elastic pool, using the following query:
SELECT server_name, database_name, slo_name, user_data_directory_space_quota_mb, user_data_directory_space_usage_mb
FROM sys.dm_user_db_resource_governance
WHERE database_id = DB_ID();
| Column | Description |
|---|---|
server_name |
Logical server name |
database_name |
Database name |
slo_name |
Service objective name, including hardware generation |
user_data_directory_space_quota_mb |
Maximum local storage, in MB |
user_data_directory_space_usage_mb |
Current local storage consumption by data files, transaction log files, and tempdb files, in MB. Updated every five minutes. |
This query should be executed in the user database, not in the master database. For elastic pools, the query can be executed in any database in the pool. Reported values apply to the entire pool.
Important
In Premium and Business Critical service tiers, if the workload attempts to increase combined local storage consumption by data files, transaction log files, and tempdb files over the maximum local storage limit, an out-of-space error will occur. This will happen even if used space in a database file has not reached the maximum size of the file.
Local SSD storage is also used by databases in service tiers other than Premium and Business Critical for the tempdb database and Hyperscale RBPEX cache. As databases are created, deleted, and increase or decrease in size, total local storage consumption on a machine fluctuates over time. If the system detects that available local storage on a machine is low, and a database or an elastic pool is at risk of running out of space, it moves the database or elastic pool to a different machine with sufficient local storage available.
This move occurs in an online fashion, similarly to a database scaling operation, and has a similar impact, including a short (seconds) failover at the end of the operation. This failover terminates open connections and rolls back transactions, potentially affecting applications using the database at that time.
Because all data is copied to local storage volumes on different machines, moving larger databases in Premium and Business Critical service tiers can require a substantial amount of time. During that time, if local space consumption by a database or an elastic pool, or by the tempdb database grows rapidly, the risk of running out of space increases. The system initiates database movement in a balanced fashion to minimize out-of-space errors while avoiding unnecessary failovers.
tempdb sizes
Size limits for tempdb in Azure SQL Database depend on the purchasing and deployment model.
To learn more, review tempdb size limits for:
- vCore purchasing model: single databases, pooled databases
- DTU purchasing model: single databases, pooled databases.
Previously available hardware
This section includes details on previously available hardware.
- Gen4 hardware has been retired and isn't available for provisioning, upscaling, or downscaling. Migrate your database to a supported hardware generation for a wider range of vCore and storage scalability, accelerated networking, best IO performance, and minimal latency. For more information, see Support has ended for Gen 4 hardware on Azure SQL Database.
You can use Azure Resource Graph Explorer to identify all Azure SQL Database resources that currently use Gen4 hardware, or you can check the hardware used by resources for a specific logical server in the Azure portal.
You must have at least read permissions to the Azure object or object group to see results in Azure Resource Graph Explorer.
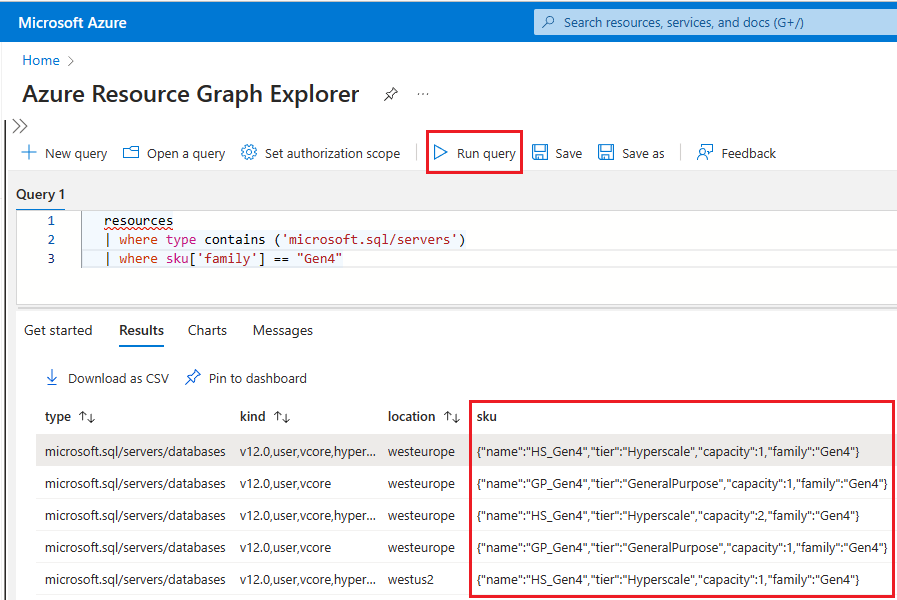
To use Resource Graph Explorer to identify Azure SQL resources that are still using Gen4 hardware, follow these steps:
Go to the Azure portal.
Search for
Resource graphin the search box, and choose the Resource Graph Explorer service from the search results.In the query window, type the following query and then select Run query:
resources | where type contains ('microsoft.sql/servers') | where sku['family'] == "Gen4"The Results pane displays all the currently deployed resources in Azure that are using Gen4 hardware.
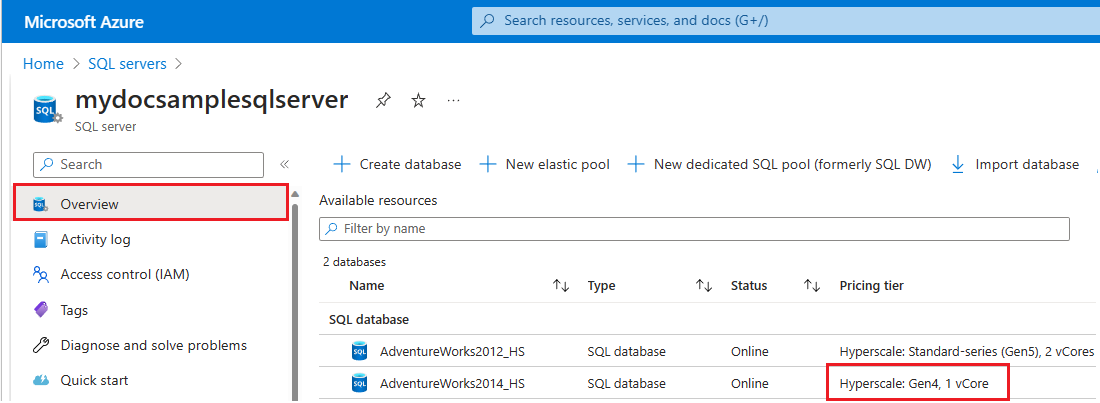
To check the hardware used by resources for a specific logical server in Azure, follow these steps:
- Go to the Azure portal.
- Search for
SQL serversin the search box and choose SQL servers from the search results to open the SQL servers page and view all servers for the chosen subscription(s). - Select the server of interest to open the Overview page for the server.
- Scroll down to available resources and check the Pricing tier column for resources that are using gen4 hardware.
To migrate resources to standard-series hardware, review Change hardware.
Related content
- For information about general Azure limits, see Azure subscription and service limits, quotas, and constraints.
- For information about DTUs and eDTUs, see DTUs and eDTUs.
- For information about
tempdbsize limits, see single vCore databases, pooled vCore databases, single DTU databases, and pooled DTU databases.