Failover and patching for Azure Managed Redis (preview)
To build resilient and successful client applications, it's critical to understand failover in the Azure Managed Redis (preview)service. A failover can be a part of planned management operations, or it might be caused by unplanned hardware or network failures. A common use of cache failover comes when the management service patches the Azure Managed Redis binaries.
In this article, you find this information:
- What is a failover?
- How failover occurs during patching.
- How to build a resilient client application.
What is a failover?
Let's start with an overview of failover for Azure Managed Redis.
A quick summary of cache architecture
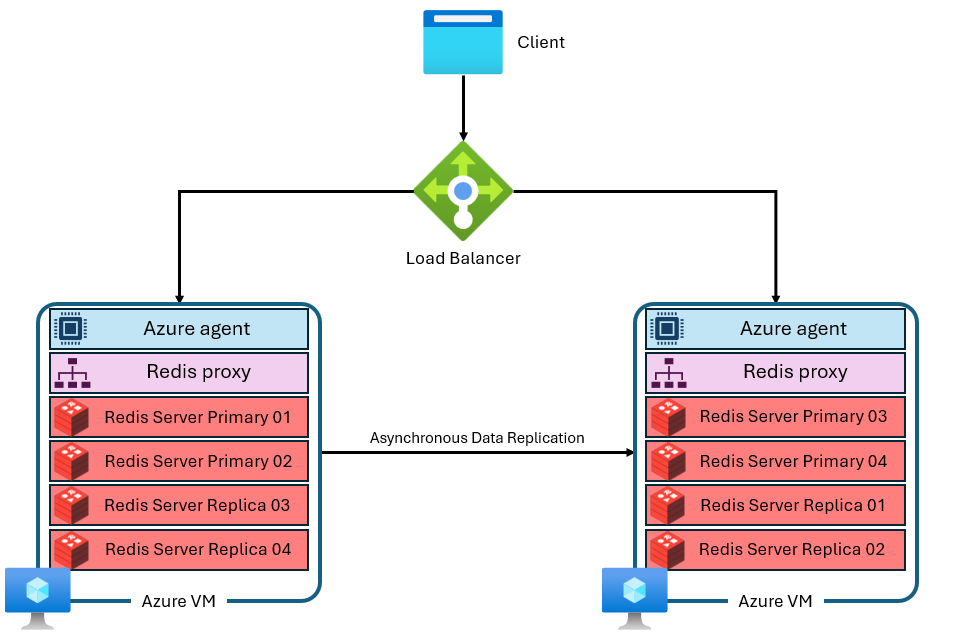
A cache is constructed of multiple virtual machines with separate and private IP addresses. Each virtual machine (or "node") runs multiple Redis server processes (called "shards") in parallel. Multiple shards allow for more efficient utilization of vCPUs on each virtual machine and higher performance. Not all of the primary Redis shards are on the same VM/node. Instead, primary and replica shards are distributed across both nodes. Because primary shards use more CPU resources than replica shards, this approach enables more primary shards to be run in parallel. Each node has a high-performance proxy process to manage the shards, handle connection management, and trigger self-healing. One shard might be down while the others remain available.
In depth details of Azure Managed Redis Architecture can be found here.
Explanation of a failover
A failover occurs when one or more replica shards promote themselves to become primary shards, and the old primary shards close existing connections. A failover might be planned or unplanned.
A planned failover takes place during two different times:
- System updates, such as Redis patching or OS upgrades.
- Management operations, such as scaling and rebooting.
Because the nodes receive advance notice of the update, they can cooperatively swap roles and quickly update the load balancer of the change. A planned failover typically finishes in less than 1 second.
An unplanned failover might happen because of hardware failure, network failure, or other unexpected outages to one or more nodes in the cluster. The replica shard(s) on the remaining node(s) will promote themselves to primary to maintain availability, but the process takes longer. A replica shard must first detect its primary shard isn't available before it can start the failover process. The replica shard must also verify this unplanned failure isn't transient or local, to avoid an unnecessary failover. This delay in detection means an unplanned failover typically finishes within 10 to 15 seconds.
How does patching occur?
The Azure Managed Redis service regularly updates your cache with the latest platform features and fixes. To patch a cache, the service follows these steps:
- The service creates new up-to-date VMs to replace all VMs being patched.
- Then it promotes one of the new VMs as the cluster leader.
- One by one, all nodes being patched are removed from the cluster. Any shards on these VMs will be demoted and migrated to one of the new VMs.
- Finally, all VMs that were replaced are deleted.
Each shard of a clustered cache is patched separately and doesn't close connections to another shard.
Multiple caches in the same resource group and region are also patched one at a time. Caches that are in different resource groups or different regions might be patched simultaneously.
Because full data synchronization happens before the process repeats, data loss is unlikely to occur for your cache. You can further guard against data loss by exporting data and enabling persistence.
Additional cache load
Whenever a failover occurs, the caches need to replicate data from one node to the other. This replication causes some load increase in both server memory and CPU. If the cache instance is already heavily loaded, client applications might experience increased latency. In extreme cases, client applications might receive time-out exceptions.
How does a failover affect my client application?
Client applications could receive some errors from their Azure Managed Redis instance. The number of errors seen by a client application depends on how many operations were pending on that connection at the time of failover. Any connection routed through the node that closed its connections sees errors.
Many client libraries can throw different types of errors when connections break, including:
- Time-out exceptions
- Connection exceptions
- Socket exceptions
The number and type of exceptions depends on where the request is in the code path when the cache closes its connections. For instance, an operation that sends a request but hasn't received a response when the failover occurs might get a time-out exception. New requests on the closed connection object receive connection exceptions until the reconnection happens successfully.
Most client libraries attempt to reconnect to the cache if they're configured to do so. However, unforeseen bugs can occasionally place the library objects into an unrecoverable state. If errors persist for longer than a preconfigured amount of time, the connection object should be recreated. In Microsoft.NET and other object-oriented languages, recreating the connection without restarting the application can be accomplished by using a ForceReconnect pattern.
What are the updates included under maintenance?
Maintenance includes these updates:
- Redis Server updates: Any update or patch of the Redis server binaries.
- Virtual machine (VM) updates: Any updates of the virtual machine hosting the Redis service. VM updates include patching software components in the hosting environment to upgrading networking components or decommissioning.
Does maintenance appear in the service health in the Azure portal before a patch?
No, maintenance doesn't appear under service health in the portal or any other place.
Client network-configuration changes
Certain client-side network-configuration changes can trigger No connection available errors. Such changes might include:
- Swapping a client application's virtual IP address between staging and production slots.
- Scaling the size or number of instances of your application.
Such changes can cause a connectivity issue that usually lasts less than one minute. Your client application probably loses its connection to other external network resources, but also to the Azure Managed Redis service.
Build in resiliency
You can't avoid failovers completely. Instead, write your client applications to be resilient to connection breaks and failed requests. Most client libraries automatically reconnect to the cache endpoint, but few of them attempt to retry failed requests. Depending on the application scenario, it might make sense to use retry logic with backoff.
How do I make my application resilient?
Refer to these design patterns to build resilient clients, especially the circuit breaker and retry patterns:
- Reliability patterns - Cloud Design Patterns
- Retry guidance for Azure services - Best practices for cloud applications
- Implement retries with exponential backoff