This article describes an architecture that uses Azure Machine Learning to predict the delinquency and default probabilities of loan applicants. The model's predictions are based on the fiscal behavior of the applicant. The model uses a huge set of data points to classify applicants and provide an eligibility score for each applicant.
Apache®, Spark, and the flame logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by the Apache Software Foundation is implied by the use of these marks.
Architecture

Download a Visio file of this architecture.
Dataflow
The following dataflow corresponds to the preceding diagram:
Storage: Data is stored in a database like an Azure Synapse Analytics pool if it's structured. Older SQL databases can be integrated into the system. Semi-structured and unstructured data can be loaded into a data lake.
Ingestion and pre-processing: Azure Synapse Analytics processing pipelines and extract, transform, load (ETL) processing can connect to data stored in Azure or third-party sources via built-in connectors. Azure Synapse Analytics supports multiple analysis methodologies that use SQL, Spark, Azure Data Explorer, and Power BI. You can also use existing Azure Data Factory orchestration for the data pipelines.
Processing: Azure Machine Learning is used to develop and manage the machine learning models.
Initial processing: During this stage, raw data is processed to create a curated dataset that will train a machine learning model. Typical operations include data type formatting, imputation of missing values, feature engineering, feature selection, and dimensionality reduction.
Training: During the training stage, Azure Machine Learning uses the processed dataset to train the credit risk model and select the best model.
Model training: You can use a range of machine learning models, including classical machine learning and deep learning models. You can use hyperparameter tuning to optimize model performance.
Model evaluation: Azure Machine Learning assesses the performance of each trained model so you can select the best one for deployment.
Model registration: You register the model that performs best in Azure Machine Learning. This step makes the model available for deployment.
Responsible AI: Responsible AI is an approach to developing, assessing, and deploying AI systems in a safe, trustworthy, and ethical way. Because this model infers an approval or denial decision for a loan request, you need to implement the principles of Responsible AI.
Fairness metrics assess the effect of unfair behavior and enable mitigation strategies. Sensitive features and attributes are identified in the dataset and in cohorts (subsets) of the data. For more information, see Model performance and fairness.
Interpretability is a measure of how well you can understand the behavior of a machine learning model. This component of Responsible AI generates human-understandable descriptions of the model's predictions. For more information, see Model interpretability.
Real-time machine learning deployment: You need to use real-time model inference when the request needs to be reviewed immediately for approval.
- Managed machine learning online endpoint. For real-time scoring, you need to choose an appropriate compute target.
- Online requests for loans use real-time scoring based on input from the applicant form or loan application.
- The decision and the input used for model scoring are stored in persistent storage and can be retrieved for future reference.
Batch machine learning deployment: For offline loan processing, the model is scheduled to be triggered at regular intervals.
- Managed batch endpoint. Batch inference is scheduled and the result dataset is created. Decisions are based on the creditworthiness of the applicant.
- The result set of scoring from batch processing is persisted in the database or Azure Synapse Analytics data warehouse.
Interface to data about applicant activity: The details input by the applicant, the internal credit profile, and the model's decision are all staged and stored in appropriate data services. These details are used in the decision engine for future scoring, so they're documented.
- Storage: All details of credit processing are retained in persistent storage.
- User interface: The approval or denial decision is presented to the applicant.
Reporting: Real-time insights about the number of applications processed and approve or deny outcomes are continuously presented to managers and leadership. Examples of reporting include near real-time reports of amounts approved, the loan portfolio created, and model performance.
Components
- Azure Blob Storage provides scalable object storage for unstructured data. It's optimized for storing files like binary files, activity logs, and files that don't adhere to a specific format.
- Azure Data Lake Storage is the storage foundation for creating cost-effective data lakes on Azure. It provides blob storage with a hierarchical folder structure and enhanced performance, management, and security. It services multiple petabytes of information while sustaining hundreds of gigabits of throughput.
- Azure Synapse Analytics is an analytics service that brings together the best of SQL and Spark technologies and a unified user experience for data exploration and pipelines. It integrates with Power BI, Azure Cosmos DB, and Azure Machine Learning. The service supports both dedicated and serverless resource models and the ability to switch between those models.
- Azure SQL Database is an always up-to-date, fully managed relational database that's built for the cloud.
- Azure Machine Learning is a cloud service for managing machine learning project lifecycles. It provides an integrated environment for data exploration, model building and management, and deployment and supports code-first and low-code/no-code approaches to machine learning.
- Power BI is a visualization tool that provides easy integration with Azure resources.
- Azure App Service enables you to build and host web apps, mobile back ends, and RESTful APIs without managing infrastructure. Supported languages include .NET, .NET Core, Java, Ruby, Node.js, PHP, and Python.
Alternatives
You can use Azure Databricksto develop, deploy, and manage machine learning models and analytics workloads. The service provides a unified environment for model development.
Scenario details
Organizations in the financial industry need to predict the credit risk of individuals or businesses that request credit. This model evaluates the delinquency and default probabilities of loan applicants.
Credit risk prediction involves deep analysis of population behavior and classification of the customer base into segments based on fiscal responsibility. Other variables include market factors and economic conditions, which have a significant influence on results.
Challenges. Input data includes tens of millions of customer profiles and data about customer credit behavior and spending habits that's based on billions of records from disparate systems, like internal customer activity systems. The third-party data about economic conditions and the country/region's market analysis can come from monthly or quarterly snapshots that require the loading and maintenance of hundreds of GBs of files. Credit bureau information about the applicant or semi-structured rows of customer data, and cross joins between these datasets and quality checks to validate the integrity of the data, are needed.
The data usually consists of wide-column tables of customer information from credit bureaus together with market analysis. The customer activity consists of records with dynamic layout that might not be structured. Data is also available in free-form text from the customer service notes and applicant-interaction forms.
Processing these large volumes of data and ensuring the results are current requires streamlined processing. You need a low-latency storage and retrieval process. The data infrastructure should be able to scale to support disparate data sources and provide the ability to manage and secure the data perimeter. The machine learning platform needs to support the complex analysis of the many models that are trained, tested, and validated across many population segments.
Data sensitivity and privacy. The data processing for this model involves personal data and demographic details. You need to avoid the profiling of populations. Direct visibility to all personal data must be restricted. Examples of personal data include account numbers, credit card details, social security numbers, names, addresses, and postal codes.
Credit card and bank account numbers must always be obfuscated. Certain data elements need to be masked and always encrypted, providing no access to the underlying information, but available for analysis.
Data needs to be encrypted at rest, in transit, and during processing via secure enclaves. Access to data items is logged in a monitoring solution. The production system needs to be set up with appropriate CI/CD pipelines with approvals that trigger model deployments and processes. Audit of the logs and workflow should provide the interactions with the data for any compliance needs.
Processing. This model requires high computational power for analysis, contextualizing, and model training and deployment. Model scoring is validated against random samples to ensure that credit decisions don't include any race, gender, ethnic, or geographic-location bias. The decision model needs to be documented and archived for future reference. Every factor that's involved in the decision outcomes is stored.
Data processing requires high CPU usage. It includes SQL processing of structured data in DB and JSON format, Spark processing of the data frames, or big data analytics on terabytes of information in various document formats. Data extract, load, transform (ELT)/ETL jobs are scheduled or triggered at regular intervals or in real time, depending on the value of most recent data.
Compliance and regulatory framework. Every detail of loan processing needs to be documented, including the submitted application, the features used in model scoring, and the result set of the model. Model training information, data used for training, and training results should be registered for future reference and audit and compliance requests.
Batch versus real-time scoring. Certain tasks are proactive and can be processed as batch jobs, like pre-approved balance transfers. Some requests, like online credit line increases, require real-time approval.
Real-time access to the status of online loan requests must be available to the applicant. The loan-issuing financial institution continuously monitors the performance of the credit model and needs insight into metrics like loan-approval status, number of approved loans, dollar amounts issued, and the quality of new loan originations.
Responsible AI
The Responsible AI dashboard provides a single interface for multiple tools that can help you implement Responsible AI. The Responsible AI Standard is based on six principles:
Fairness and inclusiveness in Azure Machine Learning. This component of the Responsible AI dashboard helps you evaluate unfair behaviors by avoiding harms of allocation and harms of quality-of-service. You can use it to assess fairness across sensitive groups defined in terms of gender, age, ethnicity, and other characteristics. During assessment, fairness is quantified via disparity metrics. You should implement the mitigation algorithms in the Fairlearn open-source package, which use parity constraints.
Reliability and safety in Azure Machine Learning. The error analysis component of Responsible AI can help you:
- Gain a deep understanding of how failure is distributed for a model.
- Identify cohorts of data that have a higher error rate than the overall benchmark.
Transparency in Azure Machine Learning. A crucial part of transparency is understanding how features affect the machine learning model.
- Model interpretability helps you understand what influences the behavior of the model. It generates human-understandable descriptions of the model's predictions. This understanding helps to ensure that you can trust the model and helps you debug and improve it. InterpretML can help you understand the structure of glass-box models or the relationship among features in black-box deep neural network models.
- Counterfactual what-if can help you understand and debug a machine learning model in terms of how it reacts to feature changes and perturbations.
Privacy and security in Azure Machine Learning. Machine Learning administrators need to create a secure configuration to develop and manage the deployment of models. Security and governance features can help you comply with your organization's security policies. Other tools can help you assess and secure your models.
Accountability in Azure Machine Learning. Machine learning operations (MLOps) is based on DevOps principles and practices that increase the efficiency of AI workflows. Azure Machine Learning can help you implement MLOps capabilities:
- Register, package, and deploy models
- Get notifications and alerts to changes in models
- Capture governance data for the end-to-end lifecycle
- Monitor applications for operational problems
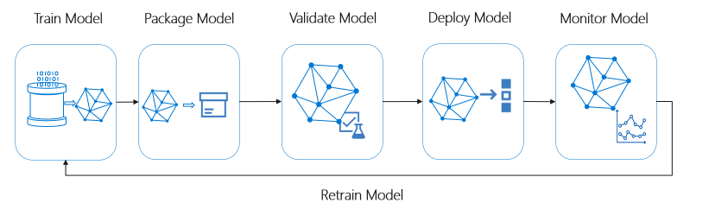
This diagram illustrates the MLOps capabilities of Azure Machine Learning:
Potential use cases
You can apply this solution to the following scenarios:
- Finance: Get financial analysis of customers or cross-sales analysis of customers for targeted marketing campaigns.
- Healthcare: Use patient information as input to suggest treatment offerings.
- Hospitality: Create a customer profile to suggest offerings for hotels, flights, cruise packages, and memberships.
Considerations
These considerations implement the pillars of the Azure Well-Architected Framework, which is a set of guiding tenets that you can use to improve the quality of a workload. For more information, see Microsoft Azure Well-Architected Framework.
Security
Security provides assurances against deliberate attacks and the abuse of your valuable data and systems. For more information, see Design review checklist for Security.
Azure solutions provide defense in depth and a Zero Trust approach.
Consider implementing the following security features in this architecture:
- Deploy dedicated Azure services into virtual networks
- Azure SQL Database security capabilities
- Secure the credentials in data factory by using Key Vault
- Enterprise security and governance for Azure Machine Learning
- Azure security baseline for Synapse Analytics Workspace
Cost Optimization
Cost Optimization is about reducing unnecessary expenses and improving operational efficiencies. For more information, see Design review checklist for Cost Optimization.
To estimate the cost of implementing this solution, use the Azure pricing calculator.
Also consider these resources:
Operational Excellence
Operational Excellence covers the operations processes that deploy an application and keep it running in production. For more information, see Design review checklist for Operational Excellence.
Machine learning solutions need to be scalable and standardized for easier management and maintenance. Ensure that your solution supports ongoing inference with retraining cycles and automated redeployments of models.
For more information, see Azure MLOps v2 GitHub repository.
Performance Efficiency
Performance Efficiency is the ability of your workload to scale to meet the demands placed on it by users in an efficient manner. For more information, see Design review checklist for Performance Efficiency.
- For more information about designing scalable solutions, see Performance efficiency checklist.
- Manage your Azure Synapse Analytics environment with SQL, Spark, or serverless SQL pools.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal author:
- Charitha Basani | Senior Cloud Solution Architect
Other contributor:
- Mick Alberts | Technical Writer
To see non-public LinkedIn profiles, sign into LinkedIn.
Next steps
- Azure security baseline for Azure Machine Learning
- Azure Synapse Analytics
- Deploy machine learning models to Azure
- What is Responsible AI?