Global routing redundancy for mission-critical web applications
Important
Designing redundancy implementations that deal with global platform outages for a mission-critical architecture can be complex and costly. Because of the potential problems that might arise with this design, carefully consider the tradeoffs.
In most situations, you won't need the architecture described in this article.
Mission-critical systems strive to minimize single points of failure by building redundancy and self-healing capabilities in the solution as much as possible. Any unified entry point of the system can be considered a point of failure. If this component experiences an outage, the entire system will be offline to the user. When choosing a routing service, it's important to consider the reliability of the service itself.
In the baseline architecture for a mission-critical application, Azure Front Door was chosen because of its high uptime Service-level agreements (SLA) and a rich feature set:
- Route traffic to multiple regions in an active-active model
- Transparent failover using TCP anycast
- Serve static content from edge nodes by using integrated content delivery networks (CDNs)
- Block unauthorized access with integrated web application firewall
Front Door is designed to provide the utmost resiliency and availability for not only our external customers, but also for multiple properties across Microsoft. For more information about Front Door's capabilities, see Accelerate and secure your web application with Azure Front Door.
Front Door capabilities are more than enough to meet most business requirements, however, with any distributed system, expect failure. If the business requirements demand a higher composite SLO or zero-down time in case of an outage, you'll need to rely on an alternate traffic ingress path. However, the pursuit of a higher SLO comes with significant costs, operational overhead, and can lower your overall reliability. Carefully consider the tradeoffs and potential issues that the alternate path might introduce in other components that are on the critical path. Even when the impact of unavailability is significant, complexity might outweigh the benefit.
One approach is to define a secondary path, with alternate service(s), which becomes active only when Azure Front Door is unavailable. Feature parity with Front Door shouldn't be treated as a hard requirement. Prioritize features that you absolutely need for business continuity purposes, even potentially running in a limited capacity.
Another approach is using third-party technology for global routing. This approach will require a multicloud active-active deployment with stamps hosted across two or more cloud providers. Even though Azure can effectively be integrated with other cloud platforms, this approach isn't recommended because of operational complexity across the different cloud platforms.
This article describes some strategies for global routing using Azure Traffic Manager as the alternate router in situations where Azure Front Door isn't available.
Approach
This architecture diagram shows a general approach with multiple redundant traffic paths.
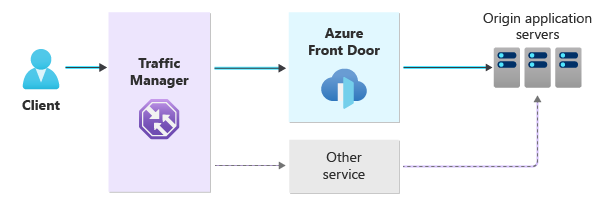
With this approach, we will introduce several components and provide guidance that will make significant changes associated to the delivery of your web application(s):
Azure Traffic Manager directs traffic to Azure Front Door or to the alternative service that you've selected.
Azure Traffic Manager is a DNS-based global load balancer. Your domain's CNAME record points to Traffic Manager, which determines the destination based on how you configure its routing method. Using priority routing will make traffic flow through Azure Front Door by default. Traffic Manager can automatically switch traffic to your alternate path if Azure Front Door is unavailable.
Important
This solution mitigates risks associated with Azure Front Door outages, but it's susceptible to Azure Traffic Manager outages as a global point of failure.
You can also consider using a different global traffic routing system, such as a global load balancer. However, Traffic Manager works well for many situations.
You have two ingress paths:
Azure Front Door provides the primary path and processes and routes all of your application traffic.
Another router is used as a backup for Azure Front Door. Traffic only flows through this secondary path if Front Door is unavailable.
The specific service that you select for the secondary router depends on many factors. You might choose to use Azure-native services, or third-party services. In these articles we provide Azure-native options to avoid adding additional operational complexity to the solution. If you use third-party services, you need to use multiple control planes to manage your solution.
Your origin application servers need to be ready to accept traffic from either service. Consider how you secure traffic to your origin, and what responsibilities Front Door and other upstream services provide. Ensure that your application can handle traffic from whichever path your traffic flows through.
Tradeoffs
While this mitigation strategy can make the application be available during platform outages, there are some significant tradeoffs. You should weigh the potential benefits against known costs, and make an informed decision about whether the benefits are worth those costs.
Financial cost: When you deploy multiple redundant paths to your application, you need to consider the cost of deploying and running the resources. We provide two example scenarios for different use cases, each of which has a different cost profile.
Operational complexity: Every time you add additional components to your solution, you increase your management overhead. Any change to one component might impact other components.
Suppose you decide to use the new capabilities of Azure Front Door. You need to check whether your alternative traffic path also provides an equivalent capability, and if not, you need to decide how to handle the difference in behavior between the two traffic paths. In real-world applications, these complexities can have a high cost, and can present a major risk to your system's stability.
Performance: This design requires additional CNAME lookups during name resolution. In most applications, this isn't a significant concern, but you should evaluate whether your application performance is affected by introducing additional layers into your ingress path.
Opportunity cost: Designing and implementing redundant ingress paths requires a significant engineering investment, which ultimately comes at an opportunity cost to feature development and other platform improvements.
Warning
If you're not careful in how you design and implement a complex high-availability solution, you can actually make your availability worse. Increasing the number of components in your architecture increases the number of failure points. It also means you have a higher level of operational complexity. When you add extra components, every change that you make needs to be carefully reviewed to understand how it affects your overall solution.
Availability of Azure Traffic Manager
Azure Traffic Manager is a reliable service, but the service level agreement doesn't guarantee 100% availability. If Traffic Manager is unavailable, your users might not be able to access your application, even if Azure Front Door and your alternative service are both available. It's important to plan how your solution will continue to operate under these circumstances.
Traffic Manager returns cacheable DNS responses. If time to live (TTL) on your DNS records allows caching, short outages of Traffic Manager might not be a concern. That is because downstream DNS resolvers might have cached a previous response. You should plan for prolonged outages. You might choose to manually reconfigure your DNS servers to direct users to Azure Front Door if Traffic Manager is unavailable.
Traffic routing consistency
It's important to understand the Azure Front Door capabilities and features that you use and rely on. When you choose the alternate service, decide the minimum capabilities that you need and omit other features when your solution is in a degraded mode.
When planning an alternative traffic path, here are some key questions you should consider:
- Do you use Azure Front Door's caching features? If caching is unavailable, can your origin servers keep up with your traffic?
- Do you do use the Azure Front Door rules engine to perform custom routing logic, or to rewrite requests?
- Do you use the Azure Front Door web application firewall (WAF) to secure your applications?
- Do you restrict traffic based on IP address or geography?
- Who issues and managed your TLS certificates?
- How do you restrict access to your origin application servers to ensure it comes through Azure Front Door? Do you use Private Link, or do you rely on public IP addresses with service tags and identifier headers?
- Do your application servers accept traffic from anywhere other than Azure Front Door? If they do, which protocols do they accept?
- Do your clients use Azure Front Door's HTTP/2 support?
Web application firewall (WAF)
If you use Azure Front Door's WAF to protect your application, consider what happens if the traffic doesn't go through Azure Front Door.
If your alternative path also provides a WAF, consider the following questions:
- Can it be configured in the same way as your Azure Front Door WAF?
- Does it need to be tuned and tested independently, to reduce the likelihood of false positive detections?
Warning
You might choose not to use WAF for your alternative ingress path. This approach can be considered to support the reliability target of the application. However, this isn't a good practice and we don't recommend it.
Consider the tradeoff in accepting traffic from the internet without any checks. If an attacker discovers an unprotected secondary traffic path to your application, they might send malicious traffic through your secondary path even when the primary path includes a WAF.
It's best to secure all paths to your application servers.
Domain names and DNS
Your mission-critical application should use a custom domain name. You'll control over how traffic flows to your application, and you reduce the dependencies on a single provider.
It's also a good practice to use a high-quality and resilient DNS service for your domain name, such as Azure DNS. If your domain name's DNS servers are unavailable, users can't reach your service.
It's recommended that you use multiple DNS resolvers to increase overall resiliency even further.
CNAME chaining
Solutions that combine Traffic Manager, Azure Front Door, and other services use a multi-layer DNS CNAME resolution process, also called CNAME chaining. For example, when you resolve your own custom domain, you might see five or more CNAME records before an IP address is returned.
Adding additional links to a CNAME chain can affect DNS name resolution performance. However, DNS responses are usually cached, which reduces the performance impact.
TLS certificates
For a mission-critical application, it's recommended that you provision and use your own TLS certificates instead of the managed certificates provided by Azure Front Door. You'll reduce the number of potential problems with this complex architecture.
Here are some benefits:
To issue and renew managed TLS certificates, Azure Front Door verifies your ownership of the domain. The domain verification process assumes that your domain's CNAME records point directly to Azure Front Door. But, that assumption often isn't correct. Issuing and renewing managed TLS certificates on Azure Front Door might not work smoothly and you increase the risk of outages due to TLS certificate problems.
Even if your other services provide managed TLS certificates, they might not be able to verify domain ownership.
If each service gets their own managed TLS certificates independently, there might be issues. For example, users might not expect to see different TLS certificates issued by different authorities, or with different expiry dates or thumbprints.
However, there will be additional operations related to renewing and updating your certificates before they expire.
Origin security
When you configure your origin to only accept traffic through Azure Front Door, you gain protection against layer 3 and layer 4 DDoS attacks. Because Azure Front Door only responds to valid HTTP traffic, it also helps to reduce your exposure to many protocol-based threats. If you change your architecture to allow alternative ingress paths, you need to evaluate whether you've accidentally increased your origin's exposure to threats.
If you use Private Link to connect from Azure Front Door to your origin server, how does traffic flow through your alternative path? Can you use private IP addresses to access your origins, or must you use public IP addresses?
If your origin uses the Azure Front Door service tag and the X-Azure-FDID header to validate that traffic has flowed through Azure Front Door, consider how your origins can be reconfigured to validate that traffic has flowed through either of your valid paths. You must test that you haven't accidentally opened your origin to traffic through other paths, including from other customers' Azure Front Door profiles.
When you plan your origin security, check whether the alternative traffic path relies on provisioning dedicated public IP addresses. This might need a manually triggered process to bring the backup path online.
If there are dedicated public IP addresses, consider whether you should implement Azure DDoS Protection to reduce the risk of denial of service attacks against your origins. Also, consider whether you need to implement Azure Firewall or another firewall capable of protecting you against a variety of network threats. You might also need more intrusion detection strategies. These controls can be important elements in a more complex multi-path architecture.
Health modeling
Mission-critical design methodology requires a system health model that gives you overall observability of the solution and its components. When you use multiple traffic ingress paths, you need to monitor the health of each path. If your traffic is rerouted to the secondary ingress path, your health model should reflect the fact that the system is still operational but that it's running in a degraded state.
Include these questions in your health model design:
- How do the different components of your solution monitor the health of downstream components?
- When should health monitors consider downstream components to be unhealthy?
- How long does it take for an outage to be detected?
- After an outage is detected, how long does it take for traffic to be routed through an alternative path?
There are multiple global load balancing solutions that enable you to monitor the health of Azure Front Door and trigger an automatic failover to a backup platform if an outage occurs. Azure Traffic Manager is suitable in most cases. With Traffic Manager, you configure endpoint monitoring to monitor downstream services by specifying which URL to check, how frequently to check that URL, and when to consider the downstream service unhealthy based on probe responses. In general, the shorter the interval between checks, the less time it takes for Traffic Manager to direct traffic through an alternative path to reach your origin server.
If Front Door is unavailable, then multiple factors influence the amount of time that the outage affects your traffic, including:
- The time to live (TTL) on your DNS records.
- How frequently Traffic Manager runs its health checks.
- How many failed probes Traffic Manager is configured to see before it reroutes traffic.
- How long clients and upstream DNS servers cache Traffic Manager's DNS responses for.
You also need to determine which of those factors are within your control and whether upstream services beyond your control might affect user experience. For example, even if you use low TTL on your DNS records, upstream DNS caches might still serve stale responses for longer than they should. This behavior might exacerbate the effects of an outage or make it seem like your application is unavailable, even when Traffic Manager has already switched to sending requests to the alternative traffic path.
Tip
Mission-critical solutions require automated failover approaches wherever possible. Manual failover processes are considered slow in order for the application to remain responsive.
Zero-downtime deployment
When you're planning how to operate a solution with redundant ingress path, you should also plan for how you deploy or configure your services when they're degraded. For most Azure services, SLAs apply to the uptime of the service itself, and not to management operations or deployments. Consider whether your deployment and configuration processes need to be made resilient to service outages.
You should also consider the number of independent control planes that you need to interact with to manage your solution. When you use Azure services, Azure Resource Manager provides a unified and consistent control plane. However, if you use a third-party service to route traffic, you might need to use a separate control plane to configure the service, which introduces further operational complexity.
Warning
The use of multiple control planes introduces complexity and risk to your solution. Every point of difference increases the likelihood that somebody accidentally misses a configuration setting, or apply different configurations to redundant components. Ensure that your operational procedures mitigate this risk.
Refer to: Mission-critical design area: Zero-downtime deployment
Continuous validation
For a mission-critical solution, your testing practices need to verify that your solution meets your requirements regardless of the path that your application traffic flows through. Consider each part of the solution and how you test it for each type of outage.
Ensure that your testing processes include these elements:
- Can you verify that traffic is correctly redirected through the alternative path when the primary path is unavailable?
- Can both paths support the level of production traffic you expect to receive?
- Are both paths adequately secured, to avoid opening or exposing vulnerabilities when you're in a degraded state?
Refer to: Mission-critical design area: Continuous validation
Common scenarios
Here are common scenarios where this design can be used:
Global content delivery commonly applies to static content delivery, media, and high-scale eCommerce applications. In this scenario, caching is a critical part of the solution architecture, and failures to cache can result in significantly degraded performance or reliability.
Global HTTP ingress commonly applies to mission-critical dynamic applications and APIs. In this scenario, the core requirement is to route traffic to the origin server reliably and efficiently. Frequently, a WAF is an important security control used in these solutions.
Warning
If you're not careful in how you design and implement a complex multi-ingress solution, you can actually make your availability worse. Increasing the number of components in your architecture increases the number of failure points. It also means you have a higher level of operational complexity. When you add extra components, every change that you make needs to be carefully reviewed to understand how it affects your overall solution.
Next steps
Review the global HTTP ingress and global content delivery scenarios to understand whether they apply to your solution.