Natural language processing (NLP) has many applications, such as sentiment analysis, topic detection, language detection, key phrase extraction, and document categorization.
Specifically, you can use NLP to:
- Classify documents, for example, labeling them as sensitive or spam.
- Conduct subsequent processing or searches with NLP outputs.
- Summarize text by identifying entities in the document.
- Tag documents with keywords, utilizing identified entities.
- Conduct content-based search and retrieval through tagging.
- Summarize a document's key topics using identified entities.
- Categorize documents for navigation utilizing detected topics.
- Enumerate related documents based on a selected topic.
- Assess text sentiment to understand its positive or negative tone.
With advancements in technology, NLP can not only be used to categorize and analyze text data, but also to enhance interpretable AI functions across diverse domains. The integration of Large Language Models (LLM) significantly enhances NLP's capabilities. LLMs like GPT and BERT can generate human-like, contextually aware text, making them highly effective for complex language processing tasks. They complement existing NLP techniques by handling broader cognitive tasks, which improve conversation systems and customer engagement, especially with models like Databricks' Dolly 2.0.
Relationship and differences between language models and NLP
NLP is a comprehensive field encompassing various techniques for processing human language. In contrast, language models are a specific subset within NLP, focusing on deep learning to perform high-level language tasks. While language models enhance NLP by providing advanced text generation and understanding capabilities, they aren't synonymous with NLP. Instead, they serve as powerful tools within the broader NLP domain, enabling more sophisticated language processing.
Note
This article focuses on NLP. The relationship between NLP and language models demonstrates that language models enhance NLP processes through superior language understanding and generation capabilities.
Apache®, Apache Spark, and the flame logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Potential use cases
Business scenarios that can benefit from custom NLP include:
- Document Intelligence for handwritten or machine-created documents in finance, healthcare, retail, government, and other sectors.
- Industry-agnostic NLP tasks for text processing, such as name entity recognition (NER), classification, summarization, and relation extraction. These tasks automate the process of retrieving, identifying, and analyzing document information like text and unstructured data. Examples of these tasks include risk stratification models, ontology classification, and retail summarizations.
- Information retrieval and knowledge graph creation for semantic search. This functionality makes it possible to create medical knowledge graphs that support drug discovery and clinical trials.
- Text translation for conversational AI systems in customer-facing applications across retail, finance, travel, and other industries.
- Sentiment and enhanced emotional intelligence in analytics, particularly for monitoring brand perception and customer feedback analytics.
- Automated report generation. Synthesize and generate comprehensive textual reports from structured data inputs, aiding sectors such as finance and compliance where thorough documentation is necessary.
- Voice-activated interfaces to enhance user interactions in IoT and smart device applications by integrating NLP for voice recognition and natural conversation capabilities.
- Adaptative language models to dynamically adjust language output to suit various audience comprehension levels, which is crucial for educational content and accessibility improvements.
- Cybersecurity text analysis to analyze communication patterns and language usage in real-time to identify potential security threats in digital communication, improving the detection of phishing attempts or misinformation.
Apache Spark as a customized NLP framework
Apache Spark is a powerful parallel processing framework that enhances the performance of big-data analytic applications through in-memory processing. Azure Synapse Analytics, Azure HDInsight, and Azure Databricks continue to provide robust access to Spark's processing capabilities, ensuring seamless execution of large-scale data operations.
For customized NLP workloads, Spark NLP remains an efficient framework capable of processing vast volumes of text. This open-source library provides extensive functionality through Python, Java, and Scala libraries, which deliver the sophistication found in prominent NLP libraries such as spaCy and NLTK. Spark NLP includes advanced features like spell checking, sentiment analysis, and document classification, consistently ensuring state-of-the-art accuracy and scalability.
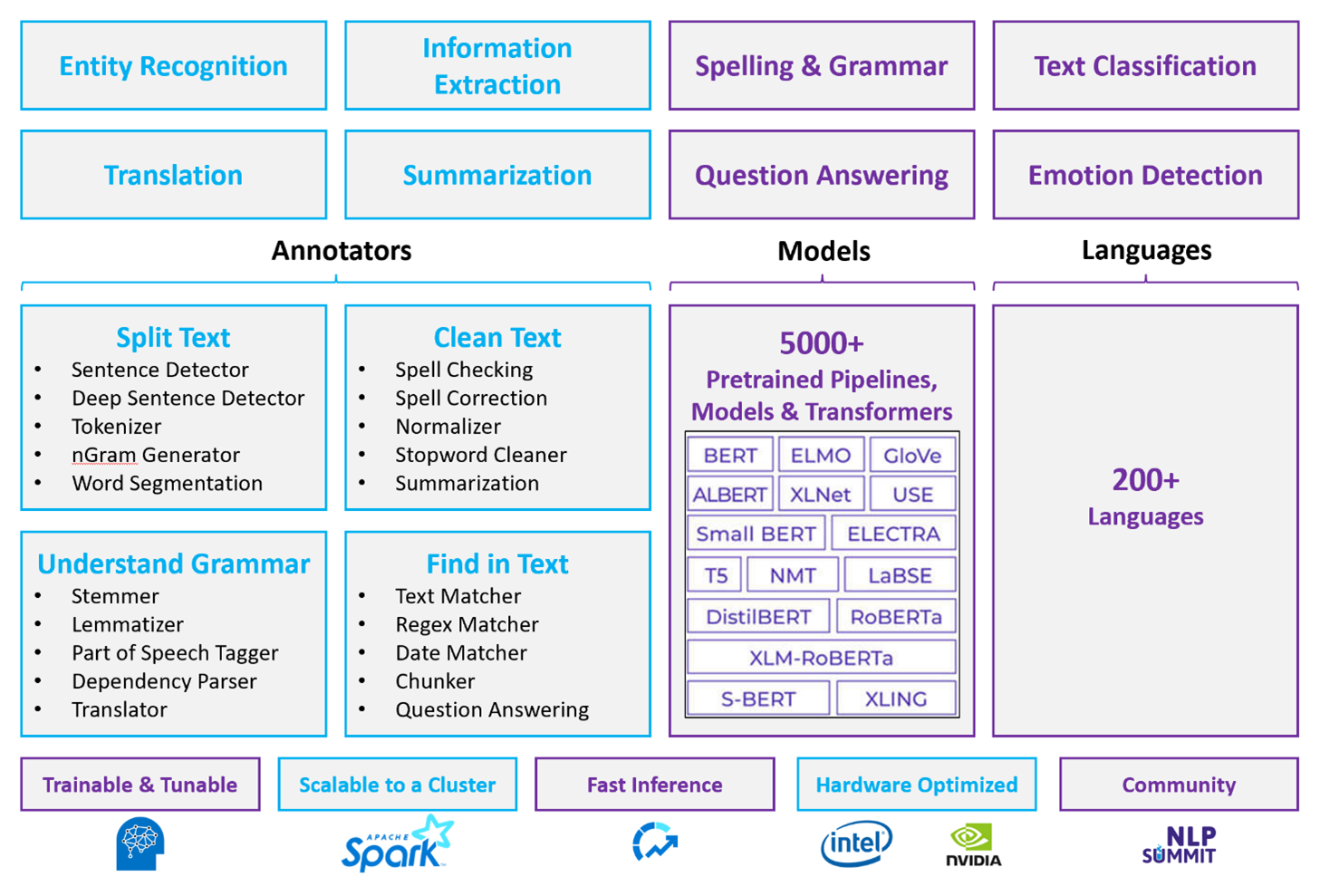
Recent public benchmarks highlight Spark NLP's performance, showing significant speed improvements over other libraries while maintaining comparable accuracy for training custom models. Notably, the integration of the Llama-2 models and OpenAI Whisper enhances conversational interfaces and multilingual speech recognition, marking significant strides in optimized processing capabilities.
Uniquely, Spark NLP effectively utilizes a distributed Spark cluster, functioning as a native extension of Spark ML that operates directly on data frames. This integration supports enhanced performance gains on clusters, facilitating the creation of unified NLP and machine learning pipelines for tasks such as document classification and risk prediction. The introduction of MPNet embeddings and extensive ONNX support further enrich these capabilities, allowing for precise and context-aware processing.
Beyond performance advantages, Spark NLP delivers state-of-the-art accuracy across an expanding array of NLP tasks. The library comes with prebuilt deep learning models for named entity recognition, document classification, sentiment detection, and more. Its feature-rich design includes pre-trained language models supporting word, chunk, sentence, and document embeddings.
With optimized builds for CPUs, GPUs, and the latest Intel Xeon chips, Spark NLP's infrastructure is designed for scalability, enabling training and inference processes to fully utilize Spark clusters. This ensures efficient handling of NLP tasks across diverse environments and applications, maintaining its position at the forefront of NLP innovation.
Challenges
Processing resources: Processing a collection of free-form text documents requires a significant amount of computational resources, and the processing is also time-intensive. This kind of processing often involves GPU compute deployment. Recent advancements, such as optimizations in Spark NLP architectures like Llama-2 which support quantization, help streamline these intensive tasks, making resource allocation more efficient.
Standardization issues: Without a standardized document format, it can be difficult to achieve consistently accurate results when you use free-form text processing to extract specific facts from a document. For example, extracting the invoice number and date from various invoices poses challenges. The integration of adaptable NLP models like M2M100 improved processing accuracy across multiple languages and formats, facilitating greater consistency in results.
Data variety and complexity: Addressing the variety of document structures and linguistic nuances remains complex. Innovations such as MPNet embeddings provide enhanced contextual understanding, offering more intuitive handling of diverse textual formats and improving overall data processing reliability.
Key selection criteria
In Azure, Spark services like Azure Databricks, Microsoft Fabric, and Azure HDInsight provide NLP functionality when used with Spark NLP. Azure AI services are another option for NLP functionality. To decide which service to use, consider these questions:
Do you want to use prebuilt or pretrained models? If yes, consider using the APIs that Azure AI services offer, or download your model of choice through Spark NLP, which now includes advanced models like Llama-2 and MPNet for enhanced capabilities.
Do you need to train custom models against a large corpus of text data? If yes, consider using Azure Databricks, Microsoft Fabric, or Azure HDInsight with Spark NLP. These platforms provide the computational power and flexibility needed for extensive model training.
Do you need low-level NLP capabilities like tokenization, stemming, lemmatization, and term frequency/inverse document frequency (TF/IDF)? If yes, consider using Azure Databricks, Microsoft Fabric, or Azure HDInsight with Spark NLP. Alternatively, use an open-source software library in your processing tool of choice.
Do you need simple, high-level NLP capabilities like entity and intent identification, topic detection, spell check, or sentiment analysis? If yes, consider using the APIs that Azure AI services offers. Or download your model of choice through Spark NLP to leverage prebuilt functions for these tasks.
Capability matrix
The following tables summarize the key differences in the capabilities of NLP services.
General capabilities
| Capability | Spark service (Azure Databricks, Microsoft Fabric, Azure HDInsight) with Spark NLP | Azure AI services |
|---|---|---|
| Provides pretrained models as a service | Yes | Yes |
| REST API | Yes | Yes |
| Programmability | Python, Scala | For supported languages, see Additional Resources |
| Supports processing of big data sets and large documents | Yes | No |
Low-level NLP capabilities
Capability of Annotators
| Capability | Spark service (Azure Databricks, Microsoft Fabric, Azure HDInsight) with Spark NLP | Azure AI services |
|---|---|---|
| Sentence detector | Yes | No |
| Deep sentence detector | Yes | Yes |
| Tokenizer | Yes | Yes |
| N-gram generator | Yes | No |
| Word segmentation | Yes | Yes |
| Stemmer | Yes | No |
| Lemmatizer | Yes | No |
| Part-of-speech tagging | Yes | No |
| Dependency parser | Yes | No |
| Translation | Yes | No |
| Stopword cleaner | Yes | No |
| Spell correction | Yes | No |
| Normalizer | Yes | Yes |
| Text matcher | Yes | No |
| TF/IDF | Yes | No |
| Regular expression matcher | Yes | Embedded in Conversational Language Understanding (CLU) |
| Date matcher | Yes | Possible in CLU through DateTime recognizers |
| Chunker | Yes | No |
Note
Microsoft Language Understanding (LUIS) will be retired on October 1st, 2025. Existing LUIS applications are encouraged to migrate to Conversational Language Understanding (CLU), a capability of Azure AI Services for Language, which enhances language understanding capabilities and offers new features.
High-level NLP capabilities
| Capability | Spark service (Azure Databricks, Microsoft Fabric, Azure HDInsight) with Spark NLP | Azure AI services |
|---|---|---|
| Spell checking | Yes | No |
| Summarization | Yes | Yes |
| Question answering | Yes | Yes |
| Sentiment detection | Yes | Yes |
| Emotion detection | Yes | Supports opinion mining |
| Token classification | Yes | Yes, through custom models |
| Text classification | Yes | Yes, through custom models |
| Text representation | Yes | No |
| NER | Yes | Yes—text analytics provides a set of NER, and custom models are in entity recognition |
| Entity recognition | Yes | Yes, through custom models |
| Language detection | Yes | Yes |
| Supports languages besides English | Yes, supports over 200 languages | Yes, supports over 97 languages |
Set up Spark NLP in Azure
To install Spark NLP, use the following code, but replace <version> with the latest version number. For more information, see the Spark NLP documentation.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
Develop NLP pipelines
For the execution order of an NLP pipeline, Spark NLP follows the same development concept as traditional Spark ML machine learning models, applying specialized NLP techniques.
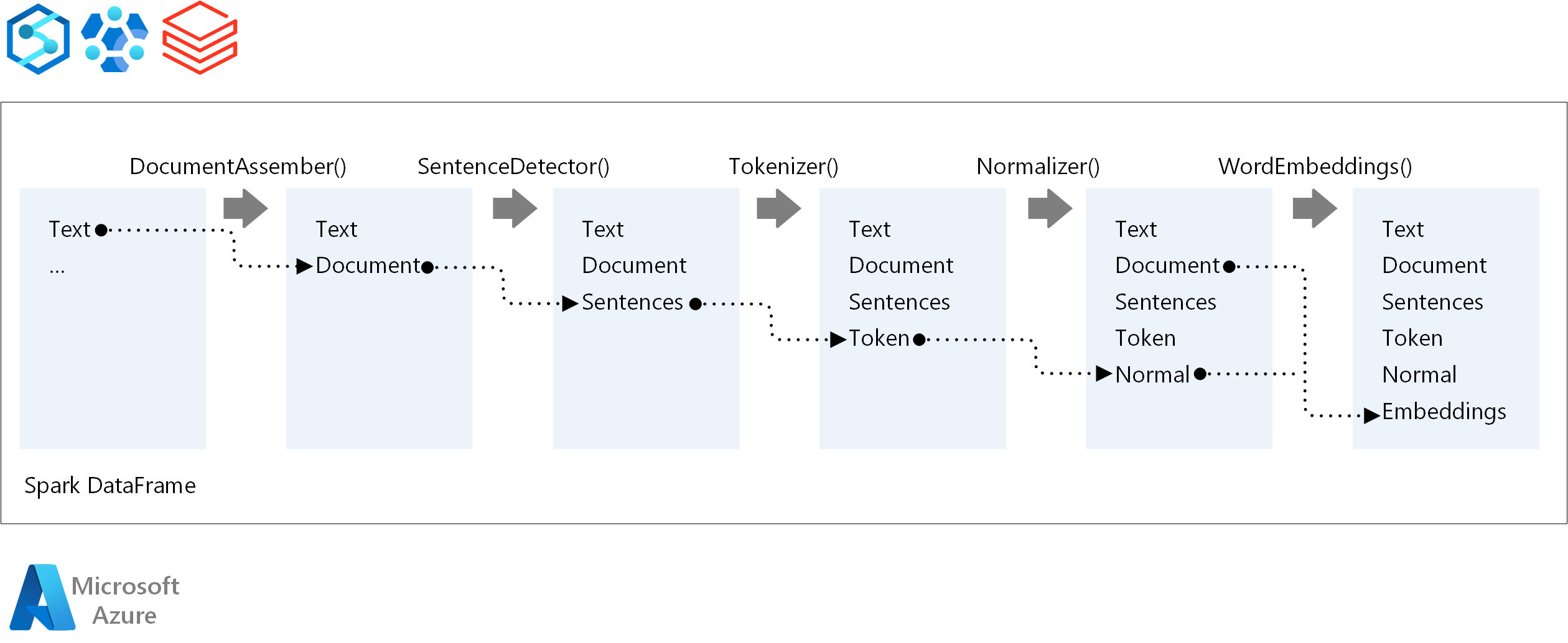
The core components of a Spark NLP pipeline are:
DocumentAssembler: A transformer that prepares data by converting it into a format that Spark NLP can process. This stage is the entry point for every Spark NLP pipeline. DocumentAssembler reads either a
Stringcolumn or anArray[String], with options to preprocess the text usingsetCleanupMode, which is off by default.SentenceDetector: An annotator that identifies sentence boundaries using predefined approaches. It can return each detected sentence in an
Array, or in separate rows whenexplodeSentencesis set to true.Tokenizer: An annotator that divides raw text into discrete tokens—words, numbers, and symbols—outputting these as a
TokenizedSentence. The Tokenizer is non-fitted and uses input configuration within theRuleFactoryto create tokenizing rules. Custom rules can be added when defaults are insufficient.Normalizer: An annotator tasked with refining tokens. Normalizer applies regular expressions and dictionary transformations to clean text and remove extraneous characters.
WordEmbeddings: Lookup annotators that map tokens to vectors, facilitating semantic processing. You can specify a custom embedding dictionary using
setStoragePath, where each line contains a token and its vector, separated by spaces. Unresolved tokens default to zero vectors.
Spark NLP leverages Spark MLlib pipelines, with native support from MLflow, an open-source platform that manages the machine learning lifecycle. MLflow's key components include:
MLflow Tracking: Records experimental runs and provides robust querying capabilities for analyzing outcomes.
MLflow Projects: Enables the execution of data science code on diverse platforms, enhancing portability and reproducibility.
MLflow Models: Supports versatile model deployment across different environments through a consistent framework.
Model Registry: Provides comprehensive model management, storing versions centrally for streamlined access and deployment, facilitating production-readiness.
MLflow is integrated with platforms such as Azure Databricks but can also be installed in other Spark-based environments to manage and track your experiments. This integration allows the use of the MLflow Model Registry for making models available for production purposes, thus streamlining the deployment process and maintaining model governance.
By using MLflow alongside Spark NLP, you can ensure efficient management and deployment of NLP pipelines, addressing modern requirements for scalability and integration while supporting advanced techniques like word embeddings and large language model adaptations.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal authors:
- Freddy Ayala | Cloud Solution Architect
- Moritz Steller | Senior Cloud Solution Architect
Next steps
Spark NLP documentation:
Azure components:
Learn resources:
Related resources
- Large-scale custom natural language processing in Azure
- Choose a Microsoft Azure AI services technology
- Compare the machine learning products and technologies from Microsoft
- MLflow and Azure Machine Learning
- AI enrichment with image and natural language processing in Azure Cognitive Search
- Analyze news feeds with near real-time analytics using image and natural language processing