Overview of generative AI gateway capabilities in Azure API Management
APPLIES TO: All API Management tiers
This article introduces capabilities in Azure API Management to help you manage generative AI APIs, such as those provided by Azure OpenAI Service. Azure API Management provides a range of policies, metrics, and other features to enhance security, performance, and reliability for the APIs serving your intelligent apps. Collectively, these features are called generative AI (GenAI) gateway capabilities for your generative AI APIs.
Note
- This article focuses on capabilities to manage APIs exposed by Azure OpenAI Service. Many of the GenAI gateway capabilities apply to other large language model (LLM) APIs, including those available through Azure AI Model Inference API.
- Generative AI gateway capabilities are features of API Management's existing API gateway, not a separate API gateway. For more information on API Management, see Azure API Management overview.
Challenges in managing generative AI APIs
One of the main resources you have in generative AI services is tokens. Azure OpenAI Service assigns quota for your model deployments expressed in tokens-per-minute (TPM) which is then distributed across your model consumers - for example, different applications, developer teams, departments within the company, etc.
Azure makes it easy to connect a single app to Azure OpenAI Service: you can connect directly using an API key with a TPM limit configured directly on the model deployment level. However, when you start growing your application portfolio, you're presented with multiple apps calling single or even multiple Azure OpenAI Service endpoints deployed as pay-as-you-go or Provisioned Throughput Units (PTU) instances. That comes with certain challenges:
- How is token usage tracked across multiple applications? Can cross-charges be calculated for multiple applications/teams that use Azure OpenAI Service models?
- How do you ensure that a single app doesn't consume the whole TPM quota, leaving other apps with no option to use Azure OpenAI Service models?
- How is the API key securely distributed across multiple applications?
- How is load distributed across multiple Azure OpenAI endpoints? Can you ensure that the committed capacity in PTUs is exhausted before falling back to pay-as-you-go instances?
The rest of this article describes how Azure API Management can help you address these challenges.
Import Azure OpenAI Service resource as an API
Import an API from an Azure OpenAI Service endpoint to Azure API management using a single-click experience. API Management streamlines the onboarding process by automatically importing the OpenAPI schema for the Azure OpenAI API and sets up authentication to the Azure OpenAI endpoint using managed identity, removing the need for manual configuration. Within the same user-friendly experience, you can preconfigure policies for token limits and emitting token metrics.

Token limit policy
Configure the Azure OpenAI token limit policy to manage and enforce limits per API consumer based on the usage of Azure OpenAI Service tokens. With this policy you can set a rate limit, expressed in tokens-per-minute (TPM). You can also set a token quota over a specified period, such as hourly, daily, weekly, monthly, or yearly.
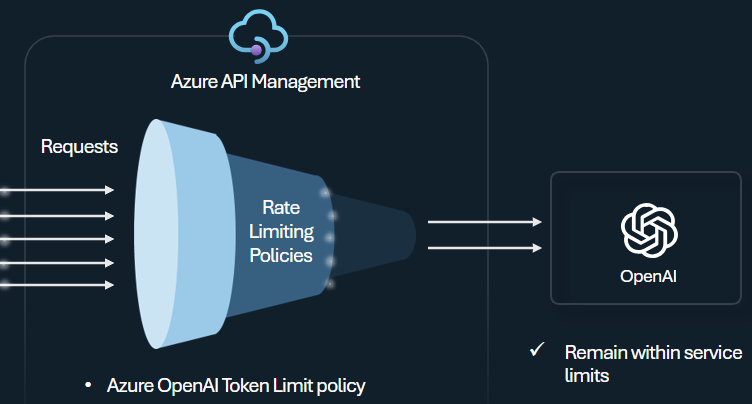
This policy provides flexibility to assign token-based limits on any counter key, such as subscription key, originating IP address, or an arbitrary key defined through a policy expression. The policy also enables precalculation of prompt tokens on the Azure API Management side, minimizing unnecessary requests to the Azure OpenAI Service backend if the prompt already exceeds the limit.
The following basic example demonstrates how to set a TPM limit of 500 per subscription key:
<azure-openai-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</azure-openai-token-limit>
Tip
To manage and enforce token limits for LLM APIs available through the Azure AI Model Inference API, API Management provides the equivalent llm-token-limit policy.
Emit token metric policy
The Azure OpenAI emit token metric policy sends metrics to Application Insights about consumption of LLM tokens through Azure OpenAI Service APIs. The policy helps provide an overview of the utilization of Azure OpenAI Service models across multiple applications or API consumers. This policy could be useful for chargeback scenarios, monitoring, and capacity planning.
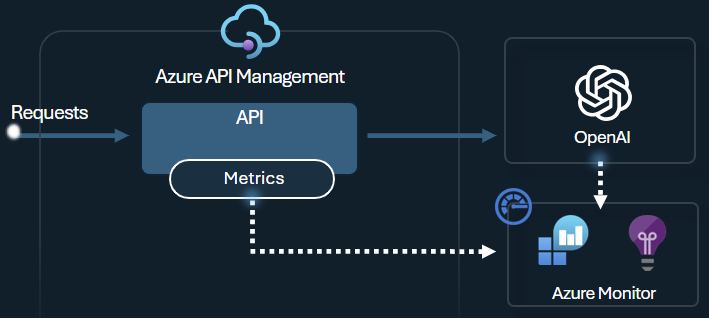
This policy captures prompt, completions, and total token usage metrics and sends them to an Application Insights namespace of your choice. Moreover, you can configure or select from predefined dimensions to split token usage metrics, so you can analyze metrics by subscription ID, IP address, or a custom dimension of your choice.
For example, the following policy sends metrics to Application Insights split by client IP address, API, and user:
<azure-openai-emit-token-metric namespace="openai">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</azure-openai-emit-token-metric>
Tip
To send metrics for LLM APIs available through the Azure AI Model Inference API, API Management provides the equivalent llm-emit-token-metric policy.
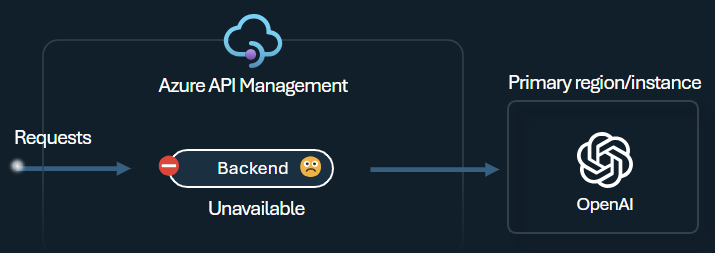
Backend load balancer and circuit breaker
One of the challenges when building intelligent applications is to ensure that the applications are resilient to backend failures and can handle high loads. By configuring your Azure OpenAI Service endpoints using backends in Azure API Management, you can balance the load across them. You can also define circuit breaker rules to stop forwarding requests to the Azure OpenAI Service backends if they're not responsive.
The backend load balancer supports round-robin, weighted, and priority-based load balancing, giving you flexibility to define a load distribution strategy that meets your specific requirements. For example, define priorities within the load balancer configuration to ensure optimal utilization of specific Azure OpenAI endpoints, particularly those purchased as PTUs.
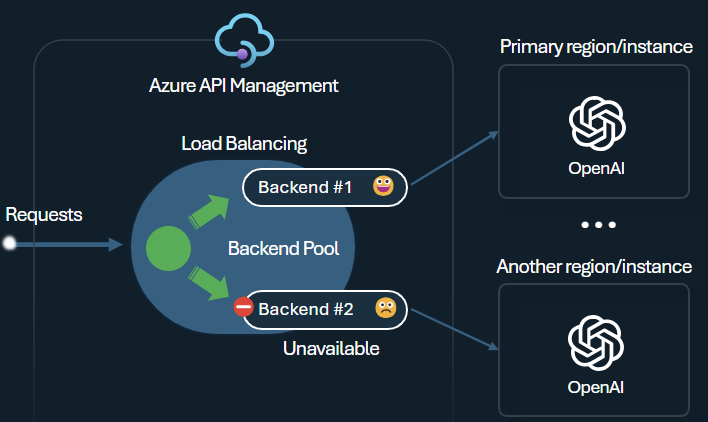
The backend circuit breaker features dynamic trip duration, applying values from the Retry-After header provided by the backend. This ensures precise and timely recovery of the backends, maximizing the utilization of your priority backends.
Semantic caching policy
Configure Azure OpenAI semantic caching policies to optimize token use by storing completions for similar prompts.
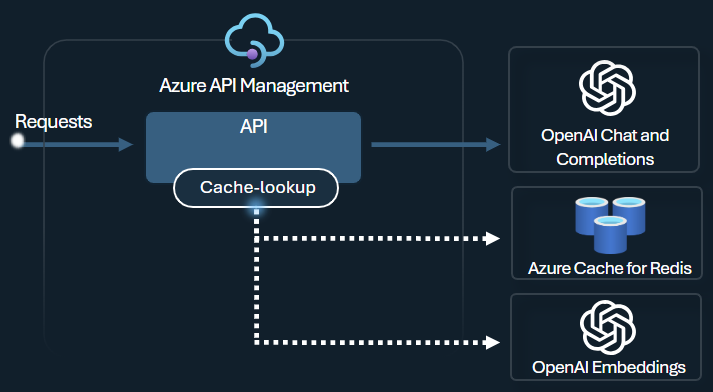
In API Management, enable semantic caching by using Azure Redis Enterprise or another external cache compatible with RediSearch and onboarded to Azure API Management. By using the Azure OpenAI Service Embeddings API, the azure-openai-semantic-cache-store and azure-openai-semantic-cache-lookup policies store and retrieve semantically similar prompt completions from the cache. This approach ensures completions reuse, resulting in reduced token consumption and improved response performance.
Tip
To enable semantic caching for LLM APIs available through the Azure AI Model Inference API, API Management provides the equivalent llm-semantic-cache-store-policy and llm-semantic-cache-lookup-policy policies.
Labs and samples
- Labs for the GenAI gateway capabilities of Azure API Management
- Azure API Management (APIM) - Azure OpenAI Sample (Node.js)
- Python sample code for using Azure OpenAI with API Management
Architecture and design considerations
- GenAI gateway reference architecture using API Management
- AI hub gateway landing zone accelerator
- Designing and implementing a gateway solution with Azure OpenAI resources
- Use a gateway in front of multiple Azure OpenAI deployments or instances
Related content
- Blog: Introducing GenAI capabilities in Azure API Management
- Blog: Integrating Azure Content Safety with API Management for Azure OpenAI Endpoints
- Training: Manage your generative AI APIs with Azure API Management
- Smart load balancing for OpenAI endpoints and Azure API Management
- Authenticate and authorize access to Azure OpenAI APIs using Azure API Management