Quickstart: Recognize and convert speech to text
Important
Items marked (preview) in this article are currently in public preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
In this quickstart, you try real-time speech to text in Azure AI Foundry.
Prerequisites
- Azure subscription - Create one for free.
- Some Azure AI services features are free to try in the Azure AI Foundry portal. For access to all capabilities described in this article, you need to connect AI services in AI Foundry.
Try real-time speech to text
Go to your AI Foundry project. If you need to create a project, see Create an AI Foundry project.
Select Playgrounds from the left pane and then select a playground to use. In this example, select Try the Speech playground.
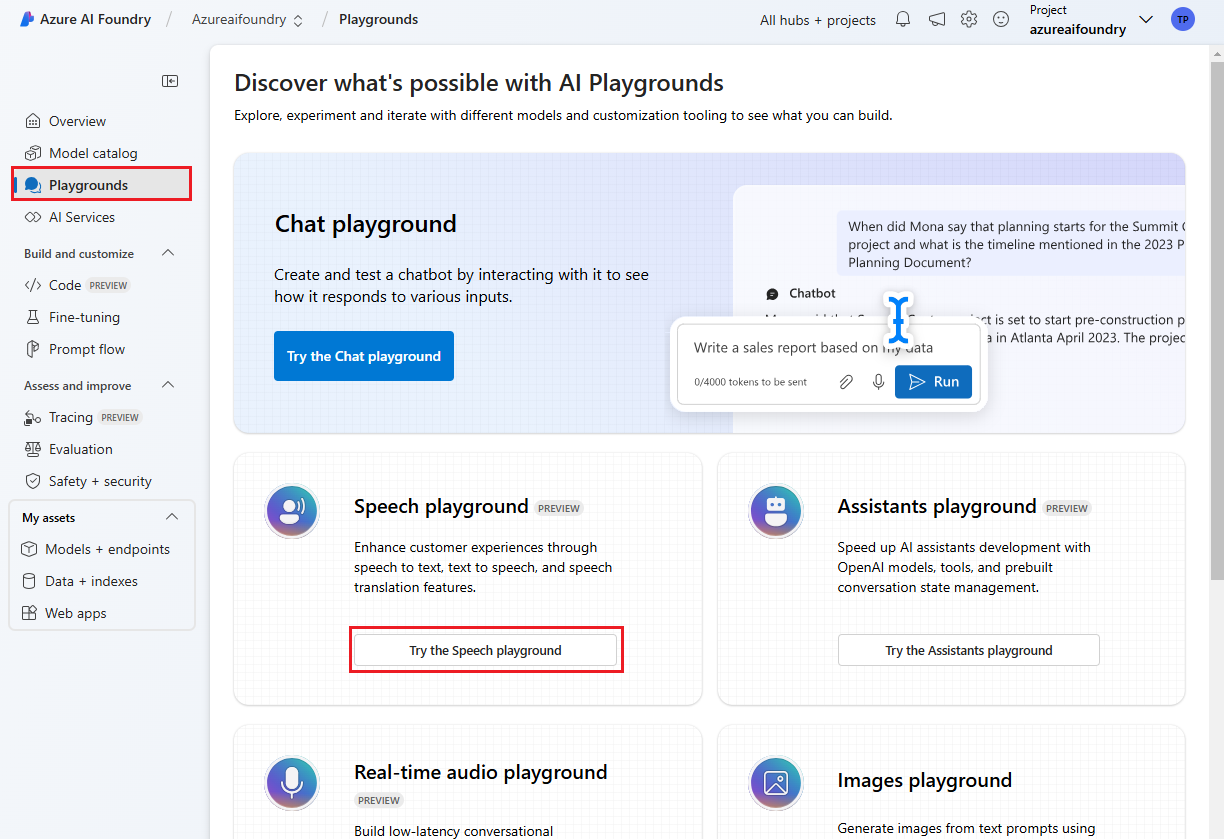
Optionally, you can select a different connection to use in the playground. In the Speech playground, you can connect to Azure AI Services multi-service resources or Speech service resources.
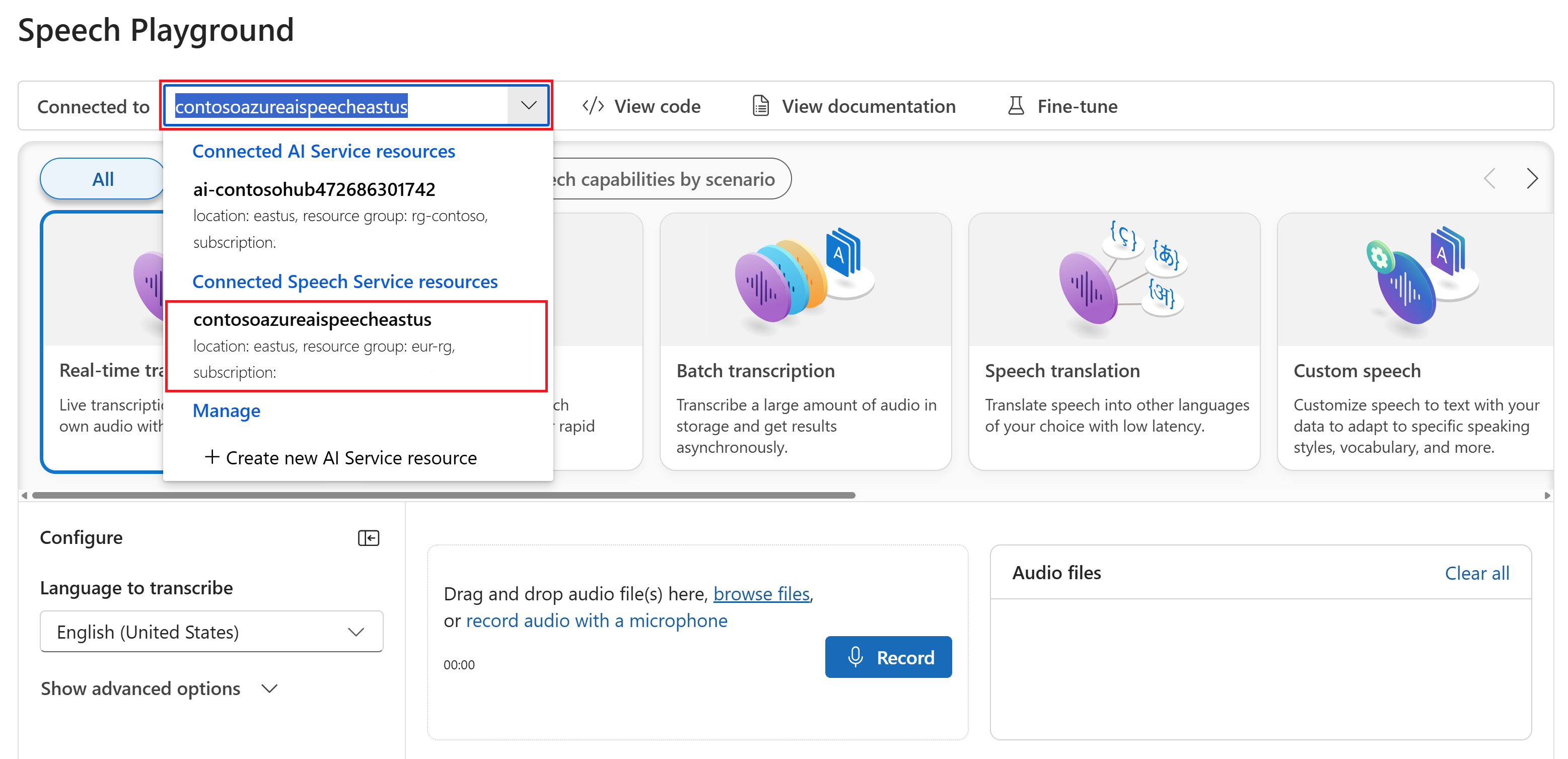
Select Real-time transcription.
Select Show advanced options to configure speech to text options such as:
- Language identification: Used to identify languages spoken in audio when compared against a list of supported languages. For more information about language identification options such as at-start and continuous recognition, see Language identification.
- Speaker diarization: Used to identify and separate speakers in audio. Diarization distinguishes between the different speakers who participate in the conversation. The Speech service provides information about which speaker was speaking a particular part of transcribed speech. For more information about speaker diarization, see the real-time speech to text with speaker diarization quickstart.
- Custom endpoint: Use a deployed model from custom speech to improve recognition accuracy. To use Microsoft's baseline model, leave this set to None. For more information about custom speech, see Custom Speech.
- Output format: Choose between simple and detailed output formats. Simple output includes display format and timestamps. Detailed output includes more formats (such as display, lexical, ITN, and masked ITN), timestamps, and N-best lists.
- Phrase list: Improve transcription accuracy by providing a list of known phrases, such as names of people or specific locations. Use commas or semicolons to separate each value in the phrase list. For more information about phrase lists, see Phrase lists.
Select an audio file to upload, or record audio in real-time. In this example, we use the
Call1_separated_16k_health_insurance.wavfile that's available in the Speech SDK repository on GitHub. You can download the file or use your own audio file.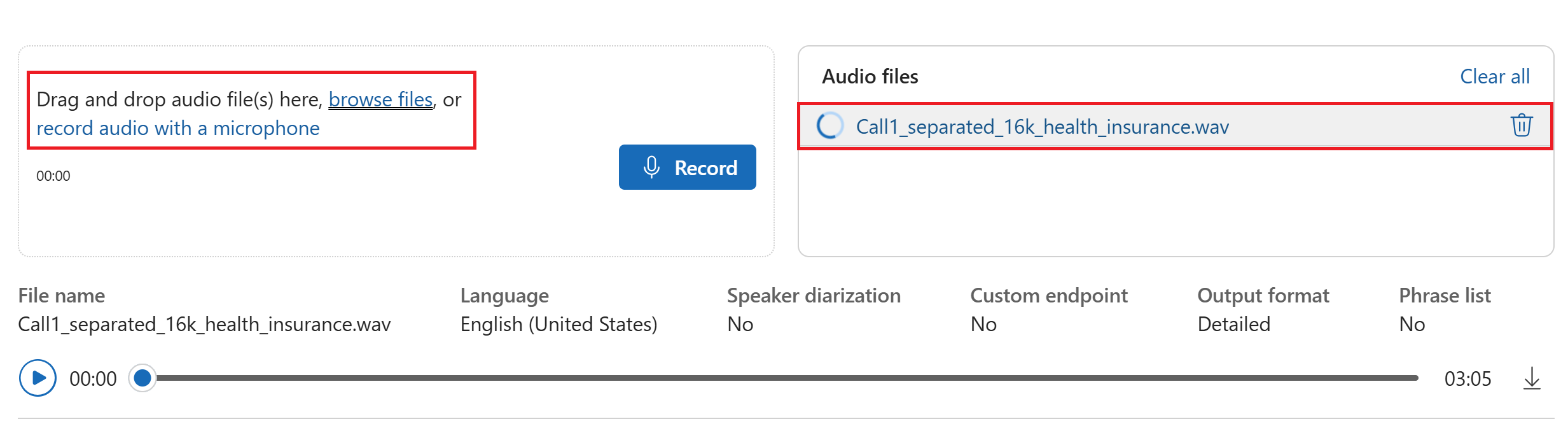
You can view the real-time transcription at the bottom of the page.
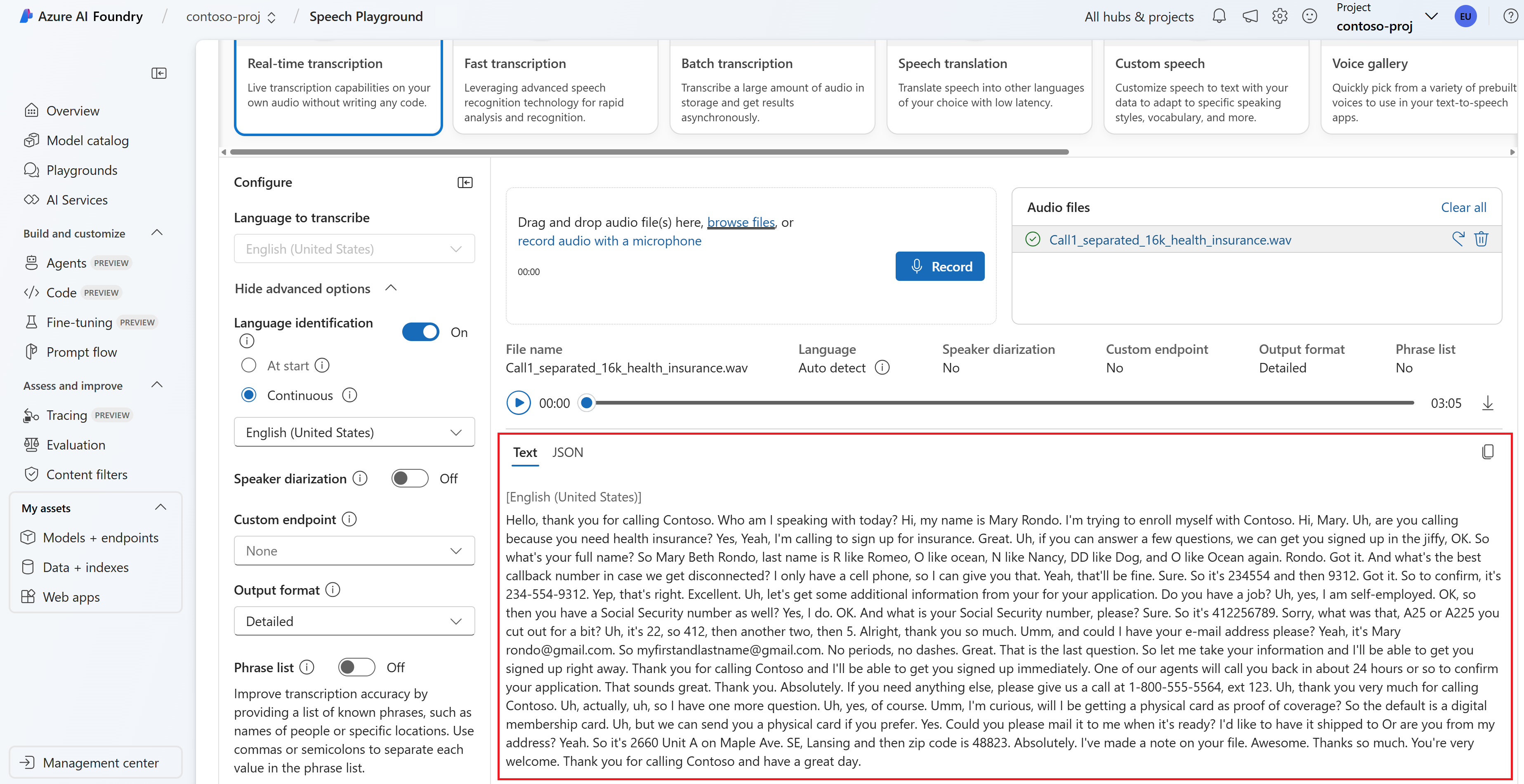
You can select the JSON tab to see the JSON output of the transcription. Properties include
Offset,Duration,RecognitionStatus,Display,Lexical,ITN, and more.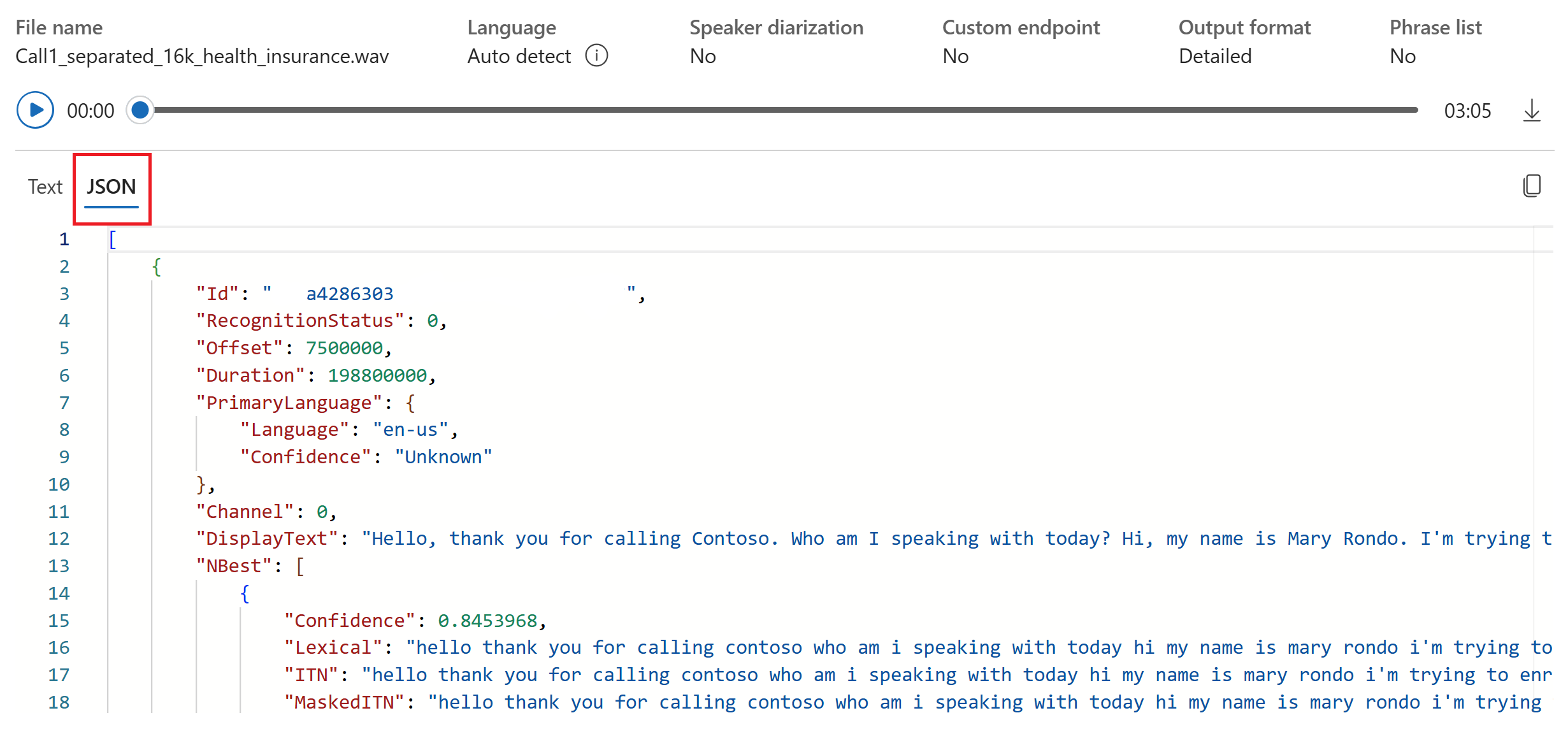





Reference documentation | Package (NuGet) | Additional samples on GitHub
In this quickstart, you create and run an application to recognize and transcribe speech to text in real-time.
To instead transcribe audio files asynchronously, see What is batch transcription. If you're not sure which speech to text solution is right for you, see What is speech to text?
Prerequisites
- An Azure subscription. You can create one for free.
- Create a Speech resource in the Azure portal.
- Get the Speech resource key and region. After your Speech resource is deployed, select Go to resource to view and manage keys.
Set up the environment
The Speech SDK is available as a NuGet package and implements .NET Standard 2.0. You install the Speech SDK later in this guide. For any other requirements, see Install the Speech SDK.
Set environment variables
You need to authenticate your application to access Azure AI services. This article shows you how to use environment variables to store your credentials. You can then access the environment variables from your code to authenticate your application. For production, use a more secure way to store and access your credentials.
Important
We recommend Microsoft Entra ID authentication with managed identities for Azure resources to avoid storing credentials with your applications that run in the cloud.
If you use an API key, store it securely somewhere else, such as in Azure Key Vault. Don't include the API key directly in your code, and never post it publicly.
For more information about AI services security, see Authenticate requests to Azure AI services.
To set the environment variables for your Speech resource key and region, open a console window, and follow the instructions for your operating system and development environment.
- To set the
SPEECH_KEYenvironment variable, replace your-key with one of the keys for your resource. - To set the
SPEECH_REGIONenvironment variable, replace your-region with one of the regions for your resource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Note
If you only need to access the environment variables in the current console, you can set the environment variable with set instead of setx.
After you add the environment variables, you might need to restart any programs that need to read the environment variables, including the console window. For example, if you're using Visual Studio as your editor, restart Visual Studio before you run the example.
Recognize speech from a microphone
Tip
Try out the Azure AI Speech Toolkit to easily build and run samples on Visual Studio Code.
Follow these steps to create a console application and install the Speech SDK.
Open a command prompt window in the folder where you want the new project. Run this command to create a console application with the .NET CLI.
dotnet new consoleThis command creates the Program.cs file in your project directory.
Install the Speech SDK in your new project with the .NET CLI.
dotnet add package Microsoft.CognitiveServices.SpeechReplace the contents of Program.cs with the following code:
using System; using System.IO; using System.Threading.Tasks; using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; class Program { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); static void OutputSpeechRecognitionResult(SpeechRecognitionResult speechRecognitionResult) { switch (speechRecognitionResult.Reason) { case ResultReason.RecognizedSpeech: Console.WriteLine($"RECOGNIZED: Text={speechRecognitionResult.Text}"); break; case ResultReason.NoMatch: Console.WriteLine($"NOMATCH: Speech could not be recognized."); break; case ResultReason.Canceled: var cancellation = CancellationDetails.FromResult(speechRecognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?"); } break; } } async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); using var speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); Console.WriteLine("Speak into your microphone."); var speechRecognitionResult = await speechRecognizer.RecognizeOnceAsync(); OutputSpeechRecognitionResult(speechRecognitionResult); } }To change the speech recognition language, replace
en-USwith another supported language. For example, usees-ESfor Spanish (Spain). If you don't specify a language, the default isen-US. For details about how to identify one of multiple languages that might be spoken, see Language identification.Run your new console application to start speech recognition from a microphone:
dotnet runImportant
Make sure that you set the
SPEECH_KEYandSPEECH_REGIONenvironment variables. If you don't set these variables, the sample fails with an error message.Speak into your microphone when prompted. What you speak should appear as text:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Remarks
Here are some other considerations:
This example uses the
RecognizeOnceAsyncoperation to transcribe utterances of up to 30 seconds, or until silence is detected. For information about continuous recognition for longer audio, including multi-lingual conversations, see How to recognize speech.To recognize speech from an audio file, use
FromWavFileInputinstead ofFromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav");For compressed audio files such as MP4, install GStreamer and use
PullAudioInputStreamorPushAudioInputStream. For more information, see How to use compressed input audio.
Clean up resources
You can use the Azure portal or Azure Command Line Interface (CLI) to remove the Speech resource you created.
Reference documentation | Package (NuGet) | Additional samples on GitHub
In this quickstart, you create and run an application to recognize and transcribe speech to text in real-time.
To instead transcribe audio files asynchronously, see What is batch transcription. If you're not sure which speech to text solution is right for you, see What is speech to text?
Prerequisites
- An Azure subscription. You can create one for free.
- Create a Speech resource in the Azure portal.
- Get the Speech resource key and region. After your Speech resource is deployed, select Go to resource to view and manage keys.
Set up the environment
The Speech SDK is available as a NuGet package and implements .NET Standard 2.0. You install the Speech SDK later in this guide. For other requirements, see Install the Speech SDK.
Set environment variables
You need to authenticate your application to access Azure AI services. This article shows you how to use environment variables to store your credentials. You can then access the environment variables from your code to authenticate your application. For production, use a more secure way to store and access your credentials.
Important
We recommend Microsoft Entra ID authentication with managed identities for Azure resources to avoid storing credentials with your applications that run in the cloud.
If you use an API key, store it securely somewhere else, such as in Azure Key Vault. Don't include the API key directly in your code, and never post it publicly.
For more information about AI services security, see Authenticate requests to Azure AI services.
To set the environment variables for your Speech resource key and region, open a console window, and follow the instructions for your operating system and development environment.
- To set the
SPEECH_KEYenvironment variable, replace your-key with one of the keys for your resource. - To set the
SPEECH_REGIONenvironment variable, replace your-region with one of the regions for your resource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Note
If you only need to access the environment variables in the current console, you can set the environment variable with set instead of setx.
After you add the environment variables, you might need to restart any programs that need to read the environment variables, including the console window. For example, if you're using Visual Studio as your editor, restart Visual Studio before you run the example.
Recognize speech from a microphone
Tip
Try out the Azure AI Speech Toolkit to easily build and run samples on Visual Studio Code.
Follow these steps to create a console application and install the Speech SDK.
Create a new C++ console project in Visual Studio Community named
SpeechRecognition.Select Tools > Nuget Package Manager > Package Manager Console. In the Package Manager Console, run this command:
Install-Package Microsoft.CognitiveServices.SpeechReplace the contents of
SpeechRecognition.cppwith the following code:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); if ((size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set both SPEECH_KEY and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto speechRecognizer = SpeechRecognizer::FromConfig(speechConfig, audioConfig); std::cout << "Speak into your microphone.\n"; auto result = speechRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }To change the speech recognition language, replace
en-USwith another supported language. For example, usees-ESfor Spanish (Spain). If you don't specify a language, the default isen-US. For details about how to identify one of multiple languages that might be spoken, see Language identification.Build and run your new console application to start speech recognition from a microphone.
Important
Make sure that you set the
SPEECH_KEYandSPEECH_REGIONenvironment variables. If you don't set these variables, the sample fails with an error message.Speak into your microphone when prompted. What you speak should appear as text:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Remarks
Here are some other considerations:
This example uses the
RecognizeOnceAsyncoperation to transcribe utterances of up to 30 seconds, or until silence is detected. For information about continuous recognition for longer audio, including multi-lingual conversations, see How to recognize speech.To recognize speech from an audio file, use
FromWavFileInputinstead ofFromDefaultMicrophoneInput:auto audioConfig = AudioConfig::FromWavFileInput("YourAudioFile.wav");For compressed audio files such as MP4, install GStreamer and use
PullAudioInputStreamorPushAudioInputStream. For more information, see How to use compressed input audio.
Clean up resources
You can use the Azure portal or Azure Command Line Interface (CLI) to remove the Speech resource you created.
Reference documentation | Package (Go) | Additional samples on GitHub
In this quickstart, you create and run an application to recognize and transcribe speech to text in real-time.
To instead transcribe audio files asynchronously, see What is batch transcription. If you're not sure which speech to text solution is right for you, see What is speech to text?
Prerequisites
- An Azure subscription. You can create one for free.
- Create a Speech resource in the Azure portal.
- Get the Speech resource key and region. After your Speech resource is deployed, select Go to resource to view and manage keys.
Set up the environment
Install the Speech SDK for Go. For requirements and instructions, see Install the Speech SDK.
Set environment variables
You need to authenticate your application to access Azure AI services. This article shows you how to use environment variables to store your credentials. You can then access the environment variables from your code to authenticate your application. For production, use a more secure way to store and access your credentials.
Important
We recommend Microsoft Entra ID authentication with managed identities for Azure resources to avoid storing credentials with your applications that run in the cloud.
If you use an API key, store it securely somewhere else, such as in Azure Key Vault. Don't include the API key directly in your code, and never post it publicly.
For more information about AI services security, see Authenticate requests to Azure AI services.
To set the environment variables for your Speech resource key and region, open a console window, and follow the instructions for your operating system and development environment.
- To set the
SPEECH_KEYenvironment variable, replace your-key with one of the keys for your resource. - To set the
SPEECH_REGIONenvironment variable, replace your-region with one of the regions for your resource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Note
If you only need to access the environment variables in the current console, you can set the environment variable with set instead of setx.
After you add the environment variables, you might need to restart any programs that need to read the environment variables, including the console window. For example, if you're using Visual Studio as your editor, restart Visual Studio before you run the example.
Recognize speech from a microphone
Follow these steps to create a GO module.
Open a command prompt window in the folder where you want the new project. Create a new file named speech-recognition.go.
Copy the following code into speech-recognition.go:
package main import ( "bufio" "fmt" "os" "github.com/Microsoft/cognitive-services-speech-sdk-go/audio" "github.com/Microsoft/cognitive-services-speech-sdk-go/speech" ) func sessionStartedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Started (ID=", event.SessionID, ")") } func sessionStoppedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Stopped (ID=", event.SessionID, ")") } func recognizingHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognizing:", event.Result.Text) } func recognizedHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognized:", event.Result.Text) } func cancelledHandler(event speech.SpeechRecognitionCanceledEventArgs) { defer event.Close() fmt.Println("Received a cancellation: ", event.ErrorDetails) fmt.Println("Did you set the speech resource key and region values?") } func main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speechKey := os.Getenv("SPEECH_KEY") speechRegion := os.Getenv("SPEECH_REGION") audioConfig, err := audio.NewAudioConfigFromDefaultMicrophoneInput() if err != nil { fmt.Println("Got an error: ", err) return } defer audioConfig.Close() speechConfig, err := speech.NewSpeechConfigFromSubscription(speechKey, speechRegion) if err != nil { fmt.Println("Got an error: ", err) return } defer speechConfig.Close() speechRecognizer, err := speech.NewSpeechRecognizerFromConfig(speechConfig, audioConfig) if err != nil { fmt.Println("Got an error: ", err) return } defer speechRecognizer.Close() speechRecognizer.SessionStarted(sessionStartedHandler) speechRecognizer.SessionStopped(sessionStoppedHandler) speechRecognizer.Recognizing(recognizingHandler) speechRecognizer.Recognized(recognizedHandler) speechRecognizer.Canceled(cancelledHandler) speechRecognizer.StartContinuousRecognitionAsync() defer speechRecognizer.StopContinuousRecognitionAsync() bufio.NewReader(os.Stdin).ReadBytes('\n') }Run the following commands to create a go.mod file that links to components hosted on GitHub:
go mod init speech-recognition go get github.com/Microsoft/cognitive-services-speech-sdk-goImportant
Make sure that you set the
SPEECH_KEYandSPEECH_REGIONenvironment variables. If you don't set these variables, the sample fails with an error message.Build and run the code:
go build go run speech-recognition
Clean up resources
You can use the Azure portal or Azure Command Line Interface (CLI) to remove the Speech resource you created.
Reference documentation | Additional samples on GitHub
In this quickstart, you create and run an application to recognize and transcribe speech to text in real-time.
To instead transcribe audio files asynchronously, see What is batch transcription. If you're not sure which speech to text solution is right for you, see What is speech to text?
Prerequisites
- An Azure subscription. You can create one for free.
- Create a Speech resource in the Azure portal.
- Get the Speech resource key and region. After your Speech resource is deployed, select Go to resource to view and manage keys.
Set up the environment
To set up your environment, install the Speech SDK. The sample in this quickstart works with the Java Runtime.
Install Apache Maven. Then run
mvn -vto confirm successful installation.Create a new
pom.xmlfile in the root of your project, and copy the following code into it:<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.microsoft.cognitiveservices.speech.samples</groupId> <artifactId>quickstart-eclipse</artifactId> <version>1.0.0-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>com.microsoft.cognitiveservices.speech</groupId> <artifactId>client-sdk</artifactId> <version>1.42.0</version> </dependency> </dependencies> </project>Install the Speech SDK and dependencies.
mvn clean dependency:copy-dependencies
Set environment variables
You need to authenticate your application to access Azure AI services. This article shows you how to use environment variables to store your credentials. You can then access the environment variables from your code to authenticate your application. For production, use a more secure way to store and access your credentials.
Important
We recommend Microsoft Entra ID authentication with managed identities for Azure resources to avoid storing credentials with your applications that run in the cloud.
If you use an API key, store it securely somewhere else, such as in Azure Key Vault. Don't include the API key directly in your code, and never post it publicly.
For more information about AI services security, see Authenticate requests to Azure AI services.
To set the environment variables for your Speech resource key and region, open a console window, and follow the instructions for your operating system and development environment.
- To set the
SPEECH_KEYenvironment variable, replace your-key with one of the keys for your resource. - To set the
SPEECH_REGIONenvironment variable, replace your-region with one of the regions for your resource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Note
If you only need to access the environment variables in the current console, you can set the environment variable with set instead of setx.
After you add the environment variables, you might need to restart any programs that need to read the environment variables, including the console window. For example, if you're using Visual Studio as your editor, restart Visual Studio before you run the example.
Recognize speech from a microphone
Follow these steps to create a console application for speech recognition.
Create a new file named SpeechRecognition.java in the same project root directory.
Copy the following code into SpeechRecognition.java:
import com.microsoft.cognitiveservices.speech.*; import com.microsoft.cognitiveservices.speech.audio.AudioConfig; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; public class SpeechRecognition { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" private static String speechKey = System.getenv("SPEECH_KEY"); private static String speechRegion = System.getenv("SPEECH_REGION"); public static void main(String[] args) throws InterruptedException, ExecutionException { SpeechConfig speechConfig = SpeechConfig.fromSubscription(speechKey, speechRegion); speechConfig.setSpeechRecognitionLanguage("en-US"); recognizeFromMicrophone(speechConfig); } public static void recognizeFromMicrophone(SpeechConfig speechConfig) throws InterruptedException, ExecutionException { AudioConfig audioConfig = AudioConfig.fromDefaultMicrophoneInput(); SpeechRecognizer speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); System.out.println("Speak into your microphone."); Future<SpeechRecognitionResult> task = speechRecognizer.recognizeOnceAsync(); SpeechRecognitionResult speechRecognitionResult = task.get(); if (speechRecognitionResult.getReason() == ResultReason.RecognizedSpeech) { System.out.println("RECOGNIZED: Text=" + speechRecognitionResult.getText()); } else if (speechRecognitionResult.getReason() == ResultReason.NoMatch) { System.out.println("NOMATCH: Speech could not be recognized."); } else if (speechRecognitionResult.getReason() == ResultReason.Canceled) { CancellationDetails cancellation = CancellationDetails.fromResult(speechRecognitionResult); System.out.println("CANCELED: Reason=" + cancellation.getReason()); if (cancellation.getReason() == CancellationReason.Error) { System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode()); System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails()); System.out.println("CANCELED: Did you set the speech resource key and region values?"); } } System.exit(0); } }To change the speech recognition language, replace
en-USwith another supported language. For example, usees-ESfor Spanish (Spain). If you don't specify a language, the default isen-US. For details about how to identify one of multiple languages that might be spoken, see Language identification.Run your new console application to start speech recognition from a microphone:
javac SpeechRecognition.java -cp ".;target\dependency\*" java -cp ".;target\dependency\*" SpeechRecognitionImportant
Make sure that you set the
SPEECH_KEYandSPEECH_REGIONenvironment variables. If you don't set these variables, the sample fails with an error message.Speak into your microphone when prompted. What you speak should appear as text:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Remarks
Here are some other considerations:
This example uses the
RecognizeOnceAsyncoperation to transcribe utterances of up to 30 seconds, or until silence is detected. For information about continuous recognition for longer audio, including multi-lingual conversations, see How to recognize speech.To recognize speech from an audio file, use
fromWavFileInputinstead offromDefaultMicrophoneInput:AudioConfig audioConfig = AudioConfig.fromWavFileInput("YourAudioFile.wav");For compressed audio files such as MP4, install GStreamer and use
PullAudioInputStreamorPushAudioInputStream. For more information, see How to use compressed input audio.
Clean up resources
You can use the Azure portal or Azure Command Line Interface (CLI) to remove the Speech resource you created.
Reference documentation | Package (npm) | Additional samples on GitHub | Library source code
In this quickstart, you create and run an application to recognize and transcribe speech to text in real-time.
To instead transcribe audio files asynchronously, see What is batch transcription. If you're not sure which speech to text solution is right for you, see What is speech to text?
Prerequisites
- An Azure subscription. You can create one for free.
- Create a Speech resource in the Azure portal.
- Get the Speech resource key and region. After your Speech resource is deployed, select Go to resource to view and manage keys.
You also need a .wav audio file on your local machine. You can use your own .wav file (up to 30 seconds) or download the https://crbn.us/whatstheweatherlike.wav sample file.
Set up the environment
To set up your environment, install the Speech SDK for JavaScript. Run this command: npm install microsoft-cognitiveservices-speech-sdk. For guided installation instructions, see Install the Speech SDK.
Set environment variables
You need to authenticate your application to access Azure AI services. This article shows you how to use environment variables to store your credentials. You can then access the environment variables from your code to authenticate your application. For production, use a more secure way to store and access your credentials.
Important
We recommend Microsoft Entra ID authentication with managed identities for Azure resources to avoid storing credentials with your applications that run in the cloud.
If you use an API key, store it securely somewhere else, such as in Azure Key Vault. Don't include the API key directly in your code, and never post it publicly.
For more information about AI services security, see Authenticate requests to Azure AI services.
To set the environment variables for your Speech resource key and region, open a console window, and follow the instructions for your operating system and development environment.
- To set the
SPEECH_KEYenvironment variable, replace your-key with one of the keys for your resource. - To set the
SPEECH_REGIONenvironment variable, replace your-region with one of the regions for your resource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Note
If you only need to access the environment variables in the current console, you can set the environment variable with set instead of setx.
After you add the environment variables, you might need to restart any programs that need to read the environment variables, including the console window. For example, if you're using Visual Studio as your editor, restart Visual Studio before you run the example.
Recognize speech from a file
Tip
Try out the Azure AI Speech Toolkit to easily build and run samples on Visual Studio Code.
Follow these steps to create a Node.js console application for speech recognition.
Open a command prompt window where you want the new project, and create a new file named SpeechRecognition.js.
Install the Speech SDK for JavaScript:
npm install microsoft-cognitiveservices-speech-sdkCopy the following code into SpeechRecognition.js:
const fs = require("fs"); const sdk = require("microsoft-cognitiveservices-speech-sdk"); // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" const speechConfig = sdk.SpeechConfig.fromSubscription(process.env.SPEECH_KEY, process.env.SPEECH_REGION); speechConfig.speechRecognitionLanguage = "en-US"; function fromFile() { let audioConfig = sdk.AudioConfig.fromWavFileInput(fs.readFileSync("YourAudioFile.wav")); let speechRecognizer = new sdk.SpeechRecognizer(speechConfig, audioConfig); speechRecognizer.recognizeOnceAsync(result => { switch (result.reason) { case sdk.ResultReason.RecognizedSpeech: console.log(`RECOGNIZED: Text=${result.text}`); break; case sdk.ResultReason.NoMatch: console.log("NOMATCH: Speech could not be recognized."); break; case sdk.ResultReason.Canceled: const cancellation = sdk.CancellationDetails.fromResult(result); console.log(`CANCELED: Reason=${cancellation.reason}`); if (cancellation.reason == sdk.CancellationReason.Error) { console.log(`CANCELED: ErrorCode=${cancellation.ErrorCode}`); console.log(`CANCELED: ErrorDetails=${cancellation.errorDetails}`); console.log("CANCELED: Did you set the speech resource key and region values?"); } break; } speechRecognizer.close(); }); } fromFile();In SpeechRecognition.js, replace YourAudioFile.wav with your own .wav file. This example only recognizes speech from a .wav file. For information about other audio formats, see How to use compressed input audio. This example supports up to 30 seconds of audio.
To change the speech recognition language, replace
en-USwith another supported language. For example, usees-ESfor Spanish (Spain). If you don't specify a language, the default isen-US. For details about how to identify one of multiple languages that might be spoken, see Language identification.Run your new console application to start speech recognition from a file:
node.exe SpeechRecognition.jsImportant
Make sure that you set the
SPEECH_KEYandSPEECH_REGIONenvironment variables. If you don't set these variables, the sample fails with an error message.The speech from the audio file should be output as text:
RECOGNIZED: Text=I'm excited to try speech to text.
Remarks
This example uses the recognizeOnceAsync operation to transcribe utterances of up to 30 seconds, or until silence is detected. For information about continuous recognition for longer audio, including multi-lingual conversations, see How to recognize speech.
Note
Recognizing speech from a microphone is not supported in Node.js. It's supported only in a browser-based JavaScript environment. For more information, see the React sample and the implementation of speech to text from a microphone on GitHub.
The React sample shows design patterns for the exchange and management of authentication tokens. It also shows the capture of audio from a microphone or file for speech to text conversions.
Clean up resources
You can use the Azure portal or Azure Command Line Interface (CLI) to remove the Speech resource you created.
Reference documentation | Package (PyPi) | Additional samples on GitHub
In this quickstart, you create and run an application to recognize and transcribe speech to text in real-time.
To instead transcribe audio files asynchronously, see What is batch transcription. If you're not sure which speech to text solution is right for you, see What is speech to text?
Prerequisites
- An Azure subscription. You can create one for free.
- Create a Speech resource in the Azure portal.
- Get the Speech resource key and region. After your Speech resource is deployed, select Go to resource to view and manage keys.
Set up the environment
The Speech SDK for Python is available as a Python Package Index (PyPI) module. The Speech SDK for Python is compatible with Windows, Linux, and macOS.
- For Windows, install the Microsoft Visual C++ Redistributable for Visual Studio 2015, 2017, 2019, and 2022 for your platform. Installing this package for the first time might require a restart.
- On Linux, you must use the x64 target architecture.
Install a version of Python from 3.7 or later. For other requirements, see Install the Speech SDK.
Set environment variables
You need to authenticate your application to access Azure AI services. This article shows you how to use environment variables to store your credentials. You can then access the environment variables from your code to authenticate your application. For production, use a more secure way to store and access your credentials.
Important
We recommend Microsoft Entra ID authentication with managed identities for Azure resources to avoid storing credentials with your applications that run in the cloud.
If you use an API key, store it securely somewhere else, such as in Azure Key Vault. Don't include the API key directly in your code, and never post it publicly.
For more information about AI services security, see Authenticate requests to Azure AI services.
To set the environment variables for your Speech resource key and region, open a console window, and follow the instructions for your operating system and development environment.
- To set the
SPEECH_KEYenvironment variable, replace your-key with one of the keys for your resource. - To set the
SPEECH_REGIONenvironment variable, replace your-region with one of the regions for your resource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Note
If you only need to access the environment variables in the current console, you can set the environment variable with set instead of setx.
After you add the environment variables, you might need to restart any programs that need to read the environment variables, including the console window. For example, if you're using Visual Studio as your editor, restart Visual Studio before you run the example.
Recognize speech from a microphone
Tip
Try out the Azure AI Speech Toolkit to easily build and run samples on Visual Studio Code.
Follow these steps to create a console application.
Open a command prompt window in the folder where you want the new project. Create a new file named speech_recognition.py.
Run this command to install the Speech SDK:
pip install azure-cognitiveservices-speechCopy the following code into speech_recognition.py:
import os import azure.cognitiveservices.speech as speechsdk def recognize_from_microphone(): # This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('SPEECH_KEY'), region=os.environ.get('SPEECH_REGION')) speech_config.speech_recognition_language="en-US" audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True) speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config) print("Speak into your microphone.") speech_recognition_result = speech_recognizer.recognize_once_async().get() if speech_recognition_result.reason == speechsdk.ResultReason.RecognizedSpeech: print("Recognized: {}".format(speech_recognition_result.text)) elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized: {}".format(speech_recognition_result.no_match_details)) elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled: cancellation_details = speech_recognition_result.cancellation_details print("Speech Recognition canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) print("Did you set the speech resource key and region values?") recognize_from_microphone()To change the speech recognition language, replace
en-USwith another supported language. For example, usees-ESfor Spanish (Spain). If you don't specify a language, the default isen-US. For details about how to identify one of multiple languages that might be spoken, see language identification.Run your new console application to start speech recognition from a microphone:
python speech_recognition.pyImportant
Make sure that you set the
SPEECH_KEYandSPEECH_REGIONenvironment variables. If you don't set these variables, the sample fails with an error message.Speak into your microphone when prompted. What you speak should appear as text:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Remarks
Here are some other considerations:
This example uses the
recognize_once_asyncoperation to transcribe utterances of up to 30 seconds, or until silence is detected. For information about continuous recognition for longer audio, including multi-lingual conversations, see How to recognize speech.To recognize speech from an audio file, use
filenameinstead ofuse_default_microphone:audio_config = speechsdk.audio.AudioConfig(filename="YourAudioFile.wav")For compressed audio files such as MP4, install GStreamer and use
PullAudioInputStreamorPushAudioInputStream. For more information, see How to use compressed input audio.
Clean up resources
You can use the Azure portal or Azure Command Line Interface (CLI) to remove the Speech resource you created.
Reference documentation | Package (download) | Additional samples on GitHub
In this quickstart, you create and run an application to recognize and transcribe speech to text in real-time.
To instead transcribe audio files asynchronously, see What is batch transcription. If you're not sure which speech to text solution is right for you, see What is speech to text?
Prerequisites
- An Azure subscription. You can create one for free.
- Create a Speech resource in the Azure portal.
- Get the Speech resource key and region. After your Speech resource is deployed, select Go to resource to view and manage keys.
Set up the environment
The Speech SDK for Swift is distributed as a framework bundle. The framework supports both Objective-C and Swift on both iOS and macOS.
The Speech SDK can be used in Xcode projects as a CocoaPod, or downloaded directly and linked manually. This guide uses a CocoaPod. Install the CocoaPod dependency manager as described in its installation instructions.
Set environment variables
You need to authenticate your application to access Azure AI services. This article shows you how to use environment variables to store your credentials. You can then access the environment variables from your code to authenticate your application. For production, use a more secure way to store and access your credentials.
Important
We recommend Microsoft Entra ID authentication with managed identities for Azure resources to avoid storing credentials with your applications that run in the cloud.
If you use an API key, store it securely somewhere else, such as in Azure Key Vault. Don't include the API key directly in your code, and never post it publicly.
For more information about AI services security, see Authenticate requests to Azure AI services.
To set the environment variables for your Speech resource key and region, open a console window, and follow the instructions for your operating system and development environment.
- To set the
SPEECH_KEYenvironment variable, replace your-key with one of the keys for your resource. - To set the
SPEECH_REGIONenvironment variable, replace your-region with one of the regions for your resource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Note
If you only need to access the environment variables in the current console, you can set the environment variable with set instead of setx.
After you add the environment variables, you might need to restart any programs that need to read the environment variables, including the console window. For example, if you're using Visual Studio as your editor, restart Visual Studio before you run the example.
Recognize speech from a microphone
Follow these steps to recognize speech in a macOS application.
Clone the Azure-Samples/cognitive-services-speech-sdk repository to get the Recognize speech from a microphone in Swift on macOS sample project. The repository also has iOS samples.
Navigate to the directory of the downloaded sample app (
helloworld) in a terminal.Run the command
pod install. This command generates ahelloworld.xcworkspaceXcode workspace containing both the sample app and the Speech SDK as a dependency.Open the
helloworld.xcworkspaceworkspace in Xcode.Open the file named AppDelegate.swift and locate the
applicationDidFinishLaunchingandrecognizeFromMicmethods as shown here.import Cocoa @NSApplicationMain class AppDelegate: NSObject, NSApplicationDelegate { var label: NSTextField! var fromMicButton: NSButton! var sub: String! var region: String! @IBOutlet weak var window: NSWindow! func applicationDidFinishLaunching(_ aNotification: Notification) { print("loading") // load subscription information sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"] label = NSTextField(frame: NSRect(x: 100, y: 50, width: 200, height: 200)) label.textColor = NSColor.black label.lineBreakMode = .byWordWrapping label.stringValue = "Recognition Result" label.isEditable = false self.window.contentView?.addSubview(label) fromMicButton = NSButton(frame: NSRect(x: 100, y: 300, width: 200, height: 30)) fromMicButton.title = "Recognize" fromMicButton.target = self fromMicButton.action = #selector(fromMicButtonClicked) self.window.contentView?.addSubview(fromMicButton) } @objc func fromMicButtonClicked() { DispatchQueue.global(qos: .userInitiated).async { self.recognizeFromMic() } } func recognizeFromMic() { var speechConfig: SPXSpeechConfiguration? do { try speechConfig = SPXSpeechConfiguration(subscription: sub, region: region) } catch { print("error \(error) happened") speechConfig = nil } speechConfig?.speechRecognitionLanguage = "en-US" let audioConfig = SPXAudioConfiguration() let reco = try! SPXSpeechRecognizer(speechConfiguration: speechConfig!, audioConfiguration: audioConfig) reco.addRecognizingEventHandler() {reco, evt in print("intermediate recognition result: \(evt.result.text ?? "(no result)")") self.updateLabel(text: evt.result.text, color: .gray) } updateLabel(text: "Listening ...", color: .gray) print("Listening...") let result = try! reco.recognizeOnce() print("recognition result: \(result.text ?? "(no result)"), reason: \(result.reason.rawValue)") updateLabel(text: result.text, color: .black) if result.reason != SPXResultReason.recognizedSpeech { let cancellationDetails = try! SPXCancellationDetails(fromCanceledRecognitionResult: result) print("cancelled: \(result.reason), \(cancellationDetails.errorDetails)") print("Did you set the speech resource key and region values?") updateLabel(text: "Error: \(cancellationDetails.errorDetails)", color: .red) } } func updateLabel(text: String?, color: NSColor) { DispatchQueue.main.async { self.label.stringValue = text! self.label.textColor = color } } }In AppDelegate.m, use the environment variables that you previously set for your Speech resource key and region.
sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"]To change the speech recognition language, replace
en-USwith another supported language. For example, usees-ESfor Spanish (Spain). If you don't specify a language, the default isen-US. For details about how to identify one of multiple languages that might be spoken, see Language identification.To make the debug output visible, select View > Debug Area > Activate Console.
Build and run the example code by selecting Product > Run from the menu or selecting the Play button.
Important
Make sure that you set the
SPEECH_KEYandSPEECH_REGIONenvironment variables. If you don't set these variables, the sample fails with an error message.
After you select the button in the app and say a few words, you should see the text that you spoke on the lower part of the screen. When you run the app for the first time, it prompts you to give the app access to your computer's microphone.
Remarks
This example uses the recognizeOnce operation to transcribe utterances of up to 30 seconds, or until silence is detected. For information about continuous recognition for longer audio, including multi-lingual conversations, see How to recognize speech.
Objective-C
The Speech SDK for Objective-C shares client libraries and reference documentation with the Speech SDK for Swift. For Objective-C code examples, see the recognize speech from a microphone in Objective-C on macOS sample project in GitHub.
Clean up resources
You can use the Azure portal or Azure Command Line Interface (CLI) to remove the Speech resource you created.
Speech to text REST API reference | Speech to text REST API for short audio reference | Additional samples on GitHub
In this quickstart, you create and run an application to recognize and transcribe speech to text in real-time.
To instead transcribe audio files asynchronously, see What is batch transcription. If you're not sure which speech to text solution is right for you, see What is speech to text?
Prerequisites
- An Azure subscription. You can create one for free.
- Create a Speech resource in the Azure portal.
- Get the Speech resource key and region. After your Speech resource is deployed, select Go to resource to view and manage keys.
You also need a .wav audio file on your local machine. You can use your own .wav file up to 60 seconds or download the https://crbn.us/whatstheweatherlike.wav sample file.
Set environment variables
You need to authenticate your application to access Azure AI services. This article shows you how to use environment variables to store your credentials. You can then access the environment variables from your code to authenticate your application. For production, use a more secure way to store and access your credentials.
Important
We recommend Microsoft Entra ID authentication with managed identities for Azure resources to avoid storing credentials with your applications that run in the cloud.
If you use an API key, store it securely somewhere else, such as in Azure Key Vault. Don't include the API key directly in your code, and never post it publicly.
For more information about AI services security, see Authenticate requests to Azure AI services.
To set the environment variables for your Speech resource key and region, open a console window, and follow the instructions for your operating system and development environment.
- To set the
SPEECH_KEYenvironment variable, replace your-key with one of the keys for your resource. - To set the
SPEECH_REGIONenvironment variable, replace your-region with one of the regions for your resource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Note
If you only need to access the environment variables in the current console, you can set the environment variable with set instead of setx.
After you add the environment variables, you might need to restart any programs that need to read the environment variables, including the console window. For example, if you're using Visual Studio as your editor, restart Visual Studio before you run the example.
Recognize speech from a file
Open a console window and run the following cURL command. Replace YourAudioFile.wav with the path and name of your audio file.
curl --location --request POST "https://%SPEECH_REGION%.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed" ^
--header "Ocp-Apim-Subscription-Key: %SPEECH_KEY%" ^
--header "Content-Type: audio/wav" ^
--data-binary "@YourAudioFile.wav"
Important
Make sure that you set the SPEECH_KEY and SPEECH_REGION environment variables. If you don't set these variables, the sample fails with an error message.
You should receive a response similar to what is shown here. The DisplayText should be the text that was recognized from your audio file. The command recognizes up to 60 seconds of audio and converts it to text.
{
"RecognitionStatus": "Success",
"DisplayText": "My voice is my passport, verify me.",
"Offset": 6600000,
"Duration": 32100000
}
For more information, see Speech to text REST API for short audio.
Clean up resources
You can use the Azure portal or Azure Command Line Interface (CLI) to remove the Speech resource you created.
In this quickstart, you create and run an application to recognize and transcribe speech to text in real-time.
To instead transcribe audio files asynchronously, see What is batch transcription. If you're not sure which speech to text solution is right for you, see What is speech to text?
Prerequisites
- An Azure subscription. You can create one for free.
- Create a Speech resource in the Azure portal.
- Get the Speech resource key and region. After your Speech resource is deployed, select Go to resource to view and manage keys.
Set up the environment
Follow these steps and see the Speech CLI quickstart for other requirements for your platform.
Run the following .NET CLI command to install the Speech CLI:
dotnet tool install --global Microsoft.CognitiveServices.Speech.CLIRun the following commands to configure your Speech resource key and region. Replace
SUBSCRIPTION-KEYwith your Speech resource key and replaceREGIONwith your Speech resource region.spx config @key --set SUBSCRIPTION-KEY spx config @region --set REGION
Recognize speech from a microphone
Run the following command to start speech recognition from a microphone:
spx recognize --microphone --source en-USSpeak into the microphone, and you see transcription of your words into text in real-time. The Speech CLI stops after a period of silence, 30 seconds, or when you select Ctrl+C.
Connection CONNECTED... RECOGNIZED: I'm excited to try speech to text.
Remarks
Here are some other considerations:
To recognize speech from an audio file, use
--fileinstead of--microphone. For compressed audio files such as MP4, install GStreamer and use--format. For more information, see How to use compressed input audio.spx recognize --file YourAudioFile.wav spx recognize --file YourAudioFile.mp4 --format anyTo improve recognition accuracy of specific words or utterances, use a phrase list. You include a phrase list in-line or with a text file along with the
recognizecommand:spx recognize --microphone --phrases "Contoso;Jessie;Rehaan;" spx recognize --microphone --phrases @phrases.txtTo change the speech recognition language, replace
en-USwith another supported language. For example, usees-ESfor Spanish (Spain). If you don't specify a language, the default isen-US.spx recognize --microphone --source es-ESFor continuous recognition of audio longer than 30 seconds, append
--continuous:spx recognize --microphone --source es-ES --continuousRun this command for information about more speech recognition options such as file input and output:
spx help recognize
Clean up resources
You can use the Azure portal or Azure Command Line Interface (CLI) to remove the Speech resource you created.