Основы построения In-Memory optimized СУБД SQL Server 2014
Впервые появившееся в SQL Server 2014 In-Memory OLTP — это оптимизированное для исполнения только в памяти ядро СУБД, встроенное в основной SQL Server, оптимизированный для OLTP.
In-Memory OLTP более всего повышает производительность в OLTP системах с короткими транзакциями.
Интеграция со средствами SQL Server означает, что в одной базе данных можно иметь как оптимизированные для исполнения в памяти таблицы, так и дисковые таблицы, а также запрашивать оба типа таблиц.
In-Memory OLTP помогает добиться значительного повышения производительности и масштабируемости с помощью:
- оптимизированных для доступа к данным, хранимым в памяти ;
- управления оптимистичным параллелизмом, устраняющим логические блокировки;
- объектов без блокировки, которые используются для получения всех данных. Потоки, выполняющие транзакционную работу, не используют блокировки или кратковременные блокировки для управления параллелизмом.
- хранимых процедур, скомпилированных в коде языка "С", что на порядок сокращают время выполнения кода.
Для понимания принципов построения и работы с In-Memory СУРБД необходимо рассмотреть:
- организацию хранения данных;
- организацию и использования индексов;
- организацию доступа к данным;
- особенности использования и ограничения.
Давайте для начала определимся с некоторыми базовыми понятиями, чтобы в дальнейшем разговаривать на одном языке.
- "In-Memory OLTP database" - OLTP база данных оптимизированная для хранения и обработки в оперативной памяти
- "Disk based OLTP database" - класичесикая OLTP база данных оптимизированная для хранения и обработки данных с диска.
- "Memory optimized tables" это таблицы In-Memory OLTP базы данных, которые оптимизированы для доступа при их полном хранении в оперативной памяти.
- "Disk based tables" - таблицы классической базы данных, хранящиеся на диске в виде страниц.
- "Natively Compiled Storage Procedure" - хранимые процедуры код которых компилируется в объектный код (бинарный) и не изменяется никогда от момента создания до удаления.
Организация хранения данных. Дисковая структура.
Принцип хранения данных претерпел существенные изменения. По сути это абсолютно другой способ хранения, основанный на построчном, а не на постраничном хранении данных. Каждая строка хранится внутри специального сегмента (heap) и связана с метаданными через специальные ссылки.
При рассмотрении принципа хранения данных мы рассмотрим логическую структуру хранения (Relation engine) и физическую организацию данных (Storage engine). Хотя эти аналогии взятые из предыдущей (дисковой) организации и не совсем точны мы все же будем ими пользоваться.
Физическая структура присутствует только в оперативной памяти в момент загрузки SQL Server или восстановления базы из резервной копии. Именно по этой причине есть смысл говорить о двух видах физической организации таких таблиц, а именно о физической организации на диске и физической организации в оперативной памяти.
С точки зрения физической организации на диске In-Memory база состоит из файлов трех видов:
- Data - файлы. Файлы в которых хранятся все строки, как те которые реально есть, так и те, которые были подвергнуты обновлению или удалению.
- Delta - файл. Файл хранящий информацию о удаленных строках в Data-файлах.
- Transaction Log - файлов, функция, которых во многом схожа с функцией журнала транзакций обычной (Disk based) базы данных.
В момент загрузки данных в Memory optimized таблицы с диска Delta-файл используется как битовая матрица, определяющая какие из строк, размещенных в Data-файлах являются актуальными, а какие были удалены и не должны быть загружены в память. Удаление строк происходит при их реальном удалении (DELETE), а также при выполнении операции модификации строк (UPDATE), поскольку операция UPDATE (в данном случае) выполняется как пара операций DELETE/INSERT. Об этом мы с вами поговорим позже.
Data -файл и соответствующий ему Delta-файл называются файловой парой, но глядя на папку, где они размещены невозможно определить кто есть кто. Единственным косвенным указателем является размер файла. Как правило Data-файл значительно больше его парного файла (Delta-файла). Эти файлы еще называют Checkpoint файлы (файлы контрольных точек). Поскольку каждый Data-файл покрывает определенный диапазон времени транзакций. Размер этого файла фиксирован при создании 128 МБ. Как только размер Data-файла превышает некое пороговое значение (около 512 МБ), создается новая пара файлов (Data и Delta).
Каждая пара файлов содержит строки в определенном временном диапазоне выполнения транзакций.
Как и в предыдущих версиях SQL Server файл журнала транзакций может содержать транзакции с данными, которые уже доступны для выполнения запроса, но еще не отображены в файлах данных. Перенос данных в классической OLTP выполнялся процессом CHECKPOINT. Здесь ситуация точно такая же, с одной лишь разницей, процесс CHECKPOINT здесь работает постоянно и не прекращается никогда. После отображения операций с данными из фалов журнала транзакций в Data- или Delta-файлах, журналы транзакций очищаются.
Со временем количество удаленных из Data-файлов строк превышает некоторый порог и запускается процесс слияния (MERGE CHECKPOINT), который комбинирует данные из Delta-файла (список удаленных строк) и Data-файла (где эти строки хранятся). Эти действия приводят к уменьшению размера Data-файла. Пороговые значения заданы в системы и изменены быть не могут, но существует возможность ручного слияния файлов при помощи хранимой процедуры sp_xtp_merge_checkpoint_files.
Ниже показана структура папки, где размещены Data- и Delta-файлы. Как видно на рисунке никаких признаков, для различения этих фалов нет. .
Имя файл представляет LSN транзакции создавшей этот файл.

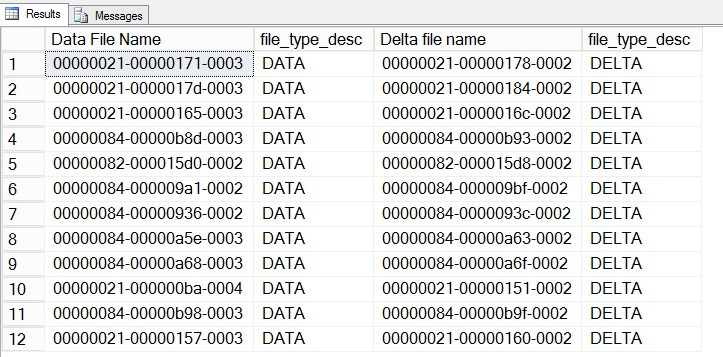
Определить какие файлы являются Data. а какие Delta можно при помощи системного просмотра sys.dm_db_xtp_checkpoint_files.

Приведенный выше запрос выведет все файлы, включая те их них, которые не активны. Для получения информации только об активных запрос необходимо переписать.
Организация хранения данных. Структура данных в памяти.
После старта SQL Server или восстановлении базы из резервной копии, или подсоединении (attach) базы происходит загрузка данных In-Memory-базы в оперативную память. Для загрузки используются Data- и Delta-файлы. Строки из Data-файлов загружаются в соответствии с битовой маской удаленных строк, размещенной в Delta-файлах. В результате в оперативной памяти формируются структуры представляющие In-Memory OLTP базу данных.
Загрузка строк в оперативную память ускоряется за счет создания большого количества файлов (Data и Delta), что позволяет производить параллельную загрузку, а также за счет последовательной структуры файлов, что обеспечивает выполнение на файлах только последовательных (sequential) операций чтения.
Структура, где хранятся строки базы, представляет собой неупорядоченных набор строк (heap). Строки связаны воедино при помощи специальных структур hash-индексов.
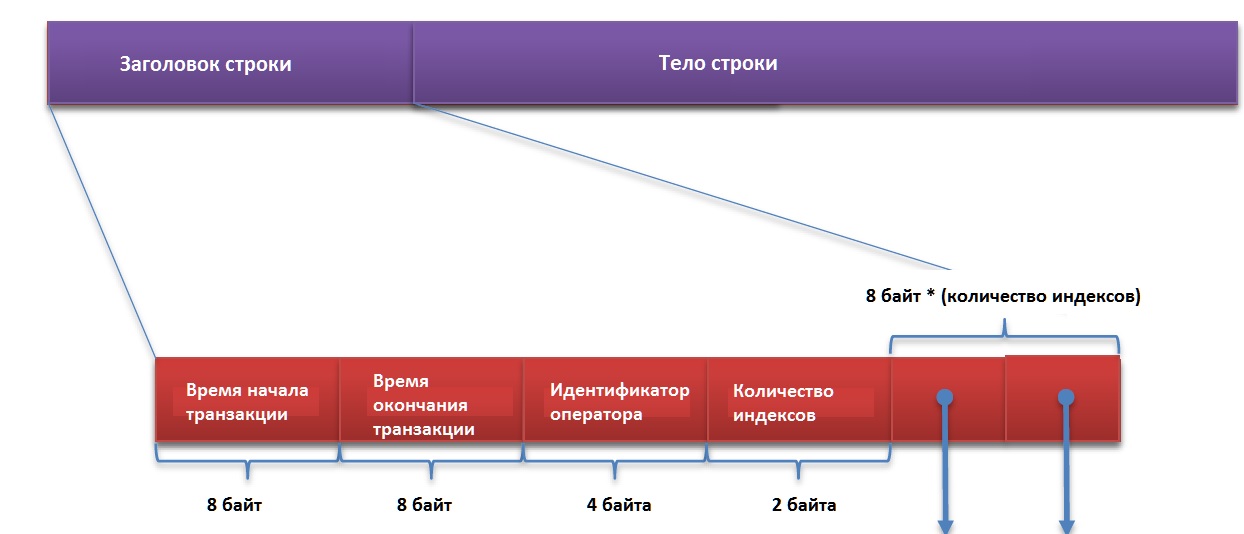
Поле "Время начала транзакции" содержит метку времени начала транзакции которая создала/модифицировала/удалила данную строку.
Поле "Время окончания транзакции" содержит метку времени окончания транзакции (если транзакция удалила строку), или признак бесконечности (если транзакция модифицировала строку). Если транзакция произвела удаление строки, то она не удаляется из Data-файла, а взамен информация о удаленной строке появляется в Delta-файле в виде структуры [inserting_tx_id, row_id, deleting_tx_id]. Эта информация храниться в Delta-файле до момента слияния (Merge) Data- и Delta-файла и выполнения операции очистки файлов при помощи процесса Garbage Collection, запускаемого автоматически или при помощи sp_xtp_checkpoint_force_garbage_collection.
Поле "Идентификатор оператора" содержит идентификатор оператора внутри транзакции (transaction) или блока (batch). Он необходим для определения того какой оператор в транзакции произвел модификации в данной строке.
Поле "Количество индексов" содержит информацию о количестве hash-индексов в строке.
Далее следуют поля представляющие собой сами hash-индексы.
Кроме, приведенных здесь полей существует еще несколько служебных полей необходимых для функционирования системы.
Видимость сформированной таким образом строки определяется метками времени в начале строки ("Время начала транзакции" и "Время окончания транзакции"). Если запрос попадает в эти "временные ворота", то он "видит" строку, если нет, то "не видит". На время модификации строки она защищается специальным флагом, не позволяющим доступ к ней. Этот флаг выполняет функцию подобную latch в классической OLTP, но поскольку здесь операция выполняется со строкой, а не со страницей и, кроме того, модификация выполняется методом удаления/вставки, то продолжительность такого latch значительно меньше, чем в классических системах.
Все строки, принадлежащие одной таблице, связаны hash-индексами (речь о которых пойдет в следующих статьях). Ссылка на первую строку в цепочке размещена в специальной таблице, являющейся неотъемлемой частью структуры hash-индексов.
Модификация строки приводит к тому, что появляется новая строка содержащая новые данные, при этом предыдущая не удаляется, а связывается с новой при помощи hash-индексов. Таким образом в таблице может храниться несколько версий строк. Старые строки будут периодически удаляться специальным процессом Garbage Collection.
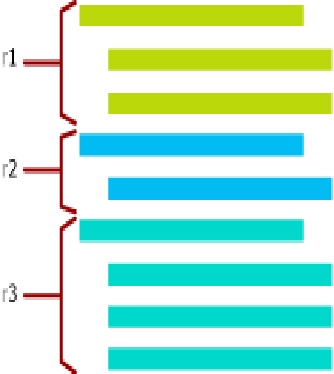
В приведенном ниже примере у нас есть три строки (r1...r3) и для каждой их них хранится несколько версий. Для строки r1 - три версии, для строки r2 - две, а для строки r3 - четыре версии.. Как было описано выше каждая версия актуальна внутри некоторого временного диапазона. По мере выхода версий за границы актуальности они вычищаются процессом Garbage Collection.
В следующей статье мы расскажем о hash-индексах.
Александр Каленик, Senior Premier Field Engineer (PFE), MSFT (Russia)