Machine Learning and Text Analytics
The following post is from Dr. Ashok Chandra , Distinguished Scientist at Microsoft Research and Dhyanesh Narayanan , Program Manager at Microsoft Research
When I (Ashok) was a student at the Stanford Artificial Intelligence Laboratory in the 70’s, there was great optimism that human-level machine intelligence was just around the corner. Well, it is still just around the corner. But meanwhile computers are becoming more capable all the time, using machine learning (ML) technologies. So much so, that almost all the new products created in Microsoft now use some level of ML, for analyzing speech, data or text. In this post we focus largely on text.
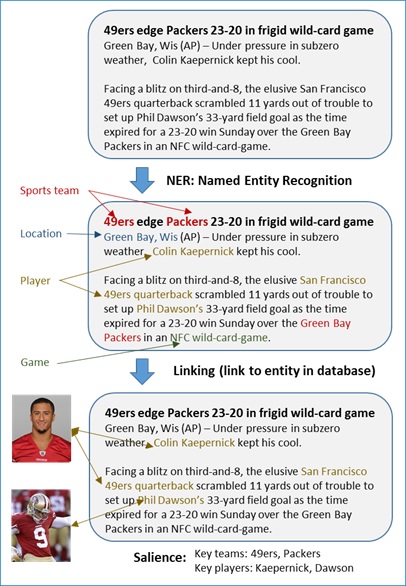
As computers better understand natural language, new frontiers open up everywhere – improved user-interfaces for applications; better search engines; personal assistants like Cortana and Siri; and tools for figuring out what a given document is really about. For instance, a news website might enable a more engaging experience for its uses, if the individuals mentioned in those articles were algorithmically linked to Wikipedia (or some appropriate database), so the reader could easily obtain more information about those people. Furthermore, by leveraging additional signals from the text, one could also determine the salient entities (e.g. players, teams) that the article was talking about, as seen in Figure 1.
{kind=link}
Figure 1 Motivating Scenario for Text Analytics
Text Analytics has been, and continues, as an area of active scientific research. After all, creating a semantic model of all human knowledge (represented as text) is no easy task. Early work, dating to the early 90’s, included Brill taggers [1] that determine parts-of-speech in sentences, and [2] gives just a hint of new work. Microsoft Research has been very active in creating ideas in this scientific field, but we go further in tailoring new science with pragmatic considerations to create production-level technologies.
In this blog post, we present a glimpse of how ML techniques can be leveraged for text analytics, using Named Entity Recognition (NER) as a reference point. As a platform that offers turnkey ML functionality, Microsoft Azure ML includes text analytics capabilities in general, and support for NER in particular – so we use that to make the connection from general concepts to specific design choices.
NER is the task of determining references in text to people, places, organizations, sports teams, etc. Let’s take a quick look at how we might solve this problem using a “supervised learning” approach.
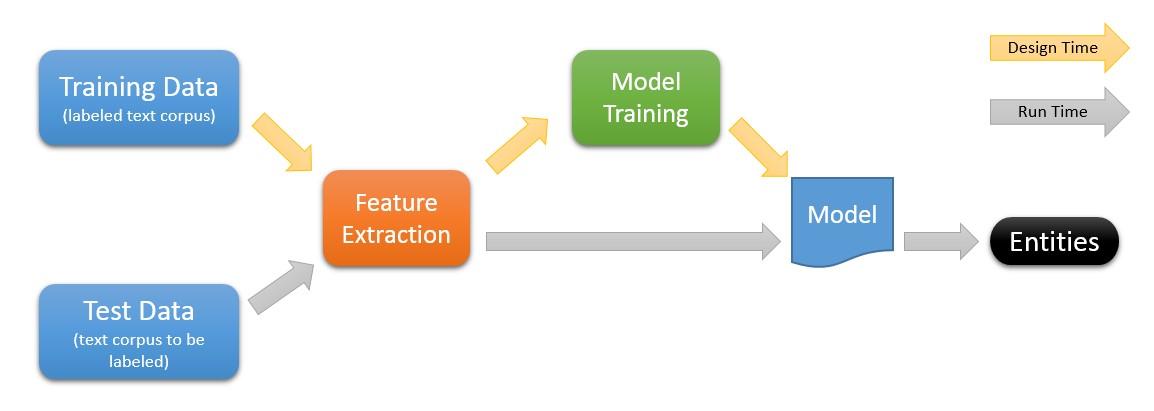
Figure 2 : Workflows for Named Entity Recognition
At Design Time or "learning time", the system uses training data to create a “model” of what is to be learned. The idea is for the system to generalize from a small set of examples to handle arbitrary new text.
The training data consists of human-annotated tags for the named entities to be learned. It might look something like this: “When <Player>Chris Bosh</Player> excels, <Team>Miami Heat</Team> becomes juggernaut” . The expectation is that, a model that learns from examples of this nature, will be trained to recognize Player entities and Team entities from new input text.
The effectiveness of the Design Time workflow hinges on the Feature Extraction phase – typically, the more diligently engineered features results in more powerful models. For instance, the local context associated with a word in a piece of text [say, the previous k words and next k words] is a strong feature that we as humans use to associate entities with words. For example, in the sentence “San Francisco beat the Cardinals in an intense match yesterday” , it is apparent from the context that the mention “San Francisco” refers to a sports team (i.e. the San Francisco Giants) rather than the city San Francisco. Capitalization is another useful feature that is often useful to recognize named entities such as People or Locations that occur in text.
Model Training is what ML is about, i.e. to produce a good model. It is typically a complex combination of the features selected. There are several ML techniques available, including Perceptron, Conditional Random Fields and more. The choice of technique depends on how accurate the model can become with limited training data, the speed of processing, and the number of different named entity types to be learned simultaneously. For instance, the Azure ML NER module supports three entity-types by default, namely People, Places, and Organizations.
The goal of the Run Time workflow is to take unlabeled input text and produce corresponding output text with entities recognized by the model that was created at Design Time. As one can observe, the Run Time workflow reuses the Feature Extraction module from the Design Time workflow – accordingly, if high throughput of entity recognition is necessary for an application, one has to provision relatively lightweight yet high-value features in the pipeline. As an illustrative example, the Azure ML NER module uses a small set of easy-to-compute features that are primarily based on local context, which also turn out to be very effective. Ambiguity during processing is often resolved using something like Viterbi decoding for assigning entity-labels to the sequence of input words.
It is important to realize that NER is just the beginning, but nevertheless an important first step towards capturing “knowledge” from raw text. This recent blog post describes how NER plus a set of related technologies were used to light up compelling experiences in the Bing Sports app - and the very same NER stack is available for you to use in Azure ML here. Beyond NER, general natural language parsing, linking and salience, sentiment analysis, fact extraction, etc. represent additional steps to enhance the user experience of applications built around content, these are additional techniques that can help you make your text "come alive".
We hope you enjoyed reading this post and look forward to your comments.
Ashok Chandra.
Follow my research here.
Dhyanesh Narayanan.
Follow my research here.
References
[1] Eric Brill, 1992, A simple rule-based part of speech tagger, Applied natural language processing (ANLC '92)
[2] Li Deng, Dong Yu, 2014, Deep Learning: Methods and Applications
Comments
- Anonymous
January 01, 2003
@Marco Shaw - thanks for pointing this out! The source has moved, we have fixed the URL. - Anonymous
January 01, 2003
Thanks for the informational post. (^_^) - Anonymous
January 01, 2003
thanks - Anonymous
July 25, 2014
There seems to be something wrong with the second reference. I think the correct public URL to the PDF ishttp://research.microsoft.com/pubs/209355/DeepLearning-NowPublishing-Vol7-SIG-039.pdf - Anonymous
October 14, 2014
The comment has been removed - Anonymous
March 09, 2015
Great Article. Does Azure ML has capabilities that could be used to parse a Resume to extract its metadata ?