patterns & practices Performance Engineering
As part of our patterns & practices App Arch Guide 2.0 project, we're consolidating our information on our patterns & practices Performance Engineering. Our performance engineering approach is simply a collection of performance-focused techniques that we found to be effective for meeting your performance objectives. One of the keys to the effectiveness is our performance frame. Our performance frame is a collection of "hot spots" that organize principles, patterns, and practices, as well as anti-patterns. We use the frame to perform effective performance design and code inspections. Here's a preview of our cheat sheet so far. You'll notice a lot of similarity with our patterns & practices Security Engineering. It's by design so that you can use a consistent approach for handling both security and performance.
Performance Overlay
This is our patterns & practices Performance Overlay:
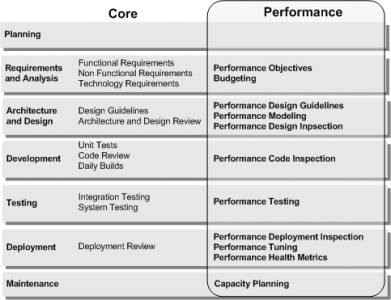
Key Activities in the Life Cycle
This Performance Engineering approach extends these proven core activities to create performance specific activities. These include:
- Performance Objectives. Setting objectives helps you scope and prioritize your work by setting boundaries and constraints. Setting performance objectives helps you identify where to start, how to proceed, and when your application meets your performance goals.
- Budgeting. Budget represents your constraints and enables you to specify how much you can spend (resource-wise) and how you plan to spend it.
- Performance Modeling. Performance modeling is an engineering technique that provides a structured and repeatable approach to meeting your performance objectives.
- Performance Design Guidelines. Applying design guidelines, patterns and principles which enable you to engineer for performance from an early stage.
- Performance Design Inspections. Performance design inspections are an effective way to identify problems in your application design. By using pattern-based categories and a question-driven approach, you simplify evaluating your design against root cause performance issues.
- Performance Code Inspections. Many performance defects are found during code reviews. Analyzing code for performance defects includes knowing what to look for and how to look for it. Performance code inspections to identify inefficient coding practices that could lead to performance bottlenecks.
- Performance Testing. Load and stress testing is used to generate metrics and to verify application behavior and performance under normal and peak load conditions.
- Performance Tuning. Performance tuning is an iterative process that you use to identify and eliminate bottlenecks until your application meets its performance objectives. You start by establishing a baseline. Then you collect data, analyze the results, and make configuration changes based on the analysis. After each set of changes, you retest and measure to verify that your application has moved closer to its performance objectives.
- Performance Health Metrics. Identity the measures, measurements, and criteria for evaluating the health of your application from a performance perspective.
- Performance Deployment Inspections. During the deployment phase, you validate your model by using production metrics. You can validate workload estimates, resource utilization levels, response time, and throughput.
- Capacity Planning. You should continue to measure and monitor when your application is deployed in the production environment. Changes that may affect system performance include increased user loads, deployment of new applications on shared infrastructure, system software revisions, and updates to your application to provide enhanced or new functionality. Use your performance metrics to guide your capacity and scaling plans.
Performance Frames
Performance Frames define a set of patterns-based categories that can organize repeatable problems and solutions. You can use these categories to divide your application architecture for further analysis and to help identify application performance issues. The categories within the frame represent the critical areas where mistakes are most often made.
| Category | Description |
|---|---|
| Caching | What and where to cache? Caching refers to how your applications caches data. The main points to be considered are Per user, application-wide, data volatility. |
| Communication | How to communicate between layers? Communication refers to choices for transport mechanism, boundaries, remote interface design, round trips, serialization, and bandwidth. |
| Concurrency | How to handle concurrent user interactions? Concurrency refers to choices for Transaction, locks, threading, and queuing. |
| Coupling / Cohesion | How to structure your application? Coupling and Cohesion refers structuring choices leading to loose coupling, high cohesion among components and layers. |
| Data Access | How to access data? Data Access refers to choices and approaches for schema design, Paging, Hierarchies, Indexes, Amount of data, and Round trips. |
| Data Structures / Algorithms | How to handle data? Data Structures and Algorithm refers to choice of algorithms; Arrays vs. collections. |
| Exception Management | How to handle exceptions? Exceptions management refers to choices / approach for catching, throwing, exceptions. |
| Resource Management | How to manage resources? Resource Management refers to approach for allocating, creating, destroying, and pooling of application resource |
| State Management | What and where to maintain state? State management refres to how your application maintains state. The main points to consider are Per user, application-wide, persistence, and location. |
Architecture and Design Issues
Use the diagram below to help you think about performance-related architecture and design issues in your application.
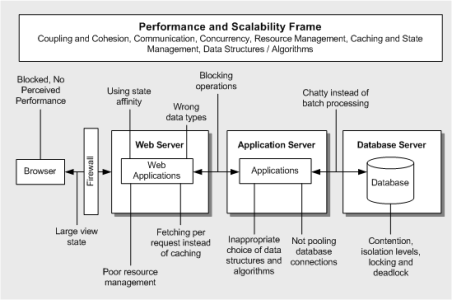
The key areas of concern for each application tier are:
- Browser. Blocked or unresponsive UI.
- Web Server. Using state affinity. Wrong data types. Fetching per request instead of caching. Poor resource management.
- Application Server. Blocking operations. Inappropriate choice of data structures and algorithms. Not pooling database connections.
- Database Server. Chatty instead of batch processing. Contention, isolation levels, locking and deadlock.
Design Process Principles
Consider the following principles to enhance your design process:
- Set objective goals. Avoid ambiguous or incomplete goals that cannot be measured such as "the application must run fast" or "the application must load quickly." You need to know the performance and scalability goals of your application so that you can (a) design to meet them, and (b) plan your tests around them. Make sure that your goals are measurable and verifiable. Requirements to consider for your performance objectives include response times, throughput, resource utilization, and workload. For example, how long should a particular request take? How many users does your application need to support? What is the peak load the application must handle? How many transactions per second must it support? You must also consider resource utilization thresholds. How much CPU, memory, network I/O, and disk I/O is it acceptable for your application to consume?
- Validate your architecture and design early. Identify, prototype, and validate your key design choices up front. Beginning with the end in mind, your goal is to evaluate whether your application architecture can support your performance goals. Some of the important decisions to validate up front include deployment topology, load balancing, network bandwidth, authentication and authorization strategies, exception management, instrumentation, database design, data access strategies, state management, and caching. Be prepared to cut features and functionality or rework areas that do not meet your performance goals. Know the cost of specific design choices and features.
- Cut the deadwood. Often the greatest gains come from finding whole sections of work that can be removed because they are unnecessary. This often occurs when (well-tuned) functions are composed to perform some greater operation. It is often the case that many interim results from the first function in your system do not end up getting used if they are destined for the second and subsequent functions. Elimination of these "waste" paths can yield tremendous end-to-end improvements.
- Tune end-to-end performance. Optimizing a single feature could take away resources from another feature and hinder overall performance. Likewise, a single bottleneck in a subsystem within your application can affect overall application performance regardless of how well the other subsystems are tuned. You obtain the most benefit from performance testing when you tune end-to-end, rather than spending considerable time and money on tuning one particular subsystem. Identify bottlenecks, and then tune specific parts of your application. Often performance work moves from one bottleneck to the next bottleneck.
- Measure throughout the life cycle. You need to know whether your application's performance is moving toward or away from your performance objectives. Performance tuning is an iterative process of continuous improvement with hopefully steady gains, punctuated by unplanned losses, until you meet your objectives. Measure your application's performance against your performance objectives throughout the development life cycle and make sure that performance is a core component of that life cycle. Unit test the performance of specific pieces of code and verify that the code meets the defined performance objectives before moving on to integrated performance testing. When your application is in production, continue to measure its performance. Factors such as the number of users, usage patterns, and data volumes change over time. New applications may start to compete for shared resources.
Design Guidelines
This table represents a set of secure design guidelines for application architects. Use this as a starting point for performance design and to improve performance design inspections.
| Category | Description |
|---|---|
| Caching | Decide where to cache data. Decide what data to cache. Decide the expiration policy and scavenging mechanism. Decide how to load the cache data. Avoid distributed coherent caches. |
| Communication | Choose the appropriate remote communication mechanism. Design chunky interfaces. Consider how to pass data between layers. Minimize the amount of data sent across the wire. Batch work to reduce calls over the network. Reduce transitions across boundaries. Consider asynchronous communication. Consider message queuing. Consider a "fire and forget" invocation model. |
| Concurrency | Design for loose coupling. Design for high cohesion. Partition application functionality into logical layers. Use early binding where possible. Evaluate resource affinity. |
| Coupling / Cohesion | How to structure your application? Coupling and Cohesion refers structuring choices leading to loose coupling, high cohesion among components and layers. |
| Data Structures / Algorithms | Choose an appropriate data structure. Pre-assign size for large dynamic growth data types. Use value and reference types appropriately. |
| Resource Management | Treat threads as a shared resource. Pool shared or scarce resources. Acquire late, release early. Consider efficient object creation and destruction. Consider resource throttling. |
| Resource Management | How to manage resources? Resource Management refers to approach for allocating, creating, destroying, and pooling of application resource |
| State Management | Evaluate stateful versus stateless design. Consider your state store options. Minimize session data. Free session resources as soon as possible. Avoid accessing session variables from business logic. |
Additional Resources
- Performance Design Guidelines (MSDN)
- Performance Modeling (MSDN)
- Performance Design Inspection (MSDN)
- Performance Testing Guidance for Web Applications (MSDN)
My Related Posts
- patterns & practices App Arch Guide 2.0 Project
- patterns & practices Security Engineering
- App Arch Meta-Frame
- Layers and Tiers
- Layers and Components
- Services Layer
- Scenario Frames for Presentation, Business, Data and Services
- The Architecture Journal
Comments
Anonymous
September 15, 2008
PingBack from http://hoursfunnywallpaper.cn/?p=6279Anonymous
September 16, 2008
Some additional resources: XPE (eXtensible Software Performance Engineering) http://www.jinspired.com/solutions/xpe/index.html Combing Performance Management and Cost Management via Activity Based Costing (ABC) http://www.jinspired.com/products/jxinsight/meteringthecloud.htmlAnonymous
September 17, 2008
Hi, JD, the Design Guidelines has two Resource Management in the grid, i think you may miss the Exception Management part instead of duplicate Resource Management :) Thanks ChengAnonymous
October 11, 2008
As part of our patterns & practices App Arch Guide 2.0 project , we've put together an arch frame.