Cambiamento epocale nella gestione delle statistiche
Salve a tutti,
L’argomento di oggi ha, per chi lavora con SQL Server da molti anni, un significato particolare perché va ad impattare uno degli aspetti più granitici ed immutabili nel tempo, sai che è così da (n) versioni e (m) anni, con tutti i problemi del caso, ed un bel giorno Ti svegli ed alcune di queste certezze non ci sono più ! :)
L’oggetto della mia meraviglia, e del presente post, è un nuovo meccanismo per la gestione “dinamica” delle statistiche, introdotto con la SP1 di SQL Server 2008 R2 e che sarà anche nella prossima versione di SQL Server (nome in codice “Denali”): quello che ora cambia, se abilitate il trace flag –T2371, è la magica soglia (di modifiche ad una colonna/e di una tabella) oltre la quale una certa statistica viene aggiornata automaticamente da SQL Server.
Fino a ieri, la regoletta che potete trovare in varie documentazioni su Internet era la seguente, per l’aggiornamento dinamico di una statistica (“recompilation threshold”):
- Tabelle con numero di righe < 500: la soglia di aggiornamento delle statistiche è (500) modifiche;
- Tabelle con numeri di righe >= 500: la soglia di aggiornamento delle statistiche è [(500) + (20% del numero di righe di una tabella)] modifiche;
- Tabelle temporanee: come sopra, con una ulteriore soglia che scatta al raggiungimento delle 6 righe inserite nella tabella;
Con varie sfaccettature, questa soglia statica (cioè il numero “20%”) non è mai cambiata dalla sua introduzione in SQL 7.0, parliamo quindi di circa 13 anni fa !
Il problema di questa percentuale fissa è che, su tabelle molto grandi come numerosità di righe, tale soglia è troppo alta e si rischia che SQL Server non scateni mai l’aggiornamento automatico delle statistiche, con conseguenti problemi di accuratezza dei “query plan” generati.
Per farVi un esempio concreto, immaginate la seguente situazione:
- Tabella con 100 milioni di record (credetemi, non sono tante ! :))
- Ogni giorno vengono inseriti 1 milione di nuovi record;
- Il 95% delle attività sulla tabella, intese come INSERT,UPDATE, DELETE ma anche SELECT, sono sui dati dell’ultima settimana, quindi gli “ultimi” 7 milioni di record;
- Il database che contiene tale tabella ha, come da default, l’opzione “AutoUpdate Statistics” abilitata;
- Le statistiche non legati agli indici, presenti sulla tabella, hanno un “sample” di default del 10%, cioè considerano un campione casuale/uniforme dei dati dell’intera tabella;
Riuscite a vedere il problema? Con la soglia fissa al 20%, le statistiche di questa tabella saranno aggiornate non prima di 20gg (1M di record x 20gg = 20M record =circa il 20% delle righe della tabella) !!!
Con tabelle di queste dimensioni, spesso partizionate, la soglia classica di aggiornamento delle statistiche non basta mai, per cui è altrettanto spesso necessario inserire un “job” del “SQL Agent” che periodicamente (non certo ogni 20gg !) forzi l’aggiornamento delle statistiche.
Con questo nuovo meccanismo, la soglia di auto-aggiornamento delle statistiche non è più fissa al 20% ma varia, nella sua percentuale, dinamicamente in base al numero di record di una tabella: purtroppo al momento l’informazione esatta su come varia questa percentuale non è di carattere pubblico :), ma facendo qualche test numerico è facilmente intuibile ;), il concetto importante da considerare è che più record ha una tabella e più si abbassa la percentuale oltre la quale scatta l’aggiornamento delle statistiche, ecco alcuni esempi:
- Tabella con 10 milioni di record, la soglia è circa dell’1% ;
- L’autoupdate scatterà dopo 100mila modifiche, anziché 2 milioni di modifiche, quindi 20 volte più frequente;
- Tabella con 50 milioni di record, la soglia è circa dello 0.5% ;
- L’autoupdate scatterà dopo 250mila modifiche, anziché 10 milioni di modifiche, quindi 40 volte più frequente;
- Tabella con 100 milioni di record, la soglia è circa lo 0.3% ;
- L’autoupdate scatterà dopo 300mila modifiche, anziché 20 milioni di modifiche, quindi 67 volte più frequente;
Per chi non avesse ancora indovinato la funzione matematica che governa la soglia dinamica, rendo ancora più facile la cosa con il seguente grafico tratto da un post del collega Juergen Thomas (grazie !), il nostro maggiore esperto di SAP:
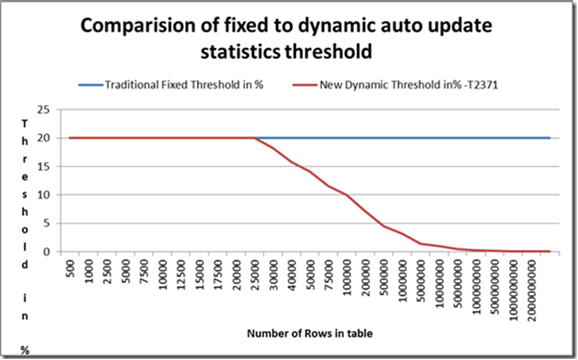
NOTA: Non Vi aspettate che questo meccanismo entri in azione su tabelle piccole, come potete vedere dal grafico la soglia è identica fino a (circa) 25000 righe, poi il comportamento cambia.
OK, sembra tutto fantastico, ma qualcuno dovrebbe chiedersi: pechè devo abilitare un “trace flag” per avere questo meccanismo ed invece non è un comportamento di default di SQL Server?
La cosa ha molto senso ed è una consuetudine del gruppo di sviluppo di SQL Server: ogni modifica al codice e/o nuova funzionalità che cambi il comportamento dell’engine di SQL deve essere attivata esplicitamente (e consciamente), ed i “trace flags” adempiono proprio a questo scopo, oltre ovviamente a molti altri. Vorrei poi puntualizzare che non è detto che questo meccanismo porti beneficio a tutti i clienti: è vero che le statistiche saranno aggiornate più frequentemente, ma ciò vuol dire anche un maggiore numero di “ricompilazioni” delle stored procedure e delle query adhoc, quindi (tra le altre cose) un maggiore utilizzo della CPU.
Come si abilita in maniera “permanente” questo meccanismo ? Và inserito il trace flag –T2371 negli “startup parameters” dell’istanza SQL utilizzando il tool “SQL Configuration Manager”, tab “Advanced” nelle proprietà del servizio SQL Server, riga “startup parameters”: attenzione, dovete inserire –T2371 in coda a quello che già c’è, pre-pendendo un punto e virgola ( ; ). Dopo l’inserimento del trace flag di SQL tramite SQL Configuration Manager, e relativo reboot, verificate che nella parte iniziale dell’ERRRORLOG compaia una cosa del genere:
Registry startup parameters:
-d C:\SQL2008R2\MSSQL10_50.SQL2008R2\MSSQL\DATA\master.mdf
-e C:\SQL2008R2\MSSQL10_50.SQL2008R2\MSSQL\Log\ERRORLOG
-l C:\SQL2008R2\MSSQL10_50.SQL2008R2\MSSQL\DATA\mastlog.ldf
-T 2371
IMPORTANTE: Sebbene dobbiate inserire -T2371 senza spazio tra –T e 2371 negli “startup parameters”, nell’ERRORLOG lo spazio invece compare, non Vi preoccupate è normale e deve essere così altrimenti avete commesso un errore nella configurazione;
Anche per oggi è tutto, mi raccomando: testate, testate ed ancora testate…..
--Igor Pagliai—