The code coverage metric is inversely proportional to the critical information it provides.
One of the best aspects of my current role is the opportunity to interact with so many talented, highly skilled, and extremely intelligent testers at Microsoft and other companies around the world. Last week I was teaching a new group of SDETs at Microsoft, and during our discussion of code coverage (the metric) and code coverage analysis (the process of analyzing areas of untested or unexercised code) Alex Kronrod (an intern from UC Berkeley who attended the class) stated "so basically what you're saying is the code coverage measure is inversely proportional to the amount of information it provides." Now, I don't know whether or not there is exact proportionality in the code coverage metric and the information provided by the measure itself, but I thought about it a moment and thought to myself, "Wow, what a great perspective!"
Code coverage is a frequently sought after measure in software testing. Code coverage is an important metric and it should not be ignored; however, as a measure it must not be abused or over-rated, nor should we attempt to correlate code coverage as a direct measure of quality. While many teams strive for higher percentages of code coverage at the system level (which is good), the code coverage metric simply tells us if statements, block of statements, or conditional expressions have been exercised. Low measures of code coverage may sometimes result from software complexity and lack of testability or from testing ineffectiveness, but are generally indicative of a software project in peril (with regards to risk). Higher percentages of code coverage certainly help reduce perceived overall risk, but the code coverage measure by itself doesn't necessarily tell us HOW it was exercised, and it doesn't provide useful information about the areas of the code that have not been exercised other than what percentage of the code is at 100% at risk. (If we don't test it; we can't qualitatively say anything about it, so risk must be assumed to be 100%.)
Let's examine the following simple example to explain this search algorithm to better understand how increased measures of code coverage provide less valuable information regarding testing effectiveness. This algorithm searches for a particular character in a string of characters and returns the index position of the character if found; otherwise it returns 0.
private static int CharSrch(string s, char c)
{
int i = 0;
int retVal = 0;
char[] cArray = s.ToCharArray();
while ((i < cArray.Length) && (cArray[i] != c))
{
i++;
}
if (i < (cArray.Length))
{
retVal = i;
}
return retVal;
}
Using Visual Studio Team System to measure block coverage and executing a test in which s = "" and c = 'c' the code coverage measure is only 72.73% for the CharSrch method as illustrated in the figure below. In this example it is easy to understand why the relatively low code coverage measure is giving us valuable information (perceived risk is great, overall confidence is low). Clearly we have more testing to do!
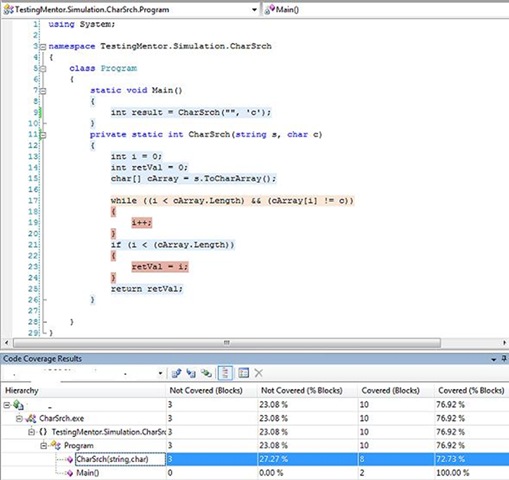
Again using Visual Studio Team System to measure block coverage and executing a test in which the search string is "abc" and the character to search for is 'c' the code coverage measure jumps up to 90.91% for the CharSrch method as illustrated in the figure below. Using just the code coverage measure as an indication of test effectiveness we might feel much more confident and perceive our exposure to risk is greatly reduced, and the algorithm is doing the right thing! But, we are still not at 100% (which is easy for this example), so we need just one more test to achieve that magic number.

A third test in which the search string is "a" and the character to search for is 'c' we see the resultant code coverage is again 90.91% as illustrated in the figure below. By merging the code coverage results in Visual Studio Team System we can achieve 100% block coverage by merging the results of Test 1 ( s = "a" and c = 'c'') and Test 2 (s = "abc" and c = 'c') . If unit tests were written in such a way as to check for an output of retVal == 0 for Test 1, and an output of retVal != 0 for Test 2, then both tests pass. Overall, my perceived risk is relatively low, and my confidence is relatively high as compared to the first test based on the code coverage measure. But, did we miss something?
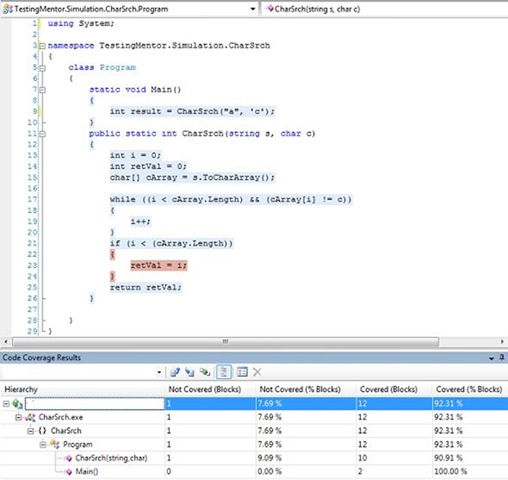
Although the percentage of block coverage is relatively high (OK...100% is the max), the information provided by the measure itself is actually less valuable because it may have actually failed to detect the defect in which the CharSrch method returns a value of 0 if the character is not found, and also returns a value of 0 if the search character is the first character in the string.
This simple example is not meant to discount the overall value of code coverage as a software metric. However, as professional testers we must realize that high levels of code coverage do not directly relate to quality, and code coverage is only an indirect indication of test effectiveness. From my perspective, the most important measure with regards to code coverage is not how much has been exercised, but the percentage of code that has been unexercised by our testing. That is the purpose of code coverage analysis (which is a great segue for a follow up blog post).
Comments
- Anonymous
December 20, 2007
PingBack from http://arunxjacob.wordpress.com/2007/12/21/code-coverage-and-false-quality-assurance/