Boundary testing isn’t guessing at numbers!
At a recent conference a speaker posed a problem in which a field accepted a string of characters with a maximum of 32,768 bytes, then asked the audience what values they would use for boundary testing. Immediately some of the attendees unleashed a flurry of silly wild ass guesses (SWAG) such as “32,000,” “64,000,” and, of course, what attempt at guessing would be complete without someone yelling out “how about a really large string!” One person asked whether it was bytes or characters? A reasonable question, but the speaker than began talking about double byte characters (DBCS). (Double byte is, in technological time, a relatively antiquated character encoding technology since most modern operating systems process data as Unicode.)
So, while some folks in the audience continued to shout out various SWAGs, I was still pondering why anyone in their right mind would artificially constrain a user input to such a seemingly ridiculous magic number within the context of computer processing and programming languages. Programming languages allow specific ranges of numeric input. Most strongly typed languages such as the C family of languages have explicit built in or intrinsic data types that include signed and unsigned ranges. For example, an unsigned short is 2^16 or 0 through 65,535, and a signed short is also 2^16 but the range is -32,768 through +32,787. Since the speaker didn’t indicate what programming language was used in this magical field, the only logical conclusion a professional tester can rationally deduce is that 32,768 is a magic number, or in other words a “hard-coded” constant value embedded somewhere in the code.
Asking questions is important! But, asking a bunch of contextually-free questions or throwing out random guesses is usually not the most efficient or productive use of one’s time. Asking specific rational questions or making logical assertions based on knowledge and understanding is important, and is generally more productive; especially when testing the boundary conditions of input or output values in software. Boundary testing is a technique that focuses on linear input or output values that are fixed, or fixed-in-time and used for various computations or Boolean decisions (branching) within the software. Similar to most testing techniques boundary testing focuses on exposing one category of issues based on a very specific fault model, and is an extremely efficient systematic approach to effectively expose that particular category of issues. In particular boundary testing is useful in identifying problems with:
- improperly used relational operators
- incorrectly assigned constant values
- and computational errors that might cause an intrinsic data type to either overflow or wrap especially when casting or converting between data types (proper identification of the data type and knowledge of the minimum and maximum ranges is critical)
I previously wrote about approaches to help the tester identify potential boundary conditions, and how to design tests to adequately analyze those specific boundary values. As I previously stated, boundary testing involves the systematic analysis of a specific value. For example, a long file name on the Windows platform (both the base file name and the extension) should not exceed 255 characters. For file types that use a default 3-character extension the most interesting boundary values are 1 character (minimum base file name length) 251 characters (maximum base file name length assuming a standard 3-character extension), and 255 characters (with or without an extension to test what occurs with a base file name equal in length to the maximum base file name with a standard 3-character extension. (Of course, if the default extension is 1-character, or 2-characters, or 4-characters, etc., than the maximum base file name without extension needs to be recalculated.) Now, let’s see why specific values are important and critical to accurately analyze boundaries.
On Windows Xp I used Notepad to test file name boundaries with a default 3-character extension. Of course the minimum -1 value is an empty string, and minimum and minimum +1 is saving a file with a 1-character and 2-character file name respectively. Next I entered a base file name of 250-characters (maximum -1) and 251-characters (maximum allowed assuming a default 3-character extension) and these file names were saved to the system with the default extension. Then I entered a 252-character file name and I got the expected error message indicating the file name is too long. But, what about my boundary of 255 characters maximum. (IMPORTANT - boundary values are not just at the edges of the extreme ranges of values, but there could be sub or supra boundary values within a range of values that may occur at the edges of equivalent class ranges, or specific values in special or unique equivalence class subsets.) So, I wondered what would happen if I entered just a base file name of 255 characters (which is the maximum length of a file name assuming an extension is also part of that file name)? Interestingly enough, on Windows Xp the operating system saved a file with 255-characters, but it did not have any extension which means that there was no application associated with the file. The same occurred with a 254-character base file name, and when I tried the maximum +1 of the overall complete file name range I was again presented with the same message I got with a 252 character base file name indicating the file name was too long.
Fortunately, the above issue was fixed in Windows Vista. But, as sometimes occurs in complex systems one fix occasionally leads to a different (but related)issue in the same functional area which is why regression testing is typically an effective testing strategy. So, when I ran my ‘regression tests’ on Windows Vista I quickly discovered the system would not save a file with only a base file name of any number of characters greater than 252-characters via Notepad. But, as I ran the specific boundary tests I realized something very important! When I entered a base file name of 252-characters I received the following error message.

And when I attempted the test with a base file name composed of any number of characters greater than 252 I received the following error message.
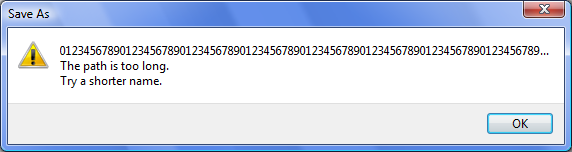
Now, those of you who are paying attention realize these 2 messages are different. Of course, in either case a file is not saved to the system which is what I expect; however, there is a strange anomaly here. Although one might notice the first message prepends the drive letter to the string of 252 characters, and the second message does not. But, the important question doesn't really have anything to do with the message text per se, in this case the professional tester tester should ask, “why is there an apparent conditional branch in the code that shunts control flow one way for a base file name of 252 characters and a different path for a base file name greater than 252 characters?”
Of course, if we just guessed, or tested ‘a really large string of characters, we might have never exposed this anomaly which occurs only at the maximum + 1 length of a base file name (assuming a default 3 character extension). Interestingly enough, if a highly skilled, technically savvy tester had designed white box tests for decision testing or path analysis then I suspect he or she could have very easily found this anomaly with even greater efficiency and exposed it earlier in the cycle.
The point here is that boundary testing is simply not random guessing, wild speculation, or simple parlor tricks. The technique of boundary value analysis requires in-depth knowledge of what the system is doing behind the user interface, and careful analysis of system and data to accurately determine the specific boundary conditions and a rigorous analysis of linear values immediately above and below each identified specific boundary value. Testers must be able to properly identify the specific and interesting boundary values based on in-depth knowledge of the system, an understanding of what is happening beneath the user interface, and experience. Then we can perform a more systematic analysis of any identified boundary conditions and potentially increase our probability of identifying real anomalies caused by this specific fault model. Boundary value analysis is a prime example of where good enough is simply not good enough in our discipline...we must be technically spot on!