O caso do Cluster que travou e o Failover não acontecia!
Failover Cluster é um grupo de servidores conectados com objetivo de proporcionar alta disponibilidade e escalabilidade para as Aplicações e Serviços. Se qualquer componente de hardware ou software falha, outro nó do Cluster começa a prover aquele Serviço (processo conhecido como Failover) com vistas a garantir a disponibilidade para os usuários e clientes.
Idealmente os clientes haveriam de perceber apenas minimamente quaisquer ocasiões de falhas, no entanto em raras oportunidades pode ocorrer um evento que impede que o Failover aconteça plenamente - Esse post descreve exatamente uma situação real em que um serviço parou de responder e o Failover não aconteceu conforme o esperado.
O ambiente é composto por um Cluster Geográfico, com 4 nós Windows Server 2008 R2 SP1 com a role de File Server e File Server Resource Manager, cada um em um site diferente e virtualizados sob VMware.
Sintomas
Os usuários e clientes perceberam uma degradação da performance e no acesso aos arquivos de uma maneira geral e desde várias horas, ao ponto que os administradores sequer conseguiam conectar na console do nó que era dono dos recursos, nem tampouco os usuários eram capazes de acessar aos seus arquivos. Eventualmente tentou-se mover os recursos de File Server para o outro nó, porém os discos permaneceram com o status ONLINE PENDING por várias horas.
Com o objetivo de restabelecer os Serviços daquela máquina e posteriormente diagnosticar o causador do problema o cliente decidiu capturar um Kernel Memory Dump de forma manual. O nosso escopo a partir daqui é determinar a causa raiz desse problema a partir da análise dos dados capturados, sobretudo os logs do Cluster, Perfmon (que já estava previamente configurado nesse sistema) e o dump.
Análise da Causa Raiz
Na perspectiva do Cluster o problema começou por volta das 19:45hs, quando o health check de alguns recursos começaram a falhar (timed out) de forma inesperada. A consequência disso é que o RHS é terminado:
818:700.07/26[20:38:02.204](000000) WARN [RES] File Server <FileServer-(<<editado>>)(Disk D:)>: Failed in NetShareGetInfo(<<editado>>, BA2), status 53. Tolerating...
818:bac.07/26[20:45:02.346](000000) ERR [RHS] RhsCall::DeadlockMonitor: Call ISALIVE timed out for resource 'FileServer-(<<editado>>)(Disk D:)'.
818:bac.07/26[20:45:02.361](000000) INFO [RHS] Enabling RHS termination watchdog with timeout 1200000 and recovery action 3.
818:bac.07/26[20:45:02.361](000000) ERR [RHS] Resource FileServer-(<<editado>>)(Disk D:) handling deadlock. Cleaning current operation and terminating RHS process.
818:bac.07/26[20:45:02.361](000000) ERR [RHS] About to send WER report.
814:1c0.07/26[20:45:02.361](000000) WARN [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'FileServer-(<<editado>>)(Disk D:)', gen(0) result 4.
814:1c0.07/26[20:45:02.361](000000) INFO [RCM] rcm::RcmResource::HandleMonitorReply: Resource 'FileServer-(<<editado>>)(Disk D:)' consecutive failure count 1.
Quando o <FileServer-(<<editado>>)(Disk D:)> tentou vir online novamente, percebe-se que o Resource Control Manager acusa somente o status 'WaitingToComeOnline' por um período longo, apesar das diversas tentativas de movimentação entre os nós feita pelos administradores enquanto o problema acontecia:
814:1c0.07/26[19:46:16.058](000000) DBG [RCM] FileServer-(<<editado>>)(Disk D:): WaitingToComeOnline,
814:1c0.07/26[19:46:19.179](000000) DBG [RCM] FileServer-(<<editado>>)(Disk D:): WaitingToComeOnline,
814:1c0.07/26[19:46:22.299](000000) DBG [RCM] FileServer-(<<editado>>)(Disk D:): WaitingToComeOnline,
.
.
.
814:1c0.07/26[20:30:53.221](000000) DBG [RCM] FileServer-(<<editado>>)(Disk D:): WaitingToComeOnline,
814:1c0.07/26[20:30:56.341](000000) DBG [RCM] FileServer-(<<editado>>)(Disk D:): WaitingToComeOnline,
814:1c0.07/26[20:30:59.461](000000) DBG [RCM] FileServer-(<<editado>>)(Disk D:): WaitingToComeOnline,
.
.
.
814:1c0.07/26[22:57:51.989](000000) DBG [RCM] FileServer-(<<editado>>)(Disk D:): WaitingToComeOnline,
814:1c0.07/26[22:57:55.109](000000) DBG [RCM] FileServer-(<<editado>>)(Disk D:): WaitingToComeOnline,
814:1c0.07/26[22:57:58.229](000000) DBG [RCM] FileServer-(<<editado>>)(Disk D:): WaitingToComeOnline,
Esses comportamentos se repetiram algumas vezes até o momento que a máquina foi reiniciada.
Do ponto de vista de performance observe que o nó estava desde às 15:30hs com uma pressão considerável sobre CPU:
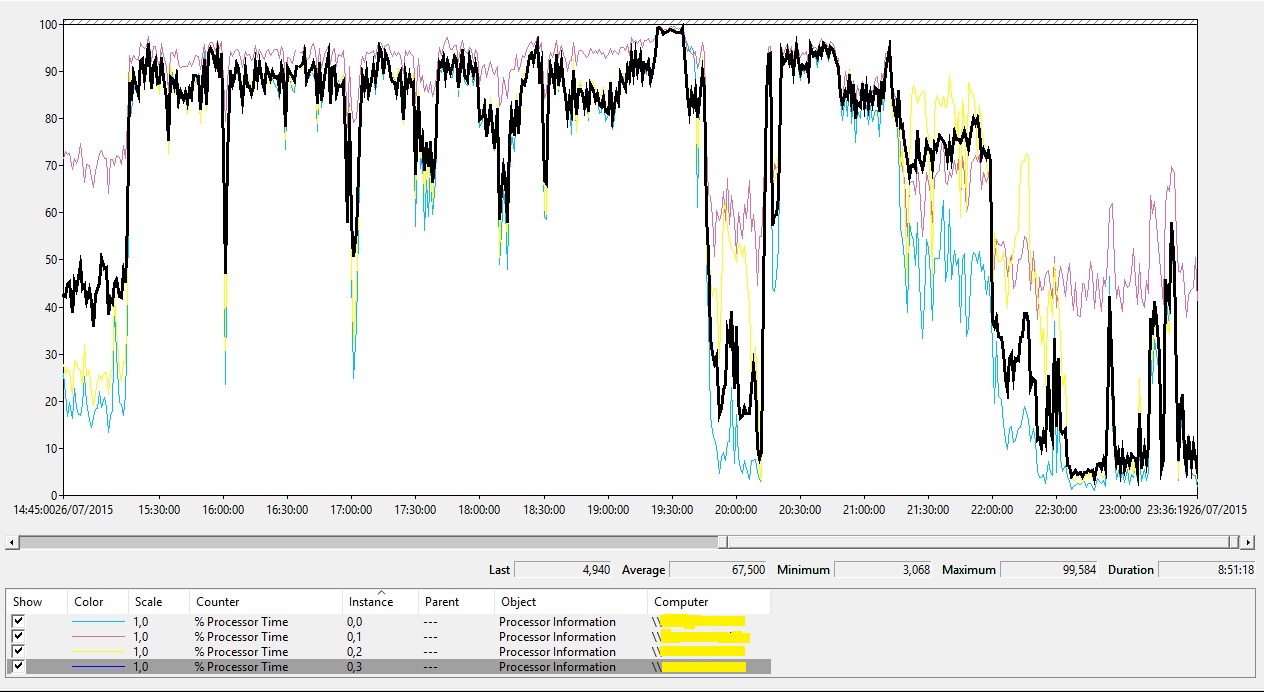
E a maior parte dessa utilização estava relacionado a componentes executando em modo privilegiado (Kernel Mode, sobretudo drivers):
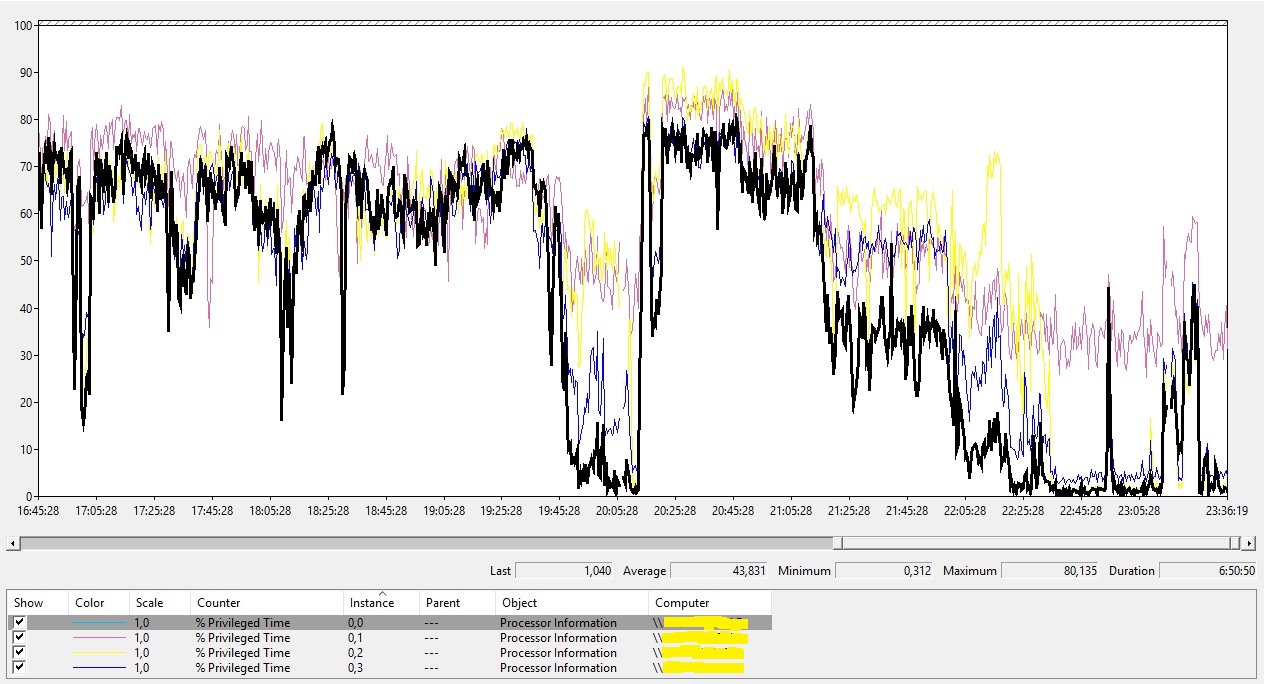
Os principais ofensores em termos de CPU parecem ser uma instância do SVCHOST e o SYSTEM (este, bem menos quando comparado à primeira).
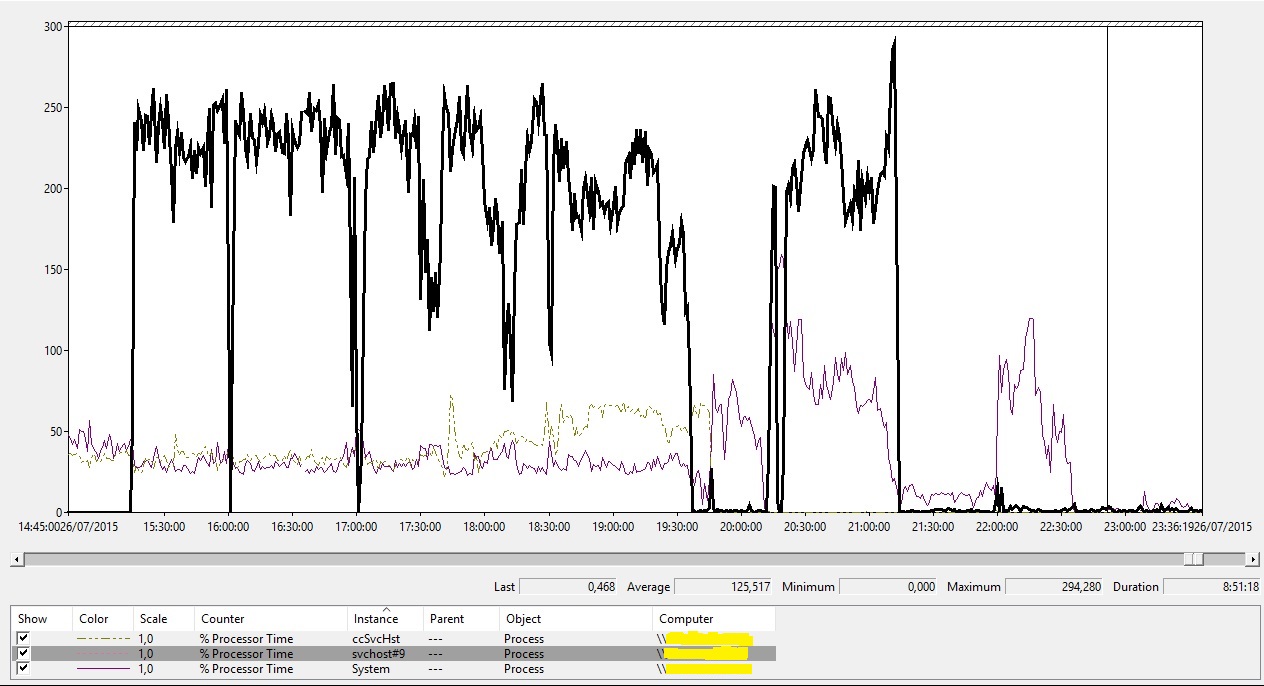
A análise do dump (que será assunto para um futuro post =) indicou que essa instância do SVCHOST (svchost#9) estava possivelmente hospedando o serviço File Server Resource Manager. Além disso o dump também evidenciava algumas stacks como a abaixo:
...
nt!KiSwapContext+0x8a
nt!ExAcquireResourceExclusiveLite+0x14f
quota!QuotaPrePnp+0x184
fltmgr!FltpPerformPreCallbacks+0x2f8
fltmgr!FltpPassThrough+0x2d9
fltmgr!FltpDispatch+0xb8
nt!IopSynchronousCall+0xb5
nt!IopRemoveDevice+0x101
nt!PnpSurpriseRemoveLockedDeviceNode+0x128
nt!PnpDeleteLockedDeviceNode+0x38
nt!PnpDeleteLockedDeviceNodes+0xa0
nt!PnpProcessQueryRemoveAndEject+0x6bf
nt!PnpProcessTargetDeviceEvent+0x4c
nt!PnpDeviceEventWorker+0xf99b6
...
Trata-se de um problema conhecido e já endereçado pelo hotfix https://support.microsoft.com/en-us/kb/2848443: O driver de quota e File Server Resource Manager (quota.sys) em uma situação muito específica entrava em deadlock (note que esse deadlock não tem nada a ver com o do RHS) e causava os sintomas que variam de alto consumo de CPU até os discos com o status "Online pending".
Depois que o hotfix foi instalado o problema foi resolvido em definitivo.
Ainda que seja relativamente raro lidar exatamente com essa mesma causa raiz em seu ambiente de produção, observe que de posse dos dados certos, capturados no momento apropriado e com seus servidores devidamente instrumentados, as chances de um diagnóstico preciso aumentam de forma considerável. Pretendo publicar novos posts em breve sobre algumas práticas simples que podem ajudar bastante em análises como essa.
Um abraço.
Diego