浅析微软大数据平台HDInsight (1)
大数据!这对我们来讲早已不是一个陌生的词汇。
什么是大数据 ?
大数据,故名思议,首先它是一套数据集的集合。然后这个集合非常大,非常复杂,以至于使用一般的数据库管理工具或者传统的数据处理程序会很难对它进行处理。
那哪些数据是属于大数据的范畴?根据大数据的定义,我们可以举出一些大数据的例子:
比如,传统的大数据有物理实验数据,各种感应器的数据,卫星数据等等。
随着人类社会的发展,计算机技术的发展,现在的大数据还包括一些计算机本身操作的日志,网店客户的一些行为表现,在线社交程序,微博,微信,twitter,
facebook之类的在线交互的内容, 等等。
我们可以发现,从上世纪九十年代的数据规模到现在,这个数据量是呈爆炸式的发展。从当初的Terabytes, 也就是兆兆字节,发展到现在的PetaBytes,
相信到不久的将来会有Zetabytes的数据量出现。
Apache Hadoop
那了解了大数据的特征,我们可以把处理大数据的平台作为一种机会来看待。事实上从商业应用的价值,大数据是一个金矿,就看你如何去挖掘。而要想从大数据中进行数据挖掘获取真正有价值的东西,那么首先,你需要这样一个大数据处理的平台。这样的平台能够帮助你存储大数据,同时提供机制使得你能够去挖掘大数据的价值。这样一个平台正是你挖掘大数据的商业价值的基础。
而一个好的大数据处理平台,我们可以想到这样一些特性:
- 我们希望用多台机器,而且是多台普通的机器架设这样的平台。我们可以不需要非常高端的硬件。
- 而它能够有很好的扩充性。你能够随时在群集中增减机器的数量,我们称为Scale
Out - 它使用的是完全开源的软件,降低成本。
那Apache Hadoop就是这样一个系统。
那么Hadoop究竟包含些什么组件呢。Hadoop并不仅仅是一个存储数据的架构,它同时提供了一个机制能够用来编写分布式可扩展的访问数据的应用。Hadoop包含下面两个重要的组成部分:
Hadoop Distributed File System
HDFS, Hadoop分布式文件系统。它是一个分布式的,可扩展的,可移植的针对Hadoop架构下的文件系统。它是由Java编写的。
MapReduce
Map Reduce, 是一种专门用于在群集中处理分布式数据的编程模型。Hadoop提供了这样一个实现。
Hadoop可以把大数据分布到成百上千的普通计算机上。传统的软件程序通常是把数据拿到本地来进行处理,而MapReduce却是把执行代码推送到数据所在的节点上运行。那我们可以看到这样可以有效的避免网络带宽的限制,而且处理的速度基本上同数据集大小本身保持线性关系,而性能取决于有多少个存储数据的节点。数据节点多,那么处理同样的数据量就快。
Relational Database vs. Hadoop
那Hadoop究竟跟传统的关系型数据库有些什么样的联系和不同呢?为了理解他们的关系和区别,我们有必要理解schema在Hadoop中是如何工作的:
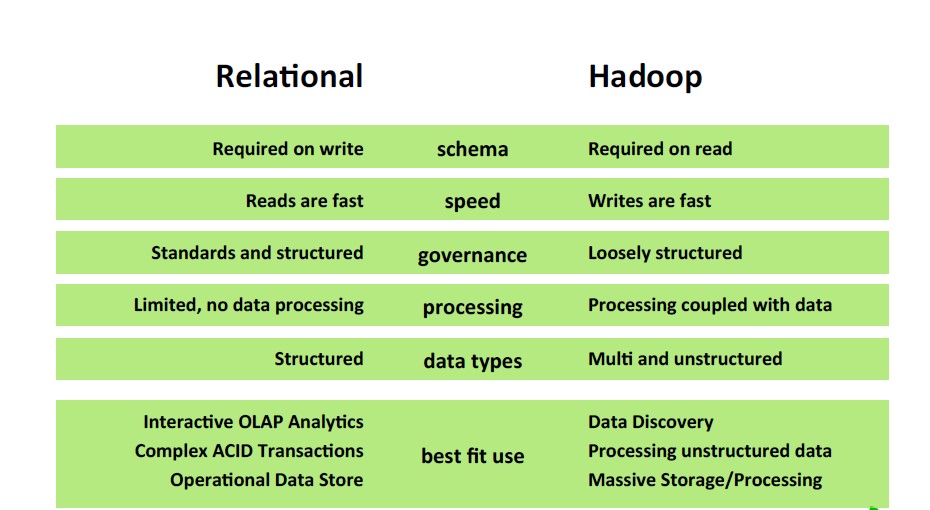
首先,在关系型数据库中,schema必须在写入数据之前就生成的。这可以使得数据必须符合某种模型的规则。
而对于Hadoop,导入的数据保持了它原始的格式,是没有任何schema的。而当数据被提取的时候,这个时候schema才会根据你应用的需要被采用。
另外从读写来看,Hadoop主要是基于批量操作,因此大批量的存储和大批量的处理是它的优势所在。而相比较而言,关系型数据库可以进行事务型读写操作,可能随机读写更具优势。由于他们针对的数据不同,处理方式也不同,所以我们不能够单纯的从某种操作的性能上来评价两者孰胜孰劣。
需要注意的是,Hadoop并不是为了取代传统的关系型数据库。Hadoop是为了存储大数据。这类数据通常因为数据量的的大小或者要求的环境限制等导致你不能存在数据库中。因此即使你打算使用Hadoop, 你仍然需要你的关系型数据库。
什么是HDInsight ?
Apache Hadoop它是一个支持数据密集型的分布式应用的开源软件框架。那么HDInsight就是Apache Hadoop这个框架的微软的分发实现。
HDInsight是开源的,微软的修改可以回馈给主项目。
离开Hadoop本身的定义,我们可以认为HDInsight它是一种通过简单的编程模型,在计算机集群中对大数据集进行分布式处理的平台。它的重要特点是具有容错性,可以处理结构化的数据和非结构化的数据。
微软的HDInsight提供了两种部署模式,Azure HDInsight Service和HDInsight Server (on premise). 同时,微软也在Parallel Data Warehouse的Appliance中提供了HDInsight的实现。另外HDInsight的实现是通过微软同HortonWorks公司进行合作推出的。微软把Hadoop技术冠名为HDInsight, 但它的基础其实是HortonWorks的HortonWorks Data Platform for Windows. 我们介绍的核心部分其实也适用于HDP for Windows。
HDInsight生态系统

从整个HDInsight生态系统来看,首先我们需要有一个分布式的存储机制,它就是HDFS框架。
在这个之上,我们需要有一个分布式的处理机制,那这个机制就是MapReduce。
那基于MapReduce的机制,我们衍生了出了两种更上层的语言机制来帮助实现数据挖掘的功能,它们就是Pig和Hive。
为了管理Metadata,特别是使得其他工具能够在Hive metastore和Pig, MapReduce之间能互相共享数据和Metadata, 又衍生了一个metadata,table的管理系统,叫做HCatalog. HCatalog是Hive的扩展,它可以把Hive中的表的Schema提供给其他工具。比如说,它提供了两个接口HCatLoader和HCatStorer给Pig来读和写HCatalog托管的表。
Hbase是一个Hadoop的Database, 它是一个NoSQL的Database。
在MapReduce挖掘数据部分又延伸出一些专门领域的工具,比如机器学习,图像挖掘,状态处理等等。为了与不是Hadoop的关系型数据达到整合,我们又有了ODBC driver, SQOOP,REST接口等等。
有了这些与外部的接口,我们就可以用BI的工具进行大数据处理的分析和展现。另一方面,为了能够有效的管理和调度Hadoop的Job, 又应运而生了一个工作流工具,叫做Oozie。还有关于日志的Aggregation。
那有了这些,我们可以把Azure的数据,以及PDW的数据也可以联系进来,我们可以通过AD, System Center,以及各式各类的世界数据都整合进来。这样就形成了一个完整的生态系统。