Understand volume languages in Azure NetApp Files
Volume language (akin to system locales on client operating systems) on an Azure NetApp Files volume controls the supported languages and character sets when using NFS and SMB protocols. Azure NetApp Files uses a default volume language of C.UTF-8, which provides POSIX compliant UTF-8 encoding for character sets. The C.UTF-8 language natively supports characters with a size of 0-3 bytes, which includes a majority of the world’s languages on the Basic Multilingual Plane (BMP) (including Japanese, German, and most of Hebrew and Cyrillic). For more information about the BMP, see Unicode.
Characters outside of the BMP sometimes exceed the 3-byte size supported by Azure NetApp Files. They thus need to use surrogate pair logic, where multiple character byte sets are combined to form new characters. Emoji symbols, for example, fall into this category and are supported in Azure NetApp Files in scenarios where UTF-8 isn't enforced: such as Windows clients that use UTF-16 encoding or NFSv3 that doesn't enforce UTF-8. NFSv4.x does enforce UTF-8, meaning surrogate pair characters don't display properly when using NFSv4.x.
Nonstandard encoding, such as Shift-JIS and less common CJK characters, also don't display properly when UTF-8 is enforced in Azure NetApp Files.
Tip
You should send and receive text using UTF-8 to avoid situations where characters can't be translated properly, which can cause file creation/rename or copy error scenarios.
The volume language settings currently can't be modified in Azure NetApp Files. For more information, see Protocol behaviors with special character sets.
For best practices, see Character set best practices.
Character encoding in Azure NetApp Files NFS and SMB volumes
In an Azure NetApp Files file sharing environment, file and folder names are represented by a series of characters that end users read and interpret. The way those characters are displayed depends on how the client sends and receives encoding of those characters. For instance, if a client is sending legacy American Standard Code for Information Interchange (ASCII) encoding to the Azure NetApp Files volume when accessing it, then it's limited to displaying only characters that are supported in the ASCII format.
For instance, the Japanese character for data is 資. Since this character can't be represented in ASCII, a client using ASCII encoding show a “?” instead of 資.
ASCII supports only 95 printable characters, principally those found in the English language. Each of those characters uses 1 byte, which is factored into the total file path length on an Azure NetApp Files volume. This limits the internationalization of datasets, since file names can have a variety of characters not recognized by ASCII, from Japanese to Cyrillic to emoji. An international standard (ISO/IEC 8859) attempted to support more international characters, but also had its limitations. Most modern clients send and receive characters using some form of Unicode.
Unicode
As a result of the limitations of ASCII and ISO/IEC 8859 encodings, the Unicode standard was established so anyone can view their home region's language from their devices.
- Unicode supports over one million character sets by increasing both the number of bytes per character allowed (up to 4 bytes) and the total number of bytes allowed in a file path as opposed to older encodings, such as ASCII.
- Unicode supports backwards compatibility by reserving the first 128 characters for ASCII, while also ensuring the first 256 code points are identical to ISO/IEC 8859 standards.
- In the Unicode standard, character sets are broken down into planes. A plane is a continuous group of 65,536 code points. In total, there are 17 planes (0-16) in the Unicode standard. The limit is 17 due to the limitations of UTF-16.
- Plane 0 is the Basic Multilingual Plane (BMP). This plane contains the most commonly used characters across multiple languages.
- Of the 17 planes, only five currently have assigned character sets as of Unicode version 15.1.
- Planes 1-17 are known as Supplementary Multilingual Planes (SMP) and contain less-used character sets, for example ancient writing systems such as cuneiform and hieroglyphs, as well as special Chinese/Japanese/Korean (CJK) characters.
- For methods to see character lengths and path sizes and to control the encoding sent to a system, see Converting files to different encodings.
Unicode uses Unicode Transformation Format as its standard, with UTF-8 and UTF-16 being the two main formats.
Unicode planes
Unicode leverages 17 planes of 65,536 characters (256 code points multiplied by 256 boxes in the plane), with Plane 0 as the Basic Multilingual Plane (BMP). This plane contains the most commonly used characters across multiple languages. Because the world's languages and character sets exceed 65536 characters, more planes are needed to support less commonly used character sets.
For instance, Plane 1 (the Supplementary Multilingual Planes (SMP)) includes historic scripts like cuneiform and Egyptian hieroglyphs as well as some Osage, Warang Citi, Adlam, Wancho, and Toto. Plane 1 also includes some symbols and emoticon characters.
Plane 2 – the Supplementary Ideographic Plane (SIP) – contains Chinese/Japanese/Korean (CJK) Unified Ideographs. Characters in planes 1 and 2 generally are 4 bytes in size.
For example:
- The "grinning face with big eyes" emoticon "😃" in plane 1 is 4 bytes in size.
- The Egyptian hieroglyph "𓀀" in plane 1 is 4 bytes in size.
- The Osage character "𐒸" in plane 1 is 4 bytes in size.
- The CJK character "𫝁" in plane 2 is 4 bytes in size.
Because these characters are all >3 bytes in size, they require the use of surrogate pairs to work properly. Azure NetApp Files natively supports surrogate pairs, but the display of the characters varies depending on the protocol in use, the client's locale settings and the settings of the remote client access application.
UTF-8
UTF-8 uses 8-bit encoding and can have up to 1,112,064 code points (or characters). UTF-8 is the standard encoding across all languages in Linux-based operating systems. Because UTF-8 uses 8-bit encoding, the maximum unsigned integer possible is 255 (2^8 – 1), which is also the maximum file name length for that encoding. UTF-8 is used on over 98% of pages on the Internet, making it by far the most adopted encoding standard. The Web Hypertext Application Technology Working Group (WHATWG) considers UTF-8 "the mandatory encoding for all [text]" and that for security reasons browser applications shouldn't use UTF-16.
Characters in UTF-8 format each use 1 to 4 bytes, but nearly all characters in all languages use between 1 and 3 bytes. For instance:
- The Latin alphabet letter "A" uses 1 byte. (One of the 128 reserved ASCII characters)
- A copyright symbol "©" uses 2 bytes.
- The character "ä" uses 2 bytes. (1 byte for "a" + 1 byte for the umlaut)
- The Japanese Kanji symbol for data (資) uses 3 bytes.
- A grinning face emoji (😃) uses 4 bytes.
Language locales can use either computer standard UTF-8 (C.UTF-8) or a more region-specific format, such as en_US.UTF-8, ja.UTF-8, etc. You should use UTF-8 encoding for Linux clients when accessing Azure NetApp Files whenever possible. As of OS X, macOS clients also use UTF-8 for its default encoding and shouldn't be adjusted.
Windows clients use UTF-16. In most cases, this setting should be left as the default for the OS locale, but newer clients offer beta support for UTF-8 characters via a checkbox. Terminal clients in Windows can also be adjusted to use UTF-8 in PowerShell or CMD as needed. For more information, see Dual protocol behaviors with special character sets.
UTF-16
UTF-16 uses 16-bit encoding and is capable of encoding all 1,112,064 code points of Unicode. The encoding for UTF-16 can use one or two 16-bit code units, each 2 bytes in size. All characters in UTF-16 use 2 or 4-byte sizes. Characters in UTF-16 that use 4 bytes leverage surrogate pairs, which combine two separate 2-byte characters to create a new character. These supplementary characters fall outside of the standard BMP plane and into one of the other multilingual planes.
UTF-16 is used in Windows operating systems and APIs, Java, and JavaScript. Since it doesn't support backwards compatibility with ASCII formats, it never gained popularity on the web. UTF-16 only makes up around 0.002% of all pages on the internet. The Web Hypertext Application Technology Working Group (WHATWG) considers UTF-8 "the mandatory encoding for all text" and recommends applications not use UTF-16 for browser security.
Azure NetApp Files supports most UTF-16 characters, including surrogate pairs. In cases where the character isn't supported, Windows clients report an error of "file name you specified isn't valid or too long."
Character set handling over remote clients
Remote connections to clients that mount Azure NetApp Files volumes (such as SSH connections to Linux clients to access NFS mounts) can be configured to send and receive specific volume language encodings. The language encoding sent to the client via the remote connection utility controls how character sets are created and viewed. As a result, a remote connection that uses a different language encoding than another remote connection (such as two different PuTTY windows) can show different results for characters when listing file and folder names in the Azure NetApp Files volume. In most cases, this won't create discrepancies (such as for Latin/English characters), but in the cases of special characters, such as emojis, results can vary.
For instance, using an encoding of UTF-8 for the remote connection shows predictable results for characters in Azure NetApp Files volumes since C.UTF-8 is the volume language. The Japanese character for "data" (資) displays differently depending on the encoding being sent by the terminal.
Character encoding in PuTTY
When a PuTTY window uses UTF-8 (found in Windows's translation settings), the character is represented properly for an NFSv3 mounted volume in Azure NetApp Files:

If the PuTTY window uses a different encoding, such as ISO-8859-1:1998 (Latin-1, West Europe), the same character displays differently even though the file name is the same.

PuTTY, by default, doesn't contain CJK encodings. There are patches available to add those language sets to PuTTY.
Character encodings in Bastion
Microsoft Azure recommends using Bastion for remote connectivity to virtual machines (VMs) in Azure. When using Bastion, the language encoding sent and received isn't exposed in the configuration but leverages standard UTF-8 encoding. As a result, most character sets seen in PuTTY using UTF-8 should also be visible in Bastion, provided the character sets are supported in the protocol being used.

Tip
Other SSH terminals can be used such as TeraTerm. TeraTerm provides a wider range of supported character sets by default, including CJK encodings and nonstandard encodings such as Shift-JIS.
Protocol behaviors with special character sets
Azure NetApp Files volumes use UTF-8 encoding and natively support characters that don't exceed 3 bytes. All characters in the ASCII and UTF-8 set display properly because they fall in the 1 to 3-byte range. For example:
- The Latin alphabet character "A" uses 1 byte (one of the 128 reserved ASCII characters).
- A copyright symbol © uses 2 bytes.
- The character "ä" uses 2 bytes (1 byte for "a" and 1 byte for the umlaut).
- The Japanese Kanji symbol for data (資) uses 3 bytes.
Azure NetApp Files also support some characters that exceed 3 bytes via surrogate pair logic (such as emoji), provided the client encoding and protocol version supports them. For more information about protocol behaviors, see:
SMB behaviors
In SMB volumes, Azure NetApp Files creates and maintains two names for files or directories in any directory that has access from an SMB client: the original long name and a name in 8.3 format.
File names in SMB with Azure NetApp Files
When file or directory names exceed the allowed character bytes or use unsupported characters, Azure NetApp Files generates an 8.3-format name as follows:
- It truncates the original file or directory name.
- It appends a tilde (~) and a numeral (1-5) to file or directory names that are no longer unique after being truncated. If there are more than five files with nonunique names, Azure NetApp Files creates a unique name with no relation to the original name. For files, Azure NetApp Files truncates the file name extension to three characters.
For example, if an NFS client creates a file named specifications.html, Azure NetApp Files creates the file name specif~1.htm following the 8.3 format. If this name already exists, Azure NetApp Files uses a different number at the end of the file name. For example, if an NFS client then creates another file named specifications\_new.html, the 8.3 format of specifications\_new.html is specif~2.htm.
Special character in SMB with Azure NetApp Files
When using SMB with Azure NetApp Files volumes, characters that exceed 3 bytes used in file and folder names (including emoticons) are allowed due to surrogate pair support. The following is what Windows Explorer sees for characters outside of the BMP on a folder created from a Windows client when using English with the default UTF-16 encoding.
Note
The default font in Windows Explorer is Segoe UI. Font changes can affect how some characters display on clients.

How the characters display on the client depends on the system font and the language and locale settings. In general, characters that fall into the BMP are supported across all protocols, regardless if the encoding is UTF-8 or UTF-16.
When using either CMD or PowerShell, the character set display depends on the font settings. These utilities have limited font choices by default. CMD uses Consolas as the default font.
File names might not display as expected depending on the font used as some consoles don't natively support Segoe UI or other fonts that render special characters properly.
This issue can be addressed on Windows clients by using PowerShell ISE, which provides more robust font support. For instance, setting the PowerShell ISE to Segoe UI displays the file names with supported characters properly.

However, PowerShell ISE is designed for scripting, rather than managing shares. Newer Windows versions offer Windows Terminal, which allows for control over the fonts and encoding values.
Note
Use the chcp command to view the encoding for the terminal. For a complete list of code pages, see Code page identifiers.

If the volume is enabled for dual-protocol (both NFS and SMB), you might observe different behaviors. For more information, see Dual-protocol behaviors with special character sets.
NFS behaviors
How NFS displays special characters depends on the version of NFS used, the client's locale settings, installed fonts, and the settings of the remote connection client in use. For instance, using Bastion to access an Ubuntu client handles character displays differently than a PuTTY client set to a different locale on the same VM. The ensuing NFS examples rely on these locale settings for the Ubuntu VM:
~$ locale
LANG=C.UTF-8
LANGUAGE=
LC\_CTYPE="C.UTF-8"
LC\_NUMERIC="C.UTF-8"
LC\_TIME="C.UTF-8"
LC\_COLLATE="C.UTF-8"
LC\_MONETARY="C.UTF-8"
LC\_MESSAGES="C.UTF-8"
LC\_PAPER="C.UTF-8"
LC\_NAME="C.UTF-8"
LC\_ADDRESS="C.UTF-8"
LC\_TELEPHONE="C.UTF-8"
LC\_MEASUREMENT="C.UTF-8"
LC\_IDENTIFICATION="C.UTF-8"
LC\_ALL=
NFSv3 behavior
NFSv3 doesn't enforce UTF encoding on files and folders. In most cases, special character sets should have no issues. However, the connection client used can affect how characters are sent and received. For instance, using Unicode characters outside of the BMP for a folder name in the Azure connection client Bastion can result in some unexpected behavior due to how the client encoding works.
In the following screenshot, Bastion is unable to copy and paste the values to the CLI prompt from outside of the browser when naming a directory over NFSv3. When attempting to copy and paste the value of NFSv3Bastion𓀀𫝁😃𐒸, the special characters display as quotation marks in the input.

The copy-paste command is permitted over NFSv3, but the characters are created as their numeric values, affecting their display:
NFSv3Bastion'$'\262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355
This display is due to the encoding used by Bastion for sending text values when copying and pasting.
When using PuTTY to create a folder with the same characters over NFSv3, the folder name than differently in Bastion than when Bastion was used to create it. The emoticon shows as expected (due to the installed fonts and locale setting), but the other characters (such as the Osage "𐒸") don't.

From a PuTTY window, the characters display correctly:

NFSv4.x behavior
NFSv4.x enforces UTF-8 encoding in file and folder names per the RFC-8881 internationalization specs.
As a result, if a special character is sent with non-UTF-8 encoding, NFSv4.x might not allow the value.
In some cases, a command can be allowed using a character outside of the Basic Multilingual Plane (BMP), but it might not display the value after it's created.
For instance, issuing mkdir with a folder name including the characters "𓀀𫝁😃𐒸" (characters in the Supplementary Multilingual Planes (SMP) and the Supplementary Ideographic Plane (SIP)) seems to succeed in NFSv4.x. The folder won't be visible when running the ls command.
root@ubuntu:/NFSv4/NFS$ mkdir "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS$ ls -la
total 8
drwxrwxr-x 3 nobody 4294967294 4096 Jan 10 17:15 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
root@ubuntu:/NFSv4/NFS$
The folder exists in the volume. Changing to that hidden directory name works from the PuTTY client, and a file can be created inside of that directory.
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ sudo touch Unicode.txt
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ ls -la
-rw-r--r-- 1 root root 0 Jan 10 17:31 Unicode.txt
A stat command from PuTTY also confirms the folder exists:
root@ubuntu:/NFSv4/NFS$ stat "NFSv4 Putty 𓀀𫝁😃𐒸"
**File: NFSv4 Putty** **𓀀**** 𫝁 ****😃**** 𐒸**
Size: 4096 Blocks: 8 IO Block: 262144 **directory**
Device: 3ch/60d Inode: 101 Links: 2
Access: (0775/drwxrwxr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-01-10 17:15:44.860775000 +0000
Modify: 2024-01-10 17:31:35.049770000 +0000
Change: 2024-01-10 17:31:35.049770000 +0000
Birth: -
Even though the folder is confirmed to exist, wildcard commands don't work, as the client can't officially "see" the folder in the display.
root@ubuntu:/NFSv4/NFS$ cp \* /NFSv3/
cp: can't stat '\*': No such file or directory
NFSv4.1 sends an error to the client when it encounters a character that doesn't rely on UTF-8 encoding.
For example, when using Bastion to attempt access to the same directory we created using PuTTY over NFSv4.1, this is the result:
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃�"
-bash: cd: $'NFSv4 Putty \262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355': Invalid argument
The "invalid argument" error message doesn't help diagnose the root cause, but a packet capture shines a light on the problem:
78 1.704856 y.y.y.y x.x.x.x NFS 346 V4 Call (Reply In 79) LOOKUP DH: 0x44caa451/NFSv4 Putty ��������
79 1.705058 x.x.x.x y.y.y.y NFS 166 V4 Reply (Call In 25) OPEN Status: NFS4ERR\_INVAL
NFS4ERR_INVAL is covered in RFC-8881.
Since the folder can be accessed from PuTTY (due to the encoding being sent and received), it can be copied if the name is specified. After copying that folder from the NFSv4.1 Azure NetApp Files volume to the NFSv3 Azure NetApp Files volume, the folder name displays:
root@ubuntu:/NFSv4/NFS$ cp -r /NFSv4/NFS/"NFSv4 Putty 𓀀𫝁😃𐒸" /NFSv3/NFSv3/
root@ubuntu:/NFSv4/NFS$ ls -la /NFSv3/NFSv3 | grep v4
drwxrwxr-x 2 root root 4096 Jan 10 17:49 NFSv4 Putty 𓀀𫝁😃𐒸
The same NFS4ERR\_INVAL error can be seen if a file conversion (using `iconv``) to a non-UTF-8 format is attempted, such as Shift-JIS.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
For more information, see Converting files to different encodings.
Dual protocol behaviors
Azure NetApp Files allows volumes to be accessed by both NFS and SMB via dual-protocol access. Because of the vast differences in the language encoding used by NFS (UTF-8) and SMB (UTF-16), character sets, file and folder names, and path lengths can have very different behaviors across protocols.
Viewing NFS-created files and folders from SMB
When Azure NetApp Files is used for dual-protocol access (SMB and NFS), a character set unsupported by UTF-16 might be used in a file name created using UTF-8 via NFS. In those scenarios, when SMB accesses a file with unsupported characters, the name is truncated in SMB using the 8.3 short file name convention.
NFSv3-created files and SMB behaviors with character sets
NFSv3 doesn't enforce UTF-8 encoding. Characters using nonstandard language encodings (such as Shift-JIS) work with Azure NetApp Files when using NFSv3.
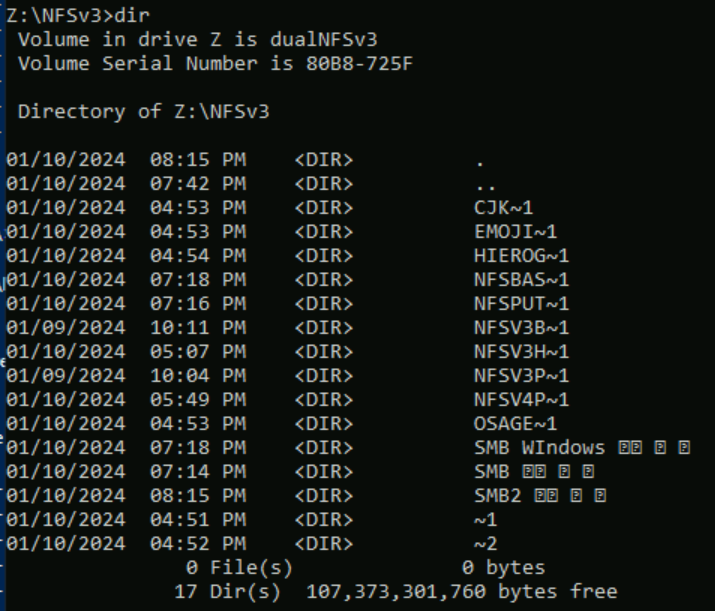
In the following example, a series of folder names using different character sets from various planes in Unicode were created in an Azure NetApp Files volume using NFSv3. When viewed from NFSv3, these show up correctly.
root@ubuntu:/NFSv3/dual$ ls -la
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-English
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-Japanese-German-資ä
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-copyright-©
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-CJK-plane2-𫝁
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-emoji-plane1-😃
From Windows SMB, the folders with characters found in the BMP display properly, but characters outside of that plane display with the 8.3 name format due to the UTF-8/UTF-16 conversion being incompatible for those characters.
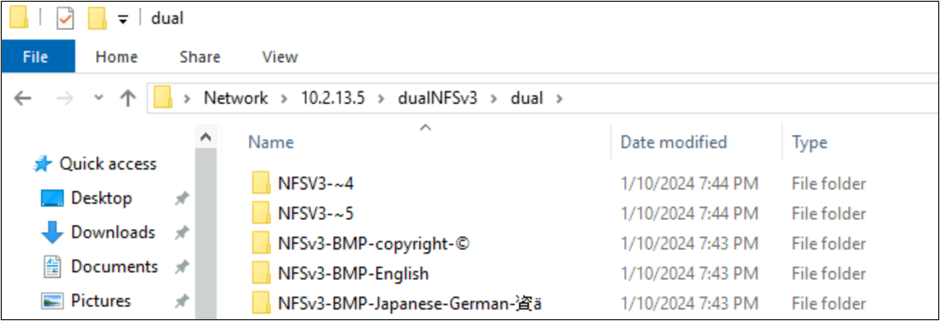
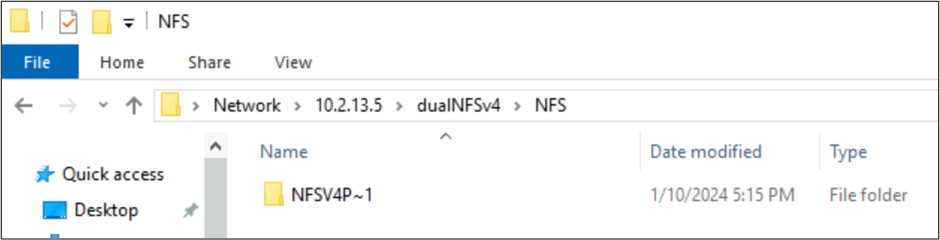
NFSv4.1-created files and SMB behaviors with character sets
In the previous examples, a folder named NFSv4 Putty 𓀀𫝁😃𐒸 was created on an Azure NetApp Files volume over NFSv4.1, but wasn't viewable using NFSv4.1. However, it can be seen using SMB. The name is truncated in SMB to a supported 8.3 format due to the unsupported character sets created from the NFS client and the incompatible UTF-8/UTF-16 conversion for characters in different Unicode planes.
When a folder name uses standard UTF-8 characters found in the BMP (English or otherwise), then SMB translates the names properly.
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-English
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-資ä
root@ubuntu:/NFSv4/NFS$ ls -la
total 16
drwxrwxr-x 5 nobody 4294967294 4096 Jan 10 18:26 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
**drwxrwxr-x 2 root root 4096 Jan 10 18:21 NFS-created-English**
**drwxrwxr-x 2 root root 4096 Jan 10 18:26 NFS-created-**** 資 ****ä**
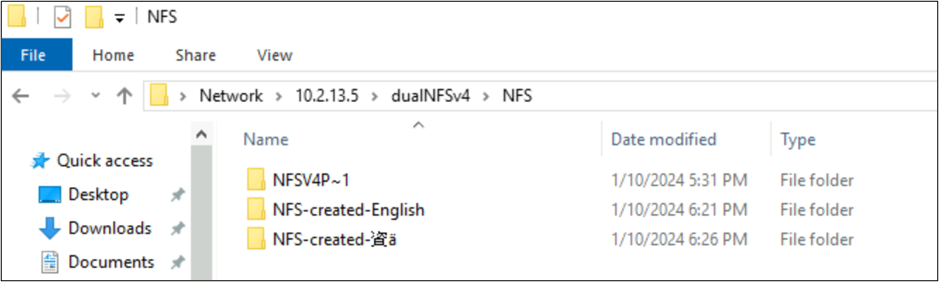
SMB-created files and folders over NFS
Windows clients are the primary type of clients that are used to access SMB shares. These clients default to UTF-16 encoding. It's possible to support some UTF-8 encoded characters in Windows by enabling it in region settings:
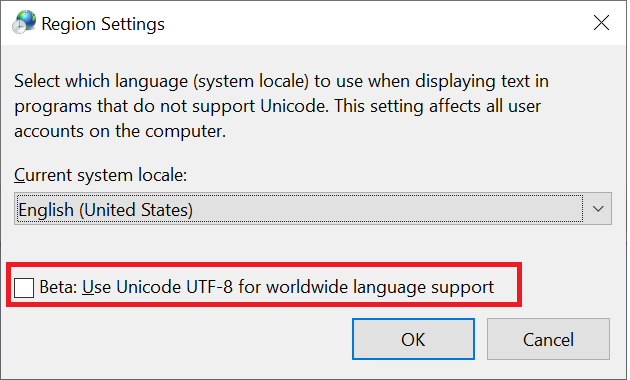
When a file or folder is created over an SMB share in Azure NetApp Files, the character set encodes as UTF-16. As a result, clients using UTF-8 encoding (such as Linux-based NFS clients) might not be able to translate some character sets properly – particularly characters that fall outside of the Basic Multilingual Plane (BMP).
Unsupported character behavior
In those scenarios, when an NFS client accesses a file created using SMB with unsupported characters, the name displays as a series of numeric values representing the Unicode values for the character.
For instance, this folder was created in Windows Explorer using characters outside of the BMP.
PS Z:\SMB\> dir
Directory: Z:\SMB
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/9/2024 9:53 PM SMB𓀀𫝁😃𐒸
Over NFSv3, the SMB-created folder shows up:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 9 21:53 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Over NFSv4.1, the SMB-created folder shows up as follows:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 4 17:09 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Supported character behavior
When the characters are in the BMP, there are no issues between the SMB and NFS protocols and their versions.
For instance, a folder name created using SMB on an Azure NetApp Files volume with characters found in the BMP across multiple languages (English, German, Cyrillic, Runic) shows up fine across all protocols and versions.
- Basic Latin "SMB"
- Greek "ͶΘΩ"
- Cyrillic "ЁЄЊ"
- Runic "ᚠᚱᛯ"
- CJK Compatibility Ideographs "豈滑虜"
This is how the name appears in SMB:
PS Z:\SMB\> mkdir SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/11/2024 8:00 PM SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
This is how the name appears from NFSv3:
$ ls | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
This is how the name appears from NFSv4.1:
$ ls /NFSv4/SMB | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Converting files to different encodings
File and folder names aren't the only portions of file system objects that utilize language encodings. File contents (such as special characters inside a text file) also can play a part. For instance, if a file is attempted to be saved with special characters in an incompatible format, then an error message may be seen. In this case, a file with Katagana characters can't be saved in ANSI, as those characters don't exist in that encoding.
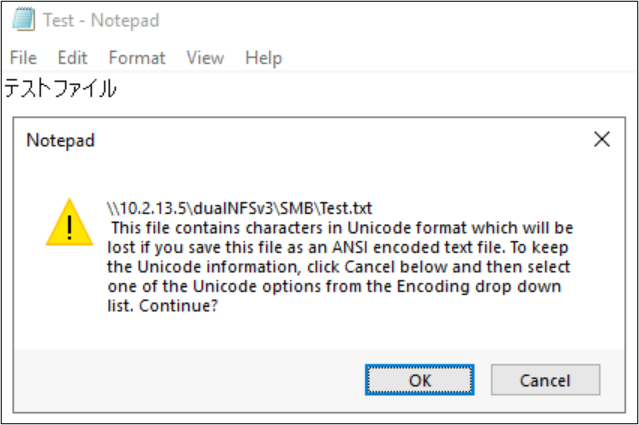
Once that file is saved in that format, the characters get converted to question marks:
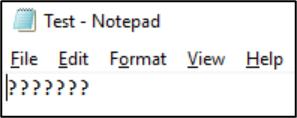
File encodings can be viewed from NAS clients. On Windows clients, you can use an application like Notepad or Notepad++ to view an encoding of a file. If Windows Subsystem for Linux (WSL) or Git are installed on the client, the file command can be used.
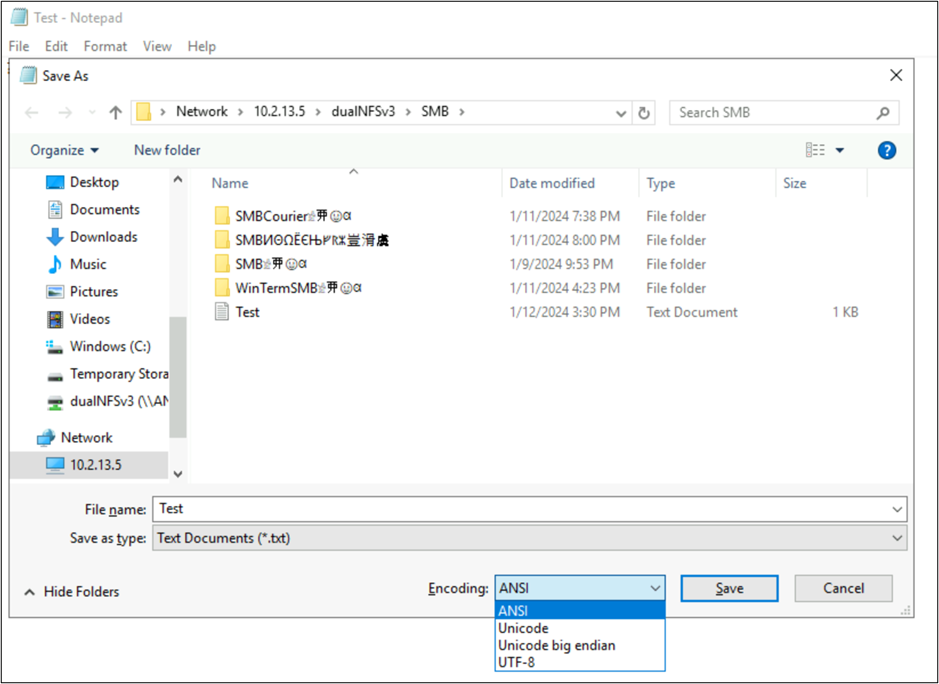
These applications also allow you to change the file's encoding by saving as different encoding types. In addition, PowerShell can be used to convert encoding on files with the Get-Content and Set-Content cmdlets.
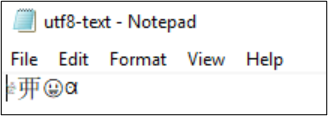
For example, the file utf8-text.txt is encoded as UTF-8 and contains characters outside of the BMP. Because UTF-8 is used, the characters are displayed properly.
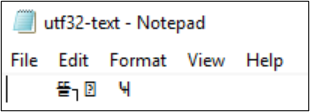
If the encoding is converted to UTF-32, the characters don't display properly.
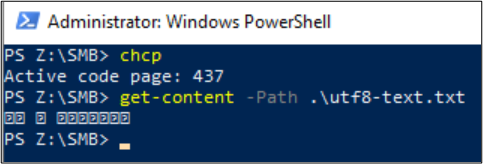
PS Z:\SMB\> Get-Content .\utf8-text.txt |Set-Content -Encoding UTF32 -Path utf32-text.txt
Get-Content can also be used to display the file contents. By default, PowerShell uses UTF-16 encoding (Code page 437) and the font selections for the console are limited, so the UTF-8 formatted file with special characters can't be displayed properly:
Linux clients can use the file command to view the encoding of the file. In dual-protocol environments, if a file is created using SMB, the Linux client using NFS can check the file encoding.
$ file -i utf8-text.txt
utf8-text.txt: text/plain; charset=utf-8
$ file -i utf32-text.txt
utf32-text.txt: text/plain; charset=utf-32le
File encoding conversion can be performed on Linux clients using the iconv command. To see the list of supported encoding formats, use iconv -l.
For instance, the UTF-8 encoded file can be converted to UTF-16.
$ iconv -t UTF16 utf8-text.txt \> utf16-text.txt
$ file -i utf8-text.txt
utf8-text.txt: text/plain; **charset=utf-8**
$ file -i utf16-text.txt
utf16-text.txt: text/plain; **charset=utf-16le**
If the character set on the file's name or in the file's contents aren't supported by the destination encoding, then conversion isn't allowed. For instance, Shift-JIS can't support the characters in the file's contents.
$ iconv -t SJIS utf8-text.txt SJIS-text.txt
iconv: illegal input sequence at position 0
If a file has characters that are supported by the encoding, then conversion will succeed. For instance, if the file contains the Katagana characters テストファイル, then Shift-JIS conversion will succeed over NFS. Since the NFS client being used here doesn't understand Shift-JIS due to locale settings, the encoding shows "unknown-8bit."
$ cat SJIS.txt
テストファイル
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
$ iconv -t SJIS SJIS.txt \> SJIS2.txt
$ file -i SJIS.txt
SJIS.txt: text/plain; **charset=utf-8**
$ file -i SJIS2.txt
SJIS2.txt: text/plain; **charset=unknown-8bit**
Because Azure NetApp Files volumes only support UTF-8 compatible formatting, the Katagana characters are converted to an unreadable format.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
When using NFSv4.x, conversion is allowed when noncompatible characters are present inside of the file's contents, even though NFSv4.x enforces UTF-8 encoding. In this example, a UTF-8 encoded file with Katagana characters located on an Azure NetApp Files volume shows the contents of a file properly.
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
S$ cat SJIS.txt
テストファイル
But once it's converted, the characters in the file display improperly due to the incompatible encoding.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
If the file's name contains unsupported characters for UTF-8, then conversion succeeds over NFSv3, but fails over NFSv4.x due to the protocol version's UTF-8 enforcement.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Character set best practices
When using special characters or characters outside of the standard Basic Multilingual Plane (BMP) on Azure NetApp Files volumes, some best practices should be kept in consideration.
- Since Azure NetApp Files volumes use UTF-8 volume language, the file encoding for NFS clients should also use UTF-8 encoding for consistent results.
- Character sets in file names or contained in file contents should be UTF-8 compatible for proper display and functionality.
- Because SMB uses UTF-16 character encoding, characters outside of the BMP might not display properly over NFS in dual-protocol volumes. As possible, minimize the use of special characters in file contents.
- Avoid using special characters outside of the BMP in file names, especially when using NFSv4.1 or dual-protocol volumes.
- For character sets not in the BMP, UTF-8 encoding should allow display of the characters in Azure NetApp Files when using a single file protocol (SMB only or NFS only). However, dual-protocol volumes aren't able to accommodate these character sets in most cases.
- Nonstandard encoding (such as Shift-JIS) isn't supported on Azure NetApp Files volumes.
- Surrogate pair characters (such as emoji) are supported on Azure NetApp Files volumes.