Configuración de PolyBase en Analytics Platform System (PDW) para obtener acceso a datos externos en Hadoop
En el artículo se explica cómo usar PolyBase en Analytics Platform System (PDW) o un dispositivo APS para consultar datos externos en Hadoop.
Requisitos previos
PolyBase es compatible con dos proveedores de Hadoop: Hortonworks Data Platform (HDP) y Cloudera Distributed Hadoop (CDH). Hadoop sigue el patrón “Principal.Secundaria.Versión” para sus revisiones nuevas y se admiten todas las versiones dentro de una revisión principal y secundaria compatible. Se admiten los siguientes proveedores de Hadoop:
- Hortonworks HDP 1.3 en Linux y Windows Server
- Hortonworks HDP 2.1 - 2.6 en Linux
- Hortonworks HDP 3.0 - 3.1 en Linux
- Hortonworks HDP 2.1 - 2.3 en Windows Server
- Cloudera CDH 4.3 en Linux
- Cloudera CDH 5.1 - 5.5, 5.9 - 5.13, 5.15 y 5.16 en Linux
Configuración de la conectividad de Hadoop
En primer lugar, configure APS para usar el proveedor específico de Hadoop.
Ejecute sp_configure con la “conectividad de hadoop” y defina un valor adecuado para el proveedor. Para hallar el valor, consulte Configuración de la conectividad de PolyBase.
-- Values map to various external data sources. -- Example: value 7 stands for Hortonworks HDP 2.1 to 2.6 and 3.0 - 3.1 on Linux, -- 2.1 to 2.3 on Windows Server, and Azure Blob Storage sp_configure @configname = 'hadoop connectivity', @configvalue = 7; GO RECONFIGURE GOReinicie la región de APS mediante la página Estado del servicio en Configuration Manager del dispositivo.
Habilitar el cálculo de la delegación
Para mejorar el rendimiento de las consultas, habilite el cálculo de la delegación para el clúster de Hadoop:
Abra una conexión de Escritorio remoto al nodo Control de PDW de APS.
Busque el archivo
yarn-site.xmlen el nodo Control. Normalmente, la ruta de acceso es:C:\Program Files\Microsoft SQL Server Parallel Data Warehouse\100\Hadoop\conf\.En el equipo de Hadoop, busque el archivo análogo en el directorio de configuración de Hadoop. En el archivo, busque y copie el valor de la clave de configuración
yarn.application.classpath.En el nodo Control, en el archivo
yarn.site.xml, busque la propiedadyarn.application.classpath. Pegue el valor del equipo de Hadoop en el elemento de valor.Para todas las versiones 5.X de CDH, se deberán agregar los parámetros de configuración
mapreduce.application.classpathal final del archivoyarn.site.xmlo en el archivomapred-site.xml. HortonWorks incluye estas configuraciones dentro de las configuracionesyarn.application.classpath. Consulte Configuración de PolyBase para obtener ejemplos.
Archivos XML de ejemplo para los valores predeterminados de clúster de CDH 5.X
Configuración de Yarn-site.xml con yarn.application.classpath y mapreduce.application.classpath.
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>yarn.resourcemanager.connect.max-wait.ms</name>
<value>40000</value>
</property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>30000</value>
</property>
<!-- Applications' Configuration-->
<property>
<description>CLASSPATH for YARN applications. A comma-separated list of CLASSPATH entries</description>
<!-- Please set this value to the correct yarn.application.classpath that matches your server side configuration -->
<!-- For example: $HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,$HADOOP_YARN_HOME/share/hadoop/yarn/*,$HADOOP_YARN_HOME/share/hadoop/yarn/lib/* -->
<name>yarn.application.classpath</name>
<value>$HADOOP_CLIENT_CONF_DIR,$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/,$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,$MR2_CLASSPATH*</value>
</property>
<!-- kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>yarn.resourcemanager.principal</name>
<value></value>
</property>
-->
</configuration>
Si decide dividir las dos opciones de configuración en mapred-site.xml y yarn-site.xml, los archivos serán los siguientes:
Para yarn-site.xml:
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>yarn.resourcemanager.connect.max-wait.ms</name>
<value>40000</value>
</property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>30000</value>
</property>
<!-- Applications' Configuration-->
<property>
<description>CLASSPATH for YARN applications. A comma-separated list of CLASSPATH entries</description>
<!-- Please set this value to the correct yarn.application.classpath that matches your server side configuration -->
<!-- For example: $HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,$HADOOP_YARN_HOME/share/hadoop/yarn/*,$HADOOP_YARN_HOME/share/hadoop/yarn/lib/* -->
<name>yarn.application.classpath</name>
<value>$HADOOP_CLIENT_CONF_DIR,$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/*</value>
</property>
<!-- kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>yarn.resourcemanager.principal</name>
<value></value>
</property>
-->
</configuration>
Para mapred-site.xml:
Anote la propiedad mapreduce.application.classpath. En CDH 5.x, encontrará los valores de configuración bajo la misma convención de nomenclatura de Ambari.
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration xmlns:xi="http://www.w3.org/2001/XInclude">
<property>
<name>mapred.min.split.size</name>
<value>1073741824</value>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,$MR2_CLASSPATH</value>
</property>
<!--kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>mapreduce.jobhistory.principal</name>
<value></value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value></value>
</property>
-->
</configuration>
Archivos XML de ejemplo para los valores predeterminados de clúster de HDP 3.X
Para yarn-site.xml:
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>yarn.resourcemanager.connect.max-wait.ms</name>
<value>40000</value>
</property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>30000</value>
</property>
<!-- Applications' Configuration-->
<property>
<description>CLASSPATH for YARN applications. A comma-separated list of CLASSPATH entries</description>
<!-- Please set this value to the correct yarn.application.classpath that matches your server side configuration -->
<!-- For example: $HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,$HADOOP_YARN_HOME/share/hadoop/yarn/*,$HADOOP_YARN_HOME/share/hadoop/yarn/lib/* -->
<name>yarn.application.classpath</name>
<value>$HADOOP_CONF_DIR,/usr/hdp/3.1.0.0-78/hadoop/*,/usr/hdp/3.1.0.0-78/hadoop/lib/*,/usr/hdp/current/hadoop-hdfs-client/*,/usr/hdp/current/hadoop-hdfs-client/lib/*,/usr/hdp/current/hadoop-yarn-client/*,/usr/hdp/current/hadoop-yarn-client/lib/*,/usr/hdp/3.1.0.0-78/hadoop-mapreduce/*,/usr/hdp/3.1.0.0-78/hadoop-yarn/*,/usr/hdp/3.1.0.0-78/hadoop-yarn/lib/*,/usr/hdp/3.1.0.0-78/hadoop-mapreduce/lib/*,/usr/hdp/share/hadoop/common/*,/usr/hdp/share/hadoop/common/lib/*,/usr/hdp/share/hadoop/tools/lib/*</value>
</property>
<!-- kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>yarn.resourcemanager.principal</name>
<value></value>
</property>
-->
</configuration>
Configuración de una tabla externa
Para consultar los datos en el origen de datos de Hadoop, debe definir una tabla externa para usar en las consultas de Transact-SQL. Los pasos siguientes describen cómo configurar la tabla externa.
Cree una clave maestra en la base de datos. Esto es necesario para cifrar el secreto de credencial.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo';Cree una credencial de ámbito de base de datos para los clústeres de Hadoop protegidos mediante Kerberos.
-- IDENTITY: the Kerberos user name. -- SECRET: the Kerberos password CREATE DATABASE SCOPED CREDENTIAL HadoopUser1 WITH IDENTITY = '<hadoop_user_name>', Secret = '<hadoop_password>';Cree un origen de datos externo con CREATE EXTERNAL DATA SOURCE.
-- LOCATION (Required) : Hadoop Name Node IP address and port. -- RESOURCE MANAGER LOCATION (Optional): Hadoop Resource Manager location to enable pushdown computation. -- CREDENTIAL (Optional): the database scoped credential, created above. CREATE EXTERNAL DATA SOURCE MyHadoopCluster WITH ( TYPE = HADOOP, LOCATION ='hdfs://10.xxx.xx.xxx:xxxx', RESOURCE_MANAGER_LOCATION = '10.xxx.xx.xxx:xxxx', CREDENTIAL = HadoopUser1 );Cree un formato de archivo externo con CREATE EXTERNAL FILE FORMAT.
-- FORMAT TYPE: Type of format in Hadoop (DELIMITEDTEXT, RCFILE, ORC, PARQUET). CREATE EXTERNAL FILE FORMAT TextFileFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS (FIELD_TERMINATOR ='|', USE_TYPE_DEFAULT = TRUE)Cree una tabla externa que señale a los datos almacenados en Hadoop con CREATE EXTERNAL TABLE. En este ejemplo, los datos externos contienen datos de sensor de vehículo.
-- LOCATION: path to file or directory that contains the data (relative to HDFS root). CREATE EXTERNAL TABLE [dbo].[CarSensor_Data] ( [SensorKey] int NOT NULL, [CustomerKey] int NOT NULL, [GeographyKey] int NULL, [Speed] float NOT NULL, [YearMeasured] int NOT NULL ) WITH (LOCATION='/Demo/', DATA_SOURCE = MyHadoopCluster, FILE_FORMAT = TextFileFormat );Cree estadísticas en una tabla externa.
CREATE STATISTICS StatsForSensors on CarSensor_Data(CustomerKey, Speed)
Consultas de PolyBase
PolyBase es adecuado para realizar tres funciones:
- Consultas ad hoc en tablas externas.
- Importar datos.
- Exportar datos.
Las siguientes consultas proporcionan un ejemplo con datos de sensor de vehículo ficticios.
Consultas ad hoc
La siguiente consulta ad hoc combina datos relacionales con datos de Hadoop. Selecciona a los clientes que conducen a más de 35 mph, para lo que combina los datos estructurados del cliente almacenados en APS con los datos del sensor de vehículo almacenados en Hadoop.
SELECT DISTINCT Insured_Customers.FirstName,Insured_Customers.LastName,
Insured_Customers. YearlyIncome, CarSensor_Data.Speed
FROM Insured_Customers, CarSensor_Data
WHERE Insured_Customers.CustomerKey = CarSensor_Data.CustomerKey and CarSensor_Data.Speed > 35
ORDER BY CarSensor_Data.Speed DESC
OPTION (FORCE EXTERNALPUSHDOWN); -- or OPTION (DISABLE EXTERNALPUSHDOWN)
Importación de datos
La consulta siguiente importa datos externos en APS. En este ejemplo se importan los datos relativos a los controladores más rápidos en APS para llevar a cabo un análisis más profundo. Para mejorar el rendimiento, aprovecha la tecnología columnstore en APS.
CREATE TABLE Fast_Customers
WITH
(CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH (CustomerKey))
AS
SELECT DISTINCT
Insured_Customers.CustomerKey, Insured_Customers.FirstName, Insured_Customers.LastName,
Insured_Customers.YearlyIncome, Insured_Customers.MaritalStatus
from Insured_Customers INNER JOIN
(
SELECT * FROM CarSensor_Data where Speed > 35
) AS SensorD
ON Insured_Customers.CustomerKey = SensorD.CustomerKey
Exportación de datos
La consulta siguiente exporta datos de APS a Hadoop. Se puede usar para archivar datos relacionales en Hadoop y, a la vez, seguir pudiendo consultarlos.
-- Export data: Move old data to Hadoop while keeping it query-able via an external table.
CREATE EXTERNAL TABLE [dbo].[FastCustomers2009]
WITH (
LOCATION='/archive/customer/2009',
DATA_SOURCE = HadoopHDP2,
FILE_FORMAT = TextFileFormat
)
AS
SELECT T.* FROM Insured_Customers T1 JOIN CarSensor_Data T2
ON (T1.CustomerKey = T2.CustomerKey)
WHERE T2.YearMeasured = 2009 and T2.Speed > 40;
Visualización de objetos PolyBase en SSDT
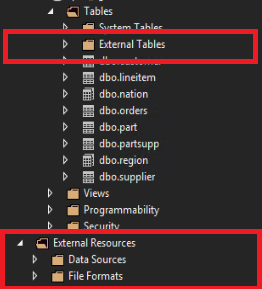
En SQL Server Data Tools, las tablas externas se muestran en una carpeta independiente llamada Tablas externas. Los orígenes de datos y los formatos de archivo externos se encuentran en subcarpetas de Recursos externos.
Contenido relacionado
- Para conocer la configuración de seguridad de Hadoop, consulte Configuración de la seguridad de Hadoop.
- Para obtener más información sobre PolyBase, consulte ¿Qué es PolyBase?.