Procedimientos recomendados de clasificación en el Mapa de datos de Microsoft Purview
La clasificación de datos en el Mapa de datos de Microsoft Purview es una forma de categorizar los recursos de datos mediante la asignación de etiquetas lógicas o clases únicas a los recursos de datos. La clasificación se basa en el contexto empresarial de los datos. Por ejemplo, puede clasificar los activos por número de pasaporte, número de licencia de conductor, número de tarjeta de crédito, código SWIFT, nombre de la persona, etc. Para obtener más información sobre la clasificación en sí, consulte nuestro artículo de clasificación.
En este artículo se describen los procedimientos recomendados que se deben adoptar al clasificar los recursos de datos, de modo que los exámenes sean más eficaces y tenga la información más completa posible sobre todo el patrimonio de datos.
Conjunto de reglas de examen
Mediante el uso de un conjunto de reglas de examen, puede configurar las clasificaciones pertinentes que se deben aplicar al examen determinado del origen de datos. Seleccione las clasificaciones del sistema pertinentes o seleccione clasificaciones personalizadas si ha creado una para los datos que va a examinar.
Por ejemplo, en la imagen siguiente, solo se aplicarán las clasificaciones personalizadas y del sistema seleccionados específicos para el origen de datos que está examinando (por ejemplo, los datos financieros).

Administración de anotaciones
Mientras decide qué clasificaciones se aplicarán, se recomienda:
Vaya al panelClasificaciones de administración de>anotaciones de mapa> de datos.
Revise las clasificaciones del sistema disponibles que se aplicarán a los recursos de datos que va a examinar. Los nombres formales de las clasificaciones del sistema tienen un prefijo MICROSOFT .
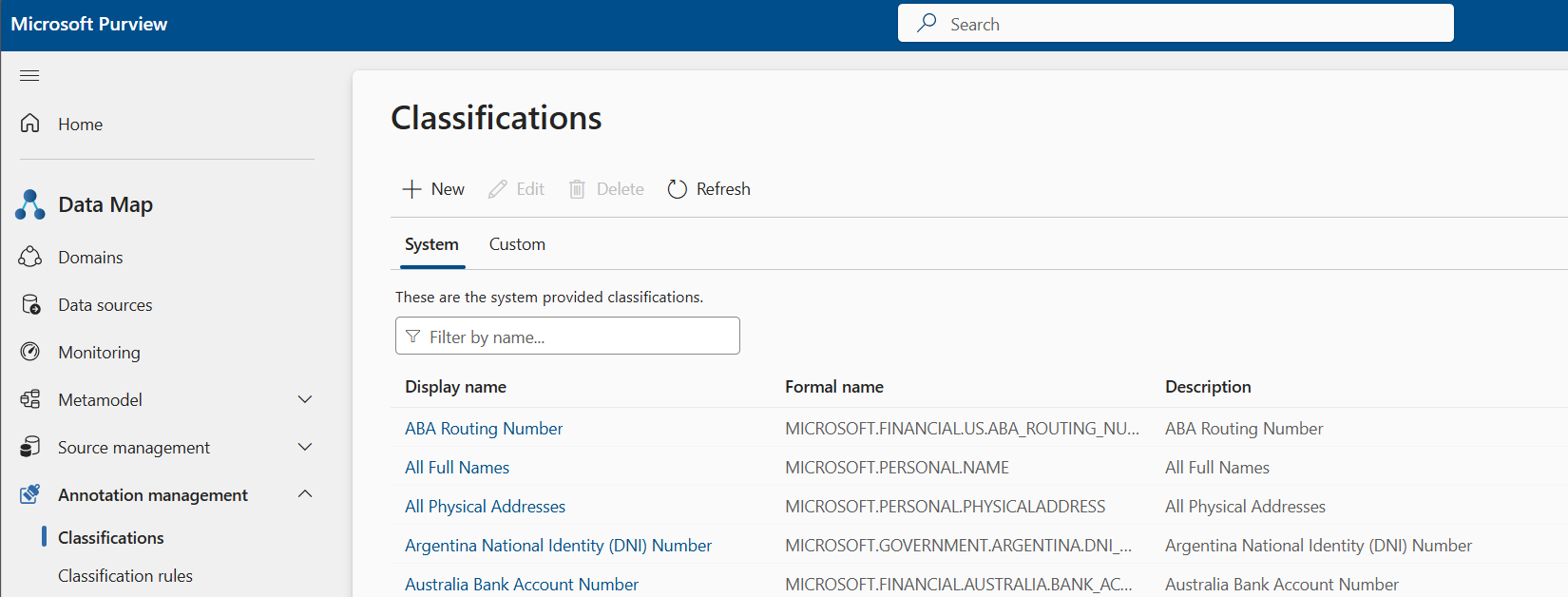
Cree una clasificación personalizada, si es necesario. Seleccione la pestaña Personalizado y, a continuación, + Nuevo. Para obtener más información sobre cómo crear una clasificación personalizada, consulte el artículo de clasificación personalizada.
Cree la regla de clasificación para la clasificación personalizada que creó en el paso anterior. Vaya aReglas de clasificación dela administración de anotaciones de>mapa> de datos. Aquí puede crear la regla de clasificación para el nombre de clasificación personalizado que creó en el paso anterior.
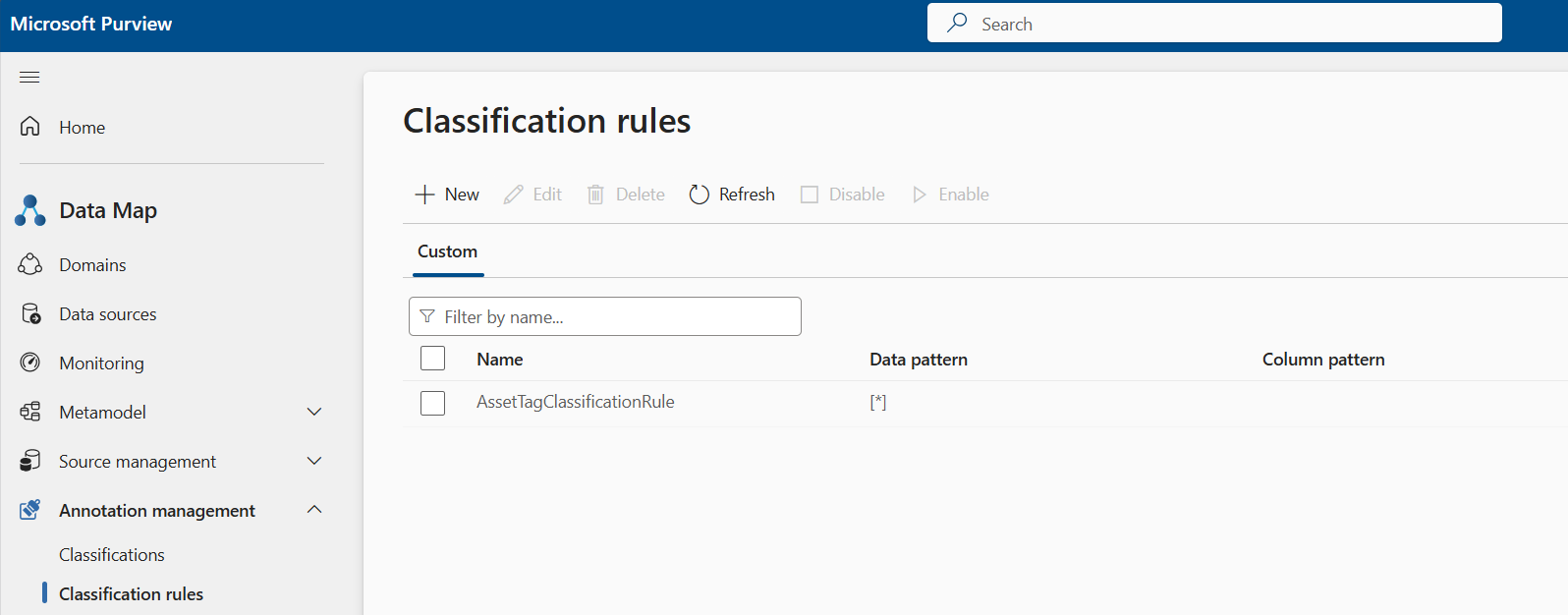


Clasificaciones personalizadas
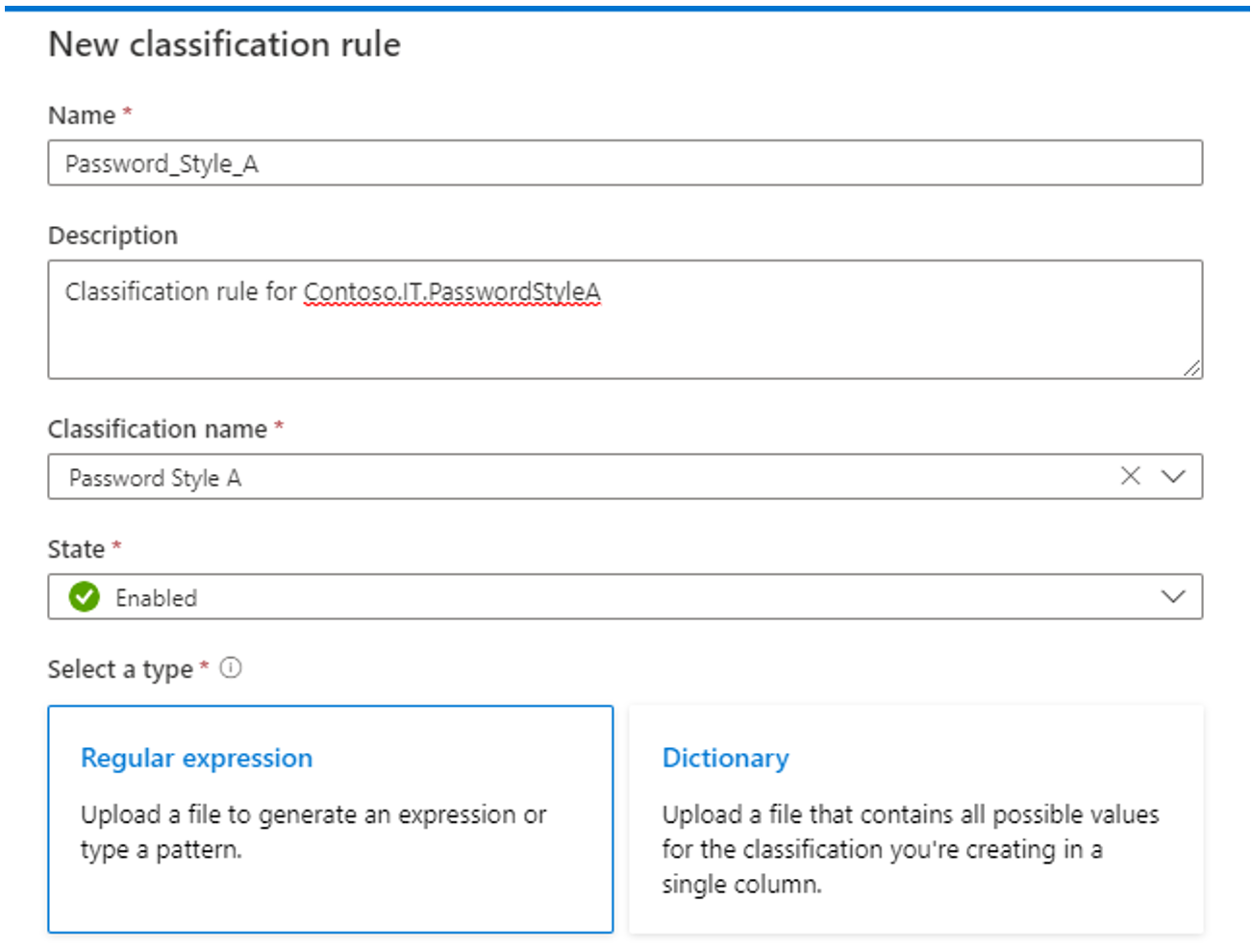
Cree clasificaciones personalizadas solo si las clasificaciones del sistema disponibles no satisfacen sus necesidades.
Para el nombre de la clasificación personalizada, se recomienda usar una convención de espacio de nombres (por ejemplo, <nombre> de la empresa).<unidad de> negocio.<nombre> de clasificación personalizado).
Por ejemplo, para la clasificación de EMPLOYEE_ID personalizada para la empresa ficticia Contoso, el nombre de la clasificación personalizada se CONTOSO.HR. EMPLOYEE_ID y el nombre descriptivo se almacena en el sistema como RR. HH. ID. DE EMPLEADO.

Al crear y configurar las reglas de clasificación para una clasificación personalizada, haga lo siguiente:
Seleccione el nombre de clasificación adecuado para el que se va a crear la regla de clasificación.
El Mapa de datos de Microsoft Purview admite los dos métodos siguientes para crear reglas de clasificación personalizadas:
Use el método Expresión regular (regex) si puede expresar de forma coherente el elemento de datos mediante un patrón de expresión regular o puede generar el patrón mediante un archivo de datos. Asegúrese de que los datos de ejemplo reflejan la población.
Use el método Dictionary solo si la lista de valores del archivo de diccionario representa todos los valores posibles de datos que se van a clasificar y se espera que se ajusten a un conjunto determinado de datos (teniendo en cuenta también valores futuros).
Mediante el método de expresión regular :
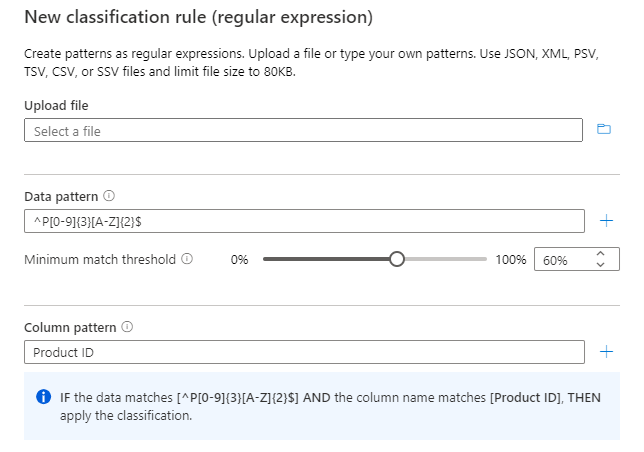
Configure el patrón regex para los datos que se van a clasificar. Asegúrese de que el patrón regex es lo suficientemente genérico como para satisfacer los datos que se clasifican.
Microsoft Purview también proporciona una característica para generar un patrón regex sugerido. Después de cargar un archivo de datos de ejemplo, seleccione uno de los patrones sugeridos y, a continuación, seleccione Agregar a patrones para usar los patrones de datos y columnas sugeridos. Puede modificar los patrones sugeridos o puede escribir sus propios patrones sin tener que cargar un archivo.
También puede configurar el patrón de nombre de columna para que la columna se clasifique para minimizar los falsos positivos.
Configure el parámetro Umbral mínimo de coincidencia que sea aceptable para los datos que coincidan con el patrón de datos para aplicar la clasificación. Los valores de umbral pueden ser del 1 % al 100 %. Se recomienda un valor de al menos el 60 % como umbral para evitar falsos positivos. Sin embargo, puede configurar según sea necesario para los escenarios de clasificación específicos. Por ejemplo, el umbral podría ser tan bajo como un 1 % si desea detectar y aplicar una clasificación para cualquier valor de los datos si coincide con el patrón.
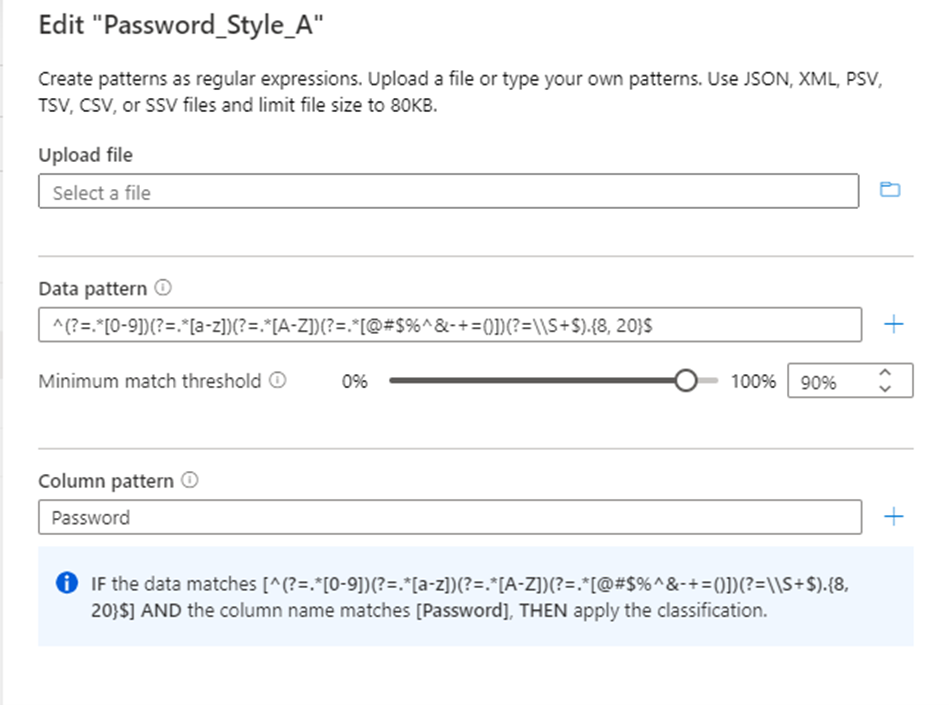
La opción para establecer una regla de coincidencia mínima se deshabilita automáticamente si se agrega más de un patrón de datos a la regla de clasificación.
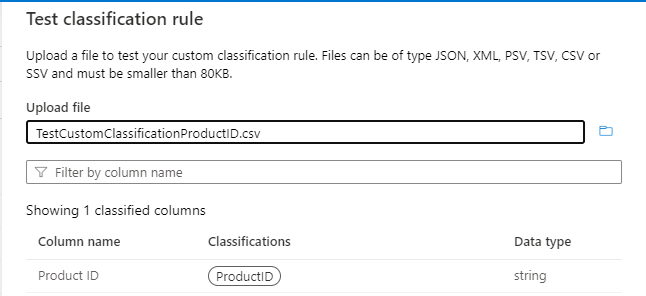
Use la regla De clasificación de pruebas y pruebe con datos de ejemplo para comprobar que la regla de clasificación funciona según lo esperado. Asegúrese de que en los datos de ejemplo (por ejemplo, en un archivo .csv) hay al menos tres columnas, incluida la columna en la que se va a aplicar la clasificación. Si la prueba se realiza correctamente, debería ver la etiqueta de clasificación en la columna, como se muestra en la siguiente imagen:
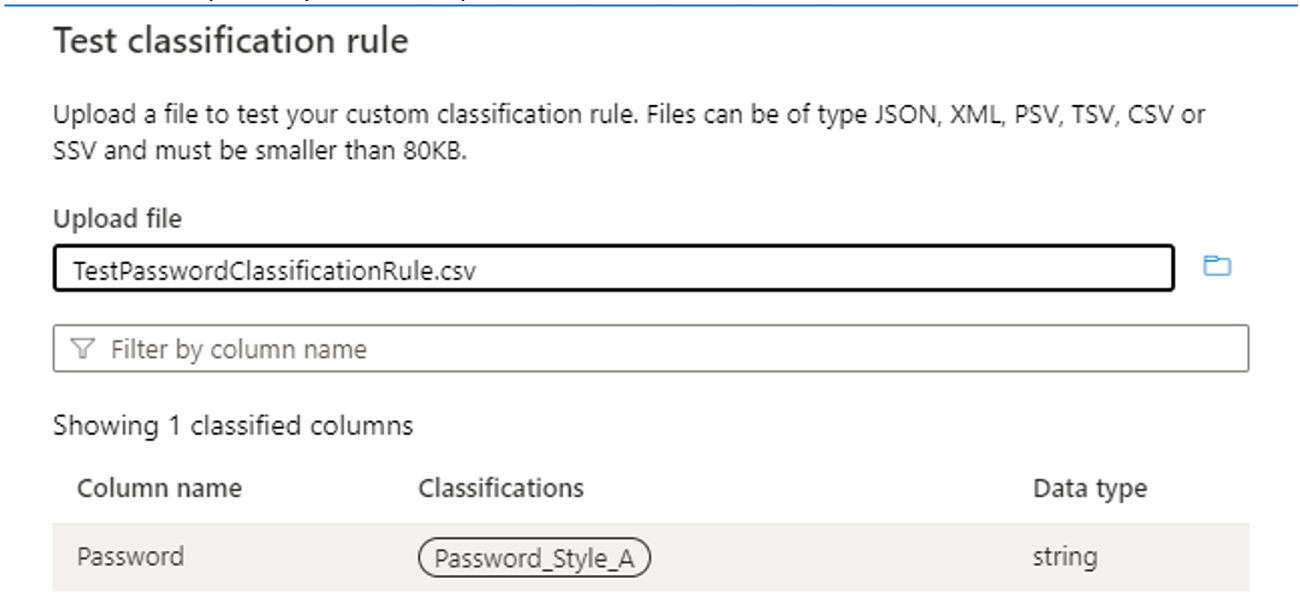
Uso del método Dictionary :
Puede usar el método Dictionary para ajustarse a los datos de enumeración o si la lista de diccionarios de valores posibles está disponible.
Este método admite archivos .csv y .tsv, con un límite de tamaño de archivo de 30 megabytes (MB).



Arquetipos de clasificación personalizados
Funcionamiento del parámetro "threshold" en la expresión regular
Tenga en cuenta los datos de origen de ejemplo en la siguiente imagen. Hay cinco columnas y la regla de clasificación personalizada debe aplicarse a las columnas Sample_col1, Sample_col2 y Sample_col3 para el patrón de datos N{Digit}{Digit}{Digit}AN.
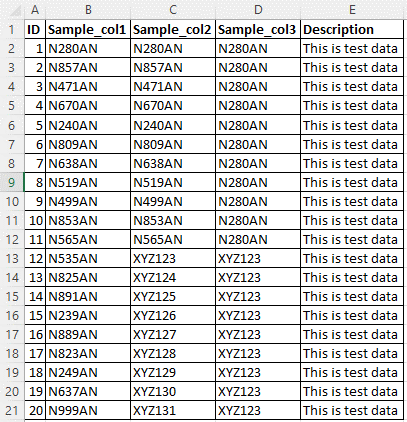
La clasificación personalizada se denomina NDDDAN.
La regla de clasificación (regex para el patrón de datos) es ^N[0-9]{3}AN$.
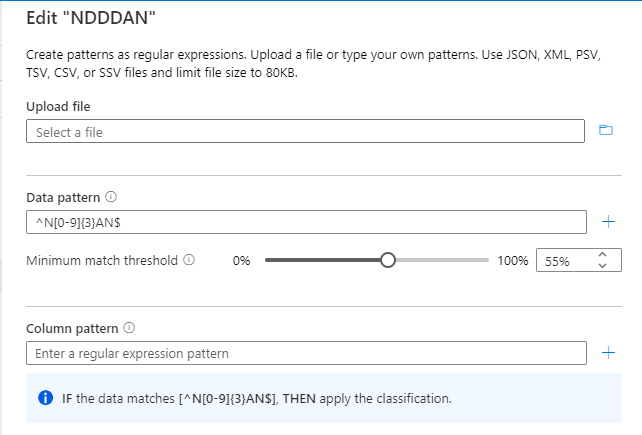
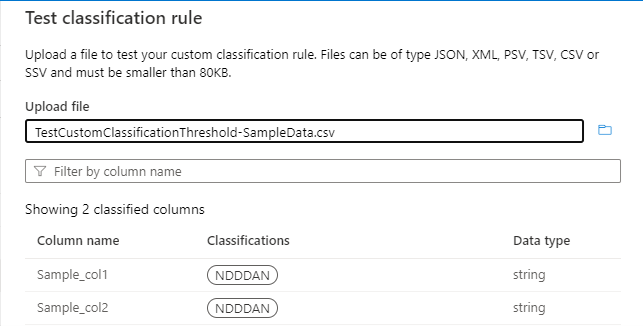
El umbral se calcularía para el patrón "^N[0-9]{3}AN$", como se muestra en la siguiente imagen:

Si tiene un umbral del 55 %, solo se clasificarán las columnas Sample_col1 y Sample_col2 . Sample_col3 no se clasificará, porque no cumple el criterio de umbral del 55 %.




Uso de patrones de datos y columnas
Para los datos de ejemplo especificados, donde tanto la columna B como la columna C tienen patrones de datos similares, puede clasificar en la columna B según el patrón de datos "^P[0-9]{3}[A-Z]{2}$".
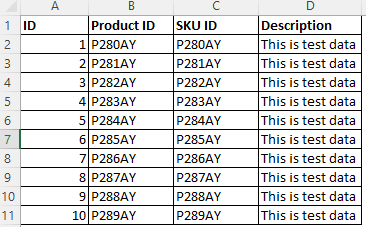
Use el patrón de columna junto con el patrón de datos para asegurarse de que solo se clasifique la columna Id. de producto .
Nota:
El patrón de columna se comprueba como una condición AND con el patrón de datos.
Use la regla De clasificación de pruebas y pruebe con datos de ejemplo para comprobar que la regla de clasificación funciona según lo esperado.



Uso de varios patrones de columna
Si hay varios patrones de columna que se van a clasificar para la misma regla de clasificación, use nombres de columna separados por caracteres de canalización (|). Por ejemplo, para las columnas Id. de producto, Product_ID, ProductID, etc., escriba el patrón de columna como se muestra en la siguiente imagen:

Para obtener más información, vea construcción de alternancia regex.
Consideraciones de clasificación
Estas son algunas consideraciones que debe tener en cuenta al definir las clasificaciones:
Para decidir qué clasificaciones se deben aplicar a los recursos antes del examen, considere cómo se van a usar las clasificaciones. Las etiquetas de clasificación innecesarias pueden parecer ruidosas e incluso engañosas para los consumidores de datos. Puede usar clasificaciones para:
- Describir la naturaleza de los datos que existen en el recurso de datos o el esquema que se examina. En otras palabras, las clasificaciones deben permitir a los clientes identificar el contenido del recurso de datos o el esquema de las etiquetas de clasificación a medida que buscan en el catálogo.
- Establezca prioridades y desarrolle un plan para lograr las necesidades de seguridad y cumplimiento de una organización.
- Describir las fases de los procesos de preparación de datos (zona sin procesar, zona de aterrizaje, etc.) y asignar las clasificaciones a recursos específicos para marcar la fase en el proceso.
Puede asignar clasificaciones en el nivel de recurso o columna automáticamente mediante la inclusión de las clasificaciones pertinentes en la regla de examen, o bien puede asignarlas manualmente después de ingerir los metadatos en el Mapa de datos de Microsoft Purview.
Para la asignación automática, consulte almacenes de datos admitidos para el Mapa de datos de Microsoft Purview.
Antes de examinar los orígenes de datos en el Mapa de datos de Microsoft Purview, es importante comprender los datos y configurar el conjunto de reglas de examen adecuado para ellos (por ejemplo, seleccionando la clasificación del sistema pertinente, las clasificaciones personalizadas o una combinación de ambos), ya que podrían afectar al rendimiento del examen. Para obtener más información, consulte clasificaciones admitidas en el Mapa de datos de Microsoft Purview.
El analizador de Microsoft Purview aplica reglas de muestreo de datos para exámenes profundos (sujetos a clasificación) para clasificaciones personalizadas y del sistema. La regla de muestreo se basa en el tipo de orígenes de datos. Para obtener más información, vea la sección "Muestreo dentro de un archivo" en Orígenes de datos y tipos de archivo admitidos en Microsoft Purview.
Nota:
Umbral de datos distinto: este es el número total de valores de datos distintos que se deben encontrar en una columna antes de que el analizador ejecute el patrón de datos en ella. El umbral de datos distintos no tiene nada que ver con la coincidencia de patrones, pero es un requisito previo para la coincidencia de patrones. Las reglas de clasificación del sistema requieren que haya al menos 8 valores distintos en cada columna para someterlos a la clasificación. El sistema requiere este valor para asegurarse de que la columna contiene suficientes datos para que el analizador la clasifique con precisión. Por ejemplo, no se clasificará una columna que contenga varias filas que contengan el valor 1. Las columnas que contienen una fila con un valor y el resto de las filas tienen valores NULL tampoco se clasificarán. Si especifica varios patrones, este valor se aplica a cada uno de ellos.
Las reglas de muestreo también se aplican a los conjuntos de recursos. Para obtener más información, consulte la sección "Muestreo de archivos del conjunto de recursos" en los orígenes de datos y los tipos de archivo admitidos en el Mapa de datos de Microsoft Purview.
Las clasificaciones personalizadas no se pueden aplicar a los recursos de tipo de documento mediante reglas de clasificación personalizadas. Las clasificaciones de estos tipos solo se pueden aplicar manualmente.
Las clasificaciones personalizadas no se incluyen en ninguna regla de examen predeterminada. Por lo tanto, si se espera la asignación automática de clasificaciones personalizadas, debe implementar y usar una regla de examen personalizada que incluya la clasificación personalizada para ejecutar el examen.
Si aplica clasificaciones manualmente desde el portal de gobernanza de Microsoft Purview, estas clasificaciones se conservan en exámenes posteriores.
Los exámenes posteriores no quitarán ninguna clasificación de los recursos, si se detectaron anteriormente, incluso si las reglas de clasificación son inaplicables.
En el caso de los recursos de datos de origen cifrados , Microsoft Purview selecciona solo nombres de archivo, nombres completos, detalles de esquema para tipos de archivo estructurados y tablas de base de datos. Para que la clasificación funcione, descifre los datos cifrados antes de ejecutar exámenes.