Supervisión y mitigación de la limitación para reducir la latencia en Azure Time Series Insights Gen1
Nota
El servicio Time Series Insights se retirará el 7 de julio de 2024. Considere la posibilidad de migrar entornos existentes a soluciones alternativas lo antes posible. Para obtener más información sobre la desaprobación y la migración, visite la documentación .
Cautela
Este es un artículo de Gen1.
Cuando la cantidad de datos entrantes supera la configuración del entorno, puede experimentar latencia o limitación en Azure Time Series Insights.
Puede evitar la latencia y la limitación configurando correctamente su entorno según la cantidad de datos que desee analizar.
Es más probable que experimente latencia y limitación cuando:
- Agregue un origen de eventos que contenga datos antiguos que puedan superar la tasa de entrada asignada (Azure Time Series Insights tendrá que actualizarse).
- Agregue más orígenes de eventos a un entorno, lo que da lugar a un pico de eventos adicionales (lo que podría superar la capacidad del entorno).
- Inserte grandes cantidades de eventos históricos en un origen de eventos, lo que da lugar a un retraso (Azure Time Series Insights tendrá que ponerse al día).
- Unir datos de referencia con telemetría, lo que da lugar a un tamaño de evento mayor. El tamaño máximo permitido del paquete es de 32 KB; Los paquetes de datos de más de 32 KB se truncan.
Vídeo
Obtenga información sobre el comportamiento de entrada de datos de Azure Time Series Insights y cómo planearlo.
Supervisión de la latencia y limitación con alertas
Las alertas pueden ayudarle a diagnosticar y mitigar los problemas de latencia que se producen en su entorno.
En Azure Portal, seleccione el entorno de Azure Time Series Insights. A continuación, seleccione Alertas.
Seleccione + Nueva regla de alertas. A continuación, se mostrará el panel de creación de reglas . Seleccione Agregar en CONDITION.
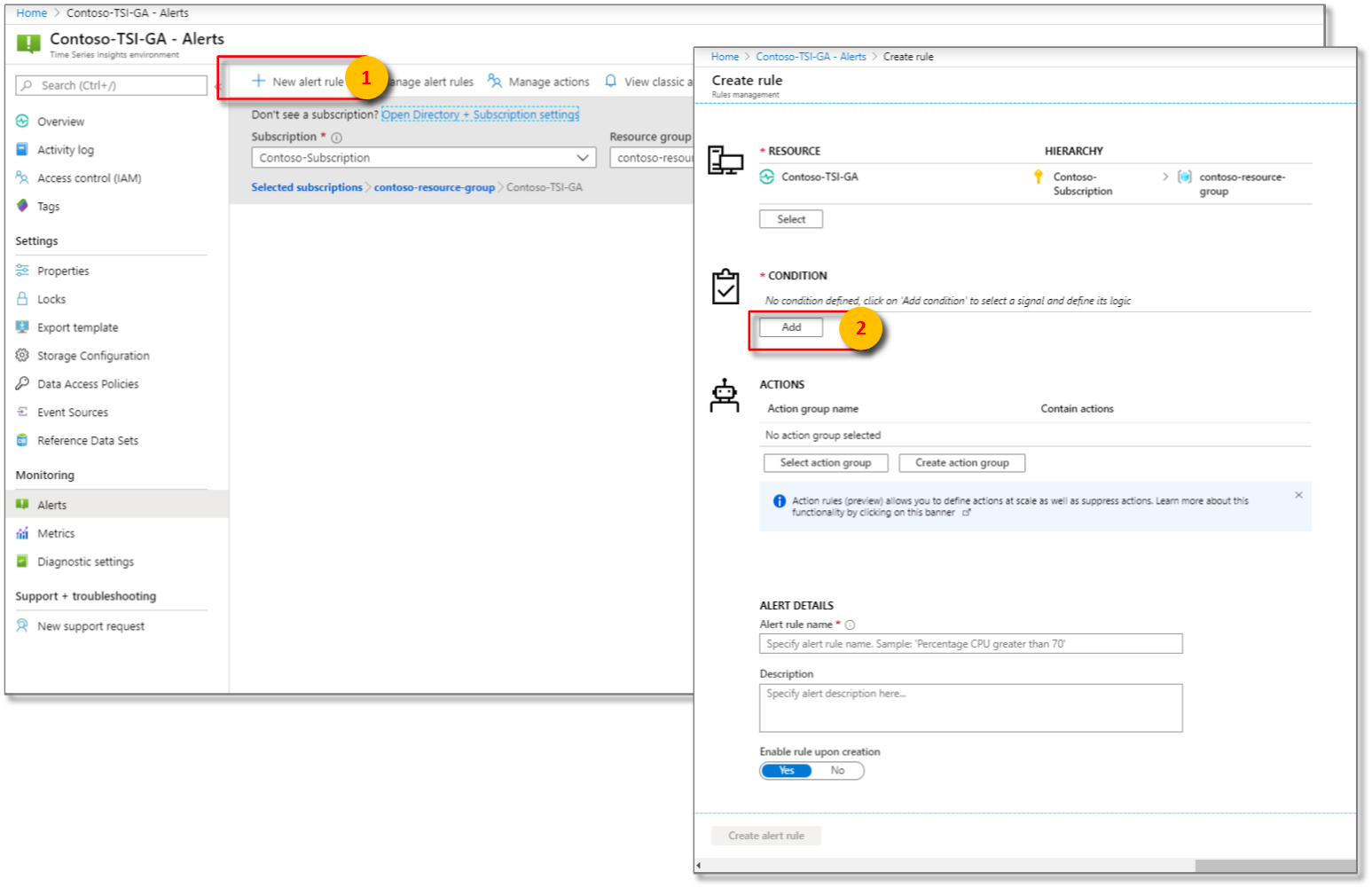
A continuación, configure las condiciones exactas para la lógica de señal.
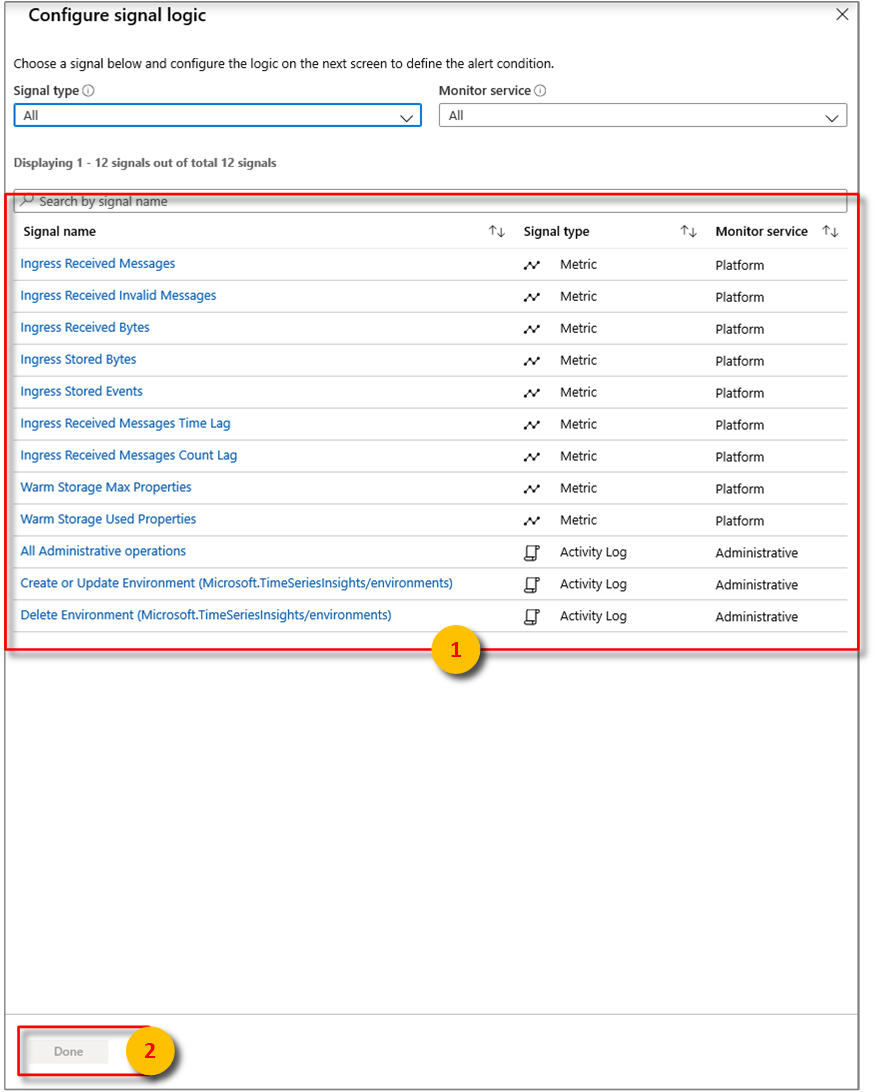
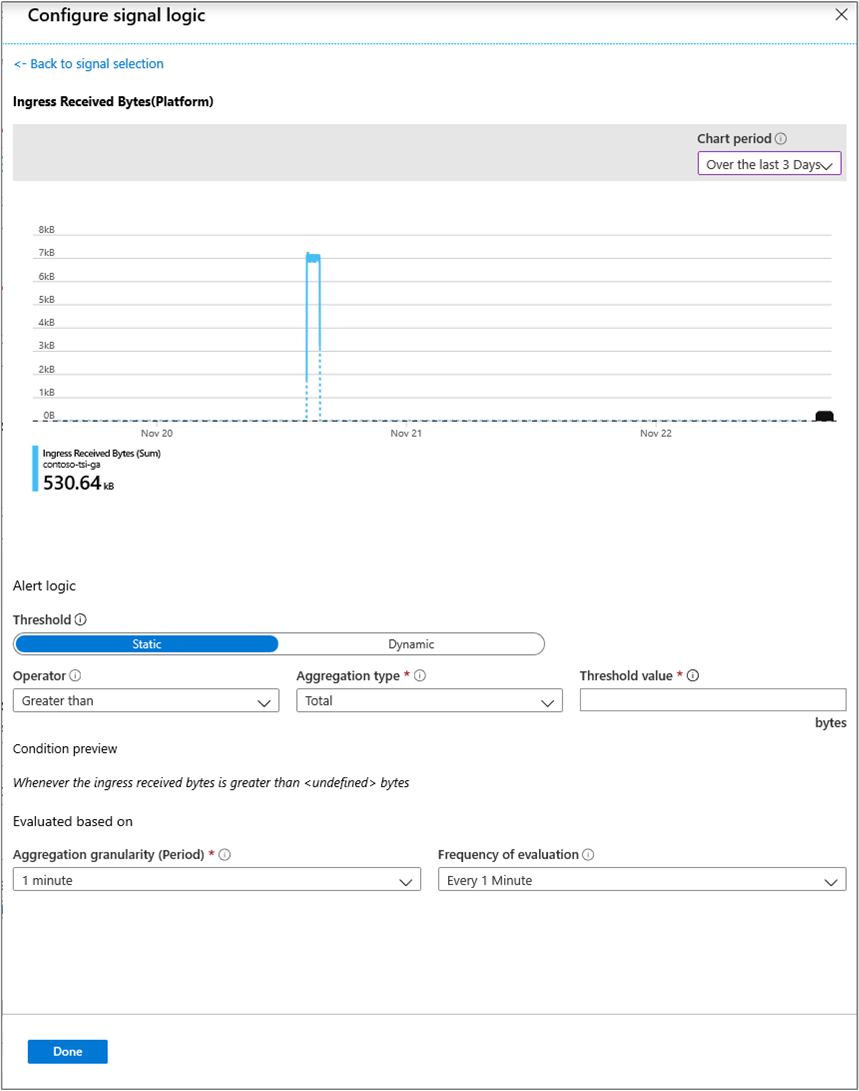
Desde allí, puede configurar alertas con algunas de las condiciones siguientes:
Métrico Descripción Bytes recibidos de entrada Recuento de bytes en bruto leídos de orígenes de eventos. El recuento bruto normalmente incluye el nombre y el valor de la propiedad. Ingreso recibido mensajes no válidos Recuento de mensajes no válidos leídos de todos los orígenes de eventos de Azure Event Hubs o Azure IoT Hub. Ingreso de mensajes recibidos Recuento de mensajes leídos de todos los orígenes de eventos de Event Hubs o IoT Hubs. Bytes de Entrada Almacenados Tamaño total de los eventos almacenados y disponibles para la consulta. El tamaño se calcula únicamente basándose en el valor de la propiedad. Eventos de ingreso almacenados Recuento de eventos planos almacenados y disponibles para consulta. Latencia de Tiempo de Recepción de Mensajes de Ingreso Diferencia en segundos entre el tiempo en que el mensaje está en cola en el origen del evento y la hora en que se procesa en entrada. retraso en el recuento de mensajes de ingreso recibidos Diferencia entre el número de secuencia del último mensaje en cola en la partición de origen de eventos y el número de secuencia del mensaje que se está procesando en Ingreso. Seleccione Listo.
Después de configurar la lógica de señal deseada, revise visualmente la regla de alerta elegida.




Administración de limitación de velocidad y entrada
Si está siendo limitado, se registrará un valor para el intervalo de tiempo de mensajes recibidos que le informará sobre cuántos segundos está su entorno de Azure Time Series Insights detrás de la hora real en que el mensaje llega al origen del evento (excluyendo el tiempo de indexación que es aproximadamente de 30 a 60 segundos).
El retraso en el conteo de mensajes ingresados debería tener también un valor, lo que te permite determinar cuántos mensajes estás atrasado. La manera más fácil de ponerse al día es aumentar la capacidad de su entorno a un tamaño que le permita superar la diferencia.
Por ejemplo, si el entorno S1 muestra un retraso de 5 000 000 mensajes, puede aumentar el tamaño de su entorno a seis unidades durante aproximadamente un día para ponerse al día. Podría aumentar aún más para ponerse al día más rápidamente. El período de puesta al día es una aparición común al aprovisionar inicialmente un entorno, especialmente cuando se conecta a un origen de eventos que ya tiene eventos en él o cuando se cargan masivamente muchos datos históricos.
Otra técnica consiste en establecer un eventos almacenados de entrada alerta >= un umbral ligeramente por debajo de la capacidad total del entorno durante un período de 2 horas. Esta alerta puede ayudarle a comprender si está constantemente al máximo de capacidad, lo que indica una alta probabilidad de retraso.
Por ejemplo, si tiene tres unidades S1 aprovisionadas (o 2100 eventos por capacidad de entrada por minuto), puede establecer una alerta de eventos almacenados de entrada de para >= 1900 eventos durante 2 horas. Si está superando constantemente este umbral y, por lo tanto, desencadenando la alerta, es probable que esté infraaprovisionado.
Si sospecha que está siendo estrangulado, puede comparar los mensajes recibidos de entrada con los mensajes egresados de su fuente de eventos. Si la entrada en tu Event Hub es mayor que tus Mensajes de entrada recibidos, es probable que Azure Time Series Insights esté siendo limitado.
Mejora del rendimiento
Para reducir la limitación o la latencia, la mejor manera de corregir esto es aumentar la capacidad del entorno.
Puede evitar la latencia y la restricción configurando correctamente su entorno para la cantidad de datos que desea analizar. Para obtener más información sobre cómo agregar capacidad a su entorno, lea Escale su entorno.
Pasos siguientes
Obtenga información sobre Diagnosticar y resolver problemas en el entorno de Azure Time Series Insights.
Aprenda sobre cómo escalar su entorno de Azure Time Series Insights.