Uso de Apache Kafka® en HDInsight con Apache Flink® en HDInsight en AKS
Importante
Azure HDInsight en AKS se retiró el 31 de enero de 2025. Descubra más con este anuncio.
Debe migrar las cargas de trabajo a microsoft Fabric o un producto equivalente de Azure para evitar la terminación repentina de las cargas de trabajo.
Importante
Esta característica está actualmente en versión preliminar. Los Términos de uso complementarios para las versiones preliminares de Microsoft Azure incluyen más términos legales que se aplican a las características de Azure que se encuentran en versión beta, en versión preliminar o, de lo contrario, aún no se han publicado en disponibilidad general. Para obtener información sobre esta versión preliminar específica, consulte la información de la versión preliminar de Azure HDInsight en AKS . Para preguntas o sugerencias de características, envíe una solicitud en AskHDInsight con los detalles y siganos para obtener más actualizaciones sobre comunidad de Azure HDInsight.
Un caso de uso conocido para Apache Flink es stream analytics. La opción popular de muchos usuarios para usar los flujos de datos, que se ingieren mediante Apache Kafka. Las instalaciones típicas de Flink y Kafka comienzan con flujos de eventos que se envían a Kafka, que pueden ser consumidos por los trabajos de Flink.
En este ejemplo se usa HDInsight en clústeres de AKS que ejecutan Flink 1.17.0 para procesar datos de streaming que consumen y generan un tema de Kafka.
Nota
FlinkKafkaConsumer está en desuso y se quitará con Flink 1.17, use KafkaSource en su lugar. FlinkKafkaProducer está en desuso y se quitará con Flink 1.15, use KafkaSink en su lugar.
Prerrequisitos
Tanto Kafka como Flink deben estar en la misma red virtual o debe haber emparejamiento de redes virtuales (VNet) entre los dos clústeres.
Crear un clúster de Kafka en la misma red virtual. Puede elegir Kafka 3.2 o 2.4 en HDInsight en función del uso actual.
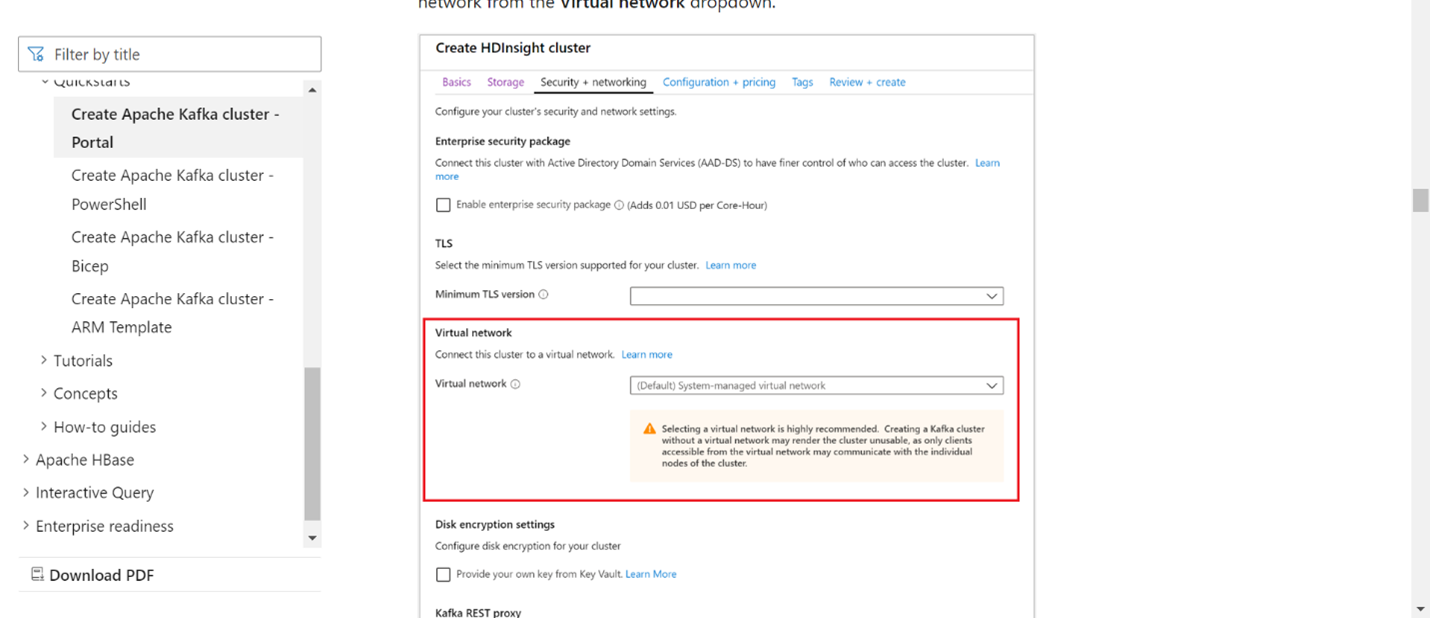
Agregue los detalles de la red virtual en la sección red virtual.
Cree un HDInsight en el grupo de clústeres de AKS utilizando la misma red virtual.
Cree un clúster de Flink en el grupo de clústeres creado.

Conector de Apache Kafka
Flink proporciona un conector de Apache Kafka para leer datos de y escribir datos en tópicos de Kafka con garantías de exactamente una vez.
Dependencia de Maven
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.0</version>
</dependency>
Construcción de Sumidero de Kafka
El sumidero de Kafka proporciona una clase de constructor para crear una instancia de KafkaSink. Usamos el mismo para construir nuestro sink y usarlo con el clúster de Flink que opera en HDInsight sobre AKS.
SinKafkaToKafka.java
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SinKafkaToKafka {
public static void main(String[] args) throws Exception {
// 1. get stream execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. read kafka message as stream input, update your broker IPs below
String brokers = "X.X.X.X:9092,X.X.X.X:9092,X.X.X.X:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("clicks")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3. transformation:
// https://www.taobao.com,1000 --->
// Event{user: "Tim",url: "https://www.taobao.com",timestamp: 1970-01-01 00:00:01.0}
SingleOutputStreamOperator<String> result = stream.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
String[] fields = value.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim())).toString();
}
});
// 4. sink click into another kafka events topic
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers(brokers)
.setProperty("transaction.timeout.ms","900000")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("events")
.setValueSerializationSchema(new SimpleStringSchema())
.build())
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.build();
result.sinkTo(sink);
// 5. execute the stream
env.execute("kafka Sink to other topic");
}
}
Escribir un programa de Java Event.java
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
public Event() {
}
public Event(String user,String url,Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString(){
return "Event{" +
"user: \"" + user + "\"" +
",url: \"" + url + "\"" +
",timestamp: " + new Timestamp(timestamp) +
"}";
}
}
Empaquetar el archivo jar y enviar el trabajo a Flink
En Webssh, cargue el archivo jar y envíe el archivo jar.

En la interfaz de usuario del panel de Flink

Generar el tema: clics en Kafka

Consumir el tópico: eventos en Kafka

Referencia
- Conector de Apache Kafka
- Apache, Apache Kafka, Kafka, Apache Flink, Flink y los proyectos de código abierto asociados son marcas comerciales de la Apache Software Foundation (ASF).