Preparar los conjuntos de datos públicos en Conjuntos de datos SDOH: transformaciones (versión preliminar)
[Este artículo es documentación preliminar y está sujeto a modificaciones].
Los conjuntos de datos públicos de SDOH contienen datos agregados de determinantes sociales de salud (SDOH, por sus siglas en inglés) publicados por agencias gubernamentales y otras fuentes oficiales, como universidades. Estos conjuntos de datos consolidan varios parámetros SDOH en los niveles geográficos, como el estado, el condado o el código postal. Conjuntos de datos SDOH: transformaciones (versión preliminar) le permite ingerir estos conjuntos de datos de nivel geográfico en formato CSV (valores separados por comas) o XLSX (hoja de cálculo Open XML de Excel) y normalizarlos en un modelo de datos personalizado.
La versión preliminar proporciona los siguientes ocho conjuntos de datos SDOH de ejemplo de varios dominios SDOH para ayudarle a ejecutar canalizaciones de datos y explorar las transformaciones de datos a través de las capas de almacén de lago bronce, plata y oro:
Atlas del entorno alimentario del USDA: incluye factores como la proximidad de la tienda/restaurante, los precios de los alimentos, los programas de asistencia nutricional y las características de la comunidad. Estos factores afectan la elección de alimentos, la calidad de la dieta y, en última instancia, los resultados de salud.
Atlas rural del USDA: ofrece estadísticas sobre factores socioeconómicos, como personas, empleos, clasificaciones de condados, ingresos y veteranos.
Datos sobre SDOH de la AHRQ: proporciona detalles sobre cinco dominios clave de SDOH:
- Contexto social, como edad, raza/etnia, condición de veterano.
- Contexto económico, como ingresos, tasa de desempleo.
- Educación
- Infraestructura física, como viviendas, delincuencia, transporte.
- Contexto sanitario, como seguro médico.
Índice de asequibilidad por localización: estima los costes de vivienda y transporte de los hogares en el nivel de vecindario.
Índice de Justicia Medioambiental: agrega datos de varios orígenes para clasificar los impactos acumulativos de la injusticia medioambiental en la salud para cada área de censo.
Nivel de estudios ACS: proporciona información educativa para áreas geográficas, derivada de una gran encuesta demográfica en curso.
SEIFA australiana: combina los datos del censo australiano, como los ingresos, la educación, el empleo y la vivienda, para resumir las características socioeconómicas de un área.
Índices de privación del Reino Unido: una medida socioeconómica ampliamente utilizada en el Reino Unido para evaluar la pobreza en áreas pequeñas, abarcando varias dimensiones.
Donde:
- USDA: Departamento de Agricultura de Estados Unidos
- AHRQ: Agencia de Investigación y Calidad Sanitarias
- ACS: Encuesta sobre la Comunidad Estadounidense
- SEIFA: Índices Socioeconómicos por Áreas
Importante
Estos conjuntos de datos no son solo muestras, sino conjuntos de datos completos y reales publicados por las respectivas organizaciones. Proporcionan una representación precisa de los perfiles SDOH de sus áreas geográficas. Tenga cuidado al modificarlos, ya que son publicaciones oficiales de agencias federales.
Estructura de carpetas
La zona de aterrizaje de Conjuntos de datos SDOH: transformaciones (versión preliminar) consta de tres carpetas: Ingesta Proceso y Con error. Para obtener más información sobre estas carpetas, consulte Estructura de carpetas unificada.
Preparar los conjuntos de datos de SDOH antes de la ingesta
Antes de ingerir conjuntos de datos públicos SDOH, asegúrese de que estén listos para una ingesta correcta. En las siguientes secciones se describen dos escenarios:
- Usar su propio conjunto de datos
- Usar el conjunto de datos de ejemplo
Usar su propio conjunto de datos
Los conjuntos de datos públicos de SDOH varían significativamente entre las organizaciones editoriales en cuanto a formato, volumen y estructura. Carecen de un estándar establecido para recopilar e intercambiar la información capturada. Por lo tanto, unificarlos en una forma común es esencial antes de representarlos dentro de un modelo de datos.
Para ingerir y transformar un conjunto de datos público de SDOH de su elección, agrégueles los siguientes tres datos clave:
Diseño: debido a la ausencia de un conjunto estándar de códigos para capturar datos SDOH, comprender el significado de cada campo resulta un desafío. Para resolver este problema, cree un diccionario de datos para el conjunto de datos agregando una nueva hoja denominada Diseño (si el conjunto de datos está en formato XLSX) o cree un nuevo archivo CSV (si el conjunto de datos está en formato CSV) con las columnas que se muestran en el siguiente ejemplo:
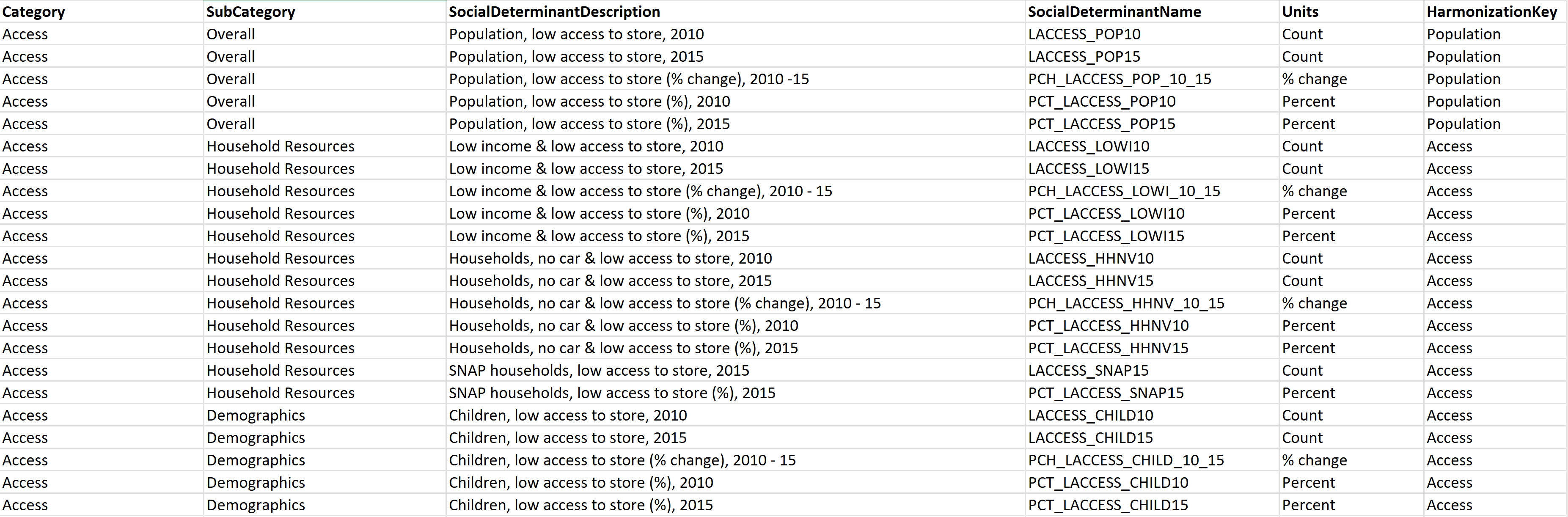
DataSetMetadata: dado que los conjuntos de datos de SDOH provienen de diferentes editores, es crucial registrar detalles clave sobre el conjunto de datos. Agregue una nueva hoja denominada DataSetMetadata (si el conjunto de datos está en formato XLSX) o cree un nuevo archivo CSV (si el conjunto de datos está en formato CSV) con las columnas que se muestran en el siguiente ejemplo:

LocationConfiguration: las diferentes zonas geográficas definen y organizan los datos de ubicación de diversas maneras. Para ayudar a las canalizaciones de SDOH a comprender la estructura geográfica del conjunto de datos, agregue una nueva hoja denominada LocationConfiguration (si el conjunto de datos está en formato XLSX) o cree un nuevo archivo CSV (si el conjunto de datos está en formato CSV) con las columnas que se muestran en el siguiente ejemplo:
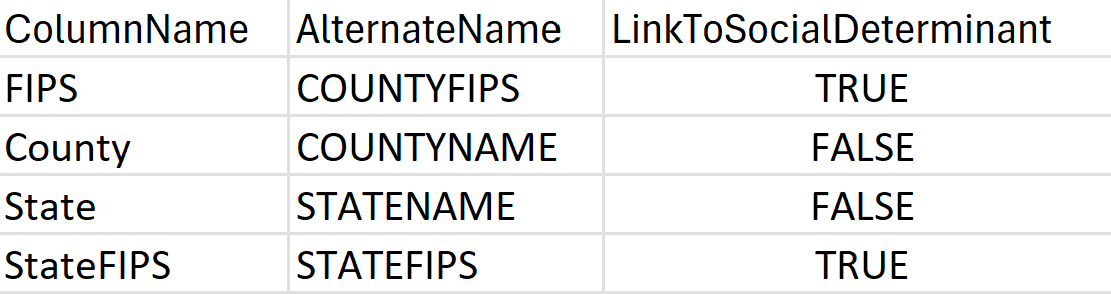



Además:
- Puede consultar la estructura de los conjuntos de datos SDOH de ejemplo para completar la información necesaria, como la categoría de determinante social, los metadatos y la clave de armonización.
- Si prefiere no ingerir determinados campos del conjunto de datos original, elimínelos de la hoja de datos o deje sus detalles en blanco en la hoja de diseño. En ambos casos, no se incluyen en el modelo de datos de plata.
- Los conjuntos de datos con el mismo nombre, fecha de publicación y editor se tratan como duplicados.
Usar el conjunto de datos de ejemplo
Los conjuntos de datos SDOH de ejemplo proporcionados con las soluciones de datos de atención sanitaria vienen rellenados previamente con toda la información de requisitos previos y están disponibles en su OneLake. Puede extraerlos localmente.
Cargar conjuntos de datos en el área de trabajo de Fabric
Una vez que los conjuntos de datos estén listos, elija una de las dos opciones siguientes para cargarlos. Solo puede usar la opción 2 si usa el conjunto de datos de ejemplo proporcionado con Conjuntos de datos SDOH: transformaciones (versión preliminar).
- Opción 1: Cargue manualmente los conjuntos de datos.
- Opción 2: Utilice un script para cargar los conjuntos de datos.
Cargar manualmente los conjuntos de datos
En su entorno de soluciones de datos de atención sanitaria, seleccione el almacén de lago healthcare#_msft_bronze.
Abra la carpeta Ingerir. Para obtener más información, consulte Descripciones de carpetas.
Seleccione los puntos suspensivos (...) junto al nombre de la carpeta y Cargar carpeta.
Cargue los conjuntos de datos desde su sistema local. Use el explorador de archivos de OneLake para buscar los conjuntos de datos en la siguiente ruta:
<workspace name>\healthcare#.HealthDataManager\DMHSampleData\8SdohPublicDatasetActualice la carpeta Ingerir. Ahora debería ver los archivos del conjunto de datos dentro de la subcarpeta SDOH.
Usar un script para cargar los conjuntos de datos
Importante
Use esta opción solo si usa el conjunto de datos de ejemplo proporcionado.
Vaya al área de trabajo de Fabric de sus soluciones de datos de atención médica.
Seleccione + Nuevo elemento.
En el panel Nuevo elemento, busque y seleccione Bloc de notas.
Copie el fragmento de código siguiente en el bloc de notas.
workspace_name = '<workspace_name>' # workspace name one_lake_endpoint = "<OneLake_endpoint>" # OneLake endpoint solution_name = "<solution_name>" # solution name bronze_lakehouse_name = "<bronze_lakehouse_name>" # bronze lakehouse name def copy_source_files_and_folders(source_path, destination_path): source_contents = mssparkutils.fs.ls(source_path) # list the source directory contents # list the destination directory contents try: if mssparkutils.fs.exists(destination_path): destination_contents = mssparkutils.fs.ls(destination_path) destination_files = {item.path.split('/')[-1]: item.path for item in destination_contents} else: print(f"Destination path {destination_path} does not exist.") destination_files = {} except Exception as e: print(f" Error: {str(e)}") destination_files = {} # copy each item inside the source directory to the destination directory for item in source_contents: item_path = item.path item_name = item_path.split('/')[-1] destination_item_path = f"{destination_path}/{item_name}" # recursively copy the contents of the directory if item.isDir: copy_source_files_and_folders(item_path, destination_item_path) else: if item_name in destination_files: print(f"File already exists, skipping: {destination_item_path}") else: print(f"Creating new file: {destination_item_path}") mssparkutils.fs.cp(item_path, destination_item_path, recurse=True) # define the source and destination paths with placeholder values data_manager_solution_path = f"abfss://{workspace_name}@{one_lake_endpoint}/{solution_name}" data_manager_sample_data_path = f"{data_manager_solution_path}/DMHSampleData" sdoh_csv_data_path = f"{data_manager_sample_data_path}/8SdohPublicDataset/csv" sdoh_xlsx_data_path = f"{data_manager_sample_data_path}/8SdohPublicDataset/xlsx" destination_path_csv = f"abfss://{workspace_name}@{one_lake_endpoint}/{bronze_lakehouse_name}.Lakehouse/Files/Ingest/SDOH/CSV" destination_path_xlsx = f"abfss://{workspace_name}@{one_lake_endpoint}/{bronze_lakehouse_name}.Lakehouse/Files/Ingest/SDOH/XLSX" # copy the files along with their parent folders copy_source_files_and_folders(sdoh_csv_data_path, destination_path_csv) copy_source_files_and_folders(sdoh_xlsx_data_path, destination_path_xlsx)Ejecute el bloc de notas. Los conjuntos de datos SDOH de ejemplo ahora se mueven a la ubicación designada dentro de la carpeta Ingerir.
Los conjuntos de datos de SDOH ya están listos para la ingesta.