Incorporación de Amazon Managed Streaming para Apache Kafka (MSK) como origen en el Centro en tiempo real
En este artículo se describe cómo agregar Amazon Streaming para Apache Kafka (MSK) como origen del evento en el centro en tiempo real de Fabric.
Amazon MSK Kafka es un servicio Kafka totalmente administrado que simplifica la configuración, el escalado y la administración. Al integrar Amazon MSK Kafka como origen dentro del flujo de eventos, puede traer sin problemas los eventos en tiempo real de su MSK Kafka y procesarlos antes de enrutarlos a varios destinos dentro de Fabric.
Requisitos previos
- Accede a un área de trabajo en el modo de licencia de capacidad de Fabric (o) el modo de licencia de prueba con los permisos Colaborador o superior.
- Un clúster de Amazon MSK Kafka en estado activo.
- El clúster de Amazon MSK Kafka debe ser accesible públicamente y no estar detrás de un firewall o protegido en una red virtual.
Página Orígenes de datos
Inicie sesión en Microsoft Fabric.
Si ve Power BI en la parte inferior izquierda de la página, cambie a la carga de trabajo Fabric seleccionando Power BI y luego seleccionando Fabric.

Selecciona Tiempo real en la barra de navegación de la izquierda.

En la página Centro en tiempo real, selecciona + Orígenes de datos en Conectar a en el menú de navegación izquierdo.
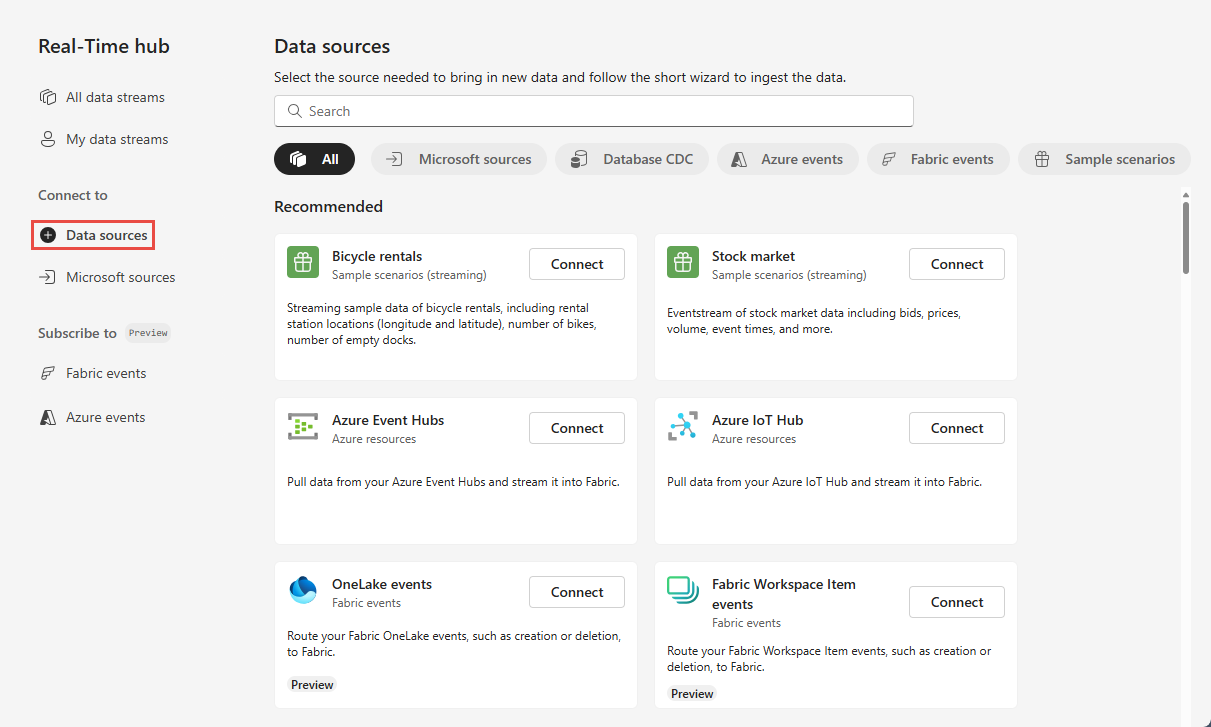
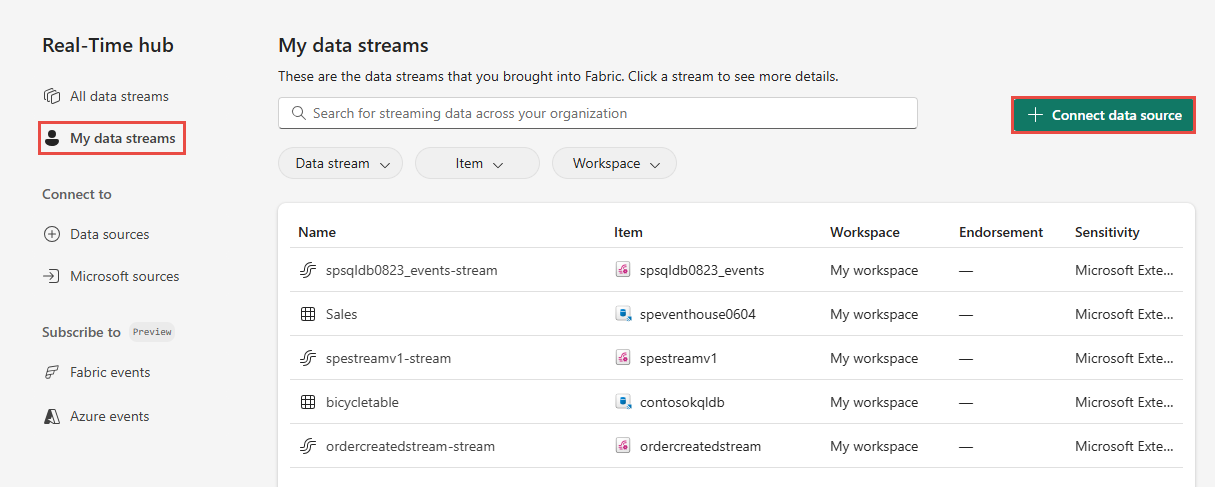
También puedes acceder a la página Orígenes de datos desde las páginas Todos los flujos de datos o Mis flujos de datos seleccionando el botón + Conectar origen de datos de la esquina superior derecha.
Incorporación de Amazon Managed Streaming para Apache Kafka como origen
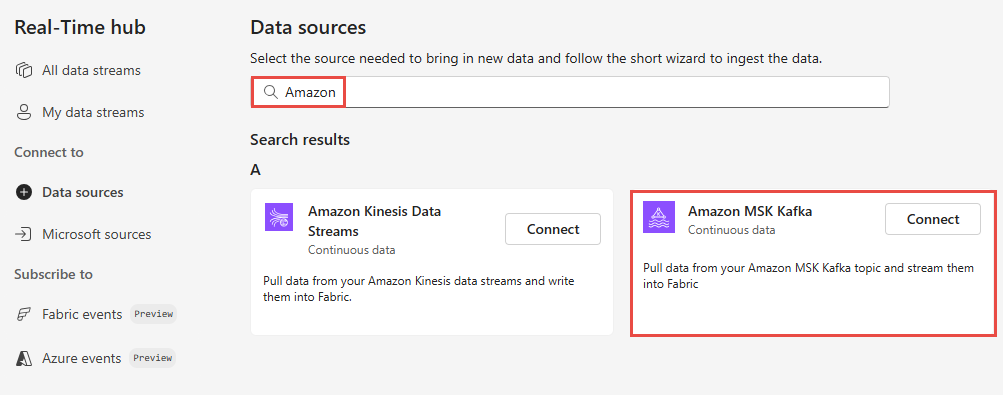
En la página Orígenes de datos, selecciona Amazon MSK Kafka.
En la página Conectar, seleccione Nueva conexión.
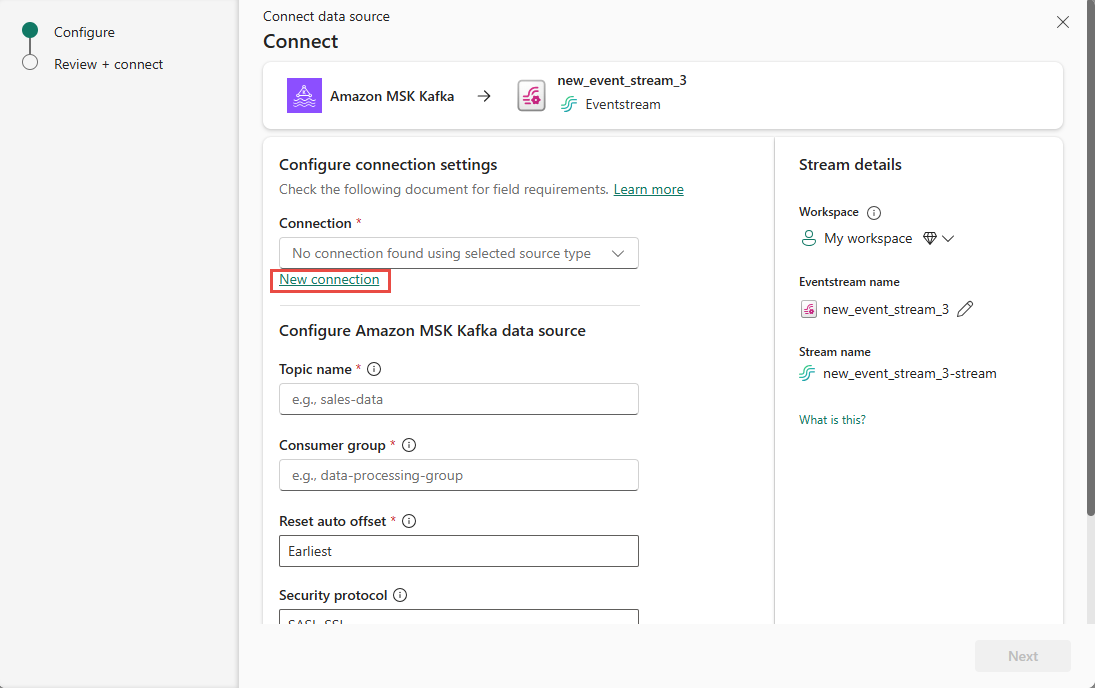
En la sección Configuración de conexión, en Arranque de servidor, escribe el punto de conexión público del clúster de Kafka.
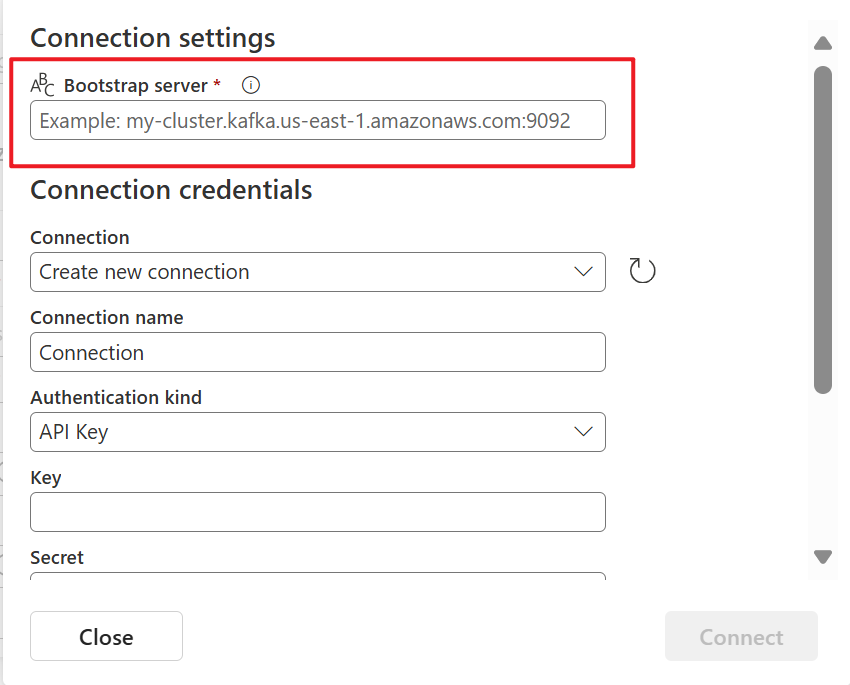
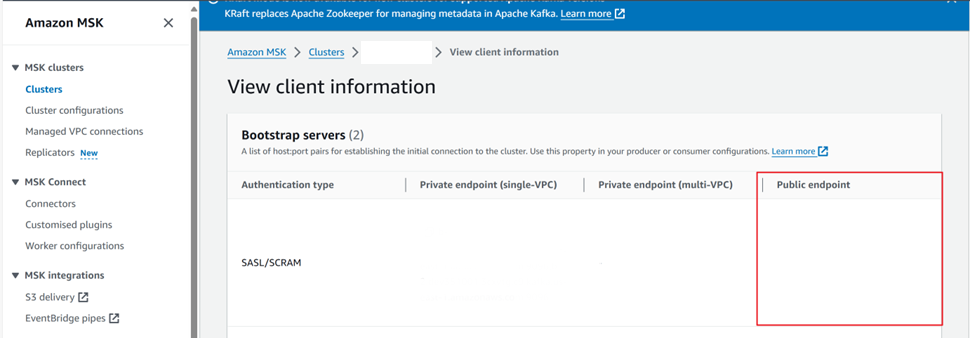
Para obtener el punto de conexión público:
En la sección Credenciales de conexión, si tienes una conexión existente al clúster de Amazon MSK Kafka, selecciónala en la lista desplegable de Conexión. De lo contrario, siga estos pasos:
- Para Nombre de conexión, introduzca un nombre para la conexión.
- En Tipo de autenticación, confirma que está seleccionada la clave de API.
- En Clave y secreto, escribe la clave de API y el secreto de clave para el clúster de Kafka de Amazon MSK.
Seleccione Conectar.
Ahora, en la página Conectar, sigue estos pasos.
En Tema, escribe el tema de Kafka.
En Grupo de consumidores, escribe el grupo de consumidores del clúster de Kafka. Este campo proporciona un grupo de consumidores dedicado para obtener eventos.
Selecciona Restablecer desplazamiento automático para especificar dónde empezar a leer desplazamientos si no hay ninguna confirmación.
En Protocolo de seguridad, el valor predeterminado es SASL_SSL. El mecanismo SASL predeterminado es SCRAM-SHA-512 y no se puede cambiar.
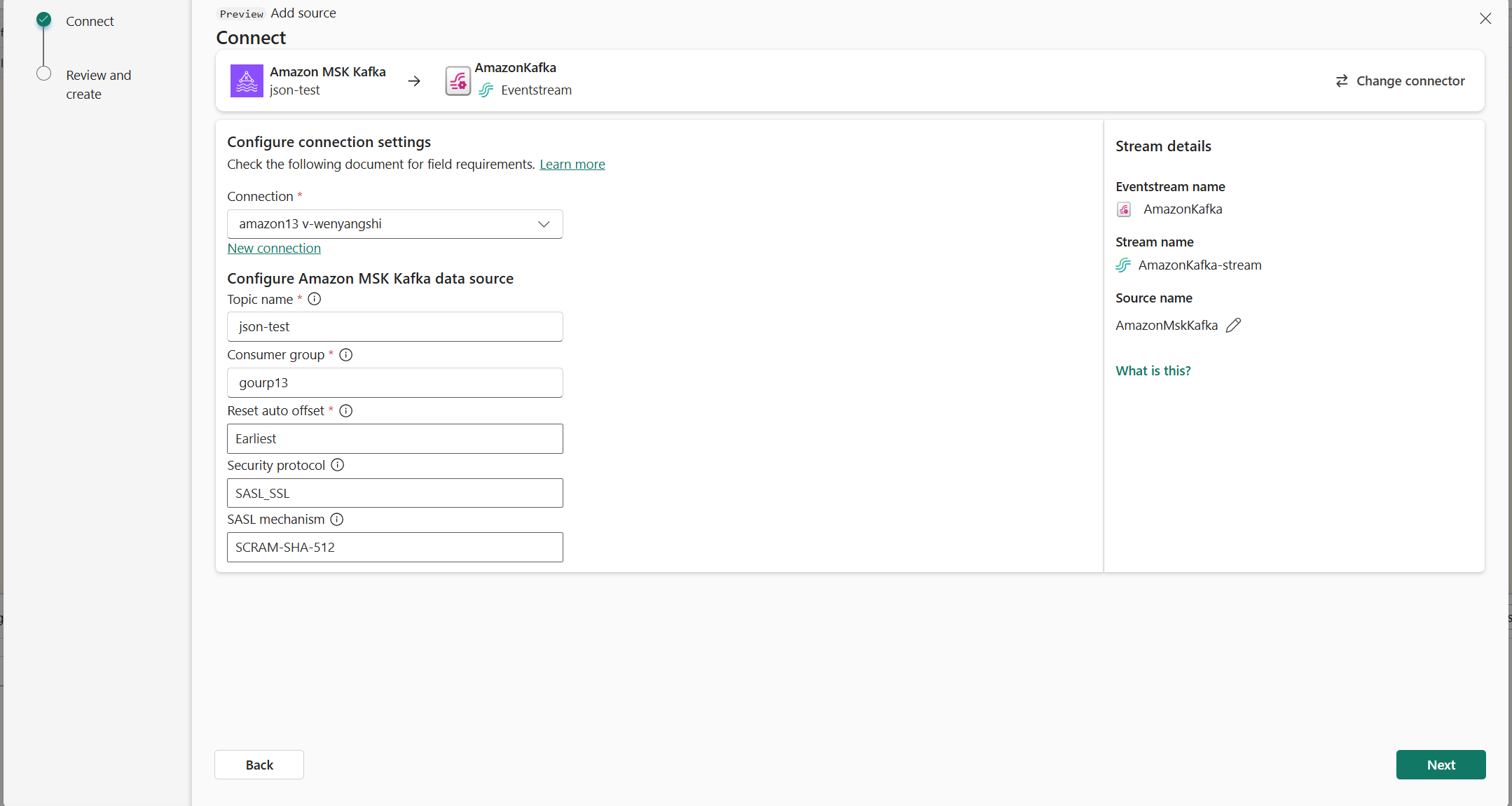
Seleccione Siguiente. En la pantalla Revisar y conectar, revisa el resumen y, después, selecciona Conectar.

Visualización de los detalles del flujo de datos
En la página Revisar y conectar, si seleccionas Abrir flujo de eventos, el asistente abre el flujo de eventos que creaste automáticamente con el origen de Amazon Managed Streaming para Apache Kafka seleccionado. Para cerrar el asistente, seleccione Cerrar en la parte inferior de la página.
En el centro en tiempo real, cambie a la pestaña Flujos de datos del centro en tiempo real. Actualice la página. Debería ver la secuencia de datos creada automáticamente.
Para obtener pasos detallados, consulte Visualización de los detalles de los flujos de datos en el centro en tiempo real de Fabric.
Contenido relacionado
Para obtener información sobre cómo consumir flujos de datos, vea los artículos siguientes: