Tutorial: Exploración y análisis de lagos de datos con un grupo de SQL sin servidor
En este tutorial, obtendrá información sobre cómo realizar análisis exploratorios de datos mediante conjuntos de datos abiertos existentes, sin que se requiera ninguna configuración de almacenamiento. Combinará diferentes instancias de Azure Open Datasets mediante un grupo de SQL sin servidor. A continuación, visualizará los resultados en Synapse Studio de Azure Synapse Analytics.
En este tutorial ha:
- Acceder al grupo de SQL sin servidor integrado
- Acceder a Azure Open Datasets para usar datos del tutorial
- Realizar análisis de datos básicos mediante SQL
Acceder al grupo de SQL sin servidor
Todas las áreas de trabajo incluyen un grupo de SQL sin servidor preconfigurado llamado Built-in para su uso. Para acceder a él:
- Abra el área de trabajo y seleccione el centro de desarrollo.
- Seleccione el botón + Agregar nuevo recurso.
- Seleccione el script SQL.
Puede usar este script para explorar los datos sin tener que reservar capacidad de SQL.
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Acceder a los datos del tutorial
Todos los datos que se usan en este tutorial se hospedan en la cuenta de almacenamiento azureopendatastorage, que contiene Azure Open Datasets para su uso abierto en tutoriales como este. Puede ejecutar todos los scripts tal cual directamente desde el área de trabajo siempre que el área de trabajo pueda acceder a una red pública.
En este tutorial se usa un conjunto de datos sobre New York City (NYC) Taxi:
- Fechas y horas de recogida y llegada a destino
- Ubicaciones de recogida y llegada a destino
- Distancias de la carrera
- Tarifas desglosadas
- Tipos de tarifa
- Formas de pago
- Recuentos de pasajeros indicados por el conductor
La función OPENROWSET(BULK...) permite acceder a archivos en Azure Storage. [OPENROWSET](develop-openrowset.md) lee el contenido de un origen de datos remoto, como archivo, y devuelve el contenido como un conjunto de filas.
Para familiarizarse con los datos de NYC Taxi, ejecute la siguiente consulta:
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
Otros conjuntos de datos accesibles
Del mismo modo, puede consultar el conjunto de datos de los días festivos locales y nacionales mediante la siguiente consulta:
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
También puede consultar el conjunto de datos meteorológicos mediante la siguiente consulta:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
Puede ver más detalles sobre el significado de cada una de las columnas individuales de las descripciones de los siguientes conjuntos de datos:
Inferencia automática del esquema
Puesto que los datos se almacenan en el formato de archivo Parquet, está disponible la inferencia de esquemas automática. Puede consultar los datos sin enumerar los tipos de datos de todas las columnas de los archivos. También puede usar el mecanismo de columna virtual y la función filepath para filtrar un determinado subconjunto de archivos.
Nota
La intercalación predeterminada es SQL_Latin1_General_CP1_CI_ASIf. Para una intercalación no predeterminada, tenga en cuenta la distinción entre mayúsculas y minúsculas.
Si crea una base de datos con intercalación que distingue mayúsculas de minúsculas, al especificar columnas, asegúrese de usar el nombre correcto de la columna.
El nombre de columna tpepPickupDateTime sería correcto, mientras que tpeppickupdatetime no funcionaría en una intercalación no predeterminada.
Análisis de series temporales, estacionalidad y valores atípicos
Puede resumir el número anual de carreras de taxi con la siguiente consulta:
SELECT
YEAR(tpepPickupDateTime) AS current_year,
COUNT(*) AS rides_per_year
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) >= '2009' AND nyc.filepath(1) <= '2019'
GROUP BY YEAR(tpepPickupDateTime)
ORDER BY 1 ASC
El fragmento a continuación muestra el resultado para el número anual de carreras de taxi:
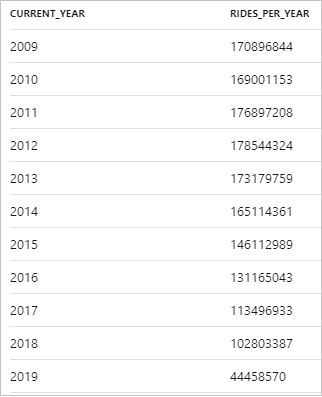
Los datos se pueden visualizar en Synapse Studio realizando un cambio de la vista de Tabla a la de Gráfico. Puede elegir entre diferentes tipos de gráficos: de área, de barras, de columnas, de líneas, circular y de dispersión. En este caso, vamos a trazar el gráfico de columnas con la columna de Categoría establecida en current_year:
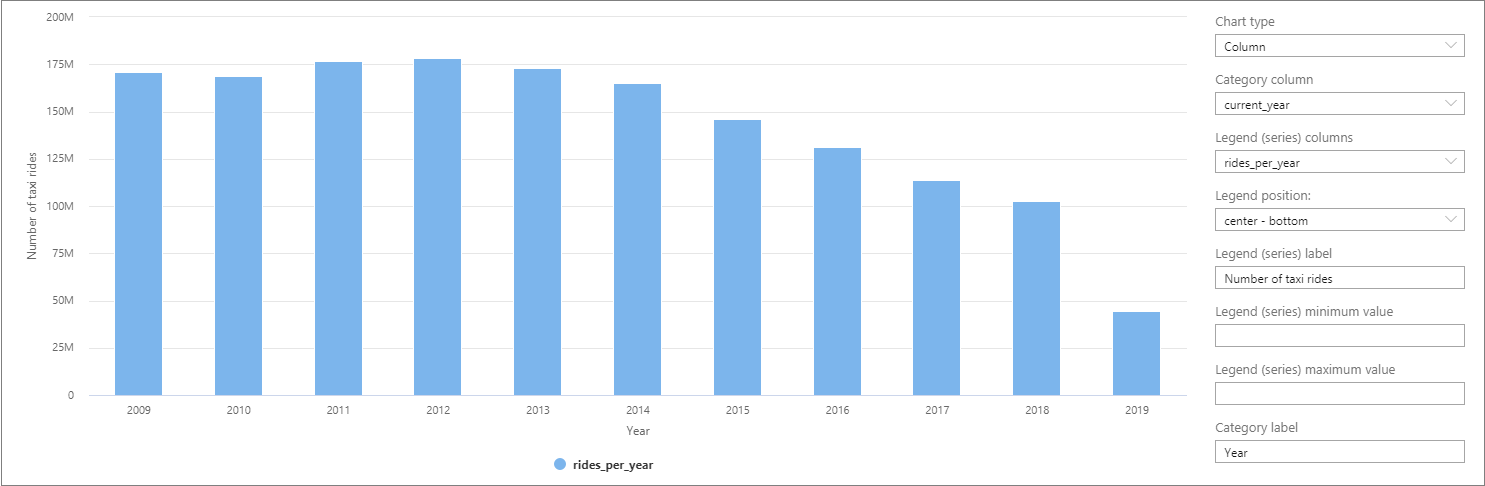
En esta visualización, puede ver una tendencia descendente en el número de carreras con el paso de los años. Posiblemente, esta disminución se debe al aumento de la popularidad de las empresas de uso compartido de vehículos.
Nota
En el momento de escribir este tutorial, los datos de 2019 están incompletos. Como resultado, hay una gran caída en el número de carreras de ese año.
Puede centrar el análisis en un solo año, por ejemplo, 2016. La siguiente consulta devuelve el número diario de carreras durante ese año:
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
ORDER BY 1 ASC
El fragmento siguiente muestra el resultado de esta consulta:
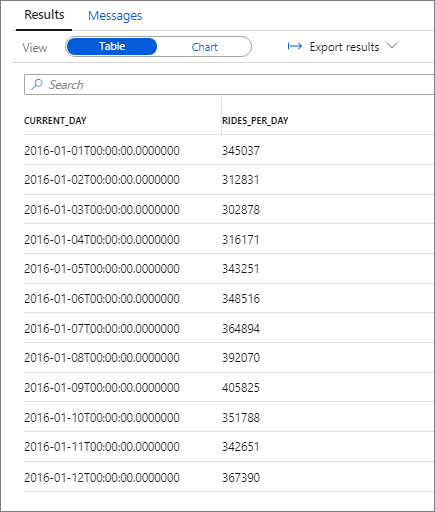
De nuevo, puede visualizar los datos trazando el gráfico Columna con la columna Categoría establecida en current_day y la columna de Leyenda (series) establecida en rides_per_day.
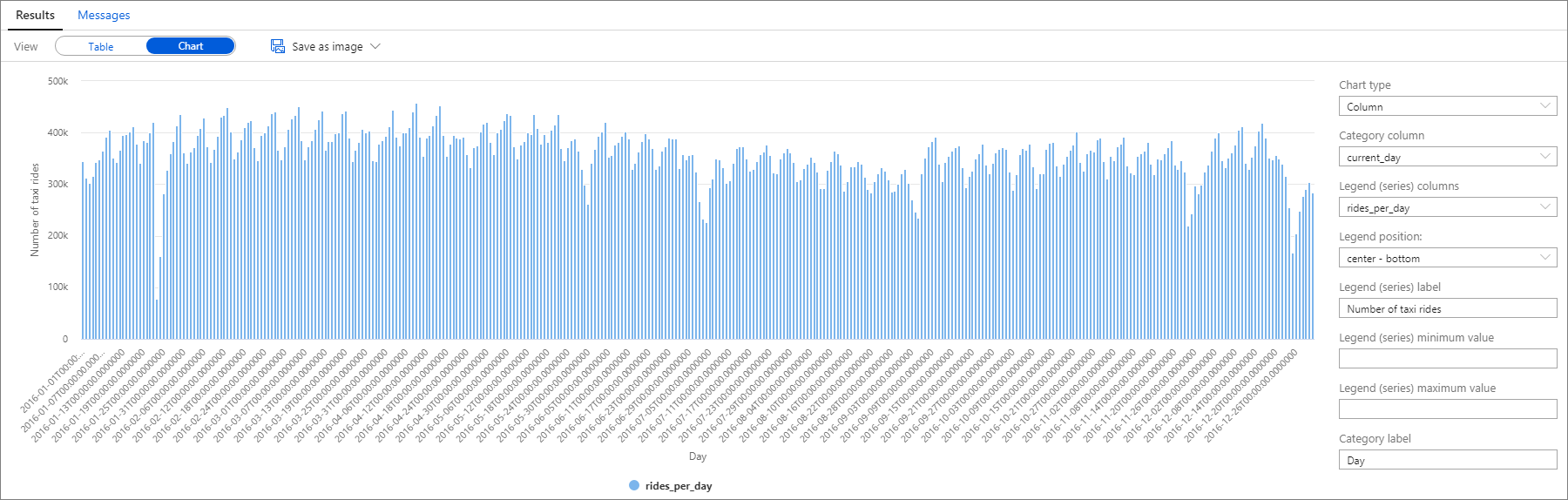
En el gráfico trazado, puede ver que hay un patrón semanal, con los sábados como día de máxima actividad. Durante los meses de verano, hay menos carreras de taxi debido al período de vacaciones. Observe igualmente que hay algunas reducciones significativas en el número de carreras de taxi sin un patrón claro de cuándo y por qué se producen.
A continuación, mire si este descenso de las carreras está relacionado con las días festivos. Compruebe si hay alguna correlación mediante la combinación del conjunto de datos de las carreras, NYC Taxi, con el conjunto de datos Public Holidays:
WITH taxi_rides AS (
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
),
public_holidays AS (
SELECT
holidayname as holiday,
date
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
WHERE countryorregion = 'United States' AND YEAR(date) = 2016
),
joined_data AS (
SELECT
*
FROM taxi_rides t
LEFT OUTER JOIN public_holidays p on t.current_day = p.date
)
SELECT
*,
holiday_rides =
CASE
WHEN holiday is null THEN 0
WHEN holiday is not null THEN rides_per_day
END
FROM joined_data
ORDER BY current_day ASC
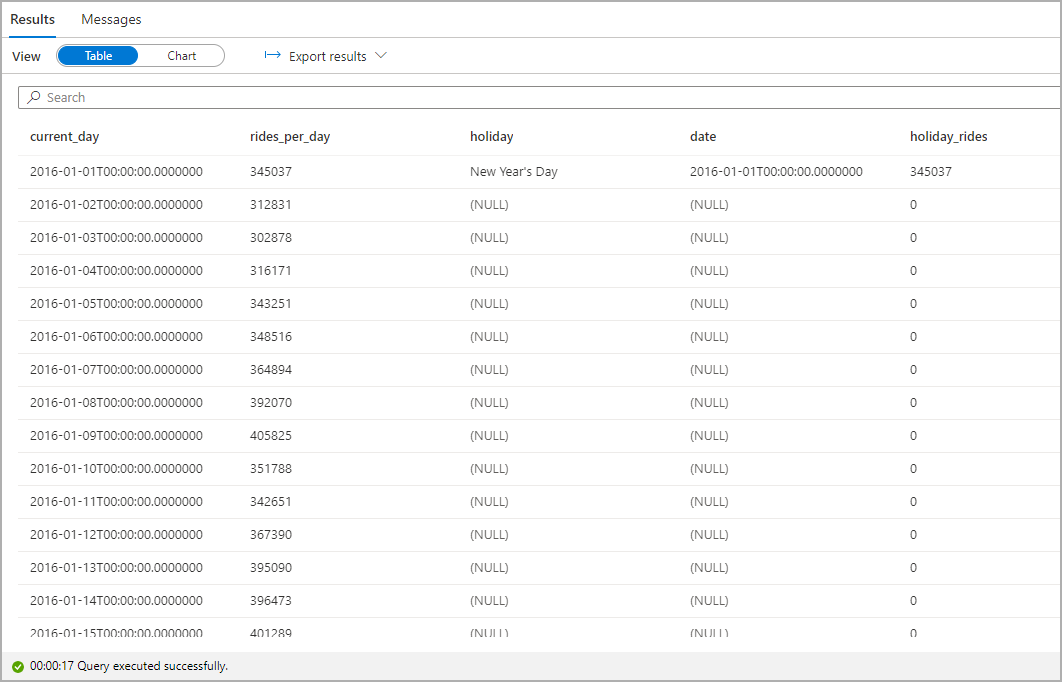
Resalte el número de carreras de taxi durante las fiestas oficiales. Para ello, elija current_day en la columna Categoría, y rides_per_day y holiday_rides como las columnas Leyenda (series).
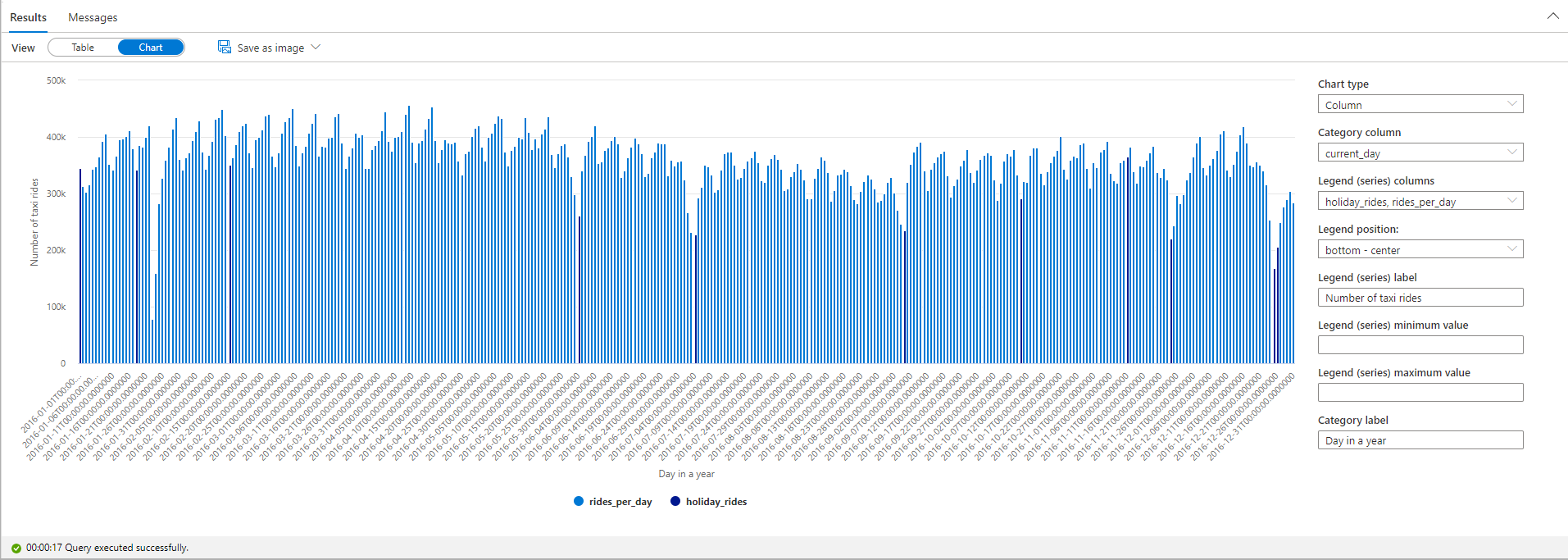
En el gráfico trazado, puede ver que durante los días festivos locales y nacionales, el número de carreras de taxi es inferior. Todavía hay una gran reducción no explicada el 23 de enero. Vamos a comprobar el tiempo en Nueva York en ese día consultando el conjunto de datos meteorológicos:
SELECT
AVG(windspeed) AS avg_windspeed,
MIN(windspeed) AS min_windspeed,
MAX(windspeed) AS max_windspeed,
AVG(temperature) AS avg_temperature,
MIN(temperature) AS min_temperature,
MAX(temperature) AS max_temperature,
AVG(sealvlpressure) AS avg_sealvlpressure,
MIN(sealvlpressure) AS min_sealvlpressure,
MAX(sealvlpressure) AS max_sealvlpressure,
AVG(precipdepth) AS avg_precipdepth,
MIN(precipdepth) AS min_precipdepth,
MAX(precipdepth) AS max_precipdepth,
AVG(snowdepth) AS avg_snowdepth,
MIN(snowdepth) AS min_snowdepth,
MAX(snowdepth) AS max_snowdepth
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
WHERE countryorregion = 'US' AND CAST([datetime] AS DATE) = '2016-01-23' AND stationname = 'JOHN F KENNEDY INTERNATIONAL AIRPORT'

Los resultados de la consulta indican que la reducción del número de viajes de taxi se debió a:
- Una tormenta de nieve ese día en Nueva York con gran acumulación de nieve (~30 cm).
- Hizo frío (una temperatura inferior a cero grados Celsius).
- Hizo viento (~ 10 m/s).
En este tutorial se ha mostrado cómo un analista de datos puede realizar rápidamente un análisis de datos exploratorio. Puede combinar diferentes conjuntos de datos mediante un grupo de SQL sin servidor y visualizar los resultados mediante Azure Synapse Studio.
Contenido relacionado
Para aprender a conectar un grupo de SQL sin servidor a Power BI Desktop y crear informes, consulte el artículo Conexión de un grupo de SQL sin servidor a Power BI Desktop y creación de informes.
Para más información sobre el uso de tablas externas en los grupos de SQL sin servidor, consulte Uso de tablas externas con Synapse SQL.