Consulta de archivos de Delta Lake (v1) mediante un grupo de SQL sin servidor en Azure Synapse Analytics
En este artículo, aprenderá a escribir una consulta mediante un grupo de Synapse SQL sin servidor para leer archivos de Delta Lake. Delta Lake es una capa de almacenamiento de código abierto que ofrece transacciones ACID (atomicidad, coherencia, aislamiento y durabilidad) para cargas de trabajo de macrodatos de Apache Spark. Puede obtener más información en el vídeo sobre cómo consultar tablas de Delta Lake.
Importante
Los grupos de SQL sin servidor pueden consultar la versión 1.0 de Delta Lake. Los cambios introducidos desde la versión de Delta Lake 1.2, como el cambio de nombre de columnas, no se admiten en el modo sin servidor. Si usa las versiones posteriores de Delta con vectores de eliminación, puntos de control v2 y otros, debe considerar la posibilidad de usar otro motor de consulta como el punto de conexión SQL de Microsoft Fabric para almacenes de lago.
El grupo de SQL sin servidor del área de trabajo de Synapse permite leer los datos almacenados en formato Delta Lake y suministrarlos a las herramientas de generación de informes. Un grupo de SQL sin servidor puede leer archivos de Delta Lake creados mediante Apache Spark, Azure Databricks o cualquier otro productor del formato Delta Lake.
Los grupos de Apache Spark de Azure Synapse permiten a los ingenieros de datos modificar los archivos de Delta Lake mediante Scala, PySpark y .NET. Los grupos de SQL sin servidor ayudan a los analistas de datos a crear informes sobre archivos de Delta Lake creados por ingenieros de datos.
Importante
La consulta del formato de Delta Lake mediante el grupo de SQL sin servidor es una funcionalidad que está disponible con carácter general. En cambio, la consulta de tablas delta de Spark sigue en versión preliminar pública y no está lista para producción. Pueden producirse problemas conocidos si se consultan tablas delta creadas mediante los grupos de Spark. Consulte los problemas conocidos en Autoayuda del grupo de SQL sin servidor.
Ejemplo de inicio rápido
La función OPENROWSET permite leer el contenido de los archivos de Delta Lake al proporcionar la dirección URL a la carpeta raíz.
Lectura de la carpeta de Delta Lake
La forma más fácil de ver el contenido del archivo DELTA es proporcionar la dirección URL del archivo a la función OPENROWSET y especificar el formato DELTA. Si el archivo está disponible públicamente o si la identidad de Microsoft Entra puede tener acceso a este archivo, debería poder ver el contenido del archivo mediante la consulta como la que se muestra en el ejemplo siguiente:
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/delta-lake/covid/',
FORMAT = 'delta') as rows;
Los nombres de columna y los tipos de datos se leen automáticamente de los archivos de Delta Lake. La función OPENROWSET usa los mejores tipos de suposición, como VARCHAR(1000) para las columnas de cadena.
El URI de la función OPENROWSET debe hacer referencia a la carpeta raíz de Delta Lake que contiene una subcarpeta denominada _delta_log.
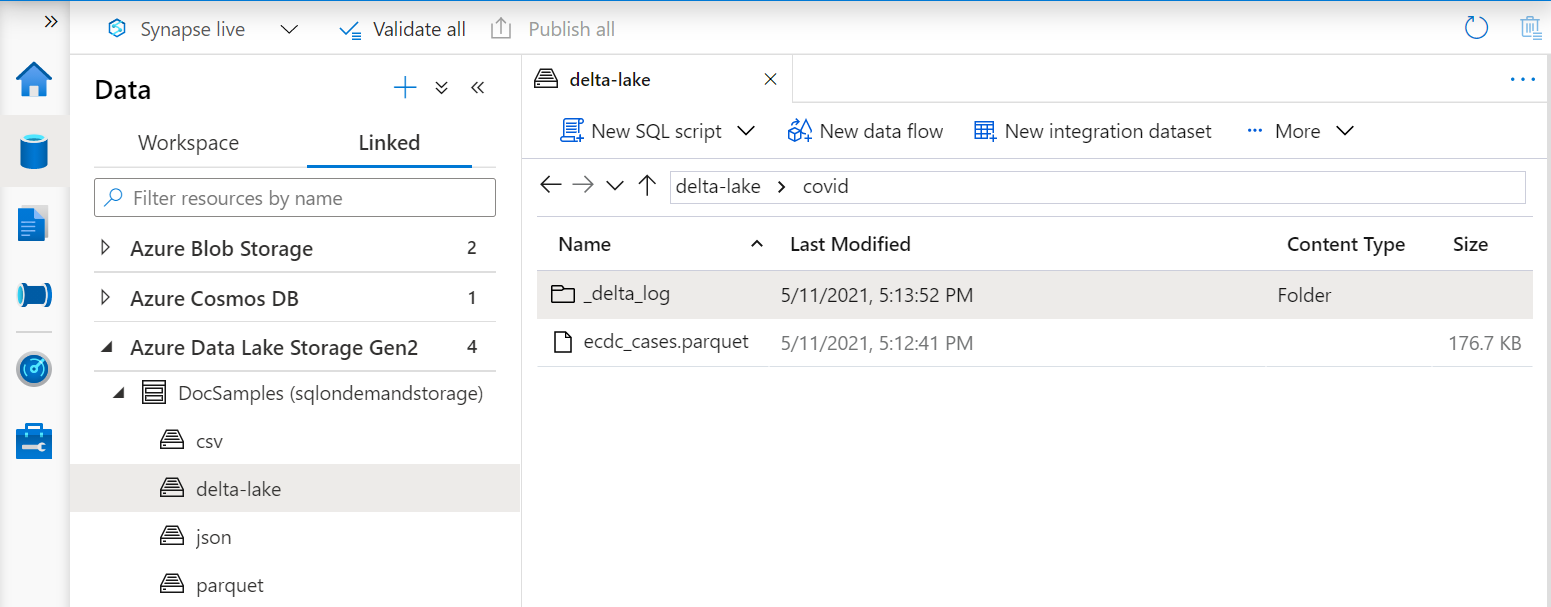
Si no tiene esta subcarpeta, no está usando el formato Delta Lake. Puede convertir los archivos sin formato de Parquet de la carpeta al formato Delta Lake mediante el siguiente script de Python de Apache Spark:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/covid`")
Para mejorar el rendimiento de las consultas, considere la posibilidad de especificar tipos explícitos en la cláusula WITH.
Nota
El grupo de Synapse SQL sin servidor usa la inferencia de esquema para determinar automáticamente las columnas y sus tipos. Las reglas de inferencia de esquema son las mismas que se usan para los archivos de Parquet. Para información sobre la asignación de tipos de Delta Lake al tipo nativo de SQL, consulte Asignación de tipos para Parquet.
Asegúrese de que puede acceder al archivo. Si el archivo está protegido con una clave SAS o una identidad personalizada de Azure, deberá configurar una credencial de nivel de servidor para el inicio de sesión de SQL.
Importante
Asegúrese de usar una intercalación de base de datos UTF-8 (por ejemplo, Latin1_General_100_BIN2_UTF8), ya que los valores de cadena de los archivos de Delta Lake se codifican con UTF-8.
Si la codificación de texto del archivo de Delta Lake y la intercalación no coinciden, se pueden producir errores de conversión inesperados.
Puede cambiar fácilmente la intercalación predeterminada de la base de datos actual mediante la siguiente instrucción T-SQL: .ALTER DATABASE CURRENT COLLATE Latin1_General_100_BIN2_UTF8; Para obtener más información sobre las intercalaciones, consulte Tipos de intercalación admitidos para Synapse SQL.
Uso del origen de datos
En los ejemplos anteriores se usaba la ruta de acceso completa al archivo. Como alternativa, puede crear un origen de datos externo con la ubicación que apunte a la carpeta raíz del almacenamiento. Una vez creado el origen de datos externo, use el origen de datos y la ruta de acceso relativa al archivo en la función OPENROWSET. De este modo, no es necesario usar el URI absoluto completo para los archivos. También puede definir credenciales personalizadas para acceder a la ubicación de almacenamiento.
Importante
Los orígenes de datos solo se pueden crear en bases de datos personalizadas (no en la base de datos maestra o en las bases de datos replicadas desde grupos de Apache Spark).
Para usar los ejemplos siguientes, deberá completar este paso:
- Cree una base de datos con un origen de datos que haga referencia a la cuenta de almacenamiento NYC Yellow Taxi.
- Inicialice los objetos ejecutando el script de instalación en la base de datos que creó en el paso 1. Este script de instalación creará los orígenes de datos, las credenciales con ámbito de base de datos y los formatos de archivo externos que se usan en estos ejemplos.
Si creó la base de datos y usó esta como contexto (mediante la instrucción USE database_name o la selección de la base de datos en la lista desplegable en algún editor de consultas), puede crear el origen de datos externo que contiene el URI raíz del conjunto de datos y usarlo para consultar archivos de Delta Lake:
CREATE EXTERNAL DATA SOURCE DeltaLakeStorage
WITH ( LOCATION = 'https://sqlondemandstorage.blob.core.windows.net/delta-lake/' );
GO
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
) as rows;
Si un origen de datos está protegido con una clave SAS o una identidad personalizada, puede configurar el origen de datos con una credencial de ámbito de base de datos.
Especificación explícita del esquema
OPENROWSET permite especificar explícitamente qué columnas desea leer del archivo con la cláusula WITH:
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
)
WITH ( date_rep date,
cases int,
geo_id varchar(6)
) as rows;
Con la especificación explícita del esquema del conjunto de resultados, puede minimizar los tamaños de los tipos y usar los tipos más precisos VARCHAR(6) en las columnas de cadena en lugar de VARCHAR(1000) pesimista. La minimización de tipos podría mejorar considerablemente el rendimiento de las consultas.
Importante
Asegúrese de especificar explícitamente alguna intercalación UTF-8 (por ejemplo, Latin1_General_100_BIN2_UTF8) para todas las columnas de cadena de la cláusula WITH o establezca alguna intercalación UTF-8 en el nivel de base de datos.
La falta de coincidencia entre la codificación de texto del archivo y la intercalación de las columnas de cadena podría producir errores de conversión inesperados.
Puede cambiar fácilmente la intercalación predeterminada de la base de datos actual mediante la siguiente instrucción T-SQL: .alter database current collate Latin1_General_100_BIN2_UTF8 Puede establecer fácilmente la intercalación en los tipos de columna mediante la siguiente definición: geo_id varchar(6) collate Latin1_General_100_BIN2_UTF8
Dataset
En este ejemplo se usa el conjunto de datos NYC Yellow Taxi. El conjunto de datos original PARQUET se convierte en el formato DELTA y la versión DELTA se usa en los ejemplos.
Consulta de datos con particiones
El conjunto de datos que se proporciona en este ejemplo se divide (particiona) en subcarpetas independientes.
A diferencia de Parquet, no es necesario dirigirse a particiones específicas mediante la función FILEPATH. OPENROWSET identificará las columnas de partición en la estructura de carpetas de Delta Lake y le permitirá consultar directamente los datos mediante estas columnas. Este ejemplo muestra los importes de las tarifas por year, month y payment_type durante los tres primeros meses de 2017.
SELECT
YEAR(pickup_datetime) AS year,
passenger_count,
COUNT(*) AS cnt
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
WHERE
nyc.year = 2017
AND nyc.month IN (1, 2, 3)
AND pickup_datetime BETWEEN CAST('1/1/2017' AS datetime) AND CAST('3/31/2017' AS datetime)
GROUP BY
passenger_count,
YEAR(pickup_datetime)
ORDER BY
YEAR(pickup_datetime),
passenger_count;
La función OPENROWSET eliminará las particiones que no coincidan con los valores de year y month en la cláusula where. Esta técnica de recorte de archivos o particiones disminuirá de forma considerable el conjunto de datos, mejorará el rendimiento y reducirá el costo de la consulta.
El nombre de la carpeta en la función OPENROWSET (yellow en este ejemplo) se concatena con LOCATION en el origen de datos DeltaLakeStorage y debe hacer referencia a la carpeta raíz Delta Lake que contiene una subcarpeta denominada _delta_log.
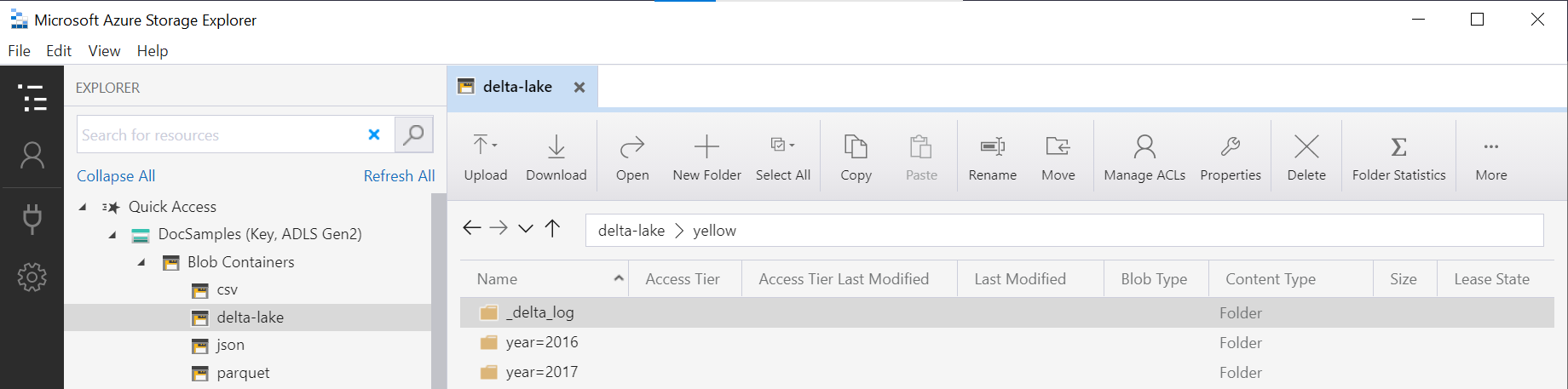
Si no tiene esta subcarpeta, no está usando el formato Delta Lake. Puede convertir los archivos sin formato de Parquet de la carpeta al formato Delta Lake mediante el siguiente script de Python de Apache Spark:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/yellow`", "year INT, month INT")
El segundo argumento de la función DeltaTable.convertToDeltaLake representa las columnas de partición (año y mes) que forman parte del patrón de carpeta (year=*/month=* en este ejemplo) y sus tipos.
Limitaciones
- Revise las limitaciones y los problemas conocidos en la página de autoayuda del grupo de SQL sin servidor de Synapse.
Contenido relacionado
Pase al siguiente artículo para obtener más información sobre cómo consultar los tipos anidados de Parquet. Si quiere seguir creando la solución Delta Lake, aprenda a crear vistas o tablas externas en la carpeta de Delta Lake.