Administración de bibliotecas para grupos de Apache Spark en Azure Synapse Analytics
Después de identificar los paquetes de Scala, Java, R (versión preliminar) o Python que desea usar o actualizar para la aplicación Spark, puede instalarlos o quitarlos de un grupo de Spark. Las bibliotecas de nivel de grupo están disponibles para todos los cuadernos y todos los trabajos que se ejecutan en el grupo.
Hay dos maneras principales de instalar una biblioteca en un grupo de Spark:
- Instale una biblioteca de área de trabajo que se haya cargado como un paquete de área de trabajo.
- Para actualizar bibliotecas de Python, proporcione un archivo de especificación de entorno requirements.txt o Conda environment.yml para instalar paquetes desde repositorios como PyPI o Conda-Forge. Para obtener más información, consulte la sección Formatos de especificación de entorno.
Después de guardar los cambios, un trabajo de Spark ejecuta la instalación y almacena en caché el entorno resultante para reutilizarlo más adelante. Una vez completado el trabajo, los nuevos trabajos o sesiones de cuaderno de Spark usan las bibliotecas de grupo actualizadas.
Importante
- Si el paquete que va a instalar es de gran tamaño o tarda mucho tiempo en instalarse, se verá afectado el tiempo de inicio de la instancia de Spark.
- No se admite la modificación de la versión de PySpark, Python, Scala/Java, .NET, R o Spark.
- La instalación de paquetes desde repositorios externos como PyPI, Conda-Forge o los canales de Conda predeterminados no se admite en áreas de trabajo habilitadas para la protección de la filtración de datos.
Administración de paquetes desde Synapse Studio o Azure Portal
Las bibliotecas de grupo de Spark se pueden administrar desde Synapse Studio o Azure Portal.
En Azure Portal, vaya al área de trabajo de Azure Synapse Analytics.
En la sección Grupos de Analytics, seleccione la pestaña Grupos de Apache Spark y seleccione un grupo de Spark de la lista.
Seleccione Paquetes en la sección Configuración del grupo de Spark.
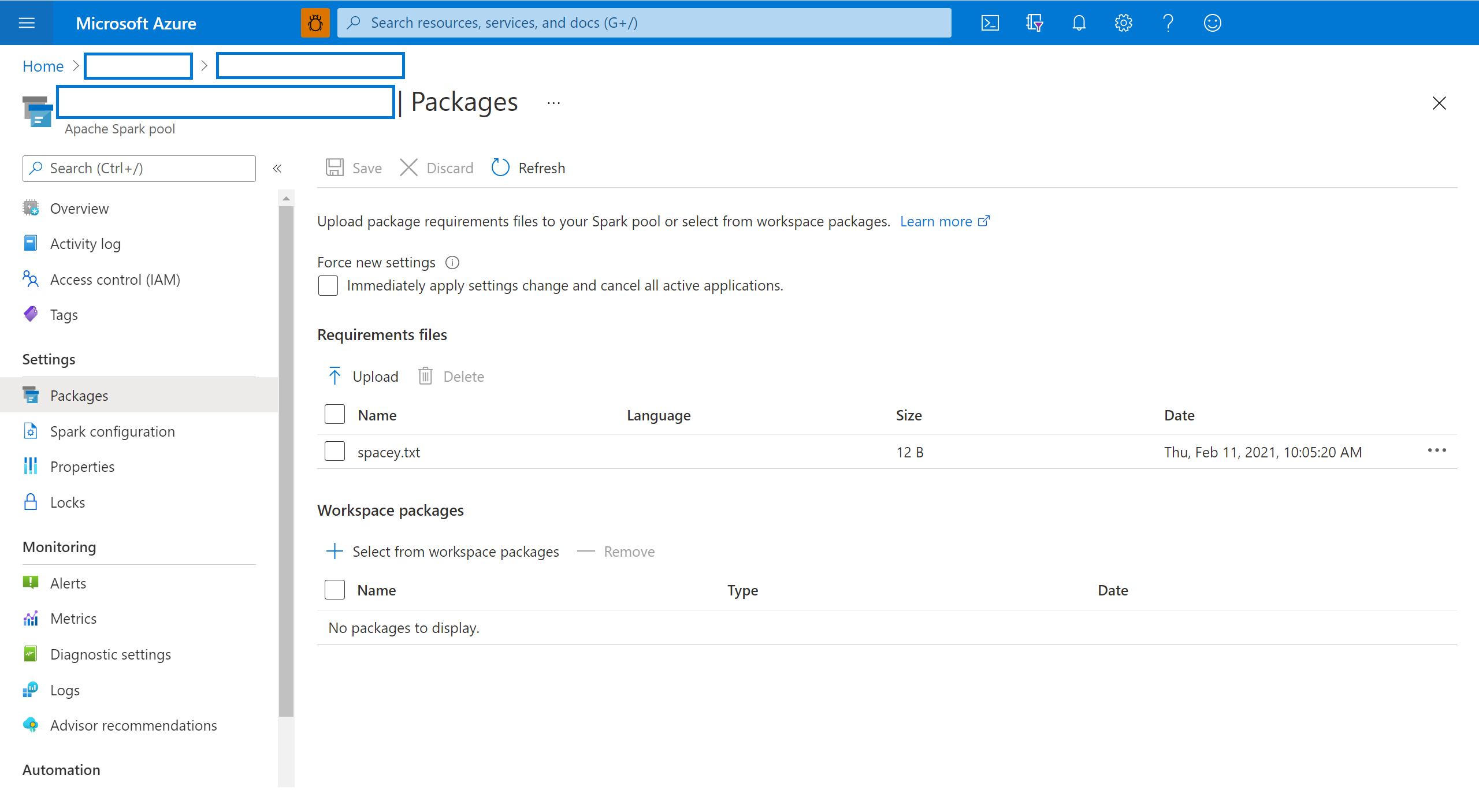
Para las bibliotecas de fuente de Python, cargue el archivo de configuración del entorno mediante el selector de archivos en la sección Paquetes de la página.
También puede seleccionar otros paquetes de área de trabajo para agregar archivos Jar o Wheel o Tar.gz al grupo.
También puede quitar los paquetes en desuso desde la sección Paquetes del área de trabajo y, a continuación, el grupo ya no adjunta estos paquetes.
Después de guardar los cambios, se desencadena un trabajo del sistema para instalar y almacenar en caché las bibliotecas especificadas. Este proceso ayuda a reducir el tiempo general de inicio de sesión.
Una vez que el trabajo se haya completado correctamente, todas las sesiones nuevas toman las bibliotecas de grupo actualizadas.


Importante
Al seleccionar la opción Forzar configuración nueva, finalizarán todas las sesiones actuales del grupo de Spark seleccionado. Una vez finalizadas las sesiones, debe esperar a que el grupo se reinicie.
Si esta opción no está seleccionada, tendrá que esperar a que la sesión de Spark actual finalice o detenerla manualmente. Una vez finalizada la sesión, debe permitir que el grupo se reinicie.
Seguimiento del progreso de la instalación
Cada vez que se actualiza un grupo con un nuevo conjunto de bibliotecas, se inicia un trabajo de Spark reservado para el sistema. Este trabajo de Spark ayuda a supervisar el estado de la instalación de las bibliotecas. Si se produce un error en la instalación debido a conflictos de la biblioteca u otros problemas, el grupo de Spark vuelve a su estado anterior o predeterminado.
Además, los usuarios pueden inspeccionar los registros de instalación para identificar conflictos de dependencia o ver qué bibliotecas se instalaron durante la actualización del grupo.
Para consultar estos registros:
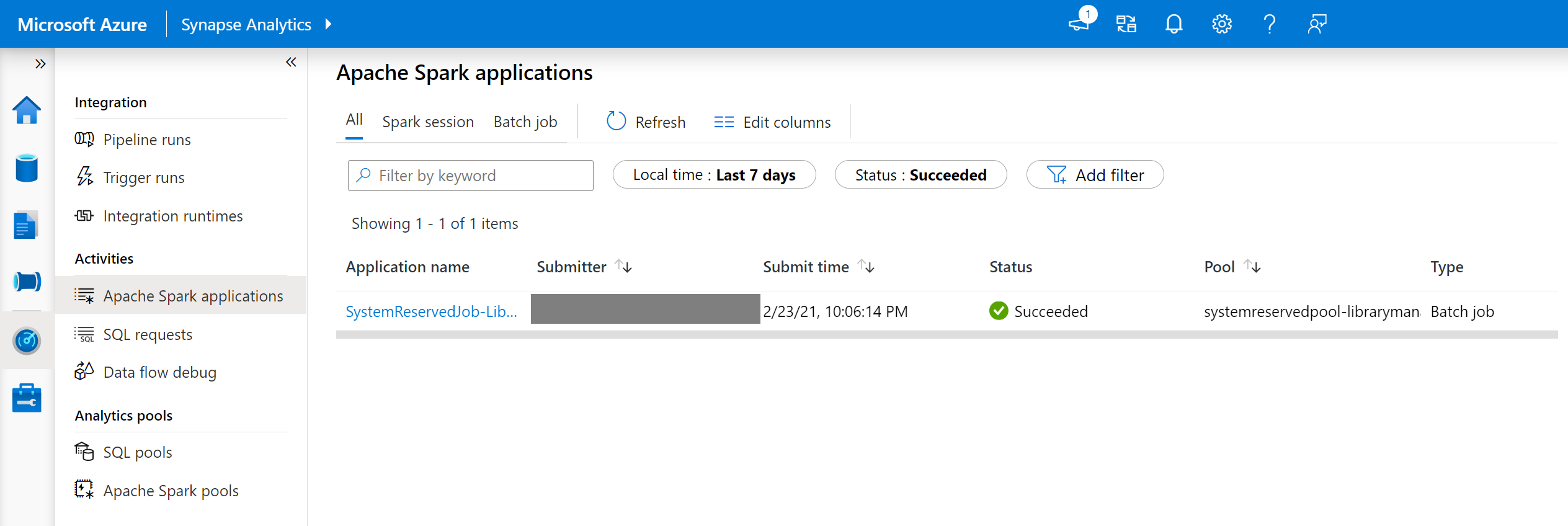
En Synapse Studio, vaya a la lista de aplicaciones Spark en la pestaña Supervisar.
Seleccione el trabajo del sistema de la aplicación de Spark que corresponde a la actualización del grupo. Estos trabajos del sistema se ejecutan con el nombre SystemReservedJob-LibraryManagement.
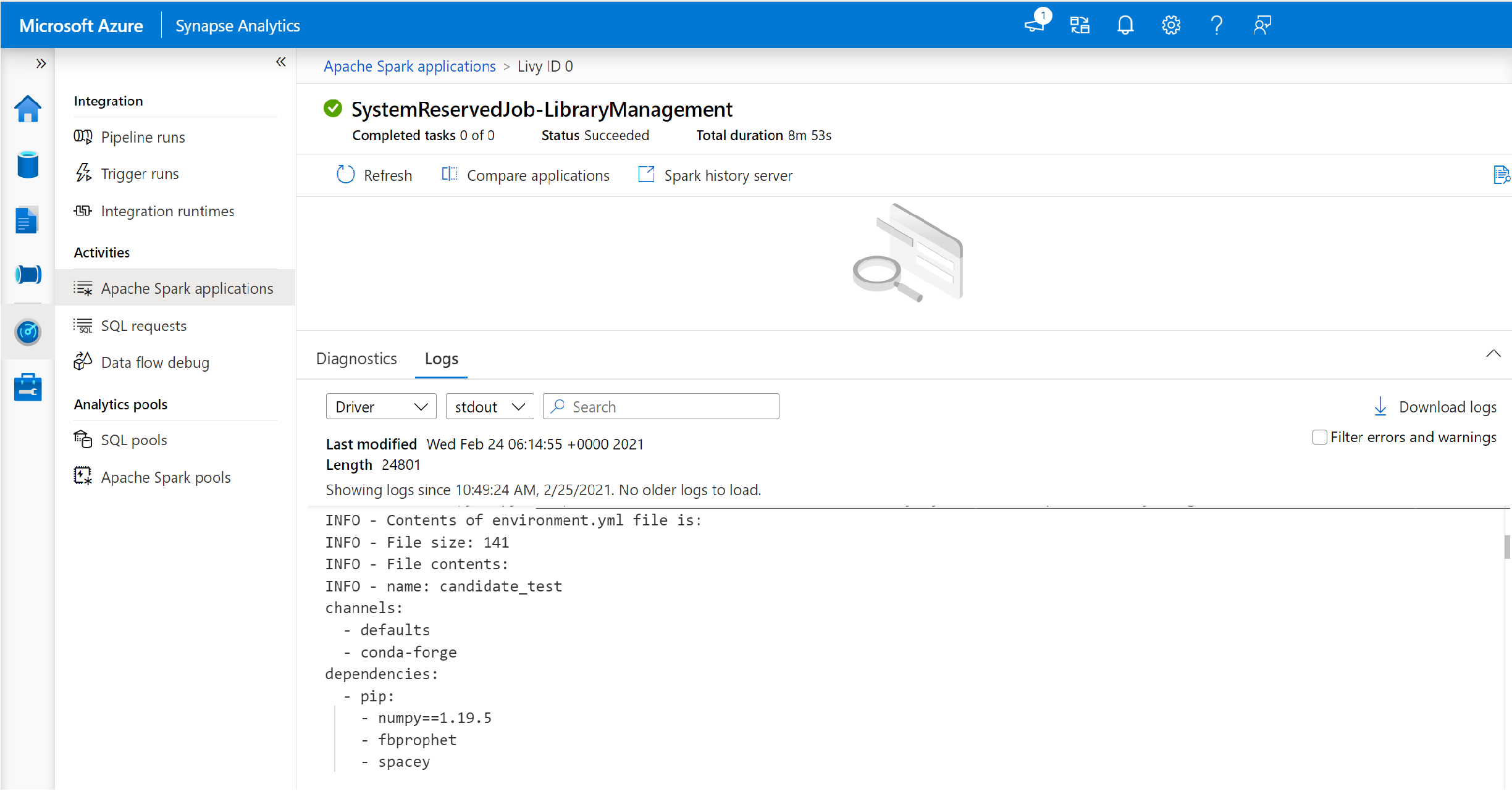
Cambie para ver los registros del controlador y de stdout.
Los resultados contienen los registros relacionados con la instalación de las dependencias.


Formatos de especificación de entorno
requirements.txt de PIP
Se puede usar un archivo requirements.txt (salida del comando pip freeze) para actualizar el entorno. Cuando se actualiza un grupo, los paquetes enumerados en este archivo se descargan desde PyPI. Después, las dependencias completas se almacenan en caché y se guardan para reutilizar el grupo más adelante.
En el fragmento de código siguiente se muestra el formato del archivo de requisitos. Se enumera el nombre del paquete PyPI, junto con una versión exacta. Este archivo sigue el formato descrito en la documentación de referencia de pip freeze.
Este ejemplo fija una versión específica.
absl-py==0.7.0
adal==1.2.1
alabaster==0.7.10
Formato YML
También puede proporcionar un archivo environment.yml para actualizar el entorno del grupo. Los paquetes que se enumeran en este archivo se descargan de los canales predeterminados de Conda, de Conda-Forge y de PyPI. Puede especificar otros canales o quitar los canales predeterminados mediante las opciones de configuración.
En este ejemplo se especifican los canales y las dependencias de Conda y PyPI.
name: stats2
channels:
- defaults
dependencies:
- bokeh
- numpy
- pip:
- matplotlib
- koalas==1.7.0
Para obtener más información sobre cómo crear un entorno a partir de este archivo environment.yml, consulte Activación de un entorno.