Más allá de la migración de Netezza: implementación de un almacenamiento de datos moderno en Microsoft Azure
Este artículo es la séptima parte de una serie de siete partes, que proporciona instrucciones sobre cómo migrar de Netezza a Azure Synapse Analytics. Este artículo se centra en proporcionar procedimientos recomendados para implementar almacenamientos de datos modernos.
Más allá de la migración del almacenamiento de datos a Azure
Una razón fundamental para migrar el almacenamiento de datos existente a Azure Synapse Analytics es la utilización de una base de datos analítica segura globalmente, escalable, de bajo coste, nativa de nube y de pago por uso. Con Azure Synapse puede integrar el almacenamiento de datos migrado con el ecosistema analítico completo de Microsoft Azure, para aprovechar las otras tecnologías de Microsoft, y modernizar el almacenamiento de datos migrado. Estas tecnologías incluyen:
Azure Data Lake Storage para una ingesta, almacenamiento provisional, limpieza y transformación de datos eficaces. Data Lake Storage puede liberar la capacidad de almacenamiento de datos ocupada por tablas de almacenamiento provisional de rápido crecimiento.
Azure Data Factory, para una integración de datos de autoservicio y de TI colaborativa, con conectores a orígenes de datos locales y en la nube, y a datos de transmisión.
Common Data Model, para compartir datos de confianza y coherentes en varias tecnologías, incluidas las siguientes:
- Azure Synapse
- Azure Synapse Spark
- HDInsight de Azure
- Power BI
- Plataforma de experiencia del cliente de Adobe
- Azure IoT
- Partners de ISV de Microsoft
Tecnologías de ciencia de datos de Microsoft, entre las que se incluyen:
- Azure Machine Learning Studio
- Azure Machine Learning
- Azure Synapse Spark (Spark como servicio)
- Cuadernos de Jupyter Notebook
- RStudio
- ML.NET
- .NET para Apache Spark, que permite que los científicos de datos usen datos de Azure Synapse para entrenar modelos de Machine Learning a gran escala.
Azure HDInsight, para procesar gran cantidad de datos y combinarlos con datos de Azure Synapse, mediante la creación de un almacenamiento de datos lógico con PolyBase.
Azure Event Hubs, Azure Stream Analytics y Apache Kafka, para realizar la integración de datos de transmisión en vivo desde Azure Synapse.
El crecimiento de macrodatos ha incrementado la demanda de que se realice la integración con el aprendizaje automático, para habilitar modelos de Machine Learning personalizados y entrenados para su uso en Azure Synapse. Los modelos de Machine Learning permiten que los análisis en las bases de datos se ejecuten a gran escala por lotes, por eventos y a petición. La capacidad de aprovechar los análisis de las bases de datos en Azure Synapse desde varias herramientas y aplicaciones de BI también garantiza predicciones y recomendaciones consistentes.
Además, puede integrar Azure Synapse con las herramientas de partners de Microsoft en Azure, y así acortar el tiempo de amortización.
Veamos con más detalle cómo sacar partido de las tecnologías del ecosistema analítico de Microsoft para modernizar el almacenamiento de datos tras la migración a Azure Synapse.
Descarga del almacenamiento provisional de datos y el procesamiento de ETL en Data Lake y Data Factory
La transformación digital ha creado un desafío crucial para las empresas al generar un torrente de nuevos datos que se han de capturar y analizar. Un buen ejemplo son los datos de transacción que se crean abriendo sistemas de procesamiento de transacciones en línea (OLTP) para el acceso de servicio desde dispositivos móviles. Gran parte de estos datos acaba en almacenes de datos y los sistemas OLTP son el origen principal. Ahora que son los clientes y no los empleados los que más impulsan la tasa de transacciones, el volumen de los datos de las tablas de almacenamiento provisional de los almacenamientos de datos ha crecido rápidamente.
La rápida entrada de datos en la empresa, junto con nuevos orígenes para los datos, como el Internet de las cosas (IoT), implica que las empresas necesitan escalar verticalmente el procesamiento de ETL de integración de datos. Un método es descargar la ingesta, la limpieza, la transformación y la integración de datos en un lago de datos y procesar los datos ahí, a gran escala, como parte de un programa de modernización del almacenamiento de datos.
Una vez que haya migrado el almacenamiento de datos a Azure Synapse, Microsoft puede modernizar el procesamiento de ETL mediante la ingesta de datos, y el almacenamiento provisional de datos, en Data Lake Storage. Después, puede limpiar, transformar e integrar los datos a gran escala mediante Data Factory, antes de cargarlos en Azure Synapse en paralelo mediante PolyBase.
En el caso de las estrategias de ELT, considere la posibilidad de descargar el procesamiento de ELT en Data Lake Storage para modificar la escala fácilmente a medida que crece el volumen o la frecuencia de los datos.
Microsoft Azure Data Factory
Azure Data Factory es un servicio de integración de datos híbridos, de pago por uso, para el procesamiento de ELT y ETL altamente escalable. Data Factory proporciona una interfaz de usuario basada en web para crear canalizaciones de integración de datos sin código. Con Data Factory puede hacer lo siguiente:
Compilar canalizaciones de integración de datos escalables sin código.
Adquirir fácilmente datos a gran escala.
Solo se paga lo que se usa.
Conéctese a orígenes de datos locales, en la nube y basados en SaaS.
Ingerir, trasladar, limpiar, transformar, integrar y analizar los datos locales y en la nube a gran escala.
Cree, supervise y administre canalizaciones sin problemas, que abarcan almacenes de datos tanto locales como en la nube.
Habilite la escalabilidad horizontal de pago por uso, en consonancia con el crecimiento de los clientes.
Puede usar estas características sin escribir código, o puede agregar código personalizado a canalizaciones de Data Factory. En la captura de pantalla siguiente se muestra un ejemplo de una canalización de Data Factory.

Sugerencia
Data Factory permite crear canalizaciones de integración de datos escalables sin código.
Tiene varias opciones desde las que implementar el desarrollo de canalizaciones de Data Factory, por ejemplo:
Microsoft Azure Portal.
Microsoft Azure PowerShell.
Mediante programación desde .NET y Python, usando un SDK de varios lenguajes.
Plantillas de Azure Resource Manager (ARM).
API de REST.
Sugerencia
Data Factory puede conectarse a datos locales, en la nube y de SaaS.
Los desarrolladores y científicos de datos que prefieren escribir código pueden crear fácilmente canalizaciones de Data Factory en Java, Python y .NET, mediante los kits de desarrollo de software (SDK) disponibles para esos lenguajes de programación. Las canalizaciones de Data Factory pueden ser canalizaciones de datos, ya que pueden conectar, ingerir, limpiar, transformar y analizar datos en centros de datos locales, en Microsoft Azure, en otras nubes y en ofertas de SaaS.
Cuando haya desarrollado canalizaciones de Data Factory para integrar y analizar datos, puede implementar esas canalizaciones globalmente y programar su ejecución por lotes, invocarlas a petición como servicio o ejecutarlas en tiempo real por eventos. Una canalización de Data Factory también se puede ejecutar en uno o varios motores de ejecución y supervisar la ejecución para garantizar el rendimiento y realizar un seguimiento de los errores.
Sugerencia
En Azure Data Factory, las canalizaciones controlan la integración y el análisis de datos. Data Factory es un software de integración de datos de clase empresarial, dirigido a profesionales de TI con una capacidad de limpieza y transformación de datos para usuarios empresariales.
Casos de uso
Data Factory admite varios casos de uso, como:
Prepare, integre y enriquezca datos de orígenes de datos locales y en la nube para rellenar el almacenamiento de datos migrado y los elementos DataMart en Microsoft Azure Synapse.
Preparare, integre y enriquezca datos de orígenes de datos locales y en la nube para generar datos de entrenamiento que se usen en el desarrollo de modelos de Machine Learning y en el entrenamiento adicional de modelos analíticos.
Organice la preparación y el análisis de datos para crear canalizaciones analíticas predictivas y prescriptivas que procesen y analicen datos por lotes, como el análisis de sentimientos. Actúe en base a los resultados del análisis o rellene el almacenamiento de datos con los resultados.
Prepare, integre y enriquezca datos de las aplicaciones empresariales controladas por datos que se ejecutan en la nube de Azure a partir de almacenes de datos operativos, como Azure Cosmos DB.
Sugerencia
Compile conjuntos de datos de entrenamiento en ciencia de datos para desarrollar modelos de Machine Learning.
Orígenes de datos
Data Factory permite usar conectores de orígenes de datos, tanto locales como de la nube. El software del agente, conocido como un entorno de ejecución de integración autohospedado, accede de forma segura a orígenes de datos locales y admite la transferencia de datos segura y escalable.
Transformación de datos con Azure Data Factory
Dentro de una canalización de Data Factory, puede ingerir, limpiar, transformar, integrar y analizar cualquier tipo de dato de estos orígenes. Los datos se pueden estructurar, semiestructurar, como JSON o Avro, o no estructurar.
Sin escribir nada de código, los desarrolladores profesionales de ETL pueden usar flujos de datos de asignación de Data Factory para filtrar, dividir, combinar varios tipos, buscar, dinamizar, anular la dinamización, ordenar, unir y agregar datos. Además, Data Factory admite claves suplentes y varias opciones de procesamiento de escritura, como insertar, upsert, actualizar, recrear tablas o truncarlas, y varios tipos de almacenes de datos de destino, también conocidos como receptores. Los desarrolladores de ETL también pueden crear agregaciones, incluidas las de series temporales en las que es necesario colocar una ventana en columnas de datos.
Sugerencia
Los desarrolladores profesionales de ETL pueden usar flujos de datos de asignación de Data Factory para limpiar, transformar e integrar datos, sin necesidad de escribir código.
Puede ejecutar flujos de datos de asignación que transforman los datos como actividades en una canalización de Data Factory y, si es necesario, puede incluir varios flujos de datos de asignación en una sola canalización. De este modo, puede administrar la complejidad dividiendo las tareas complejas de transformación e integración de datos en flujos de datos de asignación más pequeños que se pueden combinar. Además, puede agregar código personalizado cuando sea necesario. Además de esta funcionalidad, los flujos de datos de asignación de Data Factory incluyen las capacidades:
Defina expresiones para limpiar y transformar datos, procesar agregaciones y enriquecer datos. Por ejemplo, estas expresiones pueden realizar ingeniería de características en un campo de fecha, para dividirlo en varios campos y así crear datos de entrenamiento durante el desarrollo del modelo de Machine Learning. Puede construir expresiones a partir de un amplio conjunto de funciones, que incluyen tipos como matemáticas, temporales, de división, de combinación, de concatenación de cadenas, de condiciones, de coincidencia de patrones, de reemplazo y muchas otras funciones.
Controle automáticamente el desfase del esquema para que las canalizaciones de transformación de datos puedan evitar verse afectadas por los cambios de esquema en los orígenes de datos. Esta posibilidad es especialmente importante para el streaming de datos de IoT, donde los cambios de esquema pueden producirse sin previo aviso si se actualizan los dispositivos o cuando se pierden las lecturas por parte de los dispositivos de puerta de enlace que recopilan datos de IoT.
Particione los datos para permitir que las transformaciones se ejecuten en paralelo a gran escala.
Inspeccione los datos de transmisión para ver los metadatos de la secuencia que está transformando.
Sugerencia
Data Factory admite la capacidad de detectar y administrar automáticamente los cambios de esquema en los datos entrantes, como en los datos de streaming.
En la captura de pantalla siguiente se muestra un ejemplo de un flujo de datos de asignación de Data Factory.

Los ingenieros de datos pueden generar perfiles de la calidad de los datos y ver los resultados de las transformaciones de datos individuales, mediante la habilitación de una funcionalidad de depuración durante el desarrollo.
Sugerencia
Data Factory también puede particionar los datos para permitir que el procesamiento de ETL se ejecute a gran escala.
Si es necesario, puede ampliar la funcionalidad de transformación y análisis de Data Factory agregando un servicio vinculado que contenga el código en una canalización. Por ejemplo, un cuaderno de grupo de Spark en Azure Synapse podría contener código de Python que usa un modelo entrenado para puntuar los datos integrados por un flujo de datos de asignación.
Puede almacenar los datos integrados y los resultados de los análisis de una canalización de Data Factory en uno o varios almacenes de datos, como Data Lake Storage, Azure Synapse o tablas de Hive en HDInsight. También puede invocar otras actividades para tomar decisiones sobre la información generada por una canalización analítica de Data Factory.
Sugerencia
Las canalizaciones de Data Factory son extensibles, ya que Data Factory le permite escribir su propio código y ejecutarlo como parte de una canalización.
Uso de Spark para modificar la escala de la integración de datos
En el tiempo de ejecución, Data Factory usa internamente grupos de Spark de Azure Synapse, que son una oferta de Spark como servicio de Microsoft, para limpiar e integrar datos en la nube de Azure. Puede limpiar, integrar y analizar a gran escala datos de gran volumen y alta velocidad, como los datos de flujo de clics. La intención de Microsoft es ejecutar también canalizaciones de Data Factory en otras distribuciones de Spark. Además de ejecutar trabajos de ETL en Spark, Data Factory puede invocar scripts de Pig y consultas de Hive para acceder a los datos almacenados en HDInsight y transformarlos.
Vinculación de la preparación de datos de autoservicio y el procesamiento de ETL de Data Factory mediante flujos de datos de limpieza y transformación
La limpieza y transformación de datos permite que los usuarios empresariales (también conocidos como integradores civiles de datos e ingenieros de datos) usen la plataforma para detectar, explorar y preparar visualmente los datos a gran escala, sin escribir código. Esta funcionalidad de Data Factory, fácil de usar, es similar a Microsoft Excel Power Query o a los flujos de datos de Microsoft Power BI, donde los usuarios empresariales de autoservicio usan una interfaz de usuario de estilo hoja de cálculo, con transformaciones desplegables, para preparar e integrar datos. En la captura de pantalla siguiente se muestra un ejemplo de flujo de datos de limpieza y transformación de Data Factory.

A diferencia de Excel y Power BI, los flujos de datos de limpieza y transformación de Data Factory usan Power Query para generar código M y traducirlo entonces a un trabajo de Spark paralelo, masivo y en memoria para la ejecución a escala en la nube. La combinación de flujos de datos de asignación y flujos de datos de limpieza y transformación en Data Factory permite que los desarrolladores profesionales de ETL y los usuarios empresariales puedan colaborar para preparar, integrar y analizar datos con un propósito empresarial común. En el diagrama anterior del flujo de datos de asignación de Data Factory se muestra cómo se pueden combinar instancias de Data Factory con cuadernos de grupos de Spark de Azure Synapse en la misma canalización de Data Factory. La combinación de flujos de datos de limpieza y transformación en Data Factory ayuda a los usuarios empresariales y de TI a mantenerse al tanto de los flujos de datos que cada uno ha creado, y admite la reutilización del flujo de datos para minimizar la reinvención y maximizar la productividad y la coherencia.
Sugerencia
Data Factory admite flujos de datos de limpieza y transformación y flujos de datos de asignación, por lo que los usuarios empresariales y los usuarios de TI pueden integrar datos de forma colaborativa en una plataforma común.
Vinculación de datos y análisis en canalizaciones analíticas
Además de limpiar y transformar datos, Data Factory puede combinar la integración y el análisis de datos en la misma canalización. Puede usar Data Factory para crear canalizaciones de integración de datos y analíticas, siendo las del segundo tipo una extensión de las primeras. Puede colocar un modelo analítico en una canalización para crear una canalización analítica que genere datos limpios e integrados para predicciones o recomendaciones. A continuación, puede tomar decisiones en función de esas predicciones o recomendaciones inmediatamente, o almacenarlas en el almacenamiento de datos para proporcionar nuevas conclusiones y recomendaciones que se pueden visualizar en las herramientas de BI.
Para puntuar por lotes los datos, puede desarrollar un modelo analítico que invoque como servicio en una canalización de Data Factory. Puede desarrollar modelos analíticos sin código con Estudio de Azure Machine Learning o con el SDK de Azure Machine Learning mediante cuadernos de grupos de Spark en Azure Synapse o R en RStudio. Al ejecutar canalizaciones de aprendizaje automático de Spark en cuadernos de grupos de Spark en Azure Synapse, el análisis se realiza a escala.
Puede almacenar datos integrados y cualquier canalización analítica de Data Factory da como resultado uno o varios almacenes de datos, como Data Lake Storage, Azure Synapse o tablas de Hive en HDInsight. También puede invocar otras actividades para tomar decisiones sobre la información generada por una canalización analítica de Data Factory.
Use una base de datos de lago para compartir datos de confianza y coherentes
Un objetivo clave de cualquier configuración de integración de datos es la capacidad de integrar datos una vez y reutilizarlos en todas partes, no solo en un almacenamiento de datos. Por ejemplo, es posible que quiera usar datos integrados en la ciencia de datos. La reutilización evita la reinvención y garantiza datos coherentes y comprensibles, en los que todos pueden confiar.
Common Data Model describe las entidades de datos principales que se pueden compartir y reutilizar en toda la empresa. Para la reutilización, Common Data Model establece un conjunto de nombres y definiciones de datos comunes que describen entidades de datos lógicas. Algunos ejemplos de nombres de datos comunes son: cliente, cuenta, producto, proveedor, pedidos, pagos y devoluciones. Los profesionales de TI y empresariales pueden usar software de integración de datos para crear estos recursos de datos comunes, y almacenarlos para maximizar su reutilización y así controlar la coherencia en todas partes.
Azure Synapse proporciona plantillas de base de datos específicas del sector para ayudar a estandarizar los datos en el lago. Las plantillas de bases de datos de lago proporcionan esquemas para áreas de negocio predefinidas, lo que permite cargar datos en una base de datos de lago de forma estructurada. Los resultados eficaces llegan cuando el software de integración de datos se usa para crear recursos de datos comunes de la bases de datos de lago. Esto proporciona datos de confianza y autodescriptivos, que pueden consumirse en las aplicaciones y los sistemas analíticos. Puede crear recursos de datos comunes en Data Lake Storage mediante Data Factory.
Sugerencia
Data Lake Storage es un almacenamiento compartido que respalda Microsoft Azure Synapse, Azure Machine Learning, Azure Synapse Spark y HDInsight.
Power BI, Azure Synapse Spark, Azure Synapse y Azure Machine Learning pueden consumir recursos de datos comunes. En el diagrama siguiente se muestra cómo una base de datos de lago se puede usar en Azure Synapse.
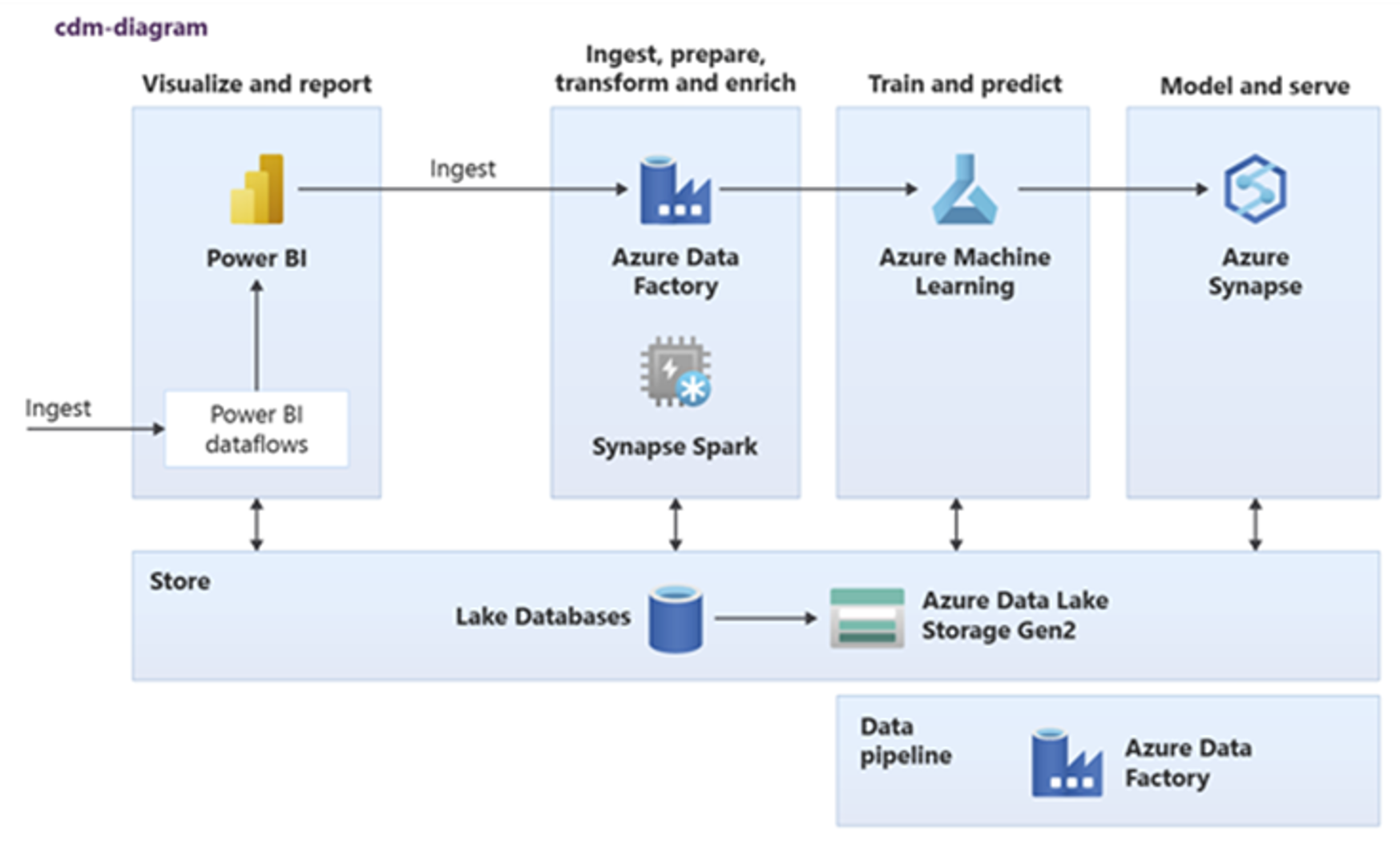
Sugerencia
Integre datos para crear entidades lógicas de bases de datos de lago en el almacenamiento compartido para maximizar la reutilización de los recursos de datos comunes.
Integración con tecnologías de ciencia de datos de Microsoft en Azure
Otro objetivo clave al modernizar un almacenamiento de datos es generar información para obtener una ventaja competitiva. Puede generar información mediante la integración del almacenamiento de datos migrado con Microsoft y tecnologías de ciencia de datos de terceros en Azure. En las secciones siguientes se describen el aprendizaje automático y las tecnologías de ciencia de datos que ofrece Microsoft para ver cómo se pueden usar con Azure Synapse en un entorno de almacenamiento de datos moderno.
Tecnologías de Microsoft para la ciencia de datos en Azure
Microsoft ofrece una variedad de tecnologías que admiten el análisis avanzado. Con estas tecnologías, puede crear modelos analíticos predictivos mediante el aprendizaje automático o analizar datos no estructurados mediante el aprendizaje profundo. Las tecnologías incluyen:
Azure Machine Learning Studio
Azure Machine Learning
Cuadernos de grupos de Spark en Azure Synapse
ML.NET (API, CLI o ML.NET Model Builder para Visual Studio)
.NET para Apache Spark
Los científicos de datos pueden usar RStudio (R) y cuadernos de Jupyter Notebook (Python) para desarrollar modelos analíticos, o pueden usar marcos como Keras o TensorFlow.
Sugerencia
Desarrolle modelos de Machine Learning con un enfoque de código escaso o sin código, o con lenguajes de programación como Python, R y .NET.
Azure Machine Learning Studio
Estudio de Azure Machine Learning es un servicio en la nube totalmente administrado que permite compilar, implementar y compartir análisis predictivos mediante una interfaz de usuario de arrastrar y colocar basada en web. En la captura de pantalla siguiente se muestra la interfaz de usuario de Estudio de Azure Machine Learning.

Azure Machine Learning
Azure Machine Learning proporciona un SDK y servicios para Python que pueden ayudarle a preparar rápidamente los datos y también entrenar e implementar modelos de aprendizaje automático. Puede usar Azure Machine Learning en cuadernos de Azure mediante Jupyter Notebook, con marcos de código abierto, como PyTorch, TensorFlow, scikit-learn o Spark MLlib, la biblioteca de aprendizaje automático para Spark.
Sugerencia
Azure Machine Learning proporciona un SDK para desarrollar modelos de Machine Learning mediante varios marcos de código abierto.
También puede usar Azure Machine Learning para compilar canalizaciones de aprendizaje automático que administran el flujo de trabajo de un extremo a otro, escalan mediante programación en la nube e implementan modelos tanto en la nube como en el perímetro. Azure Machine Learning contiene áreas de trabajo, que son espacios lógicos que se pueden crear mediante programación o manualmente en Azure Portal. Estas áreas de trabajo mantienen los destinos de proceso, los experimentos, los almacenes de datos, los modelos de Machine Learning entrenados, las imágenes de Docker y los servicios implementados en un solo lugar para permitir que los equipos trabajen de forma conjunta. Puede usar Azure Machine Learning en Visual Studio con la extensión Visual Studio para IA.
Sugerencia
Organice y administre almacenes de datos relacionados, experimentos, modelos entrenados, imágenes de Docker y servicios implementados en áreas de trabajo.
Cuadernos de grupos de Spark en Azure Synapse
Un cuaderno de grupos de Spark en Azure Synapse es un servicio de Apache Spark optimizado para Azure. Con los cuadernos de grupos de Spark en Azure Synapse:
Los ingenieros de datos pueden compilar y ejecutar trabajos de preparación de datos escalables mediante Data Factory.
Los científicos de datos pueden compilar y ejecutar modelos de Machine Learning a gran escala, mediante cuadernos escritos en lenguajes como Scala, R, Python, Java y SQL para visualizar los resultados.
Sugerencia
Spark en Azure Synapse es la oferta de Spark como servicio escalable de forma dinámica de Microsoft, ofrece una ejecución escalable de preparación de datos, desarrollo de modelos y ejecución de modelos implementados.
Los trabajos que se ejecutan en un cuaderno de grupo de Spark en Azure Synapse pueden recuperar, procesar y analizar datos a gran escala desde Azure Blob Storage, Data Lake Storage, Azure Synapse, HDInsight y servicios de datos de transmisión como Apache Kafka.
Sugerencia
Spark en Azure Synapse puede acceder a los datos de una gama de almacenes de datos del ecosistema analítico de Microsoft en Azure.
Los cuadernos de grupos de Spark en Azure Synapse admiten el escalado automático y la finalización automática para reducir el costo total de propiedad (TCO). Los científicos de datos pueden usar el marco de código abierto de MLflow para administrar el ciclo de vida del aprendizaje automático.
ML.NET
ML.NET es un marco de aprendizaje automático multiplataforma de código abierto para Windows, Linux y macOS. Microsoft creó ML.NET para que los desarrolladores de .NET puedan usar herramientas existentes, como ML.NET Model Builder para Visual Studio, para desarrollar modelos de aprendizaje automático personalizados e integrarlos en sus aplicaciones de .NET.
Sugerencia
Microsoft ha ampliado su capacidad de aprendizaje automático a los desarrolladores de .NET.
.NET para Apache Spark
.NET para Apache Spark amplía la compatibilidad con Spark más allá de R, Scala, Python y Java a .NET y tiene como objetivo que Spark sea accesible para los desarrolladores de .NET en todas las API de Spark. Aunque .NET para Apache Spark solo está disponible actualmente en Apache Spark en HDInsight, Microsoft pretende que .NET para Apache Spark esté disponible en los cuadernos de grupos de Spark en Azure Synapse.
Uso de Azure Synapse Analytics con el almacenamiento de datos
Para combinar modelos de aprendizaje automático con Azure Synapse, puede hacer lo siguiente:
Use modelos de Machine Learning en modo por lotes o en tiempo real en datos de transmisión para generar nueva información y agregarla a la que ya conoce en Azure Synapse.
Use los datos de Azure Synapse para desarrollar y entrenar nuevos modelos predictivos para su implementación en otro lugar, por ejemplo, en otras aplicaciones.
Implemente modelos de Machine Learning, incluidos los entrenados en otro lugar, en Azure Synapse para analizar datos en el almacenamiento de datos y darle un nuevo valor a su negocio.
Sugerencia
Entrene, pruebe, evalúe y ejecute modelos de Machine Learning a gran escala en cuadernos de grupos de Spark en Azure Synapse mediante datos de Azure Synapse.
Los científicos de datos pueden usar RStudio, cuadernos de Jupyter Notebook y cuadernos de grupos de Spark en Azure Synapse junto con Azure Machine Learning para desarrollar modelos de Machine Learning que se ejecutan a gran escala en cuadernos de grupos de Spark en Azure Synapse, con datos en Azure Synapse. Por ejemplo, podrían crear un modelo no supervisado para segmentar a los clientes y así controlar diferentes campañas de marketing. Use el aprendizaje automático supervisado para entrenar un modelo que prediga un resultado específico, como predecir la propensión de un cliente a abandonar o recomendar la siguiente mejor oferta para un cliente y así intentar aumentar su valor. En el diagrama siguiente se muestra cómo se puede usar Azure Synapse para Azure Machine Learning.
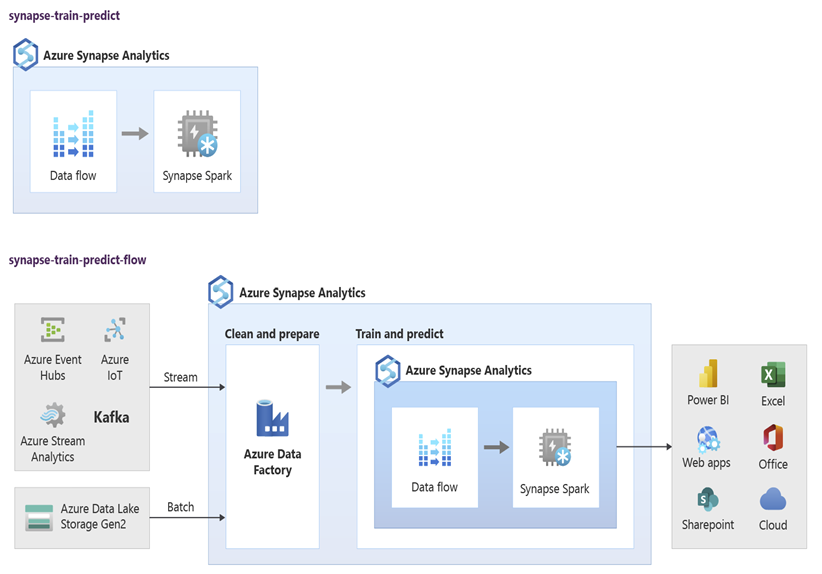
En otro escenario, puede ingerir datos de redes sociales o de sitios web de reseñas en Data Lake Storage y, después, prepararlos y analizarlos a gran escala en un cuaderno de grupo de Spark en Azure Synapse, mediante el procesamiento de lenguaje natural para puntuar opiniones de clientes sobre los productos o la marca. Después, puede agregar esas puntuaciones al almacenamiento de datos. Mediante el uso del análisis de macrodatos para comprender el efecto de la opinión negativa en las ventas de productos, se agrega a la información que ya tiene en el almacenamiento de datos.
Sugerencia
Genere nueva información mediante el aprendizaje automático en Azure, por lotes o en tiempo real, y agréguela a la que ya conoce en el almacenamiento de datos.
Integración de datos de streaming en vivo en Azure Synapse Analytics
Al analizar datos en un almacenamiento de datos moderno, debe poder analizar los datos de streaming en tiempo real y combinarlos con datos históricos en el almacenamiento de datos. Un ejemplo sería combinar datos de IoT con datos de productos o recursos.
Sugerencia
Integre el almacenamiento de datos con datos de streaming de dispositivos de IoT o de secuencia de clics.
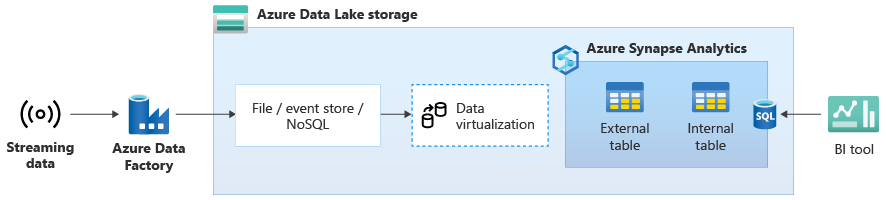
Una vez que haya migrado correctamente el almacenamiento de datos a Azure Synapse, puede introducir la integración de datos de streaming en vivo como parte de un ejercicio de modernización del almacenamiento de datos aprovechando la funcionalidad adicional en Azure Synapse. Para ello, ingiera datos de streaming mediante Event Hubs, otras tecnologías como Apache Kafka o, posiblemente, la herramienta ETL existente si admite los orígenes de datos de streaming. Almacene los datos en Data Lake Storage. A continuación, cree una tabla externa en Azure Synapse mediante PolyBase y póngala en dirección a los datos que se transmiten a Data Lake Storage para que el almacenamiento de datos contenga ahora nuevas tablas que proporcionen acceso a los datos de streaming en tiempo real. Consulte esta tabla externa como si los datos estuvieran en el almacenamiento de datos mediante TSQL estándar desde cualquier herramienta de BI que tenga acceso a Azure Synapse. También puede combinar estos datos de transmisión a otras tablas que contienen datos históricos. Así, puede crear vistas que combinan datos de streaming en vivo con datos históricos para facilitar el acceso a los datos de los usuarios empresariales.
Sugerencia
Ingiera datos de transmisión en Data Lake Storage desde Event Hubs o Apache Kafka, y acceda a ellos desde Azure Synapse mediante tablas externas de PolyBase.
En el diagrama siguiente, un almacenamiento de datos en tiempo real en Azure Synapse se integra con datos de streaming en Data Lake Storage.
Creación de un almacenamiento de datos lógico mediante PolyBase
Con PolyBase puede crear un almacenamiento de datos lógico para simplificar el acceso de los usuarios a varios almacenes de datos analíticos. En los últimos años, muchas empresas han adoptado almacenes de datos analíticos "optimizados para cargas de trabajo", además de sus almacenamientos de datos. Las plataformas analíticas de Azure incluyen:
Data Lake Storage con cuadernos de grupo de Spark en Azure Synapse (Spark como servicio) para el análisis de macrodatos.
HDInsight (Hadoop como servicio), también para el análisis de macrodatos.
Bases de datos de grafos de NoSQL para el análisis de grafos, que se podrían realizar en Azure Cosmos DB.
Event Hubs y Stream Analytics, para el análisis en tiempo real de datos en movimiento.
Es posible que tenga equivalentes de estas plataformas que no sean de Microsoft, o un sistema de administración de datos maestros (MDM), al que se debe acceder para obtener datos de confianza y coherentes sobre clientes, proveedores, productos, activos, etc.
Sugerencia
PolyBase simplifica el acceso a varios almacenes de datos analíticos subyacentes en Azure para facilitar el acceso a los usuarios empresariales.
Esas plataformas analíticas surgieron debido a la explosión de nuevos orígenes de datos dentro y fuera de la empresa y la demanda de los usuarios empresariales para capturar y analizar los nuevos datos. Los nuevos orígenes de datos incluyen:
Datos generados por máquinas, como datos de sensores de IoT e información de la secuencia de clics.
Datos generados por personas, como datos de redes sociales, de sitios web de reseñas, correos electrónicos enviados por clientes, imágenes y vídeos.
Otros datos externos, como datos públicos de administraciones y datos meteorológicos.
Estos nuevos datos van más allá de los datos de transacción estructurados y los principales orígenes de datos que normalmente alimentan los almacenes de datos y, a menudo, incluyen:
- Datos semiestructurados como JSON, XML o Avro.
- Datos no estructurados, como texto, voz, imagen o vídeo, que son más complejos de procesar y analizar.
- Datos de gran volumen, datos de alta velocidad o ambos.
Por lo tanto, han surgido nuevos tipos de análisis más complejos, como el procesamiento de lenguaje natural, el análisis de grafos, el aprendizaje profundo, el análisis de streaming o el análisis complejo de grandes volúmenes de datos estructurados. Todos estos tipos de análisis normalmente no suceden en un almacenamiento de datos, por lo que no es sorprendente que haya diferentes plataformas analíticas para distintos tipos de cargas de trabajo analíticas, como se muestra en el diagrama siguiente.
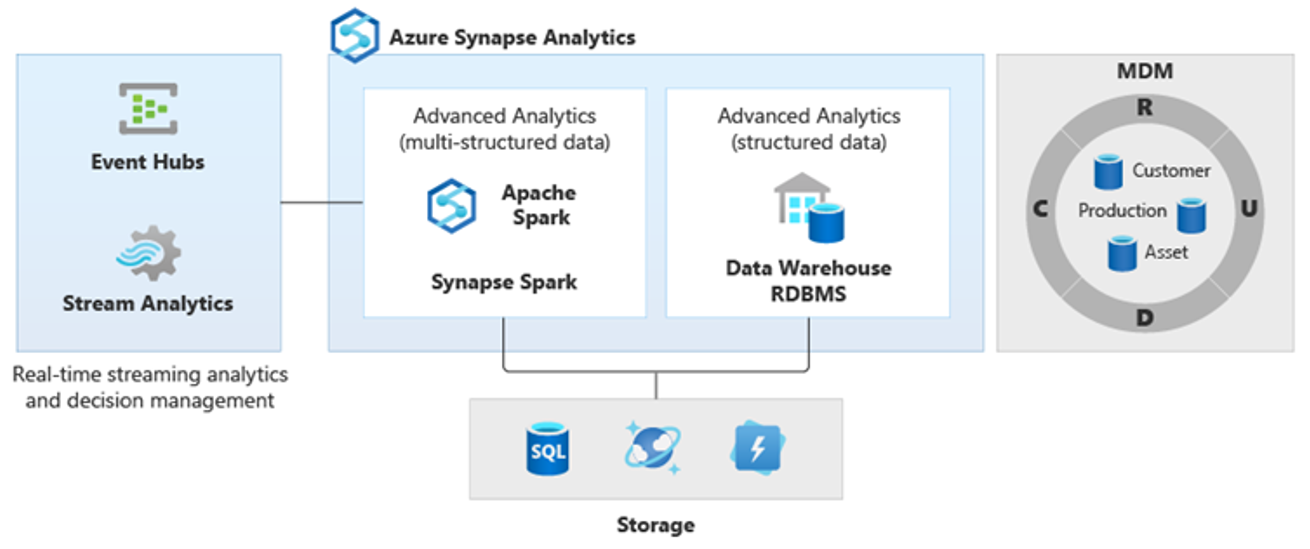
Sugerencia
La capacidad de hacer que todos los datos de varios almacenes de datos analíticos parezcan estar en un único sistema y unirlos a Azure Synapse se conoce como una arquitectura de almacenamiento de datos lógica.
Dado que estas plataformas generan nuevas conclusiones, es normal que se necesite combinar la nueva información con lo que ya posee en Azure Synapse, PolyBase hace que eso sea posible.
Mediante el uso de la virtualización de datos de PolyBase en Azure Synapse, puede implementar un almacenamiento de datos lógico donde los datos de Azure Synapse se unen a datos de otros almacenes de datos analíticos locales y de Azure, como HDInsight, Azure Cosmos DB o datos de streaming que fluyen a Data Lake Storage desde Stream Analytics o Event Hubs. Este enfoque reduce la complejidad para los usuarios que acceden a tablas externas en Azure Synapse y que no necesitan saber que los datos a los que acceden se almacenan en varios sistemas analíticos subyacentes. En el diagrama siguiente se muestra la estructura compleja del almacenamiento de datos a la que se accede con métodos de interfaz de usuario que son más sencillos en comparación pero igualmente eficaces.
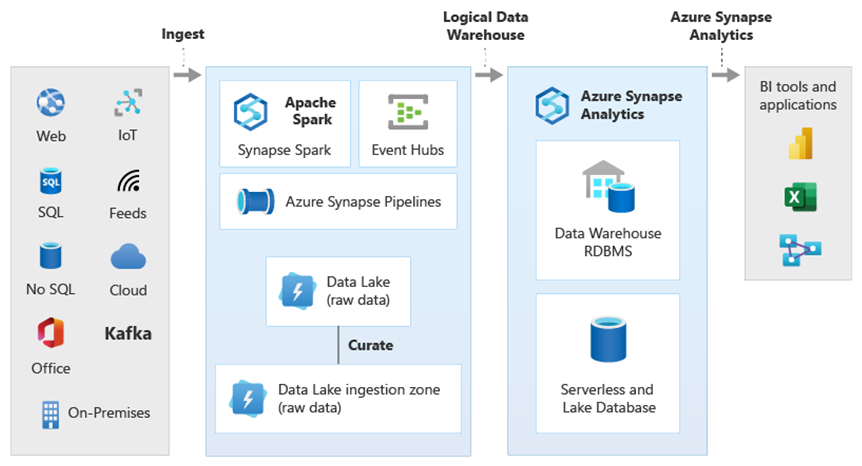
En el diagrama se muestra cómo se pueden combinar otras tecnologías del ecosistema analítico de Microsoft con la capacidad de la arquitectura de almacenamiento de datos lógica en Azure Synapse. Por ejemplo, puede ingerir datos en Data Lake Storage y mantenerlos mediante Data Factory para crear productos de datos de confianza, que representan entidades de datos lógicas de base de datos de lago de Microsoft. Así, estos datos de confianza y comprensibles se pueden consumir y reutilizar en diferentes entornos analíticos, como Azure Synapse, los cuadernos de grupos de Spark en Azure Synapse o Azure Cosmos DB. Todas las conclusiones que se generan en estos entornos son accesibles a través de una capa de virtualización de datos de almacenamiento de datos lógico que administra PolyBase.
Sugerencia
Una arquitectura de almacenamiento de datos lógico simplifica el acceso de los usuarios empresariales a los datos y agrega un nuevo valor a lo que ya conoce en el almacenamiento de datos.
Conclusiones
Tras migrar el almacenamiento de datos a Azure Synapse, puede sacar provecho de otras tecnologías en el ecosistema analítico de Microsoft. Al hacerlo, no solo moderniza el almacenamiento de datos, sino que también puede reunir la información generada en otros almacenes de datos analíticos de Azure en una arquitectura analítica integrada.
Puede ampliar el procesamiento de ETL para ingerir datos de cualquier tipo en Data Lake Storage, así como prepararlos e integrarlos a escala mediante Data Factory para generar recursos de datos de confianza de uso común. Estos recursos los puede consumir el almacenamiento de datos y los científicos de datos y otras aplicaciones pueden acceder a ellos. Puede crear canalizaciones analíticas en tiempo real y orientadas por lotes, y cree modelos de Machine Learning para que se ejecuten en lotes, en tiempo real con datos de transmisión y a petición como servicio.
Puede usar PolyBase o COPY INTO para ir más allá del almacenamiento de datos para simplificar el acceso a la información que se genera en varias plataformas de análisis subyacentes de Azure. Para hacerlo, cree vistas holísticas integradas en un almacenamiento de datos lógico que admiten el acceso al streaming, a los macrodatos y a la información del almacenamiento de datos tradicional mediante herramientas y aplicaciones de BI.
Al migrar el almacenamiento de datos a Azure Synapse, puede aprovechar el amplio ecosistema analítico de Microsoft que se ejecuta en Azure para aportarle un nuevo valor a su empresa.
Pasos siguientes
Para más información sobre la migración a un grupo de SQL dedicado, consulte Migración de un almacenamiento de datos a un grupo de SQL dedicado en Azure Synapse Analytics.