Información general de la ingesta de datos del Explorador de datos de Azure Synapse (versión preliminar)
La ingesta de datos es el proceso que se usa para cargar los registros de datos de uno o varios orígenes para importar datos en una tabla en un grupo del Explorador de datos de Azure Synapse. Una vez ingeridos, los datos están disponibles para su consulta.
El servicio de administración de datos del Explorador de datos de Azure Synapse, que es el responsable de la ingesta de datos, implementa el siguiente proceso:
- Extrae los datos por lotes o en streaming de un origen externo y lee las solicitudes de una cola de Azure pendiente.
- El procesamiento por lotes de los datos que fluyen en la misma base de datos y tabla se optimiza para mejorar el rendimiento de la ingesta.
- Se validan los datos iniciales y el formato se convierte cuando sea necesario.
- Una posterior manipulación de los datos incluye hacer coincidir los esquemas, así como organizar, indexar, codificar y comprimir los datos.
- Los datos se conservan en el almacenamiento de acuerdo con la directiva de retención establecida.
- Los datos ingeridos se confirman en el motor, donde están disponibles para su consulta.
Formatos de datos compatibles, propiedades y permisos
Propiedades de la ingesta : las propiedades que afectan a la forma en que se van a ingerir los datos (por ejemplo, etiquetado, asignación u hora de creación).
Permisos: Para ingerir datos, el proceso necesitapermisos de nivel de agente de ingesta de bases de datos. Otras acciones, como la consulta, pueden requerir permisos de administrador de base de datos, usuario de base de datos o administrador de tabla.
Ingesta de procesamiento por lotes frente a ingesta de streaming
La ingesta de procesamiento por lotes realiza el procesamiento por lotes de los datos y está optimizada para lograr un alto rendimiento de la ingesta. Este método es el tipo de ingesta preferido y de mayor rendimiento. Los datos se procesan por lotes en función de las propiedades de la ingesta. Se combinan y optimizan pequeños lotes de datos para agilizar los resultados de la consulta. La directiva de procesamiento por lotes de la ingesta se puede establecer en bases de datos o en tablas. De forma predeterminada, el valor máximo del procesamiento por lotes es de 5 minutos, 1000 elementos o un tamaño total de 1 GB. El límite de tamaño de los datos para un comando de ingesta por lotes es de 4 GB.
Ingesta en streaming es la ingesta de datos en curso desde un origen de streaming. La ingesta de streaming permite una latencia casi en tiempo real para pequeños conjuntos pequeños de datos por tabla. En un principio, los datos se ingieren en el almacén de filas y posteriormente se mueven a las extensiones del almacén de columnas.
Métodos y herramientas de ingesta
El Explorador de datos de Azure Synapse admite varios métodos de ingesta, cada uno con sus propios escenarios de destino. Estos métodos incluyen herramientas de ingesta, conectores y complementos para diversos servicios, canalizaciones administradas, ingesta mediante programación mediante distintos SDK y acceso directo a la ingesta.
Ingesta mediante canalizaciones administradas
Para aquellas organizaciones que deseen que sea un servicio externo el que realice la administración (límites, reintentos, supervisiones, alertas, etc.), es probable que un conector sea la solución más adecuada. La ingesta en cola es apropiada para grandes volúmenes de datos. El Explorador de datos de Azure Synapse admite las siguientes instancias de Azure Pipelines:
- Centro de eventos : una canalización que transfiere eventos de los servicios al Explorador de datos de Azure Synapse. Para más información, consulte Ingesta de datos del centro de eventos en el Explorador de datos de Azure Synapse.
- Canalizaciones de Synapse: un servicio de integración de datos totalmente administrado para cargas de trabajo analíticas en canalizaciones de Synapse se conecta con más de 90 orígenes admitidos para proporcionar una transferencia de datos eficaz y resistente. Las canalizaciones de Synapse preparan, transforman y enriquecen los datos para proporcionar información que se puede supervisar de varias formas. Este servicio se puede usar como solución de un solo uso, en una escala de tiempo periódica o desencadenada por eventos específicos.
Ingesta mediante programación mediante SDK
El Explorador de datos de Azure Synapse proporciona SDK que pueden usarse para la consulta e ingesta de datos. La ingesta mediante programación está optimizada para reducir los costos de ingesta (COG), minimizando las transacciones de almacenamiento durante y después del proceso de ingesta.
Antes de empezar, siga estos pasos para obtener los puntos de conexión del grupo del Explorador de datos para configurar la ingesta mediante programación.
En Synapse Studio, en el panel izquierdo, seleccione Administrar>Grupos exploradores de datos.
Seleccione el grupo explorador de datos que desee utilizar para ver los detalles.
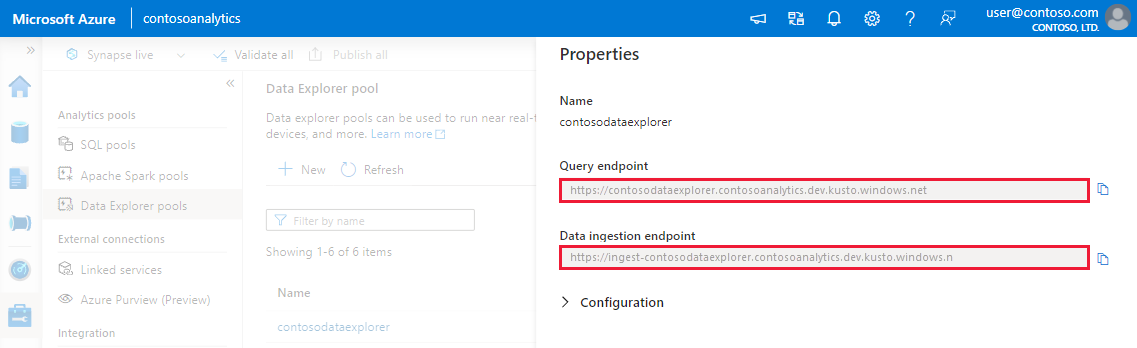
Anote los puntos de conexión de consulta e ingesta de datos. Utilice el punto de conexión de consulta como clúster al configurar las conexiones con el grupo explorador de datos. Al configurar los SDK para la ingesta de datos, use el punto de conexión de ingesta de datos.
SDK y proyectos de código abierto disponibles
Herramientas
- Ingesta con un solo clic : permite ingerir datos rápidamente mediante la creación y ajuste de tablas a partir de una amplia gama de tipos de origen. La ingesta con un solo clic sugiere tablas y estructuras de asignación automáticamente en función del origen de datos del Explorador de datos de Azure Synapse. La ingesta con un solo clic se puede usar para la ingesta puntual, o bien para definir una ingesta continua a través de Event Grid en el contenedor en el que se han ingerido los datos.
Comandos de control de ingesta del lenguaje de consulta de Kusto
Hay varios métodos por los que los datos se pueden ingerir directamente al motor mediante los comandos del lenguaje de consulta de Kusto (KQL). Dado que este método omite los servicios de Administración de datos, solo es adecuado para la exploración y la creación de prototipos. No se debe usar en escenarios de producción o de gran volumen.
Ingesta insertada: se envía un comando de control .ingest inline al motor y los datos que se van a ingerir forman parte del propio texto del comando. Este método está pensado para la realización de pruebas improvisadas.
Ingesta desde consulta: se envía un comando de control .set, .append, .set-or-append o .set-or-replace al motor y los datos se especifican indirectamente como los resultados de una consulta o un comando.
Ingesta desde almacenamiento (extracción) : se envía un comando de control .ingest into al motor con los datos almacenados en algún almacenamiento externo (por ejemplo, Azure Blob Storage) al que el motor puede acceder y al que el comando señala.
Para ver un ejemplo del uso de comandos de control de ingesta, consulte Análisis con el Explorador de datos.
Proceso de ingesta
Una vez que haya elegido el método de ingesta que más se ajuste a sus necesidades, siga estos pasos:
Establecimiento de una directiva de retención
Los datos ingeridos en una tabla del Explorador de datos de Azure Synapse están sujetos a la directiva de retención vigente de la tabla. Salvo que la directiva de retención vigente se establezca explícitamente en una tabla, deriva de la directiva de retención de la base de datos. La retención activa es una función del tamaño del clúster y de la directiva de retención. Si el espacio disponible es insuficiente para la cantidad de datos que se ingieren se obligará a realizar una retención esporádica de los primeros datos.
Asegúrese de que la directiva de retención de la base de datos se ajusta a sus necesidades. Si no es así, anúlela explícitamente en el nivel de tabla. Para más información, consulte Directiva de retención.
de una tabla
Para poder ingerir datos, es preciso crear una tabla con antelación. Use una de las siguientes opciones:
Cree una tabla con un comando. Para ver un ejemplo del uso del comando de creación de una tabla, consulte Análisis con el Explorador de datos.
Cree una tabla con ingesta con un solo clic.
Nota
Si un registro está incompleto o un campo no se puede analizar como tipo el de datos necesarios, las columnas de tabla correspondientes se rellenará con valores nulos.
Creación de la asignación de esquemas
La asignación de esquemas ayuda a enlazar los campos de datos de origen a las columnas de la tabla de destino. La asignación permite tomar datos de distintos orígenes en la misma tabla, en función de los atributos definidos. Se admiten diferentes tipos de asignaciones, tanto orientadas a filas (CSV, JSON y AVRO) como orientadas a columnas (Parquet). En la mayoría de los métodos, las asignaciones también se pueden crear previamente en la tabla y hacer referencia a ellas desde el parámetro de comando de ingesta.
Establecimiento de una directiva de actualización (opcional)
Algunas de las asignaciones de formato de datos (Parquet, JSON y Avro) admiten transformaciones sencillas y útiles en el momento de la ingesta. Si el escenario requiere un procesamiento más complejo en el momento de la ingesta, use la directiva de actualización, lo que permite el procesamiento ligero mediante los comandos del lenguaje de consulta de Kusto. La directiva de actualización ejecuta automáticamente extracciones y transformaciones en los datos ingeridos en la tabla original e ingiere los datos resultantes en una o varias tablas de destino. Establezca la directiva de actualización.