Funcionamiento de la conmutación por error planeada administrada por el cliente (versión preliminar)
La recuperación ante la conmutación por error planeada y administrada por el cliente puede ser útil en situaciones como la comprobación y planificación de desastres y recuperación, la corrección proactiva de desastres a gran escala previstos y las interrupciones no relacionadas con el almacenamiento.
Durante el proceso de conmutación por error planeada, se intercambian las regiones principales y secundarias de la cuenta de almacenamiento. La región primaria original es degradada y se convierte en la nueva secundaria, mientras que la región secundaria original es ascendida y se convierte en la nueva primaria. La cuenta de almacenamiento debe estar disponible en ambas regiones, principal y secundaria, para poder iniciar una conmutación por error planeada.
En este artículo se describe lo que ocurre durante una conmutación por recuperación y conmutación por error planeada y administrada por el cliente en cada fase del proceso. Para comprender cómo funciona una conmutación por error debido a una interrupción inesperada del punto de conexión de almacenamiento, consulta Funcionamiento de una conmutación por error administrada por el cliente (no planeada).
Importante
La conmutación por error planeada administrada por el cliente se encuentra actualmente en VERSIÓN PRELIMINAR y está limitada a las regiones siguientes:
- Este de Asia
- Sudeste de Asia
- Este de Australia
- Sudeste de Australia
- Centro de Francia
- Sur de Francia
- India central
- India occidental
- Oeste de Suiza
- Norte de Suiza
Para participar en la característica en vista previa (gb), consulte Configuración de características en versión preliminar en la suscripción de Azure y especifique AllowSoftFailover como nombre de la característica. El nombre del proveedor de esta característica en versión preliminar es Microsoft.Storage.
Consulte Términos de uso complementarios para las versiones preliminares de Microsoft Azure para conocer los términos legales que se aplican a las características de Azure que se encuentran en la versión beta, en versión preliminar o que todavía no se han publicado para que estén disponibles con carácter general.
Importante
Después de una conmutación por error planificada, es posible que el valor de la última fecha de sincronización (LST) de una cuenta de almacenamiento aparezca obsoleto o se notifique como NULL cuando los datos de Azure Files estén presentes.
Las instantáneas del sistema se crean periódicamente en la región secundaria de una cuenta de almacenamiento para mantener la coherencia de los puntos de recuperación utilizados durante la conmutación por error y la conmutación por recuperación. El inicio de la conmutación por error planeada administrada por el cliente hace que la región primaria original se convierta en la nueva secundaria. En algunos casos, no hay instantáneas del sistema disponibles en la nueva región secundaria tras la finalización de la conmutación por error planeada, lo que provoca que el valor global de LST de la cuenta parezca obsoleto o se muestre como Null.
Dado que las actividades del usuario, como crear, modificar o eliminar objetos, pueden desencadenar la creación de instantáneas, cualquier cuenta en la que se produzcan estas actividades después de la conmutación por error planeada no requerirá atención adicional. Sin embargo, las cuentas que no tengan instantáneas ni actividad de usuario pueden seguir mostrando un valor de Null LST hasta que se active la creación de instantáneas del sistema.
Si es necesario, realice una de las siguientes actividades para cada recurso compartido dentro de una cuenta de almacenamiento para desencadenar la creación de instantáneas. Tras la finalización, la cuenta debe mostrar un valor LST válido en un plazo de 30 minutos.
- Monta el recurso compartido y luego abre cualquier archivo para leerlo.
- Carga un archivo de prueba o de ejemplo en el recurso compartido.
Administración de redundancia durante la conmutación por recuperación y la conmutación por error planeada
Sugerencia
Para comprender los distintos estados de redundancia durante el proceso de conmutación por error y conmutación por recuperación administrada por el cliente, consulta Redundancia de Azure Storage para ver las definiciones de cada una.
Durante el proceso de conmutación por error planeada, los puntos de conexión del servicio de almacenamiento de la región principal se convierten en de solo lectura mientras las actualizaciones restantes finalizan la replicación en la región secundaria. A continuación, se cambian todas las entradas del servicio de nombres de dominio (DNS) del punto de conexión de servicio de almacenamiento. Los puntos de conexión secundarios de la cuenta de almacenamiento se convierten en los nuevos puntos de conexión principales y los puntos de conexión principales originales se convierten en el nuevo secundario. La replicación de datos dentro de cada región permanece sin cambios aunque se cambien las regiones primarias y secundarias.
El proceso de conmutación por recuperación planeada es básicamente el mismo que el proceso de conmutación por error planeada, pero con una excepción. Durante la conmutación por recuperación planeada, Azure almacena la configuración de redundancia original de la cuenta de almacenamiento y la restaura a su estado original tras la conmutación por recuperación. Por ejemplo, si la cuenta de almacenamiento se ha configurado originalmente como GZRS, la cuenta de almacenamiento será GZRS después de la conmutación por recuperación.
Nota:
A diferencia de conmutación por error administrada por el cliente (no planeada), durante la conmutación por error planeada, la replicación de la región principal a secundaria debe completarse antes de que las entradas DNS de los puntos de conexión se cambien a la nueva secundaria. Por este motivo, no se espera la pérdida de datos durante la conmutación por error planeada o la conmutación por recuperación siempre que las regiones principales y secundarias estén disponibles en todo el proceso.
Cómo iniciar una conmutación por error
Para obtener información sobre cómo iniciar una conmutación por error, consulta Iniciación de una conmutación por error de una cuenta.
Proceso de conmutación por recuperación y conmutación por error planeada
En los diagramas siguientes se muestra lo que sucede durante una conmutación por error planeada administrada por el cliente y la conmutación por recuperación de una cuenta de almacenamiento.
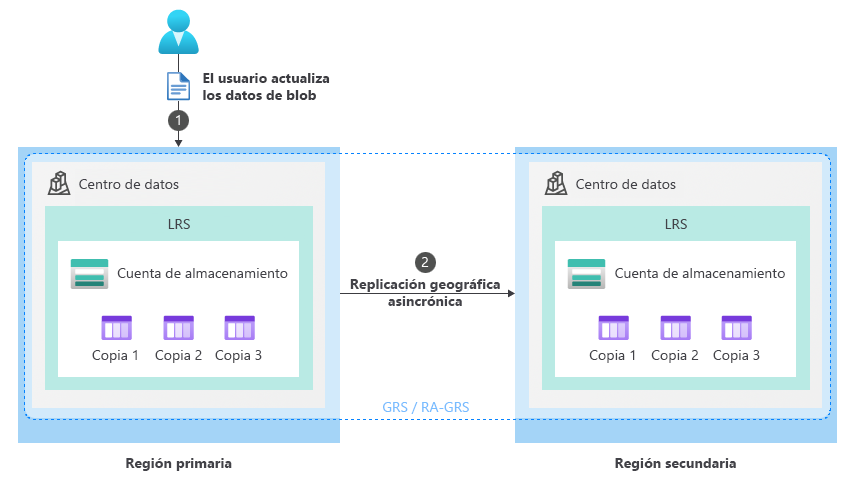
En circunstancias normales, un cliente escribe datos en una cuenta de almacenamiento de la región primaria a través de puntos de conexión de servicio de almacenamiento (1). Los datos se copian de forma asincrónica de la región primaria a la región secundaria (2). En la imagen siguiente se muestra el estado normal de una cuenta de almacenamiento configurada como GRS:

El proceso de conmutación por error planeada (GRS/RA-GRS)
Inicie las pruebas de recuperación ante desastres iniciando una conmutación por error de la cuenta de almacenamiento en la región secundaria. A continuación, se describen los pasos del proceso de conmutación por error planeado y la imagen siguiente se proporciona como ilustración:
- La región primaria pierde temporalmente el acceso de lectura y escritura. Los usuarios de RA-GRS o RA-GZRS seguirán teniendo acceso de lectura a su región secundaria.
- Se completa la replicación de todos los datos de la región primaria a la región secundaria.
- Las entradas DNS para los puntos de conexión de servicio de almacenamiento en la región secundaria se promueven y se convierten en los nuevos puntos de conexión principales de la cuenta de almacenamiento.
Por lo general, la conmutación por error tarda aproximadamente una hora.

Una vez completada la conmutación por error, la región primaria original se convierte en la nueva secundaria (1), y la región secundaria original se convierte en la nueva principal (2). Los URI de los puntos de conexión de servicio de almacenamiento para blobs, tablas, colas y archivos siguen siendo los mismos, pero sus entradas DNS se cambian para que apunten a la nueva región primaria (3). Los usuarios pueden reanudar la escritura de datos en la cuenta de almacenamiento en la nueva región primaria, y los datos se copian de forma asincrónica en la nueva secundaria (4), como se muestra en la siguiente imagen:

Mientras se encuentra en estado de conmutación por error, realice las pruebas de recuperación ante desastres.
El proceso de conmutación por recuperación planeada (GRS/RA-GRS)
Una vez completada la prueba, realice otra conmutación por error para la conmutación por recuperación a la región primaria original. Durante el proceso de conmutación por error, como se muestra en la siguiente imagen:
- La región primaria pierde temporalmente el acceso de lectura y escritura. Los usuarios de RA-GRS o RA-GZRS seguirán teniendo acceso de lectura a su región secundaria.
- Todos los datos terminan de replicarse desde la región primaria actual a la región secundaria actual.
- Las entradas DNS de los puntos de conexión de servicio de almacenamiento se cambian para que apunten a la región que era la principal antes de realizar la conmutación por error inicial.
La conmutación por recuperación suele tardar aproximadamente una hora.

Una vez completada la conmutación por recuperación, la cuenta de almacenamiento se restaura a su configuración de redundancia original. Los usuarios pueden reanudar la escritura de datos en la cuenta de almacenamiento en la región primaria original (1) mientras que la replicación en la secundaria original (2) continúa como antes de la conmutación por error: