Administración de consumo y carga de recursos en Service Fabric con métricas
Métricas son los recursos por los que se interesan sus servicios y que proporcionan los nodos del clúster. Una métrica es cualquier cosa que debe administrar para mejorar o supervisar el rendimiento de los servicios. Por ejemplo, podría observar el consumo de memoria para saber si el servicio está sobrecargado. Otro uso es averiguar si el servicio se podría mover a cualquier otro lugar en el que la memoria esté menos restringida, para poder obtener un mejor rendimiento.
Las métricas son, por ejemplo, memoria, disco y uso de CPU. Estas son métricas físicas, recursos que corresponden a los recursos físicos en el nodo que es necesario administrar. Las métricas también pueden ser (y normalmente son) métricas lógicas. Las métricas lógicas son, por ejemplo, "MyWorkQueueDepth", "MessagesToProcess" o "TotalRecords". Las métricas lógicas están definidas por la aplicación, e indirectamente corresponden al consumo de algunos recursos físicos. Las métricas lógicas son comunes porque la medición y notificación del consumo de recursos físicos en base a cada servicio puede resultar difícil de realizar. La complejidad de la medición y la generación de informes de sus propias métricas físicas es también la causa de que Service Fabric incluya algunas métricas predeterminadas.
Métricas predeterminadas
Supongamos que desea empezar a escribir e implementar un servicio. En este momento no sabe qué recursos físicos o lógicos consume. ¡Eso está bien! Cluster Resource Manager de Service Fabric utiliza algunas de las métricas predeterminadas si no se ha especificado ninguna otra métrica. Son las siguientes:
- PrimaryCount: el recuento de las réplicas principales en el nodo
- ReplicaCount: el recuento de todas las réplicas con estado en el nodo
- Count: el recuento de todos los objetos de servicio (con y sin estado) en el nodo
| Métrica | Carga de instancia sin estado | Carga secundaria con estado | Carga principal con estado | Peso |
|---|---|---|---|---|
| PrimaryCount | 0 | 0 | 1 | Alto |
| ReplicaCount | 0 | 1 | 1 | Media |
| Count | 1 | 1 | 1 | Bajo |
Para cargas de trabajo básicas, las métricas predeterminadas proporcionan una distribución apropiada del trabajo en el clúster. En el siguiente ejemplo, vamos a ver lo que sucede cuando se crean dos servicios y se confía en las métricas predeterminadas para mantener el equilibrio. El primero es un servicio con estado con tres particiones y un conjunto de tres réplicas de destino. El segundo es un servicio sin estado con una partición y un recuento de instancias de tres.
Esto es lo que obtiene:
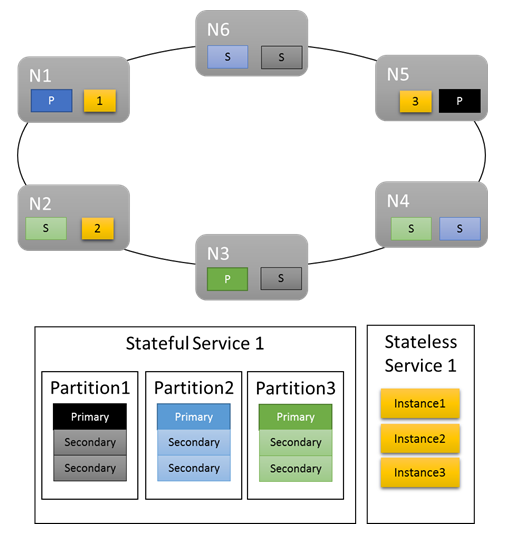
Cosas que tener en cuenta:
- Las réplicas principales para el servicio con estado se distribuyen entre varios nodos
- Las réplicas de la misma partición están en distintos nodos
- El número total de réplicas principales y secundarias está distribuido en el clúster.
- La asignación del número total de objetos de servicio es uniforme en cada nodo.
¡Bien!
Las métricas predeterminadas funcionan correctamente como lugar de partida. Pero estas métricas predeterminadas tienen una utilidad limitada. Por ejemplo: ¿Cuál es la probabilidad de que el esquema de partición que elija dé como resultado una utilización perfectamente uniforme de todas las particiones? ¿Cuál es la probabilidad de que la carga de un servicio dado se mantenga constante en el tiempo, o incluso que sea la misma en varias particiones ahora mismo?
Puede trabajar solo con las métricas predeterminadas. De todas forma, si lo hace, normalmente significa que la utilización del clúster será inferior y más desigual de lo deseable. Esto se debe a que las métricas predeterminadas no son adaptables y presuponen que todo es equivalente. Por ejemplo, un elemento principal que está ocupado y otro que no lo está, ambos contribuyen con "1" en la métrica de PrimaryCount. En el peor de los casos, usar solo las métricas predeterminadas puede producir una sobrecarga en los nodos y problemas de rendimiento. Si está interesado en obtener el máximo partido de su clúster y evitar problemas de rendimiento, tiene que usar métricas personalizadas e informes de carga dinámica.
Métricas personalizadas
Las métricas se configuran para cada instancia de servicio con nombre cuando se crea el servicio.
Todas las métricas tienen algunas propiedades que las describen: un nombre, un peso y una carga predeterminada.
- Nombre de la métrica: El nombre de la métrica. El nombre de la métrica es un identificador único de la métrica en el clúster desde la perspectiva de Resource Manager.
Nota
El nombre de la métrica personalizada no debe ser ninguno de los nombres de métricas del sistema, es decir, servicefabric:/_CpuCores o servicefabric:/_MemoryInMB, ya que puede dar lugar a un comportamiento indefinido. A partir de la versión 9.1 de Service Fabric, para los servicios existentes con estos nombres de métricas personalizados, se emite una advertencia de estado para indicar que el nombre de la métrica es incorrecto.
- Peso: el peso de la métrica define su importancia con relación a las demás métricas de este servicio.
- Carga predeterminada: la carga predeterminada se representa de forma distinta dependiendo de si el servicio es con o sin estado.
- Para los servicios sin estado, cada métrica tiene una propiedad única llamada DefaultLoad.
- Para servicios con estado, se define lo siguiente:
- PrimaryDefaultLoad: cantidad predeterminada de la métrica que este servicio consume cuando es principal.
- SecondaryDefaultLoad: cantidad predeterminada de la métrica que este servicio consume cuando es secundario.
Nota
Si define métricas personalizadas y desea usar también las métricas predeterminadas, tiene que volver a agregar estas últimas de forma explícita. Esto es así porque tiene que definir claramente la relación entre las métricas predeterminadas y sus métricas personalizadas. Por ejemplo, puede que le preocupen más las métricas ConnectionCount o WorkQueueDepth que las de distribución principal. De forma predeterminada el peso de la métrica PrimaryCount es alto pero debe reducirlo a medio cuando agregue sus otras métricas, para asegurarse de que estas tienen prioridad.
Definición de las métricas del servicio: ejemplo
Supongamos que desea la configuración siguiente:
- El servicio notifica una métrica denominada "ConnectionCount"
- También quiere usar las métricas predeterminadas
- Ha realizado algunas mediciones y sabe que, normalmente, una réplica principal de ese servicio ocupa hasta 20 unidades de "ConnectionCount"
- Por su parte las secundarias usan 5 unidades de "ConnectionCount"
- Sabe que "ConnectionCount" es la métrica más importante en cuanto a la administración del rendimiento de este servicio en concreto
- Pero también desea que las réplicas principales estén equilibradas. Mantener el equilibrio de las réplicas principales suele ser siempre una buena idea. Esto ayuda a evitar que la pérdida de algún nodo o dominio de error afecte a la mayoría de las réplicas principales.
- Por lo demás, las métricas predeterminadas están bien
Este es el código que debe escribir para crear un servicio con esa configuración de métricas:
Código:
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
StatefulServiceLoadMetricDescription connectionMetric = new StatefulServiceLoadMetricDescription();
connectionMetric.Name = "ConnectionCount";
connectionMetric.PrimaryDefaultLoad = 20;
connectionMetric.SecondaryDefaultLoad = 5;
connectionMetric.Weight = ServiceLoadMetricWeight.High;
StatefulServiceLoadMetricDescription primaryCountMetric = new StatefulServiceLoadMetricDescription();
primaryCountMetric.Name = "PrimaryCount";
primaryCountMetric.PrimaryDefaultLoad = 1;
primaryCountMetric.SecondaryDefaultLoad = 0;
primaryCountMetric.Weight = ServiceLoadMetricWeight.Medium;
StatefulServiceLoadMetricDescription replicaCountMetric = new StatefulServiceLoadMetricDescription();
replicaCountMetric.Name = "ReplicaCount";
replicaCountMetric.PrimaryDefaultLoad = 1;
replicaCountMetric.SecondaryDefaultLoad = 1;
replicaCountMetric.Weight = ServiceLoadMetricWeight.Low;
StatefulServiceLoadMetricDescription totalCountMetric = new StatefulServiceLoadMetricDescription();
totalCountMetric.Name = "Count";
totalCountMetric.PrimaryDefaultLoad = 1;
totalCountMetric.SecondaryDefaultLoad = 1;
totalCountMetric.Weight = ServiceLoadMetricWeight.Low;
serviceDescription.Metrics.Add(connectionMetric);
serviceDescription.Metrics.Add(primaryCountMetric);
serviceDescription.Metrics.Add(replicaCountMetric);
serviceDescription.Metrics.Add(totalCountMetric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ConnectionCount,High,20,5”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Nota:
Los ejemplos anteriores y el resto de este documento describen la administración de las métricas en base a cada uno de los servicios designados. También es posible definir las métricas para los servicios en el nivel de tipo de servicio. Esto se consigue especificándolos en los manifiestos de servicio. No se recomienda definir las métricas de nivel de tipo por varias razones. El primer motivo es que los nombres de métrica son frecuentemente específicos del entorno. A menos que haya un contrato firme, no puede estar seguro de que la métrica "Cores" de un entorno no es "MiliCores" o "CoReS" en otros. Si las métricas se definen en el manifiesto, tiene que crear nuevos manifiestos por cada entorno. Esto suele dar lugar al proliferación de manifiestos diferentes con solo pequeñas diferencias, lo que puede provocar problemas de administración.
Las cargas de métricas normalmente se asignan en base a cada instancia de servicio denominado. Por ejemplo, supongamos que crea una instancia del servicio para el ClienteA que tiene previsto usarlo de forma muy ligera. Supongamos también que crea otra instancia para el ClienteB que tiene una mayor carga de trabajo. En este caso, probablemente deba ajustar las cargas predeterminadas para esos servicios. Si tiene métricas y cargas definidas a través de manifiestos y desea crear el soporte adecuado para este escenario, necesita diferentes tipos de servicio y aplicación para cada cliente. Los valores definidos en el momento de creación del servicio reemplazan a aquellos definidos en el manifiesto, por lo que puede usar esto para establecer los valores predeterminados específicos. Sin embargo, esto hace que los valores declarados en los manifiestos no coincidan con los valores con los que se ejecuta el servicio. Esto puede crear confusión.
Recuerde: si solo desea utilizar las métricas predeterminadas, no necesita tocar la colección de métricas en absoluto, ni hacer nada especial al crear el servicio. Las métricas predeterminadas se usan automáticamente cuando no hay otras definidas.
Ahora, vamos a analizar en detalle cada uno de estos valores y a hablar sobre los comportamientos en los que influyen.
Cargar
La razón fundamental de la definición de las métricas es la representación de cierta carga. Carga es la cantidad de una determinada métrica que alguna instancia del servicio o réplica consume en un nodo específico. El valor Carga puede configurarse prácticamente en cualquier momento. Por ejemplo:
- Carga se puede definir cuando se crea un servicio. Este tipo de configuración de carga se denomina carga predeterminada.
- La información de la métrica, incluidas las cargas predeterminadas, para un servicio puede actualizarse después de crear el servicio. Esta actualización de la métrica se realiza al actualizar un servicio
- Las cargas para una partición determinada pueden restablecerse a los valores predeterminados para ese servicio. y se denomina restablecimiento de la carga de partición.
- La carga se puede notificar en base a cada objeto de servicio de forma dinámica durante el tiempo de ejecución. Esta actualización de la métrica se denomina notificación de la carga.
- La carga de las instancias o réplicas de la partición también se puede actualizar mediante la notificación de los valores de carga a través de una llamada API de Fabric. Esta actualización de la métrica se denomina notificación de la carga para una partición.
Todas estas estrategias pueden usarse dentro del mismo servicio durante su vigencia.
Carga predeterminada
Carga predeterminada es la cantidad de métrica que consume cada objeto de servicio (instancia sin estado o réplica con estado) de este servicio. Cluster Resource Manager utiliza este número para la carga del objeto de servicio hasta que recibe otra información, como un informe dinámico de carga. Para los servicios más sencillos, la carga predeterminada es una definición estática. La carga predeterminada nunca se actualiza y se utiliza durante la vigencia del servicio. Las cargas predeterminadas funcionan bien para escenarios de planeamiento simples donde se dedican determinadas cantidades de recursos a las distintas cargas de trabajo sin cambios.
Nota
Para más información sobre la administración de capacidad y la definición de capacidades para los nodos del clúster, consulte este artículo.
Cluster Resource Manager permite a los servicios con estado especificar una carga predeterminada diferente para sus instancias principales y secundarias. Los servicios sin estado solo pueden especificar un valor para aplicarlo a todas las instancias. Para los servicios con estado, la carga predeterminada para las réplicas principales y secundarias son normalmente diferentes porque las réplicas realizan diferentes tipos de trabajo en cada rol. Por ejemplo, las réplicas principales atienden normalmente lecturas y escrituras, así como la mayoría de la carga de cálculo, mientras que las secundarias no. Normalmente, la carga predeterminada para una réplica principal es mayor que la carga predeterminada para las réplicas secundarias. Los números reales deben depender de sus propias medidas.
Carga dinámica
Supongamos que lleva un tiempo ejecutando el servicio. Con cierta supervisión, habrá observado lo siguiente:
- Algunas particiones o instancias de un servicio determinado consumen más recursos que otras.
- Algunos servicios tienen cargas que varían con el tiempo.
Hay una gran cantidad de cosas que podrían causar estos tipos de fluctuaciones de la carga. Por ejemplo, diferentes servicios o particiones están asociadas con diferentes clientes con requisitos diferentes. La carga también puede cambiar porque la cantidad de trabajo que el servicio realiza varía a lo largo del día. Independientemente del motivo, generalmente no hay una sola cifra que se pueda usar para el valor predeterminado. Esto es especialmente cierto si desea obtener el mayor uso posible del clúster. Cualquier valor que elija como carga predeterminada será incorrecto en algún momento. Las cargas predeterminadas incorrectas hacen que Cluster Resource Manager asigne al servicio recursos o bien en exceso o insuficientes. Como resultado habrá nodos infrautilizados o usados en exceso, aunque Cluster Resource Manager piense que el clúster está equilibrado. Las cargas predeterminadas siguen siendo buenas porque proporcionan cierta información para la ubicación inicial, pero no cuentan la historia completa de las cargas de trabajo reales. Con el fin de capturar los requisitos cambiantes del recurso de forma de precisa, Cluster Resource Manager permite que cada objeto de servicio actualice su propia carga en tiempo de ejecución. Esto se llama informes de carga dinámica.
Los informes de carga dinámica permiten a las réplicas o instancias ajustar su asignación o la carga de métricas notificada mientras estén vigentes. Normalmente, una instancia o una réplica del servicio que estaba inactiva y sin realizar ningún trabajo informará de que usó poca cantidad de una métrica determinada. Una réplica o instancia ocupadas indicarían que están usando más.
Los informes de carga por instancia o réplica permiten que Cluster Resource Manager reorganice los objetos de servicio individuales en el clúster. La reorganización de los servicios ayuda a garantizar que obtienen los recursos que necesitan. Los servicios ocupados “reclaman” recursos de otras réplicas o instancias que están actualmente inactivas o realizando menos trabajo.
En Reliable Services, el código para notificar la carga dinámicamente es similar al siguiente:
Código:
this.Partition.ReportLoad(new List<LoadMetric> { new LoadMetric("CurrentConnectionCount", 1234), new LoadMetric("metric1", 42) });
Un servicio puede informar sobre cualquiera de las métricas definidas para él en tiempo de creación. Si un servicio informa sobre carga para una medida que no está configurada para usar, Service Fabric omite ese informe. Si se notifican al mismo tiempo otras métricas válidas, dichos informes se aceptan. El código de servicio puede medir y notificar todas las métricas que sabe cómo manejar, y los operadores pueden especificar la configuración de la métrica a usar, sin tener que cambiar el código de servicio.
Notificación de la carga para una partición
En la sección anterior se describe cómo se cargan el informe de instancias o las réplicas de servicio. Hay una opción adicional para notificar dinámicamente la carga de las réplicas o instancias de una partición a través de la API de Service Fabric. Al notificar la carga de una partición, puede notificar varias particiones a la vez.
Estos informes se utilizarán de la misma manera que los informes de carga que proceden de las propias réplicas o instancias. Los valores notificados serán válidos hasta que se notifiquen los nuevos valores de carga, ya sea mediante la réplica o la instancia o con la notificación de un nuevo valor de carga para una partición.
Con esta API, hay varias maneras de actualizar la carga en el clúster:
- Una partición de servicio con estado puede actualizar su carga de réplica principal.
- Los servicios con y sin estado pueden actualizar la carga de todas sus instancias o réplicas secundarias.
- Los servicios con y sin estado pueden actualizar la carga de una instancia o réplica específica o una instancia en un nodo.
También es posible combinar cualquiera de esas actualizaciones por partición al mismo tiempo. La combinación de actualizaciones de carga para una partición determinada debe especificarse a través del objeto PartitionMetricLoadDescription, que puede contener la lista correspondiente de actualizaciones de carga, como se muestra en el ejemplo siguiente. Las actualizaciones de carga se representan a través del objeto MetricLoadDescription, que puede contener el valor de carga actual o previsto para una métrica, especificado con un nombre de métrica.
Nota
Actualmente, los valores previstos de carga de métricas es una característica en vista previa. Permite notificar y usar los valores de carga previstos en el lado Service Fabric, pero esa característica no está habilitada actualmente.
Las cargas de varias particiones se pueden actualizar con una sola llamada API, en cuyo caso la salida contendrá una respuesta por partición. Si la actualización de particiones no se aplica correctamente por algún motivo, se omitirán las actualizaciones de esa partición y se proporcionará el código de error correspondiente para una partición de destino:
- PartitionNotFound: el id. de la partición especificado no existe.
- ReconfigurationPending: la partición se está volviendo a configurar.
- InvalidForStatelessServices: se intentó cambiar la carga de una réplica principal para una partición que pertenece a un servicio sin estado.
- ReplicaDoesNotExist: la réplica o instancia secundaria no existe en un nodo especificado.
- InvalidOperation: podría ocurrir en los dos casos siguientes: al actualizar la carga de una partición que pertenece a la aplicación del sistema o cuando la actualización de la carga de predicción no está habilitada.
Si se devuelven algunos de estos errores, puede actualizar la entrada de una partición específica y volver a intentar la actualización.
Código:
Guid partitionId = Guid.Parse("53df3d7f-5471-403b-b736-bde6ad584f42");
string metricName0 = "CustomMetricName0";
List<MetricLoadDescription> newPrimaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 100)
};
string nodeName0 = "NodeName0";
List<MetricLoadDescription> newSpecificSecondaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 200)
};
OperationResult<UpdatePartitionLoadResultList> updatePartitionLoadResults =
await this.FabricClient.UpdatePartitionLoadAsync(
new UpdatePartitionLoadQueryDescription
{
PartitionMetricLoadDescriptionList = new List<PartitionMetricLoadDescription>()
{
new PartitionMetricLoadDescription(
partitionId,
newPrimaryReplicaLoads,
new List<MetricLoadDescription>(),
new List<ReplicaMetricLoadDescription>()
{
new ReplicaMetricLoadDescription(nodeName0, newSpecificSecondaryReplicaLoads)
})
}
},
this.Timeout,
cancellationToken);
En este ejemplo, realizará una actualización de la última carga notificada para la partición 53df3d7f-5471-403b-b736-bde6ad584f42. La carga de la réplica principal de la métrica CustomMetricName0 se actualizará con el valor 100. Al mismo tiempo, la carga para la misma métrica de una réplica secundaria específica ubicada en el nodo NodeName0 se actualizará con el valor 200.
Actualización de la configuración de métrica de un servicio
La lista de métricas asociado con el servicio y las propiedades de esas métricas se pueden actualizar dinámicamente mientras el servicio está activo. Esto permite experimentación y flexibilidad. Algunos ejemplos de cuándo esto resulta útil son:
- deshabilitación de una métrica con un informe con errores para un servicio determinado
- reconfiguración del peso de las métricas en base al comportamiento deseado
- habilitación de una nueva métrica solo una vez que el código ya se haya implementado y validado a través de otros mecanismos
- cambio de la carga predeterminada para un servicio en base al comportamiento y consumo observados
Las API principales para cambiar la configuración de métrica están FabricClient.ServiceManagementClient.UpdateServiceAsync en C# y Update-ServiceFabricService en PowerShell. Cualquier información que se especifique con estas API reemplaza la información de métrica existente para el servicio inmediatamente.
Combinación de valores de carga predeterminados e informes de carga dinámica
La carga predeterminada y las cargas dinámicas pueden utilizarse para el mismo servicio. Cuando un servicio utiliza los informes tanto de carga predeterminada como de carga dinámica, la carga predeterminada actúa como una estimación hasta que aparecen los informes dinámicos. La carga predeterminada es útil porque proporciona a Cluster Resource Manager algo con lo que trabajar. La carga predeterminada permite a Cluster Resource Manager colocar los objetos de servicio en una buena ubicación cuando se crean. Si no se proporciona ninguna información de carga predeterminada, la ubicación de los servicios es aleatoria. Cuando más adelante llegan los informes de carga, la posición inicial aleatoria es frecuentemente incorrecta y Cluster Resource Manager tiene que mover los servicios.
Vamos a tomar nuestro ejemplo anterior y vemos qué sucede cuando se agregan algunas métricas personalizadas e informes de carga dinámicos. En este ejemplo, utilizamos "MemoryInMb" como una métrica de ejemplo.
Nota
La memoria es una de las métricas del sistema con la que Service Fabric puede regular los recursos, y que para usted suele ser difícil de notificar. No se espera que usted informe sobre el consumo de memoria; la memoria se utiliza aquí como una ayuda para aprender sobre las funcionalidades de Cluster Resource Manager.
Suponemos que inicialmente se ha creado el servicio con estado con el comando siguiente:
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("MemoryInMb,High,21,11”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Como recordatorio, esta sintaxis es ("MetricName, MetricWeight, PrimaryDefaultLoad, SecondaryDefaultLoad").
El aspecto de un diseño del clúster podría ser similar a este:
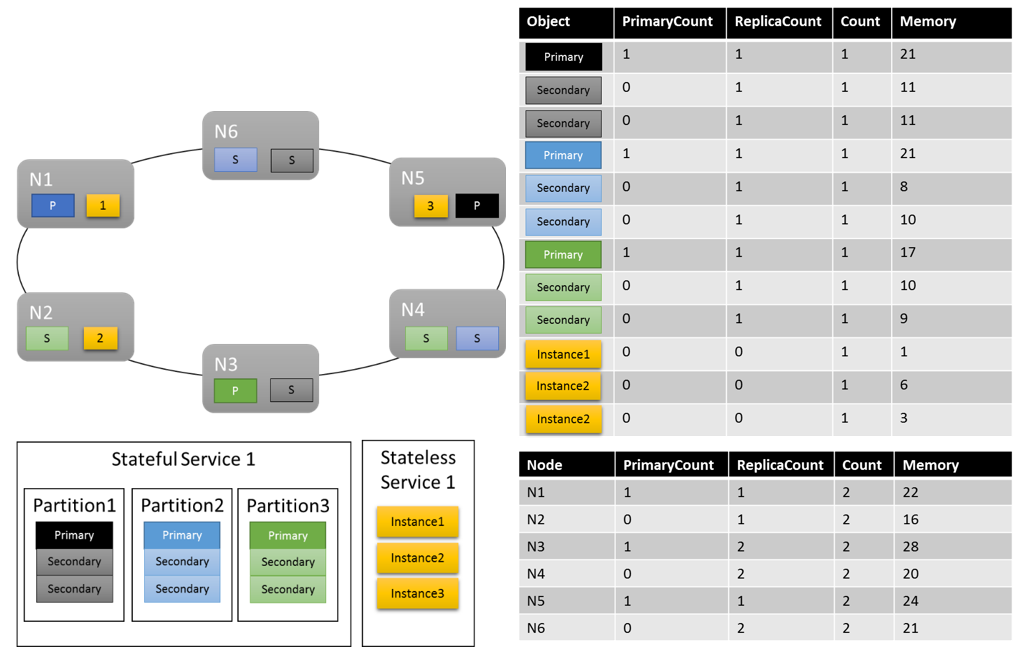
Algunas cosas que debe tener en cuenta:
- Las réplicas secundarias dentro de una partición pueden tener su propia carga cada una
- En general, las métricas parecen equilibradas. En el caso de la memoria, la proporción entre la carga máxima y mínima es 1,75 (el nodo con la mayor carga es N3, con la mínima es N2 y 28/16 = 1,75).
Hay algunas cosas aún que es necesario explicar:
- ¿Qué determinó si una relación de 1,75 era razonable o no? ¿Cómo sabe Cluster Resource Manager si eso es suficiente o si hay más trabajo que hacer?
- ¿Cuándo se produce el equilibrio?
- ¿Qué significa que la ponderación de Memoria es alta?
Pesos de métrica
Es importante realizar un seguimiento de las mismas métricas en los diferentes servicios. Esta vista global es la que permite que Cluster Resource Manager realice un seguimiento del consumo en el clúster, equilibre el consumo en todos los nodos y se asegure de que los nodos no exceden su capacidad. Sin embargo, los servicios pueden tener vistas diferentes en cuanto a la importancia de la misma métrica. Además, en un clúster con muchas métricas y una gran cantidad de servicios, puede que no existan soluciones perfectamente equilibradas para todas las métricas. ¿Cómo debe controlar Cluster Resource Manager estos casos?
La ponderación de las métricas permite a Cluster Resource Manager tomar decisiones sobre cómo equilibrar el clúster cuando no hay ninguna respuesta perfecta. La ponderación de las métricas también permite a Cluster Resource Manager equilibrar servicios específicos de manera diferente. Las métricas pueden tener cuatro niveles diferentes de peso: cero, bajo, medio y alto. Una métrica con un peso de cero no aporta nada a la hora de considerar si todo está equilibrado o no. Sin embargo, su carga contribuye a la administración de capacidad. Las métricas con un peso cero siguen siendo útiles y se utilizan con frecuencia como parte la supervisión del comportamiento y el rendimiento del servicio. En este artículo se proporciona más información sobre el uso de las métricas de supervisión y diagnóstico de los servicios.
El impacto real de las diferentes ponderaciones de métricas en el clúster es que Cluster Resource Manager genera diferentes soluciones. Las ponderaciones de las métricas indican a Cluster Resource Manager que ciertas métricas son más importantes que otras. Cuando no hay ninguna solución perfecta, Cluster Resource Manager puede preferir soluciones que equilibren mejor las métricas ponderadas. Si un servicio considera que una métrica no es importante, puede encontrar que su uso de esa métrica está desequilibrado. Esto permite que otro servicio obtenga una distribución uniforme de alguna métrica que es importante para él.
Echemos un vistazo a un ejemplo de algunos informes de carga y cómo pesos de métricas diferentes pueden generar distintas asignaciones en el clúster. En este ejemplo, se puede ver que cambiar el peso relativo de las métricas hace que Cluster Resource Manager cree diferentes disposiciones de los servicios.
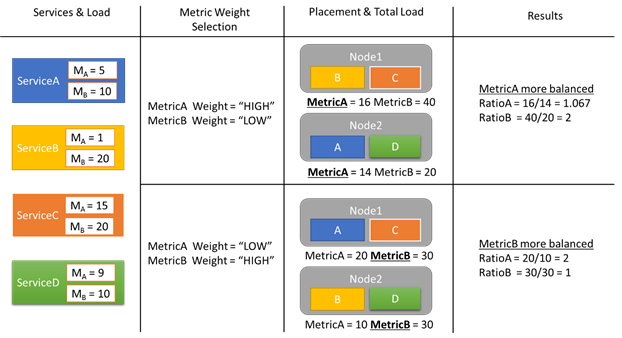
En este ejemplo, hay cuatro servicios diferentes, todos informando sobre valores diferentes para dos métricas diferentes, MetricA y MetricB. En un caso, todos los servicios definen a MetricA como la más importante (Peso = Alto) y a MetricB como no importante (Peso = Bajo). Como resultado, vemos que Cluster Resource Manager coloca los servicios de modo que MetricA está mejor equilibrada que MetricB. "Mejor equilibrada" significa que MetricA tiene una desviación estándar menor que MetricB. En el segundo caso, se invierten las ponderaciones de las métricas. Como resultado, Cluster Resource Manager intercambiaría los servicios A y B para conseguir una asignación en la que MetricB quede mejor equilibrada que MetricA.
Nota
Los pesos de las métricas determinan cómo se debe equilibrar Cluster Resource Manager, pero no cuándo se debe producir el equilibrio. Para más información sobre el equilibrio, consulte este artículo
Ponderaciones de métricas globales
Supongamos que ServiceA define MetricA con un peso alto y ServiceB establece el peso de MetricA en bajo o cero. ¿Cuál es el peso finalmente termina usándose?
En realidad, para cada métrica se realiza el seguimiento con varios pesos. El primer peso es el que se define para la métrica cuando se crea el servicio. El otro peso es un peso global, que se calcula automáticamente. Cluster Resource Manager usa ambos pesos para puntuar las soluciones. Es importante tener ambos pesos en cuenta. Esto permite que Cluster Resource Manager equilibre cada servicio según sus propias prioridades y asegura también que el clúster, como un todo, se asigna correctamente.
¿Qué ocurriría si Cluster Resource Manager no se preocupara por el equilibrio global y local? Bueno, es fácil crear soluciones que estén equilibradas globalmente, pero que tengan una asignación de recursos muy deficiente para los servicios individuales. En el siguiente ejemplo, vamos a echar un vistazo a un servicio configurado solamente con las métricas predeterminadas, y veamos qué sucede cuando solo se tiene en cuenta el equilibrio global:
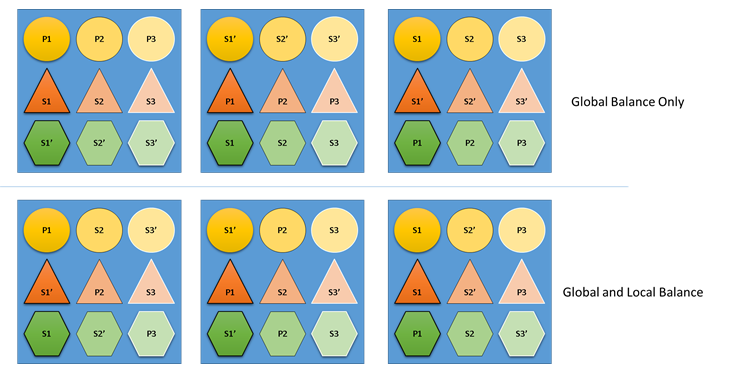
En el ejemplo de la parte superior, basado solamente en el equilibrio global, el clúster en conjunto está equilibrado. Todos los nodos tienen el mismo número de réplicas principales y el mismo número total de réplicas. Sin embargo, si examinamos el impacto real de esta asignación, no es tan bueno: la pérdida de cualquier nodo afecta a una determinada carga de trabajo desproporcionadamente, porque se lleva todas sus réplicas principales. Por ejemplo, si se produce un error en el primer nodo, se perderían las tres réplicas principales de las tres particiones diferentes del servicio Circle. Por el contrario, en los servicios Triangle y Hexagon sus particiones pierde una réplica. Esto apenas causa interrupciones, aparte de tener que recuperar la réplica perdida.
En el ejemplo inferior, Cluster Resource Manager ha distribuido las réplicas en función del equilibrio global y por servicio. Al calcular la puntuación de la solución, ofrece la mayor ponderación a la solución global, y una parte (configurable) a los servicios individuales. El equilibrio global de una métrica se calcula en función del promedio de los pesos de métricas para cada servicio. Cada servicio se equilibra según sus propias ponderaciones de métricas. Esto garantiza que los servicios están equilibrados dentro de sí mismos según sus propias necesidades. Como resultado, si se produce un error en el mismo primer nodo, el fallo se distribuye entre todas las particiones de todos los servicios. El impacto en cada una es el mismo.
Pasos siguientes
- Para más información acerca de cómo configurar servicios, lea sobre la configuración de servicios(service-fabric-cluster-resource-manager-configure-services.md)
- Definir las métricas de desfragmentación es una manera de consolidar la carga en los nodos en lugar de distribuirla. Para saber cómo configurar la desfragmentación, consulte este artículo
- Para más información sobre cómo Cluster Resource Manager administra y equilibra la carga en el clúster, consulte el artículo sobre el equilibrio de carga
- Empiece desde el principio y obtenga una introducción a Cluster Resource Manager de Service Fabric
- El costo del movimiento es una forma de señalizar al Administrador de recursos de clúster que determinados servicios son más caros de mover que otros. Para obtener más información sobre el costo del movimiento, consulte este artículo