Tutorial: Indexación de varios orígenes de datos mediante el SDK de .NET
Azure AI Search puede importar, analizar e indexar datos desde varios orígenes de datos en un único índice de búsqueda consolidado.
En este tutorial de C# se usa la biblioteca cliente de Azure.Search.Documents del SDK de Azure para .NET para indexar datos de hotel de ejemplo desde una instancia de Azure Cosmos DB y se combina con los detalles de la sala de hotel extraídos de los documentos de Azure Blob Storage. El resultado es un índice combinado de búsqueda de hoteles que contiene documentos de hotel, con habitaciones como tipos de datos complejos.
En este tutorial, realizará las siguientes tareas:
- Cargar datos de ejemplo y crear orígenes de datos
- Identificar la clave del documento
- Definir y crear el índice
- Indexar los datos de los hoteles desde Azure Cosmos DB
- Combinar los datos de las habitaciones de hotel desde Blob Storage
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Información general
En este tutorial se usa Azure.Search.Documents, versión 11.x, para crear y ejecutar varios indexadores. En este tutorial se configuran dos orígenes de datos de Azure para que pueda configurar después un indexador que extraiga datos de ambos para rellenar un índice de búsqueda único. Los dos conjuntos de datos deben tener un valor en común para admitir la combinación. En este ejemplo, ese campo es un identificador. Siempre que haya un campo en común para admitir la asignación, se pueden combinar datos de recursos dispares con un indexador, por ejemplo, datos estructurados de Azure SQL, datos no estructurados de Blob Storage o cualquier combinación de Orígenes de datos admitidos de Azure.
En el proyecto siguiente se puede encontrar una versión finalizada del código de este tutorial:
Requisitos previos
- Azure Cosmos DB para NoSQL
- Almacenamiento de Azure
- Visual Studio
- Paquete NuGet de Azure AI Search (versión 11.x)
- Azure AI Search
Nota:
Puede usar un servicio de búsqueda gratuito para este tutorial. El nivel gratis le limita a tres índices, tres indexadores y tres orígenes de datos. En este tutorial se crea uno de cada uno. Antes de empezar, asegúrese de que haya espacio en el servicio para aceptar los nuevos recursos.
1: Creación de servicios
En este tutorial se usa Azure AI Search para la indexación y las consultas, Azure Cosmos DB para un conjunto de datos y Azure Blob Storage para el segundo conjunto de datos.
Si es posible, cree todos los servicios en la misma región y grupo de recursos por proximidad y capacidad de administración. En la práctica, los servicios pueden estar en cualquier región.
Este ejemplo utiliza dos conjuntos pequeños de datos que describen las siete hoteles ficticios. Uno de ellos describe los hoteles en sí y se cargará en una base de datos de Azure Cosmos DB. El otro contiene los detalles de las habitaciones y se proporciona como siete archivos JSON independientes que se cargarán en Azure Blob Storage.
Comenzar con Azure Cosmos DB
Inicie sesión en Azure Portal y vaya a la página Introducción de la cuenta de Azure Cosmos DB.
Seleccione Explorador de datos y luego Nueva base de datos.
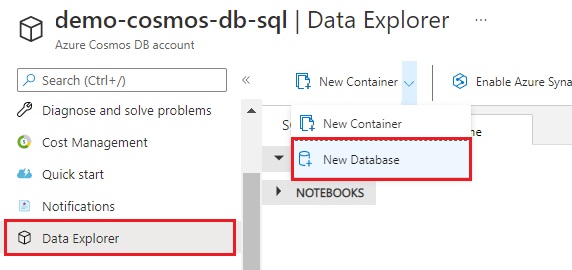
Escriba el nombre hotel-rooms-db. Acepte los valores predeterminados para la configuración restante.
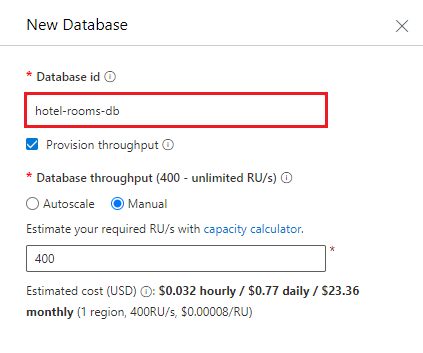
Cree un contenedor nuevo. Use la base de datos existente que acaba de crear. Escriba hotels como nombre del contenedor y use /HotelId como clave de partición.
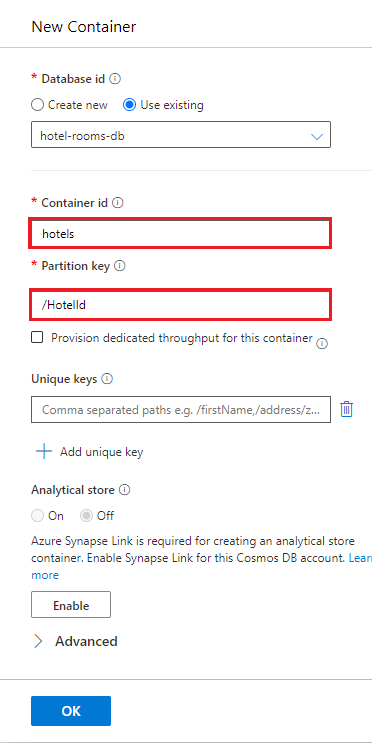
Seleccione Elementos en hoteles y luego haga clic en Cargar elemento en la barra de comandos. Vaya al archivo cosmosdb/HotelsDataSubset_CosmosDb.json de la carpeta del proyecto y selecciónelo.
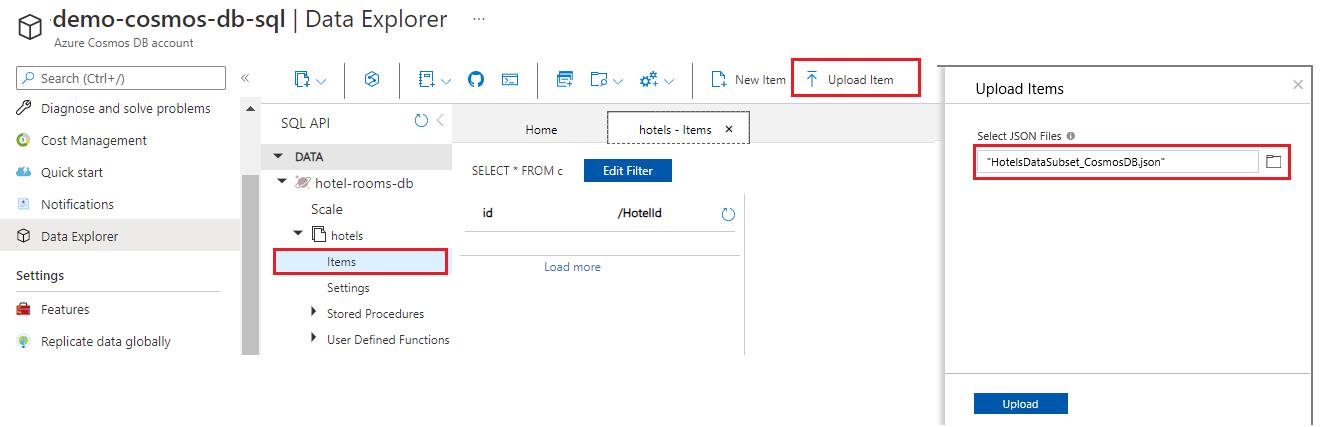
Utilice el botón Actualizar para actualizar la vista de los elementos de la colección de hoteles. Verá siete nuevos documentos de base de datos enumerados.
Copie una cadena de conexión de la página Claves en el Bloc de notas. Necesitará este valor para appsettings.json en un paso posterior. Si no ha utilizado el nombre de base de datos sugerido, "hotel-rooms-dd", copie también el nombre de la base de datos.
Azure Blob Storage
Inicie sesión en Azure Portal, vaya a su cuenta de Azure Storage, seleccione Blobs y, después, +Contenedor.
Cree un contenedor de blobs denominado hotel-rooms para almacenar los archivos JSON de las habitaciones de hotel de ejemplo. Puede establecer el nivel de acceso público a cualquiera de sus valores válidos.
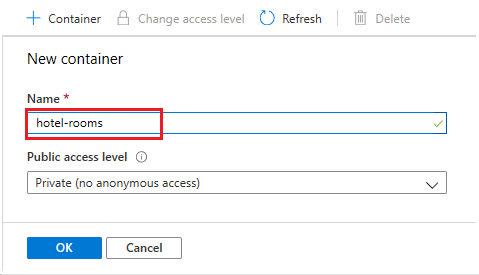
Una vez creado el contenedor, ábralo y seleccione Cargar en la barra de comandos. Vaya a la carpeta que contiene los archivos de ejemplo. Selecciónelos todos ellos y después, seleccione Cargar.
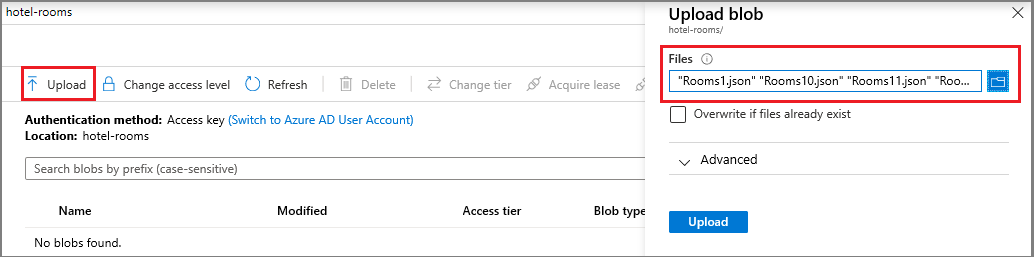
Copie el nombre de la cuenta de almacenamiento y una cadena de conexión de la página Claves de acceso en el Bloc de notas. Necesitará estos dos valores para appsettings.json en un paso posterior.
Azure AI Search
El tercer componente es Azure AI Search, que puedes crear en Azure Portal o buscar en un servicio de búsqueda existente en recursos de Azure.
Copia de una clave de API de administración y una dirección URL para Azure AI Search
Para la autenticación en el servicio de búsqueda, necesitará la dirección URL del servicio y una clave de acceso.
Inicie sesión en Azure Portal y en la página Introducción del servicio de búsqueda, y obtenga la dirección URL. Un punto de conexión de ejemplo podría ser similar a
https://mydemo.search.windows.net.En Configuración>Claves, obtenga una clave de administrador para tener derechos completos en el servicio. Se proporcionan dos claves de administrador intercambiables para lograr la continuidad empresarial, por si necesitara sustituir una de ellas. Puede usar la clave principal o secundaria en las solicitudes para agregar, modificar y eliminar objetos.
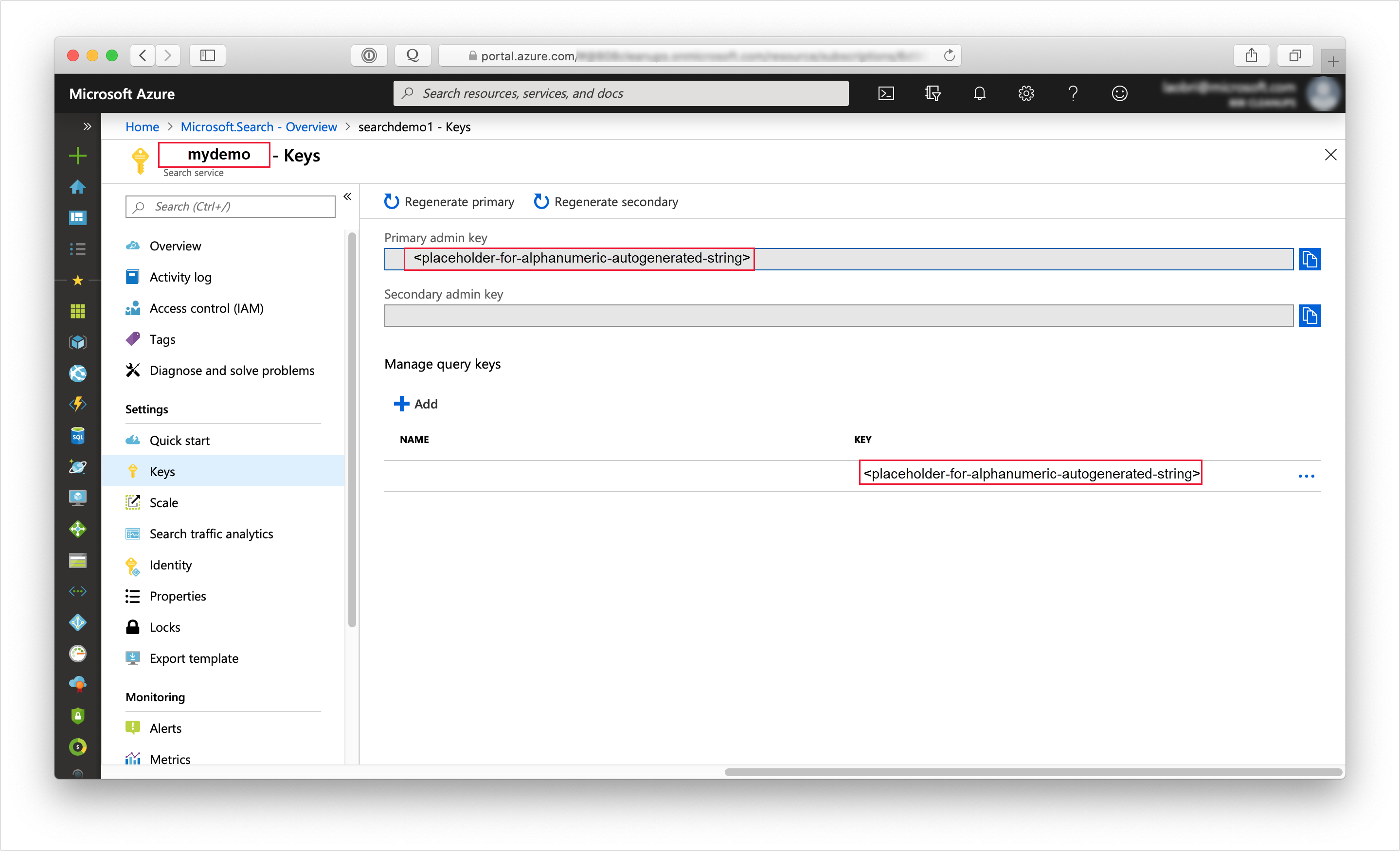
Tener una clave válida genera la confianza, solicitud a solicitud, entre la aplicación que envía la solicitud y el servicio que se encarga de ella.
2: Configuración del entorno
Inicie Visual Studio y, en el menú Herramientas, seleccione Administrador de paquetes NuGet y Administrar paquetes NuGet para la solución...
En la pestaña Examinar, busque e instale Azure.Search.Documents (versión 11.0 o posterior).
Busque los paquetes NuGet Microsoft.Extensions.Configuration y Microsoft.Extensions.Configuration.Json e instálelos también.
Abra el archivo de solución /v11/AzureSearchMultipleDataSources.sln.
En el Explorador de soluciones, edite el archivo appsettings.json para agregar información de conexión.
{ "SearchServiceUri": "<YourSearchServiceURL>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "BlobStorageAccountName": "<YourBlobStorageAccountName>", "BlobStorageConnectionString": "<YourBlobStorageConnectionString>", "CosmosDBConnectionString": "<YourCosmosDBConnectionString>", "CosmosDBDatabaseName": "hotel-rooms-db" }
Las dos primeras entradas usan las claves de dirección URL y de administrador de un servicio de búsqueda. Use el punto de conexión completo, por ejemplo, https://mydemo.search.windows.net.
Las siguientes entradas especifican nombres de cuenta e información de la cadena de conexión de los orígenes de datos de Azure Blob Storage y Azure Cosmos DB.
3: Asignación de campos de clave
La combinación de contenido requiere que ambos flujos de datos tengan como destino los mismos documentos en el índice de búsqueda.
En Azure AI Search, el campo de clave identifica de manera exclusiva cada documento. Cada índice de búsqueda debe tener exactamente un campo clave de tipo Edm.String. Ese campo de clave debe estar presente para cada documento de un origen de datos que se agregue al índice. (de hecho, es el único campo obligatorio).
Al indexar datos de varios orígenes de datos, asegúrese de que cada documento o fila entrante contiene una clave de documento común para combinar datos de dos documentos de origen físicamente distintos en un nuevo documento de búsqueda en el índice combinado.
A menudo requiere planeación inicial para identificar una clave de documentación significativa para el índice; asegúrese de que existe en ambos orígenes de datos. En esta demostración, la clave HotelId de cada hotel de Azure Cosmos DB también está presente en los blobs JSON de Blob Storage.
Los indexadores de Azure AI Search pueden usar asignaciones de campo para cambiar el nombre e incluso el formato de campos de datos durante la indexación para poder dirigir los datos de origen al campo de índice correcto. Por ejemplo, en Azure Cosmos DB, el identificador de los hoteles se denomina HotelId. Pero en los archivos de blob JSON de las habitaciones de los hoteles, se denomina Id. El programa se encarga de esta discrepancia mediante la asignación del campo Id desde los blobs hasta el campo de clave HotelId del indexador.
Nota
En la mayoría de los casos, las claves de documento generadas automáticamente, como las que crean algunos indexadores de forma predeterminada, no son buenas claves de documento para los índices combinados. En general, es preferible usar un valor de clave único y significativo que ya exista en los orígenes de datos o que se pueda agregar fácilmente a ellos.
4: Exploración del código
Una vez que los valores de configuración y los datos estén en su lugar, el ejemplo de programa de /v11/AzureSearchMultipleDataSources.sln estará listo para la compilación y la ejecución.
Esta sencilla aplicación de consola de C#/.NET realiza las siguientes tareas:
- Crea un nuevo índice basado en la estructura de datos de la clase Hotel de C# (que también hace referencia a las clases Address y Room).
- Crea un nuevo origen de datos y un indexador que asigna los datos de Azure Cosmos DB a campos de índice. Ambos son objetos de Azure AI Search.
- Ejecuta el indexador para cargar datos de Hotel desde Azure Cosmos DB.
- Crea un segundo origen de datos y un indexador que asigna datos de blob JSON a campos de índice.
- Ejecuta el segundo indexador para cargar datos de Rooms desde Blob Storage.
Antes de ejecutar el programa, dedíquele un minuto a estudiar el código y las definiciones de índice e indexador de este ejemplo. El código pertinente aparece en dos archivos:
- Hotel.cs contiene el esquema que define el índice.
- Program.cs contiene las funciones que crean el índice de Azure AI Search, los orígenes de datos y los indexadores, y cargan los resultados combinados en el índice.
Creación de un índice
Este programa de ejemplo usa CreateIndexAsync para definir y crear un índice de Azure AI Search. Aprovecha la clase FieldBuilder para generar una estructura de índice a partir de una clase de modelo de datos de C#.
El modelo de datos se define mediante la clase Hotel, que también contiene referencias a las clases Address y Room. FieldBuilder explora en profundidad varias definiciones de clase para generar una estructura de datos compleja para el índice. Se usan etiquetas de metadatos para definir los atributos de cada campo (por ejemplo, si permiten hacer búsquedas o clasificaciones).
El programa eliminará los índices existentes con el mismo nombre antes de crear el nuevo, por si desea ejecutar este ejemplo más veces.
Los fragmentos de código siguientes del archivo Hotel.cs muestran campos únicos, seguidos de una referencia a otra clase de modelo de datos, Room[], que a su vez se define en el archivo Room.cs (no se muestra).
. . .
[SimpleField(IsFilterable = true, IsKey = true)]
public string HotelId { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true)]
public string HotelName { get; set; }
. . .
public Room[] Rooms { get; set; }
. . .
En el archivo Program.cs, se define SearchIndex con un nombre y una colección de campos generados por el método FieldBuilder.Build, y se crea como sigue:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address and Room classes are referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Creación de un origen de datos de Azure Cosmos DB y de un indexador
A continuación, el programa principal incluirá lógica para crear el origen de datos de Azure Cosmos DB para los datos de los hoteles.
En primer lugar, concatena el nombre de la base de datos de Azure Cosmos DB con la cadena de conexión. A continuación, define un objeto SearchIndexerDataSourceConnection.
private static async Task CreateAndRunCosmosDbIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
// Append the database name to the connection string
string cosmosConnectString =
configuration["CosmosDBConnectionString"]
+ ";Database="
+ configuration["CosmosDBDatabaseName"];
SearchIndexerDataSourceConnection cosmosDbDataSource = new SearchIndexerDataSourceConnection(
name: configuration["CosmosDBDatabaseName"],
type: SearchIndexerDataSourceType.CosmosDb,
connectionString: cosmosConnectString,
container: new SearchIndexerDataContainer("hotels"));
// The Azure Cosmos DB data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(cosmosDbDataSource);
Una vez creado el origen de datos, el programa configura un indexador de Azure Cosmos DB denominado hotel-rooms-cosmos-indexer.
El programa actualizará los indexadores existentes con el mismo nombre y sobrescribirá el indexador existente con el contenido del código anterior. También incluye acciones de restablecimiento y ejecución, por si desea ejecutar este ejemplo más de una vez.
En el siguiente ejemplo se define una programación para el indexador para que se ejecute una vez al día. Puede quitar la propiedad de programación de esta llamada si no desea que el indexador se vuelva a ejecutar automáticamente en el futuro.
SearchIndexer cosmosDbIndexer = new SearchIndexer(
name: "hotel-rooms-cosmos-indexer",
dataSourceName: cosmosDbDataSource.Name,
targetIndexName: indexName)
{
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Indexers keep metadata about how much they have already indexed.
// If we already ran the indexer, it "remembers" and does not run again.
// To avoid this, reset the indexer if it exists.
try
{
await indexerClient.GetIndexerAsync(cosmosDbIndexer.Name);
// Reset the indexer if it exists.
await indexerClient.ResetIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
// If the indexer does not exist, 404 will be thrown.
}
await indexerClient.CreateOrUpdateIndexerAsync(cosmosDbIndexer);
Console.WriteLine("Running Azure Cosmos DB indexer...\n");
try
{
// Run the indexer.
await indexerClient.RunIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 429)
{
Console.WriteLine("Failed to run indexer: {0}", ex.Message);
}
Este ejemplo incluye un bloque sencillo try-catch para notificar los errores que puedan producirse durante la ejecución.
Tras la ejecución del indexador de Azure Cosmos DB, el índice de búsqueda contendrá un conjunto integral de documentos de ejemplo de hoteles. Sin embargo, el campo de habitaciones de cada hotel será una matriz vacía, ya que el origen de datos de Azure Cosmos DB omitía los detalles de las habitaciones. A continuación, el programa realizará una extracción de Blob Storage para cargar y combinar los datos de las habitaciones.
Creación del indexador y del origen de datos de Blob Storage
Para obtener los detalles de las habitaciones, el programa primero configura un origen de datos de Blob Storage para hacer referencia a un conjunto de archivos de blob JSON individuales.
private static async Task CreateAndRunBlobIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
SearchIndexerDataSourceConnection blobDataSource = new SearchIndexerDataSourceConnection(
name: configuration["BlobStorageAccountName"],
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["BlobStorageConnectionString"],
container: new SearchIndexerDataContainer("hotel-rooms"));
// The blob data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(blobDataSource);
Una vez creado el origen de datos, el programa configura un indexador de blobs denominado hotel-rooms-blob-indexer, como se muestra a continuación.
Los blobs JSON contienen un campo de clave denominado Id en lugar de HotelId . El código usa la clase FieldMapping para indicar al indexador que dirija el valor del campo Id a la clave de documento HotelId del índice.
Los indexadores de Blob Storage pueden usar IndexingParameters para especificar un modo de análisis. Debe establecer modos de análisis diferentes en función de si los blobs representan un único documento o varios en el mismo blob. En este ejemplo, cada blob representa un documento de JSON único, por lo que el código usa el modo de análisis json. Para más información sobre los parámetros de análisis del indexador, consulte el artículo sobre la Indexación de blobs JSON.
Este ejemplo define una programación para el indexador para que se ejecute una vez al día. Puede quitar la propiedad de programación de esta llamada si no desea que el indexador se vuelva a ejecutar automáticamente en el futuro.
IndexingParameters parameters = new IndexingParameters();
parameters.Configuration.Add("parsingMode", "json");
SearchIndexer blobIndexer = new SearchIndexer(
name: "hotel-rooms-blob-indexer",
dataSourceName: blobDataSource.Name,
targetIndexName: indexName)
{
Parameters = parameters,
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Map the Id field in the Room documents to the HotelId key field in the index
blobIndexer.FieldMappings.Add(new FieldMapping("Id") { TargetFieldName = "HotelId" });
// Reset the indexer if it already exists
try
{
await indexerClient.GetIndexerAsync(blobIndexer.Name);
await indexerClient.ResetIndexerAsync(blobIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404) { }
await indexerClient.CreateOrUpdateIndexerAsync(blobIndexer);
try
{
// Run the indexer.
await searchService.Indexers.RunAsync(blobIndexer.Name);
}
catch (CloudException e) when (e.Response.StatusCode == (HttpStatusCode)429)
{
Console.WriteLine("Failed to run indexer: {0}", e.Response.Content);
}
Dado que el índice ya se ha rellenado con datos de los hoteles desde la base de datos de Azure Cosmos DB, el indexador de blobs actualiza los documentos existentes en el índice y agrega los detalles de las habitaciones.
Nota
Si tiene los mismos campos (distintos del clave) en ambos orígenes de datos y los datos de esos campos no coinciden, el índice contendrá los valores del indexador que se ejecutara más recientemente. En nuestro ejemplo, ambos orígenes de datos contienen un campo HotelName. Si, por alguna razón, los datos de este campo difieren para documentos con el mismo valor de calve, los datos de HotelName del origen de datos que se indexara más recientemente serán los que se almacenen en el índice como valor.
5: Búsqueda
Puede explorar el índice de búsqueda relleno tras la ejecución del programa con el Explorador de búsqueda de Azure Portal.
En Azure Portal, abra la página Introducción del servicio de búsqueda y busque el índice hotel-rooms-sample en la lista Índices.

Seleccione el índice hotel-rooms-sample en la lista. Verá una interfaz del Explorador de búsqueda para el índice. Escriba una consulta con un término, como "Luxury". Debería ver al menos un documento en los resultados y este documento debería mostrar una lista de objetos de las habitaciones de la matriz.
Restablecer y volver a ejecutar
En las primeras etapas experimentales de desarrollo, el enfoque más práctico para la iteración de diseño es eliminar los objetos de Azure AI Search y permitir que el código vuelva a generarlos. Los nombres de los recursos son únicos. La eliminación de un objeto permite volver a crearlo con el mismo nombre.
En el código de ejemplo se comprueban los objetos existentes y se eliminan o se actualizan para que pueda volver a ejecutar el programa.
También puede usar Azure Portal para eliminar los índices, indexadores y orígenes de datos.
Limpieza de recursos
Cuando trabaje con su propia suscripción, al final de un proyecto, es recomendable eliminar los recursos que ya no necesite. Los recursos que se dejan en ejecución pueden costarle mucho dinero. Puede eliminar los recursos de forma individual o bien eliminar el grupo de recursos para eliminar todo el conjunto de recursos.
Puede encontrar y administrar recursos en Azure Portal mediante el vínculo Todos los recursos o Grupos de recursos en el panel de navegación izquierdo.
Pasos siguientes
Ahora que está familiarizado con el concepto de ingesta de datos de varios orígenes, echemos un vistazo más de cerca a la configuración del indexador, comenzando por Azure Cosmos DB.