Tutorial: Indexación de blobs Markdown anidados desde Azure Storage mediante REST
Nota:
Esta característica actualmente está en su versión preliminar pública. Esta versión preliminar se ofrece sin contrato de nivel de servicio y no es aconsejable usarla para cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
Búsqueda de Azure AI puede indexar documentos y matrices Markdown en Azure Blob Storage mediante un indexador que sabe cómo leer datos Markdown.
En este tutorial se muestra cómo indexar archivos Markdown indexados mediante el modo de análisis de Markdown oneToMany. Se usa un cliente REST y las API de REST de Search para realizar las tareas siguientes:
- Configuración de datos de ejemplo y configuración de un origen de datos de
azureblob - Creación de un índice de Azure AI Search que contenga contenido que permita búsquedas
- Crear y ejecutar un indexador para leer el contenedor y extraer contenido que permita búsquedas
- Buscar el índice que acaba de crear.
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Requisitos previos
Visual Studio Code con un cliente REST.
Búsqueda de Azure AI. Cree un servicio de Búsqueda de Azure AI o busque uno existente en su suscripción actual.
Nota:
Puede usar un servicio gratuito para este tutorial. Un servicio de búsqueda gratuito tiene una limitación de tres índices, tres indexadores y tres orígenes de datos. En este tutorial se crea uno de cada uno. Antes de empezar, asegúrese de que haya espacio en el servicio para aceptar los nuevos recursos.
Creación de un documento Markdown
Copie y pegue el siguiente Markdown en un archivo denominado sample_markdown.md. Los datos de ejemplo son un único archivo Markdown que contiene varios elementos Markdown. Se eligió un archivo Markdown para permanecer bajo los límites de almacenamiento del nivel gratuito.
# Project Documentation
## Introduction
This document provides a complete overview of the **Markdown Features** used within this project. The following sections demonstrate the richness of Markdown formatting, with examples of lists, tables, links, images, blockquotes, inline styles, and more.
---
## Table of Contents
1. [Headers](#headers)
2. [Introduction](#introduction)
3. [Basic Text Formatting](#basic-text-formatting)
4. [Lists](#lists)
5. [Blockquotes](#blockquotes)
6. [Images](#images)
7. [Links](#links)
8. [Tables](#tables)
9. [Code Blocks and Inline Code](#code-blocks-and-inline-code)
10. [Horizontal Rules](#horizontal-rules)
11. [Inline Elements](#inline-elements)
12. [Escaping Characters](#escaping-characters)
13. [HTML Elements](#html-elements)
14. [Emojis](#emojis)
15. [Footnotes](#footnotes)
16. [Task Lists](#task-lists)
17. [Conclusion](#conclusion)
---
## Headers
Markdown supports six levels of headers. Use `#` to create headers:
"# Project Documentation" at the top of the document is an example of an h1 header.
"## Headers" above is an example of an h2 header.
### h3 example
#### h4 example
##### h5 example
###### h6 example
This is an example of content underneath a header.
## Basic Text Formatting
You can apply various styles to your text:
- **Bold**: Use double asterisks or underscores: `**bold**` or `__bold__`.
- *Italic*: Use single asterisks or underscores: `*italic*` or `_italic_`.
- ~~Strikethrough~~: Use double tildes: `~~strikethrough~~`.
## Lists
### Ordered List
1. First item
2. Second item
3. Third item
### Unordered List
- Item A
- Item B
- Item C
### Nested List
1. Parent item
- Child item
- Child item
## Blockquotes
> This is a blockquote.
> Blockquotes are great for emphasizing important information.
>> Nested blockquotes are also possible!
## Images

## Links
[Visit Markdown Guide](https://www.markdownguide.org)
## Tables
| Syntax | Description | Example |
|-------------|-------------|---------------|
| Header | Title | Header Cell |
| Paragraph | Text block | Row Content |
## Code Blocks and Inline Code
### Inline Code
Use backticks to create `inline code`.
### Code Block
```javascript
// JavaScript example
function greet(name) {
console.log(`Hello, ${name}!`);
}
greet('World');
```
## Horizontal Rules
Use three or more dashes or underscores to create a horizontal rule.
---
___
## Inline Elements
Sometimes, it’s useful to include `inline code` to highlight code-like content.
You can also emphasize text like *this* or make it **bold**.
## Escaping Characters
To render special Markdown characters, use backslashes:
- \*Asterisks\*
- \#Hashes\#
- \[Brackets\]
## HTML Elements
You can mix HTML tags with Markdown:
<table>
<tr>
<th>HTML Table</th>
<th>With Markdown</th>
</tr>
<tr>
<td>Row 1</td>
<td>Data 1</td>
</tr>
</table>
## Emojis
Markdown supports some basic emojis:
- :smile: 😄
- :rocket: 🚀
- :checkered_flag: 🏁
## Footnotes
This is an example of a footnote[^1]. Footnotes allow you to add notes without cluttering the main text.
[^1]: This is the content of the footnote.
## Task Lists
- [x] Complete the introduction
- [ ] Add more examples
- [ ] Review the document
## Conclusion
Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.
Thank you for reviewing this example!
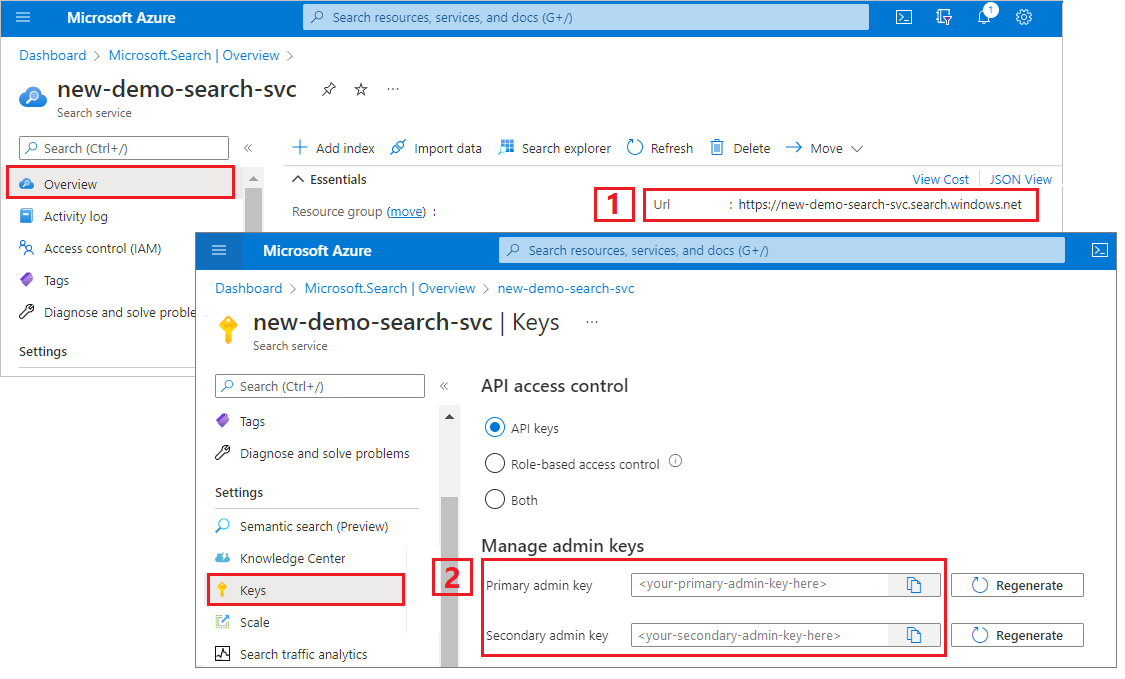
Copia de una dirección URL del servicio de búsqueda y una clave de API
Para este tutorial, las conexiones a la búsqueda de Azure AI requieren un punto de conexión y una clave de API. Puede obtener estos valores en Azure Portal. Para obtener métodos de conexión alternativos, consulte Identidades administradas.
Inicie sesión en Azure Portal, vaya a la página Información general del servicio de búsqueda y copie la dirección URL. Un punto de conexión de ejemplo podría ser similar a
https://mydemo.search.windows.net.En Configuración>Claves, copie una clave de administrador. Las claves de administrador se utilizan para agregar, modificar y eliminar objetos. Hay dos claves de administrador intercambiables. Copie una de las dos.
Configuración del archivo REST
Inicie Visual Studio Code y cree un nuevo archivo.
Proporcione valores para las variables usadas en la solicitud:
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnectionString = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HEREGuarde el archivo mediante una extensión de archivo
.resto.http.
Consulte Inicio rápido: Búsqueda de texto mediante REST si necesita ayuda con el cliente REST.
Creación de un origen de datos
Crear origen de datos (REST) crea una conexión de origen de datos que especifica qué datos se van a indexar.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Envíe la solicitud. La respuesta debería tener este aspecto:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DCF52E926A3C76"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('sample-markdown-ds')?api-version=2024-11-01-preview
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 0714c187-217e-4d35-928a-5069251e5cba
elapsed-time: 204
Date: Fri, 25 Oct 2024 19:52:35 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DCF52E926A3C76\"",
"name": "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "markdown-container",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
Creación de un índice
Crear índice (REST) crea un índice de búsqueda en el servicio de búsqueda. Un índice especifica todos los campos y sus atributos.
En el análisis de uno a varios, el documento de búsqueda define el lado "varios" de la relación. Los campos que especifique en el índice determinan la estructura del documento de búsqueda.
Solo necesita campos para los elementos Markdown que admite el analizador. Estos campos son:
content: una cadena que contiene Markdown sin procesar que se encuentra en una ubicación específica, en función de los metadatos de encabezado en ese punto del documento.sections: un objeto que contiene subcampos para los metadatos de encabezado hasta el nivel de encabezado deseado. Por ejemplo, cuandomarkdownHeaderDepthse establece enh3, contiene campos de cadenah1,h2yh3. Estos campos se indexan mediante la creación de reflejo de esta estructura en el índice o mediante asignaciones de campos con el formato/sections/h1,sections/h2, etc. Consulte las configuraciones de índice e indexador en los siguientes ejemplos para obtener ejemplos en contexto. Los subcampos incluidos son:-
h1: una cadena que contiene el valor del encabezado h1. Cadena vacía si no se ha establecido en este punto del documento. - (Opcional)
h2: una cadena que contiene el valor del encabezado h2. Cadena vacía si no se ha establecido en este punto del documento. - (Opcional)
h3: una cadena que contiene el valor del encabezado h3. Cadena vacía si no se ha establecido en este punto del documento. - (Opcional)
h4: una cadena que contiene el valor del encabezado h4. Cadena vacía si no se ha establecido en este punto del documento. - (Opcional)
h5: una cadena que contiene el valor del encabezado h5. Cadena vacía si no se ha establecido en este punto del documento. - (Opcional)
h6: una cadena que contiene el valor del encabezado h6. Cadena vacía si no se ha establecido en este punto del documento.
-
ordinal_position: un valor entero que indica la posición de la sección dentro de la jerarquía de documentos. Este campo se usa para ordenar las secciones de su secuencia original tal como aparecen en el documento, empezando por una posición ordinal de 1 e incrementando secuencialmente para cada bloque de contenido.
Esta implementación aprovecha las asignaciones de campos del indexador que asignar desde el contenido enriquecido al índice. Para obtener más información sobre la estructura de documentos de uno a varios analizados, consulte Indexación de blobs Markdown.
En este ejemplo se proporcionan ejemplos de cómo indexar datos con y sin asignaciones de campos. En este caso, sabemos que h1 contiene el título del documento, por lo que podemos asignarlo a un campo denominado title. También se asignarán los campos h2 y h3 a h2_subheader y h3_subheader respectivamente. Los campos content y ordinal_position no requieren ninguna asignación porque se extraen de Markdown directamente en campos con esos nombres. Para obtener un ejemplo de un esquema de índice completo que no requiere asignaciones de campos, consulte el final de esta sección.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "title", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Esquema de índice en una configuración sin asignaciones de campos
Las asignaciones de campos permiten manipular y filtrar contenido enriquecido para que se ajuste a la forma de índice deseada, pero es posible que solo desee adoptar directamente el contenido enriquecido. En ese caso, el esquema tendría el siguiente aspecto:
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "sections",
"type": "Edm.ComplexType",
"fields": [
{"name": "h1", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Permítanos insistir en que tenemos subcampos hasta h3 en las secciones porque markdownHeaderDepth se establece en h3.
Si decide usar este esquema, asegúrese de ajustar solicitudes posteriores en consecuencia. Para ello será necesario quitar las asignaciones de campos de la configuración del indexador y actualizar las consultas de búsqueda para usar los nombres de campo correspondientes.
Creación y ejecución de un indexador
Crear indexador crea un indexador en el servicio de búsqueda. Un indexador se conecta al origen de datos, carga e indexa datos y, opcionalmente, proporciona una programación para automatizar la actualización de datos.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-indexer",
"dataSourceName": "sample-markdown-ds",
"targetIndexName": "sample-markdown-index",
"parameters" : {
"configuration": {
"parsingMode": "markdown",
"markdownParsingSubmode": "oneToMany",
"markdownHeaderDepth": "h3"
}
},
"fieldMappings" : [
{
"sourceFieldName": "/sections/h1",
"targetFieldName": "title",
"mappingFunction": null
}
]
}
Puntos clave:
El indexador solo analizará encabezados hasta
h3. Los encabezados de nivel inferior (h4,h5yh6) se tratarán como texto sin formato y se mostrarán en el campocontent. Este es el motivo por el que las asignaciones de índices y campos solo existen hasta una profundidad deh3.Los campos
contentyordinal_positionno requieren ninguna asignación de campos, ya que existen con esos nombres en el contenido enriquecido.
Ejecutar consultas
Puede empezar a realizar búsquedas en cuanto se cargue el primer documento.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Envíe la solicitud. Se trata de una consulta de búsqueda de texto completo no especificada que devuelve todos los campos marcados como recuperables en el índice, junto con un recuento de documentos. La respuesta debería tener este aspecto:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 6b94e605-55e8-47a5-ae15-834f926ddd14
elapsed-time: 77
Date: Fri, 25 Oct 2024 20:22:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 22,
"value": [
<22 search documents here>
]
}
Agregue un parámetro search para buscar en una cadena.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "h4",
"count": true,
}
Envíe la solicitud. La respuesta debería tener este aspecto:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: ec5d03f1-e3e7-472f-9396-7ff8e3782105
elapsed-time: 52
Date: Fri, 25 Oct 2024 20:26:29 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 0.8744742,
"section_id": "aHR0cHM6Ly9hcmphZ2Fubmpma2ZpbGVzLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tYXJrZG93bi10dXRvcmlhbC9zYW1wbGVfbWFya2Rvd24ubWQ7NA2",
"content": "#### h4 example\r\n##### h5 example\r\n###### h6 example\r\nThis is an example of content underneath a header.\r\n",
"title": "Project Documentation",
"h2_subheader": "Headers",
"h3_subheader": "h3 example",
"ordinal_position": 4
}
]
}
Puntos clave:
Dado que
markdownHeaderDepthse establece enh3, los encabezadosh4,h5yh6se tratan como texto sin formato, por lo que aparecen en el campocontent.La posición ordinal aquí es
4. Este contenido aparece en cuarto lugar entre las 22 secciones de contenido totales.
Agregue un parámetro select para limitar los resultados a menos campos. Agregue un filter para restringir aún más la búsqueda.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "Markdown",
"count": true,
"select": "title, content, h2_subheader",
"filter": "h2_subheader eq 'Conclusion'"
}
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a6f9bd46-a064-4e28-818f-ea077618014b
elapsed-time: 35
Date: Fri, 25 Oct 2024 20:36:10 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 1.1029507,
"content": "Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.\r\n\r\nThank you for reviewing this example!",
"title": "Project Documentation",
"h2_subheader": "Conclusion"
}
]
}
En el caso de los filtros, también es posible usar operadores lógicos (and, or y not) y operadores de comparación (eq, ne, gt, lt, ge y le). La comparación de cadenas distingue mayúsculas de minúsculas. Para obtener más información y ejemplos, vea crear una consulta.
Nota:
El parámetro $filter solo funciona con los campos que se marcaron como filtrables al crear el índice.
Restablecer y volver a ejecutar
Los indexadores se pueden restablecer, borrar el historial de ejecución, lo que permite una nueva ejecución completa. Las siguientes solicitudes GET son para el restablecimiento, seguidas de la repetición de la ejecución.
### Reset the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/reset?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/run?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/sample-markdown-indexer/status?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
Limpieza de recursos
Cuando trabaje con su propia suscripción, al final de un proyecto, es recomendable eliminar los recursos que ya no necesite. Los recursos que se dejan en ejecución pueden costarle mucho dinero. Puede eliminar los recursos de forma individual o bien eliminar el grupo de recursos para eliminar todo el conjunto de recursos.
Puede utilizar Azure Portal para eliminar índices, indexadores y fuentes de datos.
Pasos siguientes
Ahora que está familiarizado con los aspectos básicos de la indexación de blobs de Azure, podemos abordar en detalle la configuración del indexador para blobs Markdown en Azure Storage.