Indexación de datos de bibliotecas de documentos de SharePoint
Importante
La compatibilidad con indizadores de SharePoint Online está en versión preliminar pública. Se ofrece "tal cual", en Condiciones de uso complementarias y solo se admite sobre el mejor esfuerzo. Las características en versión preliminar no se recomiendan para las cargas de trabajo de producción y no se garantiza que estén disponibles con carácter general.
Asegúrese de visitar la sección de limitaciones conocidas antes de comenzar.
Para usar esta versión preliminar, rellene este formulario. No recibirá ninguna notificación de aprobación justo después de que cualquier solicitud de acceso se acepte automáticamente después del envío. Una vez habilitado el acceso, use una API de REST de versión preliminar para indexar el contenido.
En este artículo se explica cómo configurar un indexador de búsqueda a fin de indexar los documentos almacenados en bibliotecas de documentos de SharePoint para la búsqueda de texto completo en Azure AI Search. Los pasos de configuración son lo primero, seguidos de los comportamientos y los escenarios
Funcionalidad
Un indexador en Azure AI Search es un rastreador que extrae metadatos y datos que permiten búsquedas de un origen de datos. El indexador de SharePoint Online se conecta al sitio de SharePoint e indexa documentos de una o varias bibliotecas de documentos. El indexador proporciona la funcionalidad siguiente:
- Indexe los archivos y los metadatos de una o varias bibliotecas de documentos.
- Indexe incrementalmente, seleccionando solo los archivos y metadatos nuevos y modificados.
- La detección de eliminación está integrada. La eliminación en una biblioteca de documentos se selecciona en la siguiente ejecución del indexador y el documento se quita del índice.
- El texto y las imágenes normalizadas se extraen de forma predeterminada de los documentos indexados. Opcionalmente, agregue un conjunto de aptitudes para un mayor enriquecimiento con IA, como el OCR o la traducción de texto.
Requisitos previos
Servicio en la nube SharePoint en Microsoft 365
Archivos en una biblioteca de documentos
Formatos de documento admitidos
El indexador de SharePoint Online puede extraer texto de los siguientes formatos de documento:
- CSV (consulte Indexación de blobs CSV)
- EML
- EPUB
- GZ
- HTML
- JSON (vea Indexación de blobs JSON)
- KML (XML para representaciones geográficas)
- Formatos de Microsoft Office: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (correos electrónicos de Outlook), XML (WORD XML 2003 y 2006)
- Formatos de Open Document: ODT, ODS, ODP
- Archivos de texto sin formato (vea también Indexing plain text (Indexación de texto sin formato))
- RTF
- XML
- ZIP
Limitaciones y consideraciones
Esta característica tiene las limitaciones siguientes:
No se admite la indexación de listas de SharePoint.
No se admite la indexación de contenido de sitios .ASPX de SharePoint.
No se admiten los archivos del bloc de notas de OneNote.
No se admite el punto de conexión privado.
Cambiar el nombre de una carpeta de SharePoint no desencadena la indexación incremental. Una carpeta cuyo nombre se ha cambiado se trata como nuevo contenido.
SharePoint admite un modelo de autorización detallado que determina el acceso por usuario en el nivel de documento. El indexador no extrae estos permisos en el índice y Búsqueda de Azure AI no admite la autorización de nivel de documento. Cuando un documento se indexa desde SharePoint en un servicio de búsqueda, el contenido está disponible para cualquier persona que tenga acceso de lectura al índice. Si necesitase permisos de nivel de documento, debería considerar los filtros de seguridad para recortar los resultados y automatizar la copia de los permisos a nivel de archivo en un campo del índice.
No se admiten la indexación de archivos cifrados por el usuario, los archivos protegidos de Information Rights Management (IRM), los archivos ZIP con contraseñas o contenido cifrado similar. Para que el contenido cifrado se procese, el usuario con los permisos adecuados para el archivo específico deberá quitar el cifrado para que el elemento se pueda indexar en consecuencia cuando el indexador ejecute la siguiente iteración programada.
No es posible indexar subsitios recursivamente a partir de un sitio específico.
El indexador de SharePoint Online no es compatible cuando está habilitado el Acceso condicional de Microsoft ENTRA ID.
Estas son las consideraciones al usar esta característica:
Si necesita crear una aplicación personalizada de Copilot / RAG (generación aumentada de recuperación) para chatear con datos de SharePoint, el enfoque recomendado es usar Microsoft Copilot Studio en lugar de esta característica de vista previa.
Si necesitase una solución de indexación de contenido de SharePoint en un entorno de producción, considere la posibilidad de crear un conector personalizado con Webhooks de SharePoint, llamando a Microsoft Graph API para exportar los datos a un contenedor de blobs de Azure y, a continuación, usar el indexador de blobs de Azure para la indexación incremental.
- Si la configuración de SharePoint permite que los procesos de Microsoft 365 actualicen los metadatos del sistema de archivos de SharePoint, tenga en cuenta que estas actualizaciones pueden desencadenar el indexador de SharePoint Online, lo que hace que el indexador ingiera documentos varias veces. Dado que el indexador de SharePoint Online es un conector de terceros en Azure, el indexador no puede leer la configuración ni variar su comportamiento. Responde a los cambios en el contenido nuevo y modificado, independientemente de cómo se realicen esas actualizaciones. Por esta razón, asegúrese de probar la configuración y comprender el recuento de procesamiento de documentos antes de usar el indexador y cualquier enriquecimiento con IA.
Configurar el indexador de SharePoint Online
Para configurar el indexador de SharePoint Online, use Azure Portal y una API de REST en versión preliminar. Puede usar 2020-06-30-preview o posterior. Se recomienda la API de versión preliminar más reciente.
En esta sección se proporcionan los pasos. Vea también el vídeo siguiente.
Paso 1 (opcional): Habilitación de una identidad administrada asignada por el sistema
Habilite una identidad administrada asignada por el sistema para detectar automáticamente el inquilino en el que se aprovisiona el servicio de búsqueda.
Realice este paso en caso de que el sitio de SharePoint esté en el mismo inquilino que el servicio de búsqueda. Omita este paso en caso de que el sitio de SharePoint esté en un inquilino diferente. La identidad no se usa para la indexación, solo para la detección de inquilinos. Omita este paso si desea colocar el identificador de inquilino en la cadena de conexión.
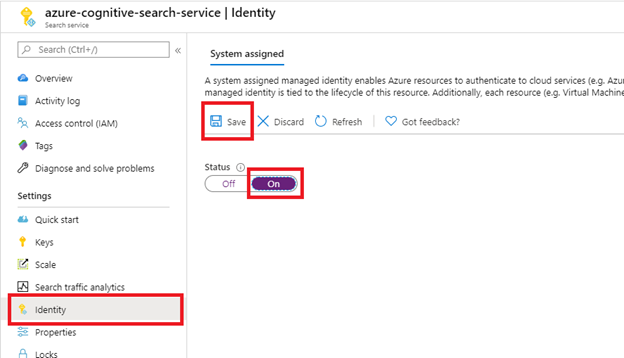
Después de seleccionar Guardar, obtendrá un id. de objeto que se habrá asignado al servicio de búsqueda.
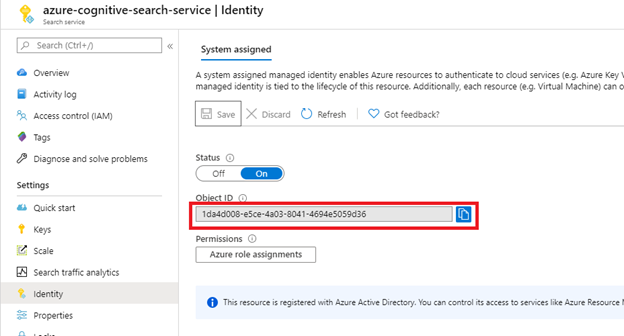
Paso 2: Decidir qué permisos necesita el indexador
El indexador de SharePoint Online admite permiso delegados y de aplicación. Elija los permisos que desee usar en función de su escenario.
Se recomiendan permisos basados en aplicaciones. Consulte las limitaciones para conocer los problemas conocidos relacionados con los permisos delegados.
Permisos de aplicación (recomendado), donde el indexador se ejecuta bajo la identidad del inquilino de SharePoint con acceso a todos los sitios y archivos. El indexador requiere un secreto de cliente. El indexador también requerirá la aprobación del administrador de inquilinos para poder indexar cualquier contenido.
Permisos delegados, donde el indexador se ejecuta bajo la identidad del usuario o la aplicación que envía la solicitud. El acceso a datos se limita a los sitios y archivos a los que el autor de llamada tiene acceso. Para admitir permisos delegados, el indexador requiere un mensaje de código de dispositivo a fin de iniciar sesión en nombre del usuario. Los permisos delegados por el usuario aplican la expiración del token cada 75 minutos, según las bibliotecas de seguridad más recientes usadas para implementar este tipo de autenticación. Este no es un comportamiento que se pueda ajustar. Un token expirado requiere indexación manual mediante Ejecutar Indizador (versión preliminar). Por este motivo, es posible que quiera permisos basados en aplicaciones en su lugar.
Paso 3: creación de un registro de aplicación de Microsoft Entra
El indexador de SharePoint Online usa esta aplicación Microsoft Entra para la autenticación.
Inicie sesión en Azure Portal.
Busque o vaya a Microsoft Entra ID y seleccione Registros de aplicaciones.
Seleccione + Nuevo registro:
- Proporcione un nombre para la aplicación.
- Seleccione Inquilino único.
- Omita el paso de designación de URI. No se necesita un URI de redirección.
- Seleccione Registrar.
A la izquierda, seleccione Permisos de API y luego, Agregar un permiso y Microsoft Graph.
Si el indexador usa permisos de API de aplicación, seleccione Permisos de la aplicación y agregue lo siguiente:
- Application - Files.Read.All
- Application - Sites.Read.All

El uso de permisos de aplicación significa que el indexador tiene acceso al sitio de SharePoint en el contexto del servicio. Por lo tanto, cuando ejecute el indexador, tendrá acceso a todo el contenido del inquilino de SharePoint, que requiere la aprobación del administrador de inquilinos. También se requiere un secreto de cliente para la autenticación. La configuración del secreto de cliente se describe más adelante en este artículo.
Si el indexador usa permisos de API delegados, seleccione Permisos delegados y agregue lo siguiente:
- Delegado: Files.Read.All
- Delegado: Sites.Read.All
- Delegado: User.Read
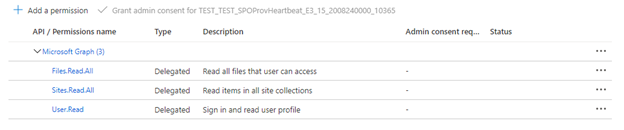
Los permisos delegados permiten al cliente de búsqueda conectarse a SharePoint bajo la identidad de seguridad del usuario actual.
Ceda el consentimiento del administrador.
El consentimiento del administrador del inquilino es necesario cuando se usan permisos de API de aplicación. Algunos inquilinos están bloqueados y hace falta el consentimiento del administrador del inquilino para usar estos permisos de API delegados. Si se aplica alguna de estas condiciones, necesitará que un administrador del inquilino conceda el consentimiento para esta aplicación de Microsoft Entra antes de crear el indexador.
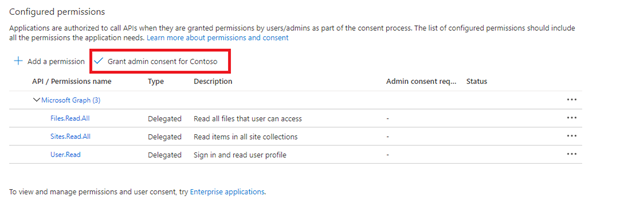
Seleccione la pestaña Autenticación.
Establezca Allow public client flows (Permitir flujos de clientes públicos) en Sí y, luego, seleccione Guardar.
Seleccione + Agregar una plataforma, después Aplicaciones móviles y de escritorio y, luego, vaya a
https://login.microsoftonline.com/common/oauth2/nativeclienty haga clic en Configurar.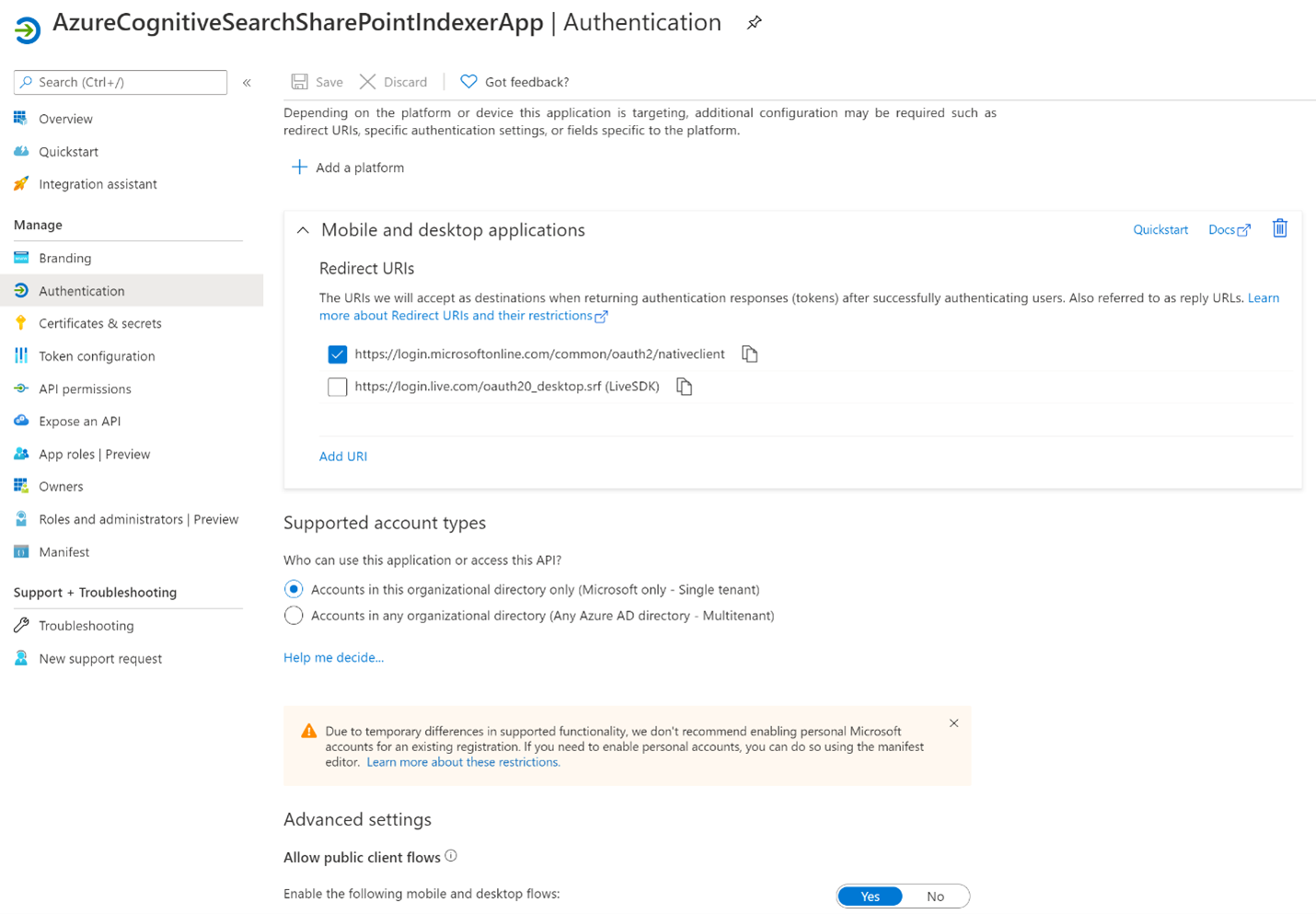
(Solo permisos de API de aplicación) Para autenticarse en la aplicación de Microsoft Entra mediante permisos de aplicación, el indexador requiere un secreto de cliente.
Seleccione Certificados y secretos en el menú de la izquierda y, a continuación, Secretos de cliente y Nuevo secreto de cliente.

En el menú que aparece, escriba una descripción para el nuevo secreto de cliente. Ajuste la fecha de expiración si es necesario. Si el secreto expirase, tendrá que volver a crearse y el indexador deberá actualizarse con el nuevo secreto.
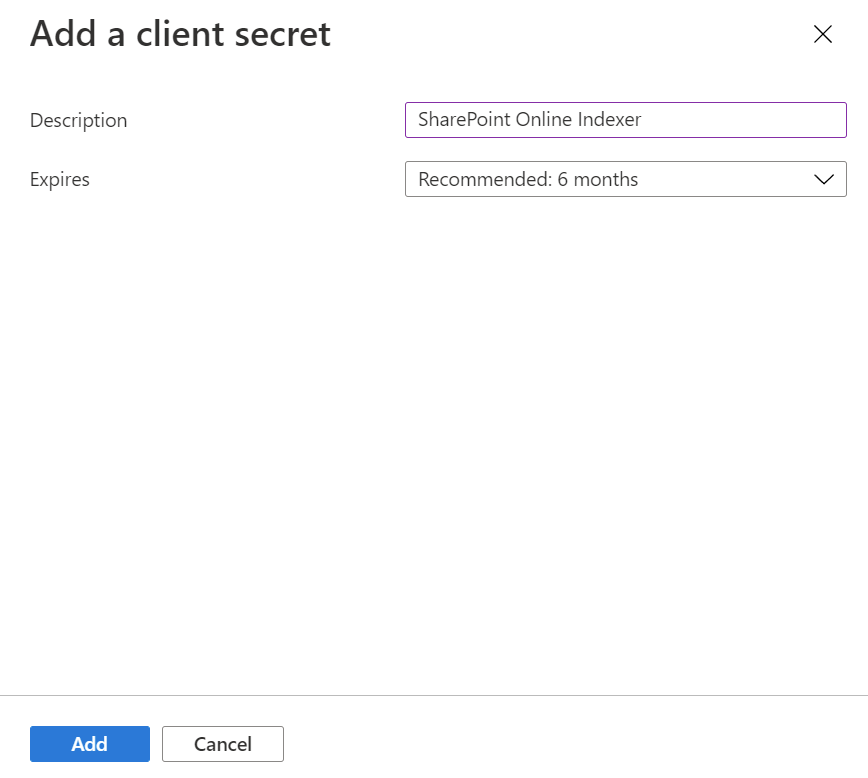
El nuevo secreto de cliente aparecerá en la lista de secretos. Una vez que deje la página, el secreto ya no estará visible, así que cópielo con el botón Copiar y guárdelo en una ubicación segura.

Paso 4: Creación del origen de datos
A partir de esta sección, use una API de REST en versión preliminar en el resto de los pasos. Se recomienda la API de versión preliminar más reciente.
Un origen de datos especifica los datos que se deben indexar, las credenciales y las directivas para identificar cambios en los datos de forma eficaz (filas nuevas, modificadas o eliminadas). Varios indexadores pueden usar el mismo origen de datos en el mismo servicio de búsqueda.
Para realizar la indexación de SharePoint, el origen de datos debe tener las siguientes propiedades obligatorias:
- name es el nombre único del origen de datos dentro del servicio de búsqueda.
- type: debe ser "sharepoint". Este valor distingue mayúsculas de minúsculas.
- credentials: proporciona el punto de conexión de SharePoint y el identificador (cliente) de la aplicación de Microsoft Entra. Un punto de conexión de SharePoint de ejemplo es
https://microsoft.sharepoint.com/teams/MySharePointSite. Para obtenerlo, vaya a la página principal del sitio de SharePoint y copie la dirección URL desde el explorador. - container: especifica la biblioteca de documentos que se va a indexar. Las propiedades controlan qué documentos se indexan.
Para crear un origen de datos, llame a Crear un origen de datos (versión preliminar).
POST https://[service name].search.windows.net/datasources?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"name" : "sharepoint-datasource",
"type" : "sharepoint",
"credentials" : { "connectionString" : "[connection-string]" },
"container" : { "name" : "defaultSiteLibrary", "query" : null }
}
Formato de la cadena de conexión
El formato de la cadena de conexión cambia en función de si el indexador usa permisos delegados de API o permisos de API de aplicación
Formato de cadena de conexión de permisos de API delegados
SharePointOnlineEndpoint=[SharePoint site url];ApplicationId=[Azure AD App ID];TenantId=[SharePoint site tenant id]Formato de cadena de conexión de permisos de API de aplicación
SharePointOnlineEndpoint=[SharePoint site url];ApplicationId=[Azure AD App ID];ApplicationSecret=[Azure AD App client secret];TenantId=[SharePoint site tenant id]
Nota:
Si el sitio de SharePoint está en el mismo inquilino que el servicio de búsqueda y la identidad administrada asignada por el sistema está habilitada, TenantId no tiene que incluirse en la cadena de conexión. Si el sitio de SharePoint está en un inquilino diferente del servicio de búsqueda, TenantId debe incluirse.
Paso 5: Creación de un índice
El índice especifica los campos de un documento, los atributos y otras construcciones que conforman la experiencia de búsqueda.
Para crear un índice, llame a Crear índice (versión preliminar):
POST https://[service name].search.windows.net/indexes?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"name" : "sharepoint-index",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "metadata_spo_item_name", "type": "Edm.String", "key": false, "searchable": true, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_path", "type": "Edm.String", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_content_type", "type": "Edm.String", "key": false, "searchable": false, "filterable": true, "sortable": false, "facetable": true },
{ "name": "metadata_spo_item_last_modified", "type": "Edm.DateTimeOffset", "key": false, "searchable": false, "filterable": false, "sortable": true, "facetable": false },
{ "name": "metadata_spo_item_size", "type": "Edm.Int64", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": false, "facetable": false }
]
}
Importante
Solo se puede usar metadata_spo_site_library_item_id como campo de clave en un índice rellenado por el indexador SharePoint Online. Si no existe un campo de clave en el origen de datos, metadata_spo_site_library_item_id se asigna automáticamente al campo de clave.
Paso 6: Creación de un indexador
Un indexador conecta un origen de datos con un índice de búsqueda de destino y proporciona una programación para automatizar la actualización de datos. Una vez que cree el origen de datos y el índice, podrá crear el indizador.
Si usa permisos delegados, durante este paso, se le pedirá que inicie sesión con las credenciales de la organización que tienen acceso al sitio de SharePoint. Si es posible, se recomienda crear otra cuenta de usuario de la organización y dar a ese nuevo usuario los permisos exactos que quiere que tenga el indexador.
Para crear el indexador, es necesario realizar algunos pasos:
Envíe una solicitud Crear indexador (versión preliminar):
POST https://[service name].search.windows.net/indexers?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key] { "name" : "sharepoint-indexer", "dataSourceName" : "sharepoint-datasource", "targetIndexName" : "sharepoint-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpg", "dataToExtract": "contentAndMetadata" } }, "schedule" : { }, "fieldMappings" : [ { "sourceFieldName" : "metadata_spo_site_library_item_id", "targetFieldName" : "id", "mappingFunction" : { "name" : "base64Encode" } } ] }Si usa permisos de aplicación, es necesario esperar hasta que se complete la ejecución inicial antes de empezar a consultar el índice. Las siguientes instrucciones proporcionadas en este paso pertenecen específicamente a los permisos delegados y no son aplicables a los permisos de aplicación.
Al crear el indexador por primera vez, la solicitud Crear indexador (versión preliminar) esperará hasta que complete el paso siguiente. Debe llamar a Obtener estado del indexador para obtener el vínculo y escribir el nuevo código de dispositivo.
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key]Si no ejecuta Obtener estado del indexador en un plazo de 10 minutos, el código expirará y deberá volver a crear el origen de datos.
Copie el código de inicio de sesión del dispositivo de la respuesta Obtener estado del indexador. El inicio de sesión del dispositivo se encontrará en el "errorMessage".
{ "lastResult": { "status": "transientFailure", "errorMessage": "To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code <CODE> to authenticate." } }Proporcione el código que se ha incluido en el mensaje de error.
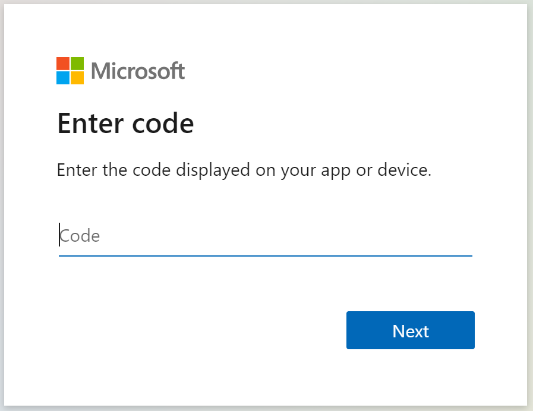
El indexador de SharePoint Online tendrá acceso al contenido de SharePoint como usuario que ha iniciado sesión. El usuario que inicia sesión durante este paso será el usuario con sesión iniciada. Por lo tanto, si inicia sesión con una cuenta de usuario que no tiene acceso a un documento de la biblioteca de documentos que quiere indexar, el indexador no tendrá acceso a ese documento.
Si es posible, se recomienda crear otra cuenta de usuario y dar a ese nuevo usuario los permisos exactos que quiere que tenga el indexador.
Apruebe los permisos que se solicitan.
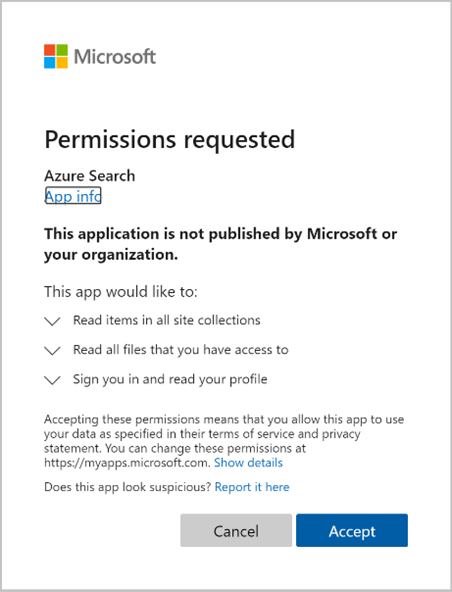
La solicitud inicial Crear indexador (versión preliminar) se completará si todos los permisos proporcionados anteriormente son correctos y se encuentran dentro del período de tiempo de 10 minutos.
Nota:
Si la aplicación de Microsoft Entra requiere la aprobación del administrador y esta no tuvo lugar antes de iniciar sesión, es posible que vea la pantalla siguiente. Se requiere la aprobación del administrador para continuar.
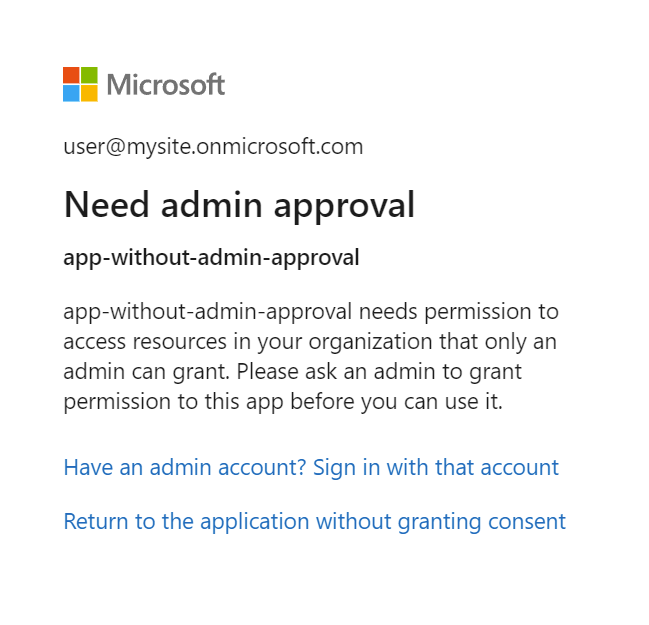
Paso 7: Comprobación del estado del indexador
Una vez creado el indexador, puede llamar a Obtener el estado del indexador:
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
Actualización del origen de datos
Si no hubiera ninguna actualización del objeto de origen de datos, el indexador se ejecutará según una programación sin interacción del usuario.
Sin embargo, si se modificase el objeto de origen de datos mientras el código del dispositivo haya expirado, se deberá iniciar sesión de nuevo para que se ejecute el indexador. Por ejemplo, si cambia la consulta del origen de datos, inicie sesión de nuevo con https://microsoft.com/devicelogin y obtenga el nuevo código de dispositivo.
Estos son los pasos para actualizar un origen de datos, suponiendo que un código de dispositivo haya expirado:
Llame a Ejecutar indexador (versión preliminar) para iniciar manualmente la ejecución del indexador.
POST https://[service name].search.windows.net/indexers/sharepoint-indexer/run?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key]Compruebe el estado del indexador.
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key]Si recibiera un error pidiéndole que visite
https://microsoft.com/devicelogin, abra la página y copie el nuevo código.Pegue el código en el cuadro de diálogo.
Vuelva a ejecutar manualmente el indexador y compruebe su estado. En esta ocasión, la ejecución del indexador debería iniciarse correctamente.
Indexación de los metadatos de los documentos
Si está indexando los metadatos del documento ("dataToExtract": "contentAndMetadata"), los siguientes metadatos estarán disponibles para indexarse.
| Identificador | Tipo | Descripción |
|---|---|---|
| metadata_spo_site_library_item_id | Edm.String | Clave de combinación de los identificadores de sitio, biblioteca y elemento que identifica de forma única un elemento en una biblioteca de documentos de un sitio. |
| metadata_spo_site_id | Edm.String | Identificador del sitio de SharePoint. |
| metadata_spo_library_id | Edm.String | Identificador de la biblioteca de documentos. |
| metadata_spo_item_id | Edm.String | Identificador del elemento (documento) de la biblioteca. |
| metadata_spo_item_last_modified | Edm.DateTimeOffset | Fecha y hora de la última modificación (UTC) del elemento. |
| metadata_spo_item_name | Edm.String | Nombre del artículo. |
| metadata_spo_item_size | Edm.Int64 | Tamaño (en bytes) del elemento. |
| metadata_spo_item_content_type | Edm.String | Tipo de contenido del elemento. |
| metadata_spo_item_extension | Edm.String | Extensión del elemento. |
| metadata_spo_item_weburi | Edm.String | URI del elemento. |
| metadata_spo_item_path | Edm.String | Combinación de la ruta de acceso principal y el nombre del elemento. |
El indexador de SharePoint Online también admite metadatos específicos de cada tipo de documento. Puede encontrar más información en Propiedades de los metadatos de contenido usadas en Azure AI Search.
Nota:
Para indexar los metadatos personalizados, se debe especificar "additionalColumns" en el parámetro de consulta del origen de datos.
Inclusión o exclusión por tipo de archivo
Puede controlar qué archivos se indexan estableciendo criterios de inclusión y exclusión en la sección "parámetros" de la definición del indexador.
Incluya extensiones de archivo específicas al establecer "indexedFileNameExtensions" en una lista separada por comas de extensiones de archivo (con un punto inicial). Excluya extensiones de archivo específicas al establecer "excludedFileNameExtensions" en las extensiones que se deben omitir. Si la misma extensión se encontrase en ambas listas, se excluirá de la indexación.
PUT /indexers/[indexer name]?api-version=2024-05-01-preview
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
Control de los documentos que se van a indexar
Un único indexador de SharePoint Online puede indexar el contenido de una o varias bibliotecas de documentos. Use el parámetro "container" en la definición del origen de datos para indicar desde qué sitios y bibliotecas de documentos se va a indexar.
La sección "container" del origen de datos tiene dos propiedades para esta tarea: "name" y "query".
Nombre
La propiedad "name" es obligatoria y debe tener uno de estos tres valores:
| Valor | Descripción |
|---|---|
| defaultSiteLibrary | Indexa todo el contenido de la biblioteca de documentos predeterminada del sitio. |
| allSiteLibraries | Indexa todo el contenido de todas las bibliotecas de documentos en un sitio. Las bibliotecas de documentos de un subsitio están fuera del ámbito/ Si necesita contenido de subsitios, elija "useQuery" y especifique "includeLibrariesInSite". |
| useQuery | Solo se indexa el contenido definido en "query". |
Consultar
El parámetro "query" del origen de datos se forma de pares palabra clave-valor. A continuación, se muestran las palabras clave que se pueden usar. Los valores son direcciones URL de sitio o de biblioteca de documentos.
Nota:
Para obtener el valor de una palabra clave determinada, se recomienda ir a la biblioteca de documentos que está intentando incluir o excluir y copiar el URI desde el explorador. Esta es la forma más fácil de obtener el valor que se va a usar con una palabra clave en la consulta.
| Palabra clave | Descripción del valor y ejemplos |
|---|---|
| null | Si es NULL o está vacía, se indexa la biblioteca de documentos predeterminada o todas las bibliotecas de documentos en función del nombre del contenedor. Ejemplo: "container" : { "name" : "defaultSiteLibrary", "query" : null } |
| includeLibrariesInSite | Indexar el contenido de todas las bibliotecas del sitio especificado en la cadena de conexión. El valor debe ser el URI del sitio o subsitio. Ejemplo 1: "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/mysite" } Ejemplo 2 (incluya solo algunos subsitios): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/sites/TopSite/SubSite1;includeLibrariesInSite=https://mycompany.sharepoint.com/sites/TopSite/SubSite2" } |
| includeLibrary | Indexar todo el contenido de esta biblioteca. El valor es la ruta de acceso completa a la biblioteca, que se puede copiar desde el explorador: Ejemplo 1 (ruta de acceso completa): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/mysite/MyDocumentLibrary" } Ejemplo 2 (URI copiado del explorador): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx" } |
| excludeLibrary | No se indexa el contenido de esta biblioteca. El valor es la ruta de acceso completa a la biblioteca, que se puede copiar desde el explorador: Ejemplo 1 (ruta de acceso completa): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mysite.sharepoint.com/subsite1; excludeLibrary=https://mysite.sharepoint.com/subsite1/MyDocumentLibrary" } Ejemplo 2 (URI copiado del explorador): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/teams/mysite; excludeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx" } |
| additionalColumns | Indexar columnas de la biblioteca de documentos. El valor es una lista separada por comas de nombres de columna que desea indexar. Use una doble barra diagonal inversa como caracteres de escape para los puntos y comas y las comas en los nombres de columna: Ejemplo 1 (additionalColumns=MyCustomColumn,MyCustomColumn2): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/mysite/MyDocumentLibrary;additionalColumns=MyCustomColumn,MyCustomColumn2" } Ejemplo 2 (caracteres de escape con doble barra diagonal inversa): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx;additionalColumns=MyCustomColumnWith\\,,MyCustomColumnWith\\;" } |
Control de errores
De forma predeterminada, el indexador de SharePoint Online se detiene cuando encuentra un documento con un tipo de contenido no admitido (por ejemplo, una imagen). Puede usar el parámetro excludedFileNameExtensions para omitir determinados tipos de contenido. Sin embargo, podría tener que indexar documentos sin conocer de antemano todos los tipos de contenido posibles. Para reanudar la indexación cuando se encuentra un tipo de contenido no admitido, establezca el parámetro de configuración failOnUnsupportedContentType en false:
PUT https://[service name].search.windows.net/indexers/[indexer name]?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
... other parts of indexer definition
"parameters" : { "configuration" : { "failOnUnsupportedContentType" : false } }
}
Con algunos documentos, Azure AI Search no puede determinar el tipo de contenido o no puede procesar un documento de otro tipo de contenido admitido. Para ignorar este modo de error, establezca el parámetro de configuración failOnUnprocessableDocument en false:
"parameters" : { "configuration" : { "failOnUnprocessableDocument" : false } }
Azure AI Search limita el tamaño de los documentos que se indexan. Estos límites se documentan en Límites de servicio en Azure AI Search. Los documentos de gran tamaño se tratan como errores de forma predeterminada. Sin embargo, puede indexar los metadatos de almacenamiento de documentos demasiado grandes si establece el parámetro de configuración indexStorageMetadataOnlyForOversizedDocuments en true:
"parameters" : { "configuration" : { "indexStorageMetadataOnlyForOversizedDocuments" : true } }
También puede continuar con la indexación si se producen errores en cualquier punto del procesamiento, bien mientras se analizan documentos o se agregan estos a un índice. Para omitir un número específico de errores, establezca los parámetros de configuración maxFailedItems y maxFailedItemsPerBatch en los valores deseados. Por ejemplo:
{
... other parts of indexer definition
"parameters" : { "maxFailedItems" : 10, "maxFailedItemsPerBatch" : 10 }
}
Si un archivo del sitio de SharePoint tuviera habilitado el cifrado, se podría encontrar un mensaje de error similar al siguiente:
Code: resourceModified Message: The resource has changed since the caller last read it; usually an eTag mismatch Inner error: Code: irmEncryptFailedToFindProtector
El mensaje de error también incluirá el identificador de sitio de SharePoint, el identificador de unidad y el identificador de elemento de unidad en el siguiente patrón: <sharepoint site id> :: <drive id> :: <drive item id>. Esta información se puede usar para identificar qué elementos producen errores por parte de SharePoint. Después, el usuario podrá quitar el cifrado del elemento para resolver el problema.