Conjuntos de datos y canalizaciones de ejemplo en el diseñador de Azure Machine Learning
Use los ejemplos integrados en el diseñador de Azure Machine Learning para empezar a crear rápidamente sus propias canalizaciones de aprendizaje automático. El repositorio de GitHub del diseñador de Azure Machine Learning contiene documentación detallada para ayudarle a conocer algunos escenarios comunes de aprendizaje automático.
Requisitos previos
- Suscripción a Azure. Si no tiene ninguna suscripción a Azure, cree una cuenta gratuita
- Un área de trabajo de Azure Machine Learning
Importante
Si no ve los elementos gráficos que se mencionan en este documento, como los botones en Studio o en el diseñador, es posible que no tenga el nivel de permisos adecuado para el área de trabajo. Póngase en contacto con el administrador de suscripciones de Azure para verificar que se le ha concedido el nivel de acceso correcto. Para obtener más información, consulte Administración de usuarios y roles.
Canalizaciones de ejemplo
El diseñador guarda una copia de las canalizaciones de ejemplo en el área de trabajo del estudio. Puede editar la canalización para adaptarla a sus necesidades y guardarla como propia. Úselas como punto de partida para iniciar sus proyectos.
Aquí se muestra cómo usar un ejemplo de diseñador:
Inicie sesión en ml.azure.com y seleccione el área de trabajo con la que quiere trabajar.
Seleccione Diseñador.
Seleccione una canalización de ejemplo en la sección Nueva canalización.
Seleccione Mostrar más ejemplos para obtener una lista completa de ejemplos.
Para ejecutar una canalización antes hay que establecer un destino de proceso predeterminado en el que ejecutarla.
En el panel de configuración situado a la derecha del lienzo, elija Selección de destino de proceso.
En el cuadro de diálogo que aparece, seleccione un destino de proceso existente, o bien créelo. Seleccione Guardar.
Seleccione Enviar en la parte superior del lienzo para enviar un trabajo de una canalización.
En función de la canalización de ejemplo y de la configuración del proceso, es posible que los trabajos tarden un poco en finalizar. La configuración del proceso predeterminada tiene un tamaño de nodo mínimo de 0, lo que significa que el diseñador debe asignar recursos después de estar inactivo. Los trabajos de canalización repetidos tardarán menos en terminar, dado que los recursos del proceso ya están asignados. Además, el diseñador usa resultados almacenados en la caché de cada componente para mejorar aún más la eficiencia.
Una vez que finalice la ejecución de la canalización, puede consultarla y ver la salida de cada componente, con el fin de obtener más información. Use los siguientes pasos para ver las salidas de los componentes:
- Haga clic con el botón derecho en el componente del lienzo cuya salida quisiera ver.
- Seleccione Visualize (Visualizar).
Use los ejemplos como puntos iniciales para algunos de los escenarios de aprendizaje automático más comunes.
Regresión
Explore estos ejemplos de regresión integrados.
| Título de ejemplo | Descripción |
|---|---|
| Regresión. Predicción del precio de los automóviles (básica) | Se predicen los precios de los automóviles mediante una regresión lineal. |
| Regresión. Predicción del precio de los automóviles (avanzada) | Se predicen los precios de los automóviles mediante los regresores de árbol de decisión impulsado y bosque de decisión. Compare los modelos para encontrar el mejor algoritmo. |
clasificación
Explore estos ejemplos de clasificación integrados. Para más información sobre los ejemplos, ábralos y vea los comentarios del componente en el diseñador.
| Título de ejemplo | Descripción |
|---|---|
| Clasificación binaria con selección de características. Predicción de ingresos | Se predicen los ingresos como altos o bajos, mediante un árbol de decisión impulsado de dos clases. Use la correlación de Pearson para seleccionar las características. |
| Clasificación binaria con un script de Python personalizado. Predicción del riesgo de crédito | Clasifique las aplicaciones de crédito como de riesgo alto o bajo. Use el componente para ejecutar script de Python para ponderar los datos. |
| Clasificación binaria. Predicción de las relaciones de cliente | Se predice el abandono de los clientes mediante árboles de decisión impulsados de dos clases. Use SMOTE para muestrear los datos sesgados. |
| Clasificación de texto. Conjunto de datos de Wikipedia SP 500 | Clasifique los tipos de empresa de los artículos de Wikipedia con regresión logística multiclase. |
| Clasificación multiclase. Reconocimiento de letras | Cree un conjunto de clasificadores binarios para clasificar las letras escritas. |
Visión del equipo
Explore estos ejemplos de Computer Vision integrados. Para más información sobre los ejemplos, ábralos y vea los comentarios del componente en el diseñador.
| Título de ejemplo | Descripción |
|---|---|
| Clasificación de imágenes mediante DenseNet | Use los componentes de Computer Vision para compilar un modelo de clasificación de imágenes basado en PyTorch DenseNet. |
Recomendador
Explore estos ejemplos integrados de recomendación. Para más información sobre los ejemplos, ábralos y vea los comentarios del componente en el diseñador.
| Título de ejemplo | Descripción |
|---|---|
| Recomendación basada en Wide & Deep. Predicción de clasificación de restaurantes | Compile un motor de recomendación de restaurante a partir de las características y las clasificaciones de los usuarios y el restaurante. |
| Recomendación. Tweets de clasificación de películas | Cree un motor de recomendación de películas a partir de características de los usuarios/las películas y valoraciones. |
Utilidad
Obtenga más información sobre los ejemplos que muestran las características y utilidades de aprendizaje automático. Para más información sobre los ejemplos, ábralos y vea los comentarios del componente en el diseñador.
| Título de ejemplo | Descripción |
|---|---|
| Clasificación binaria con el modelo de Vowpal Wabbit: predicción de ingresos para adultos | Vowpal Wabbit es un sistema de aprendizaje automático que amplía las fronteras del aprendizaje automático con técnicas como el aprendizaje en línea, el uso de hash, la clase AllReduce, las reducciones, learning2search y el aprendizaje activo e interactivo. En este ejemplo se muestra cómo usar el modelo de Vowpal Wabbit para compilar el modelo de clasificación binaria. |
| Uso de Script R personalizado. Predicción de retrasos de vuelos | Use el Script R personalizado para predecir si un vuelo de pasajeros programado se retrasará más de 15 minutos. |
| Validación cruzada para clasificación binaria. Predicción de ingresos para adultos | Use la validación cruzada para crear un clasificador binario para los ingresos para los adultos. |
| Importancia de la característica de permutación | Use la importancia de la característica de permutación a fin de calcular las clasificaciones de importancia del conjunto de datos de prueba. |
| Parámetros de optimización para la clasificación binaria. Predicción de ingresos para adultos | Utilice los hiperparámetros del modelo de optimización para encontrar los óptimos al crear un clasificador binario. |
Conjuntos de datos
Cuando se crea una canalización nueva en el diseñador de Azure Machine Learning, de manera predeterminada se incluyen diversos conjuntos de datos de ejemplo. Las canalizaciones de ejemplo de la página principal del diseñador utilizan estos conjuntos de datos de ejemplo.
Los conjuntos de datos de ejemplo están disponibles en la categoría Datasets-Samples. Puede encontrar esto en la paleta del componente a la izquierda del lienzo del diseñador. Puede usar cualquiera de estos conjuntos de datos en su propia canalización arrastrándolo al lienzo.
| Nombre del conjunto de datos | Descripción del conjunto de datos |
|---|---|
| Conjunto de datos de clasificación binaria de ingresos en el censo de adultos | Subconjunto de la base de datos del censo de 1994 en el que se utilizan adultos trabajadores a partir de 16 años con un índice de ingresos ajustado de > 100. Uso Clasificar personas utilizando valores demográficos para predecir si una persona gana más de 50 000 al año. Investigación relacionada: Kohavi, R., Becker, B., (1996). Repositorio de Machine Learning de UCI. Irvine, CA: Universidad de California, Facultad de Ciencias de la Computación y de la Información |
| Información sobre los precios de los automóviles (datos sin procesar) | Información acerca de automóviles por marca y modelo, incluido el precio, características como el número de cilindros y el consumo en relación a la distancia recorrida, así como una puntuación de riesgo para aseguradoras. La puntuación de riesgo está asociada inicialmente a un precio automático. Después, se ajusta a un riesgo real en un proceso que los actuarios conocen como simbología. Un valor de +3 indica que es arriesgado, y un valor de -3 indica que probablemente es seguro. Uso Predecir la puntuación de riesgo por características utilizando una clasificación de regresión o de múltiples variantes. Investigación relacionada: Schlimmer, J.C (1987). Repositorio de Machine Learning de UCI. Irvine, CA: Universidad de California, Facultad de Ciencias de la Computación y de la Información. |
| Etiquetas de apetencia CRM compartidas | Etiquetas del concurso sobre la previsión de relaciones con los clientes de KDD Cup 2009 (orange_small_train_appetency.labels). |
| Etiquetas de rotación de clientes de CRM compartidas | Etiquetas del concurso sobre la previsión de relaciones con los clientes de KDD Cup 2009 (orange_small_train_churn.labels). |
| Conjunto de datos CRM compartido | Estos datos están relacionados con el concurso sobre la previsión de relaciones con los clientes de KDD Cup 2009 (orange_small_train.data.zip). El conjunto de datos contiene 50.000 clientes de la empresa de telecomunicaciones francesa Orange. Cada cliente tiene 230 características anónimas, 190 de las cuales son numéricas y 40, categóricas. Las características están muy dispersas. |
| Etiquetas de mejora de ventas de CRM compartidas | Etiquetas del concurso sobre la previsión de relaciones con los clientes de KDD Cup 2009 (orange_large_train_upselling.labels) |
| Datos de retrasos de vuelos | Datos de rendimiento sobre puntualidad en vuelos de pasajeros recopilados en TranStats por el Departamento de Transporte de EE.UU. (On-Time). El conjunto de datos abarca el periodo comprendido entre abril y octubre de 2013. Antes de cargarlo en el diseñador, el conjunto de datos se ha procesado como sigue: - Se filtró el conjunto de datos para centrarse únicamente en los 70 aeropuertos con más tráfico del territorio continental de EE. UU. - Los vuelos cancelados se etiquetaron como retrasados más de 15 minutos - Los vuelos desviados se quitaron de la muestra - Se seleccionaron las siguientes columnas: Year, Month, DayofMonth, DayOfWeek, Carrier, OriginAirportID, DestAirportID, CRSDepTime, DepDelay, DepDel15, CRSArrTime, ArrDelay, ArrDel15, Cancelled |
| Conjunto de datos UCI de tarjeta de crédito alemana | El conjunto de datos Statlog de UCI (tarjeta de crédito alemana) (Statlog+German+Credit+Data), con el archivo german.data. El conjunto de datos clasifica a las personas, descritas por un conjunto de atributos, según si su riesgo de crédito es bajo o alto. Cada ejemplo representa a una persona. Hay 20 características, tanto numéricas como categóricas, y una etiqueta binaria (el valor del riesgo de crédito). Las partidas de riesgo de crédito alto tienen la etiqueta = 2, mientras que las partidas con riesgo de crédito bajo tienen la etiqueta = 1. El coste derivado de clasificar incorrectamente como alto un ejemplo de riesgo bajo es 1, mientras que, en el caso de clasificar incorrectamente como bajo un ejemplo de riesgo alto, el coste es 5. |
| Títulos de películas en IMDB | El conjunto de datos contiene información sobre películas que se han valorado en tweets de X: id. de película en IMDB, nombre, género y año de producción. Hay 17.000 películas en el conjunto de datos. El conjunto de datos se introdujo en el documento "S. Dooms, T. De Pessemier y L. Martens. MovieTweetings: un conjunto de datos sobre valoración de películas recopilado de Twitter. Taller de micromecenazgo y cálculo humano para sistemas de recomendación, CrowdRec en RecSys 2013." |
| Clasificaciones de películas | El conjunto de datos es una versión extendida del conjunto de datos Tweets sobre películas. El conjunto de datos tiene 170 000 valoraciones de películas, extraídas de tweets de X bien estructurados. Cada instancia representa un tweet y es una tupla: id. de usuario, id. de película en IMDB, valoración, marca de tiempo, número de favoritos para ese tweet y número de retweets de ese tweet. A. Said, S. Dooms, B. Loni y D. Tikk proporcionaron el conjunto de datos para el Concurso de sistemas de recomendación 2014. |
| Conjunto de datos del tiempo | Observaciones meteorológicas en tierra por hora de la NOAA (datos combinados del 201304 al 201310). Los datos meteorológicos abarcan las observaciones de las estaciones meteorológicas de los aeropuertos, durante el período que comprende desde abril hasta octubre de 2013. Antes de cargarlo en el diseñador, el conjunto de datos se ha procesado como sigue: - Se asignaron los identificadores de las estaciones meteorológicas a los identificadores de aeropuerto correspondientes - Se excluyeron las estaciones meteorológicas no asociadas a los 70 aeropuertos con mayor tráfico - La columna Date se separó en columnas independientes con los valores Year, Month y Day - Se seleccionaron las siguientes columnas: AirportID, Year, Month, Day, Time, TimeZone, SkyCondition, Visibility, WeatherType, DryBulbFarenheit, DryBulbCelsius, WetBulbFarenheit, WetBulbCelsius, DewPointFarenheit, DewPointCelsius, RelativeHumidity, WindSpeed, WindDirection, ValueForWindCharacter, StationPressure, PressureTendency, PressureChange, SeaLevelPressure, RecordType, HourlyPrecip, Altimeter |
| Conjunto de datos de SP 500 de Wikipedia | Los datos se han extraído de Wikipedia (https://www.wikipedia.org/) y se basan en artículos de cada empresa del índice S&P 500, almacenados como datos XML. Antes de cargarlo en el diseñador, el conjunto de datos se ha procesado como sigue: - Se extrajo el contenido de texto para cada empresa específica - Se eliminó el formato wiki - Se eliminaron los caracteres no alfanuméricos - Se convirtió todo el texto a minúscula - Se agregaron las categorías de empresas conocidas Tenga en cuenta que no se ha encontrado ningún artículo para algunas empresas, por lo que el número de registros es inferior a 500. |
| Datos de características de restaurantes | Un conjunto de metadatos acerca de restaurantes y sus características, como el tipo de comida, el estilo de comedor y la ubicación. Uso Usar este conjunto de datos, en combinación con los otros dos conjuntos de datos de restaurantes, para entrenar y probar un sistema de recomendaciones. Investigación relacionada: Bache, K. y Lichman, M. (2013). Repositorio de Machine Learning de UCI. Irvine, CA: Universidad de California, Facultad de Ciencias de la Computación y de la Información. |
| Valoraciones de restaurantes | Contiene valoraciones que los usuarios realizan sobre restaurantes en una escala de 0 a 2. Uso Usar este conjunto de datos, en combinación con los otros dos conjuntos de datos de restaurantes, para entrenar y probar un sistema de recomendaciones. Investigación relacionada: Bache, K. y Lichman, M. (2013). Repositorio de Machine Learning de UCI. Irvine, CA: Universidad de California, Facultad de Ciencias de la Computación y de la Información. |
| Datos de los clientes de restaurantes | Conjunto de metadatos sobre clientes que incluye información demográfica y preferencias. Uso Usar este conjunto de datos, en combinación con los otros dos conjuntos de datos de restaurantes, para entrenar y probar un sistema de recomendaciones. Investigación relacionada: Bache, K. y Lichman, M. (2013). Repositorio de Machine Learning de UCI, Irvine, CA: Universidad de California, Facultad de Ciencias de la Computación y de la Información. |
Limpieza de recursos
Importante
Los recursos que creó pueden usarse como requisitos previos de otros tutoriales y artículos de procedimientos de Azure Machine Learning.
Eliminar todo el contenido
Si no va a usar nada de lo que ha creado, elimine el grupo de recursos completo para que no le genere gastos.
En Azure Portal, seleccione Grupos de recursos en la parte izquierda de la ventana.
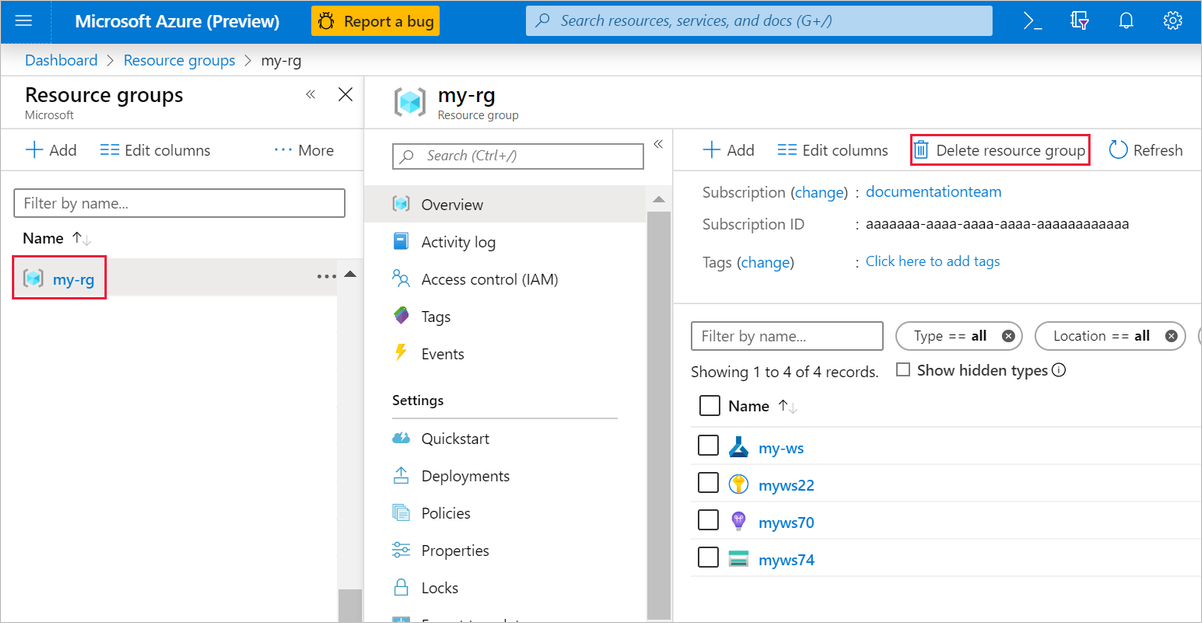
En la lista, seleccione el grupo de recursos que creó.
Seleccione Eliminar grupo de recursos.
Al eliminar el grupo de recursos también se eliminan todos los recursos que creó en el diseñador.
Eliminación de recursos individuales
En diseñador donde creó el experimento, elimine recursos individuales; para ello, selecciónelos y, luego, haga clic en el botón Eliminar.
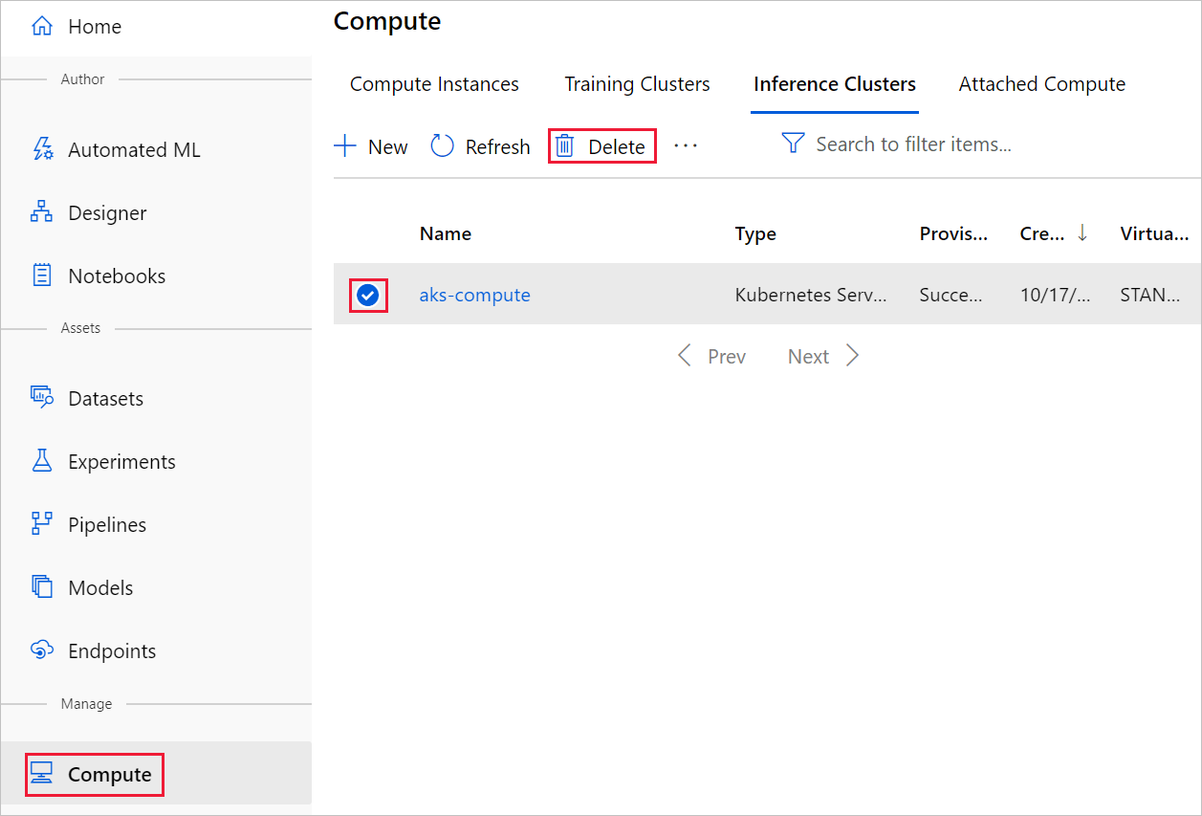
El destino de proceso que ha creado aquí se escala automáticamente a cero nodos cuando no se usa. Esta acción se lleva a cabo para minimizar los cargos. Si quiere eliminar el destino de proceso, siga estos pasos:
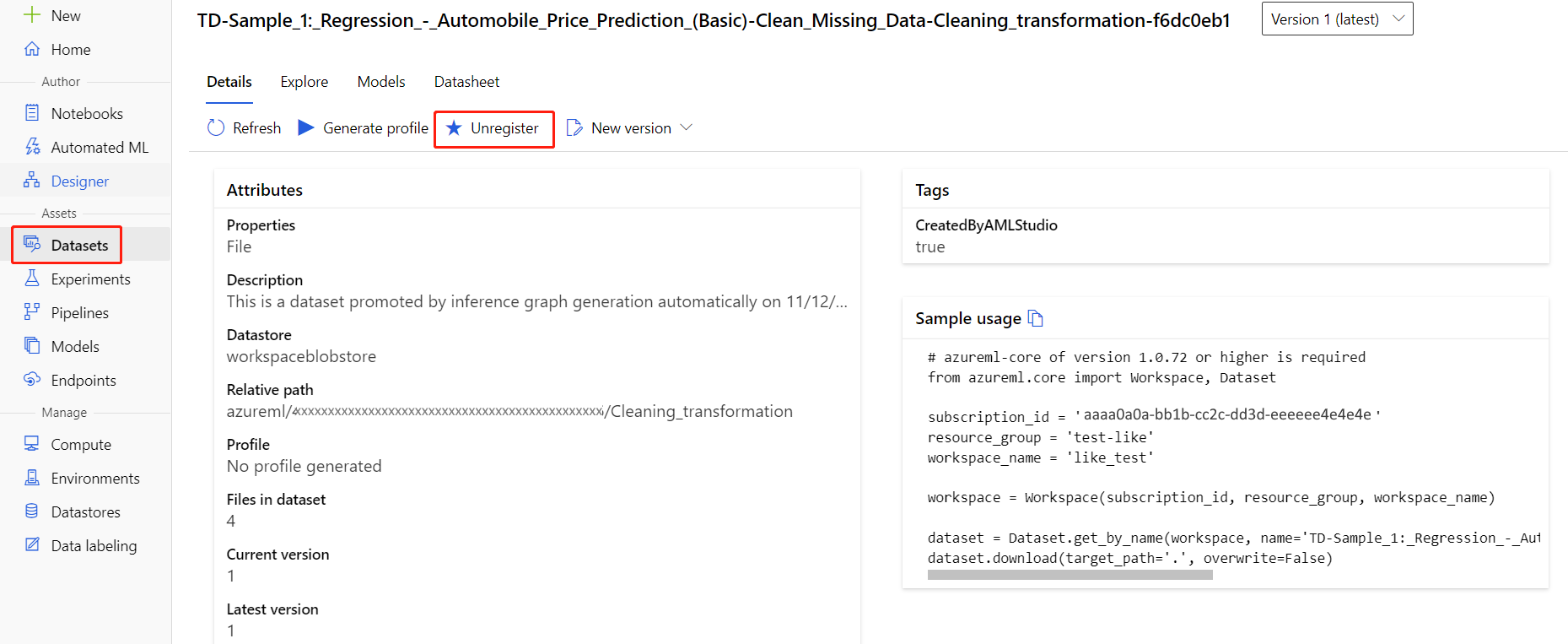
Puede anular el registro de los conjuntos de datos del área de trabajo seleccionando cada conjunto de datos y Anular el registro.
Para eliminar un conjunto de datos, vaya a la cuenta de almacenamiento mediante Azure Portal o el Explorador de Azure Storage y elimine manualmente esos recursos.
Pasos siguientes
Aprenda los aspectos fundamentales del análisis predictivo y del aprendizaje automático con el Tutorial: Predicción del precio de un automóvil con el diseñador