Ejecución de modelos de Azure Machine Learning desde Fabric mediante puntos de conexión por lotes (versión preliminar)
SE APLICA A: Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
En este artículo, aprenderá a consumir implementaciones por lotes de Azure Machine Learning desde Microsoft Fabric. Aunque el flujo de trabajo usa modelos que se implementan en puntos de conexión por lotes, también admite el uso de implementaciones de canalización por lotes de Fabric.
Importante
Esta característica actualmente está en su versión preliminar pública. Esta versión preliminar se ofrece sin un Acuerdo de Nivel de Servicio y no se recomienda para cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas.
Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
Requisitos previos
- Obtenga una suscripción a Microsoft Fabric. También puede registrarse para obtener una evaluación gratuita de Microsoft Fabric.
- Inicie sesión en Microsoft Fabric.
- Suscripción a Azure. Si no tiene una suscripción de Azure, cree una cuenta gratuita antes de empezar. Pruebe la versión gratuita o de pago de Azure Machine Learning.
- Un área de trabajo de Azure Machine Learning. Si no tiene un área de trabajo, siga los pasos descritos en Cómo administrar áreas de trabajo para crear una.
- Asegúrese de tener los permisos siguientes en el área de trabajo:
- Crear o administrar implementaciones y puntos de conexión por lotes: usar los roles de Propietario, Colaborador o un rol personalizado que permita
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*. - Crear implementaciones de ARM en el grupo de recursos del área de trabajo: use roles de Propietario, Colaborador o un rol personalizado que permita
Microsoft.Resources/deployments/writeen el grupo de recursos donde se implemente el área de trabajo.
- Crear o administrar implementaciones y puntos de conexión por lotes: usar los roles de Propietario, Colaborador o un rol personalizado que permita
- Asegúrese de tener los permisos siguientes en el área de trabajo:
- Un modelo implementado en un punto de conexión por lotes. Si no tiene uno, siga los pasos descritos en Implementación de modelos para la puntuación en puntos de conexión por lotes para crear uno.
- Descargue el conjunto de datos de ejemplo heart-unlabeled.csv que se usará para la puntuación.
Architecture
Azure Machine Learning no puede acceder directamente a los datos almacenados en OneLake de Fabric. Sin embargo, sí puede usar la funcionalidad de OneLake para crear accesos directos dentro de una instancia de almacén de datos de lago Lakehouse para leer y escribir datos almacenados en Azure Data Lake Gen2. Dado que Azure Machine Learning admite el almacenamiento de Azure Data Lake Gen2, esta configuración le permite usar Fabric y Azure Machine Learning juntos. La arquitectura de datos es la siguiente:

Configuración del acceso a datos
Para permitir que Fabric y Azure Machine Learning lean y escriban los mismos datos sin tener que copiarlos, puede aprovechar los accesos directos de OneLake y los almacenes de datos de Azure Machine Learning. Al apuntar un acceso directo de OneLake y un almacén de datos a la misma cuenta de almacenamiento, puede asegurarse de que tanto Fabric como Azure Machine Learning leen y escriben en los mismos datos subyacentes.
En esta sección, creará o identificará una cuenta de almacenamiento que se usará para almacenar la información que consumirá el punto de conexión por lotes y que los usuarios de Fabric verán en OneLake. Fabric solamente admite cuentas de almacenamiento con nombres jerárquicos habilitados, como Azure Data Lake Gen2.
Creación de un acceso directo de OneLake a la cuenta de almacenamiento
En Fabric, abra la experiencia de ingeniería de datos Synapse.
En el panel izquierdo, seleccione el área de trabajo de Fabric para abrirlo.
Abra la instancia de almacén de datos de lago Lakehouse que usará para configurar la conexión. Si aún no tiene una instancia de almacén de datos de lago, vaya a la experiencia de ingeniería de datos para crear una instancia de lakehouse. En este ejemplo, se usa una instancia de lakehouse denominada de confianza.
En la barra de navegación de la izquierda, abra más opciones para Archivosy, a continuación, seleccione Nuevo acceso directo para abrir el asistente.
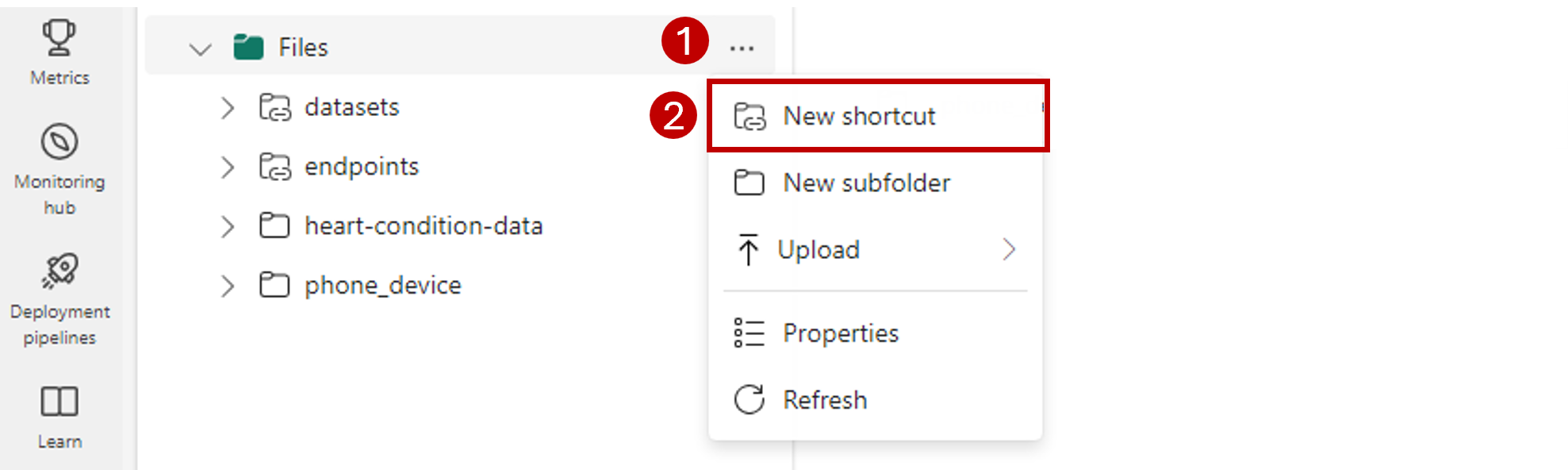
Seleccione la opción Azure Data Lake Storage Gen2.

En la sección Configuración de conexión, pegue la dirección URL asociada a la cuenta de almacenamiento de Azure Data Lake Gen2.
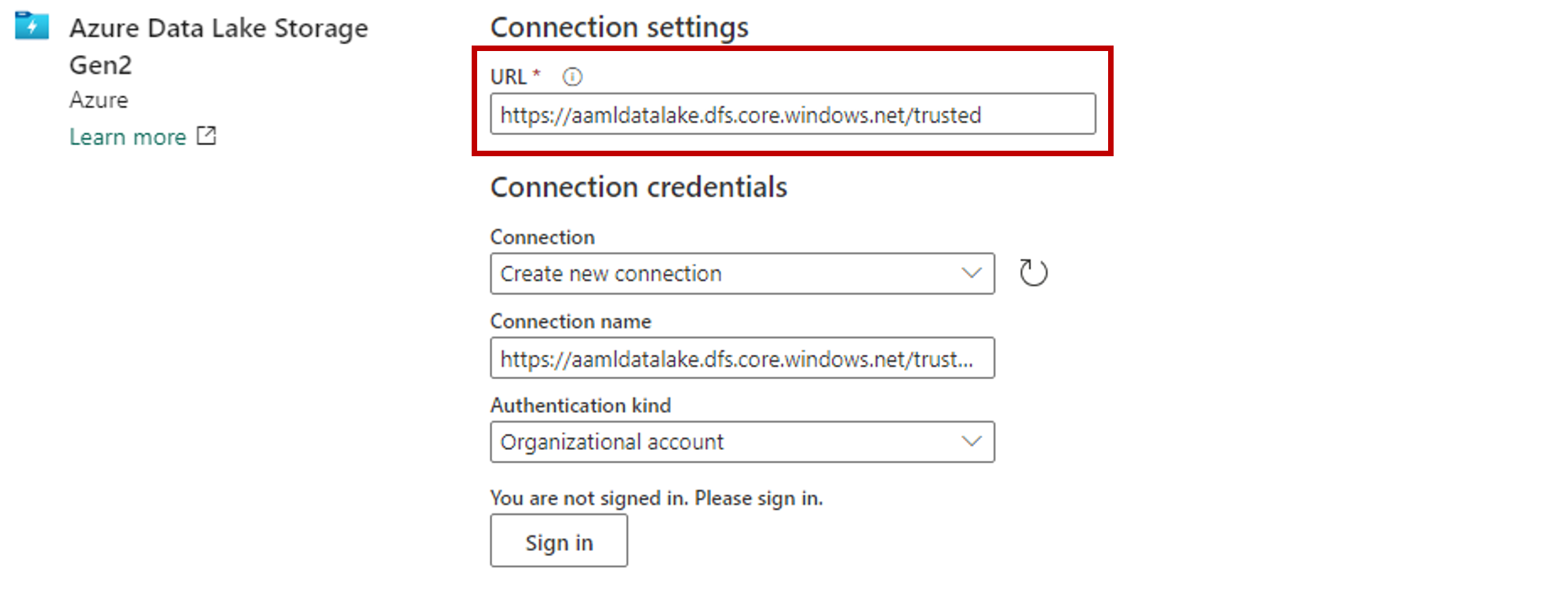
En la sección Credenciales de conexión:
- En Conexión, seleccione Crear nueva conexión.
- Para Nombre de conexión, mantenga el valor que figura rellenado de forma predeterminada.
- Para Tipo de autenticación, seleccione Cuenta de organización para usar las credenciales del usuario conectado a través de OAuth 2.0.
- Seleccione Iniciar sesión.
Seleccione Siguiente.
Si es necesario, configure la ruta de acceso al acceso directo en relación con la cuenta de almacenamiento. Use esta opción para configurar la carpeta a la que apuntará el acceso directo.
Configure el Nombre del acceso directo. Este nombre será un camino dentro del almacén de datos de lago. En este ejemplo, asigne al acceso directo el nombre datasets.
Guarde los cambios.



Creación de un almacén de datos que apunte a la cuenta de almacenamiento
Abra el Estudio de Azure Machine Learning.
Cargue su área de trabajo de Azure Machine Learning.
Vaya a la sección Datos.
Seleccione la pestaña Almacenes de datos.
Seleccione Crear.
Configure el almacén de datos como sigue:
En Nombre del almacén de datos, escriba trusted_blob.
Para el Tipo de almacén de datos, seleccione Azure Blob Storage.
Sugerencia
¿Por qué debe configurar Azure Blob Storage en lugar de Azure Data Lake Gen2? Los puntos de conexión por lotes solamente pueden escribir predicciones en cuentas de Blob Storage. Sin embargo, cada cuenta de almacenamiento de Azure Data Lake Gen2 también es una cuenta de almacenamiento de blobs; por lo tanto, se pueden usar indistintamente.
Seleccione la cuenta de almacenamiento desde el asistente, con el Id. de suscripción, la Cuenta de almacenamiento y el Contenedor de blobs (sistema de archivos).
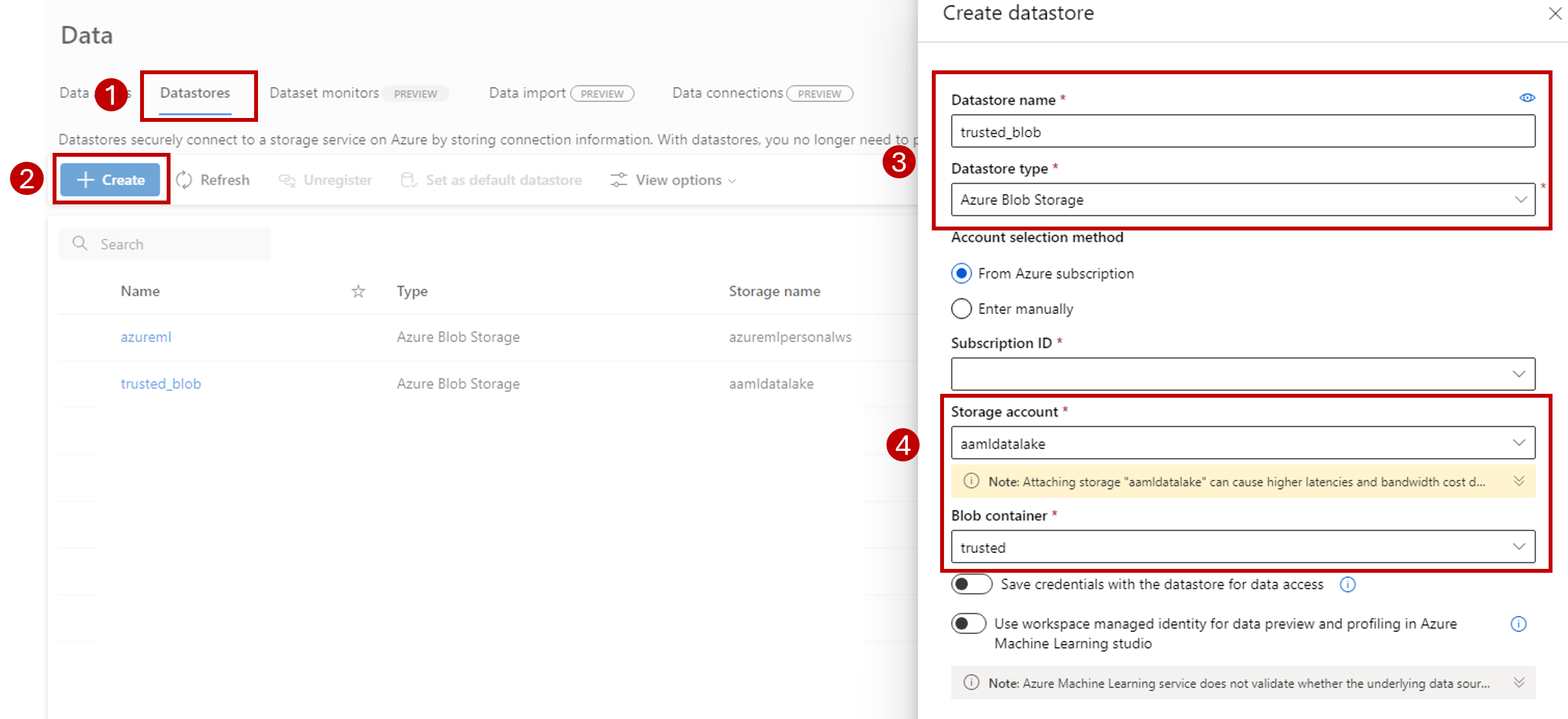
Seleccione Crear.
Asegúrese de que el proceso en el que se ejecuta el punto de conexión por lotes tiene permisos para montar los datos en esta cuenta de almacenamiento. Aunque el acceso todavía lo concede la identidad que invoca el punto de conexión, el proceso en el que se ejecuta el punto de conexión por lotes debe tener permiso para montar la cuenta de almacenamiento que usted proporcione. Para más información, consulte Acceso a servicios de almacenamiento.
Cargar un conjunto de datos de ejemplo
Cargue datos de ejemplo para que el punto de conexión los use como entrada:
Vaya al área de trabajo de Fabric.
Seleccione la instancia de almacén de datos de lago donde haya creado el acceso directo.
Vaya al acceso directo de conjuntos de datos.
Cree una carpeta para almacenar el conjunto de datos de ejemplo que desee puntuar. Asigne a la carpeta el nombre uci-heart-unlabeled.
Use la opción Obtener datos y seleccione Cargar archivos para cargar el conjunto de datos de ejemplo heart-unlabeled.csv.
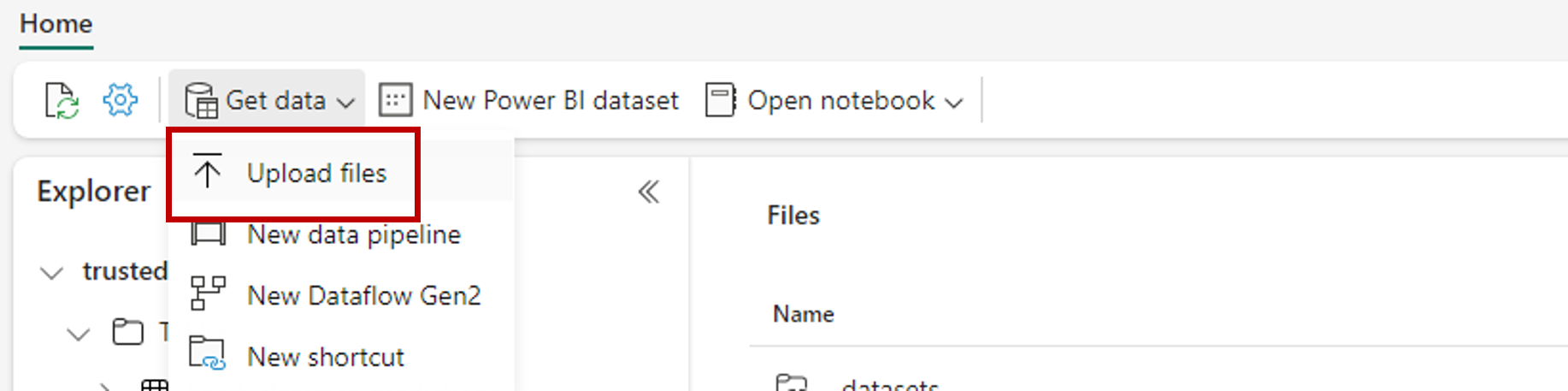
Cargue los datos de ejemplo.
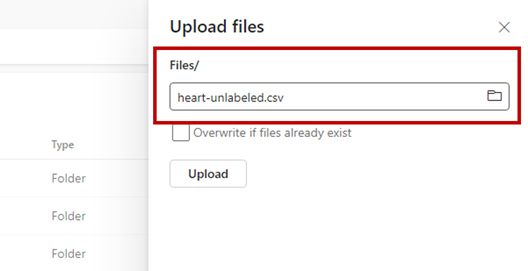
El archivo de ejemplo está listo para consumirse. Anote la ruta de acceso a la ubicación donde lo ha guardado.


Creación de una canalización de inferencia por lotes para Fabric
En esta sección, creará una canalización de inferencia de Fabric a lotes en el área de trabajo de Fabric existente e invocará puntos de conexión por lotes.
Vuelva a la experiencia de ingeniería de datos (si ya había salido de ella), mediante el icono del selector de experiencia en la esquina inferior izquierda de la página principal.
Abra el área de trabajo de Fabric.
En la sección Nueva de la página principal, seleccione Canalización de datos.
Asigne un nombre a la canalización y seleccione Crear.
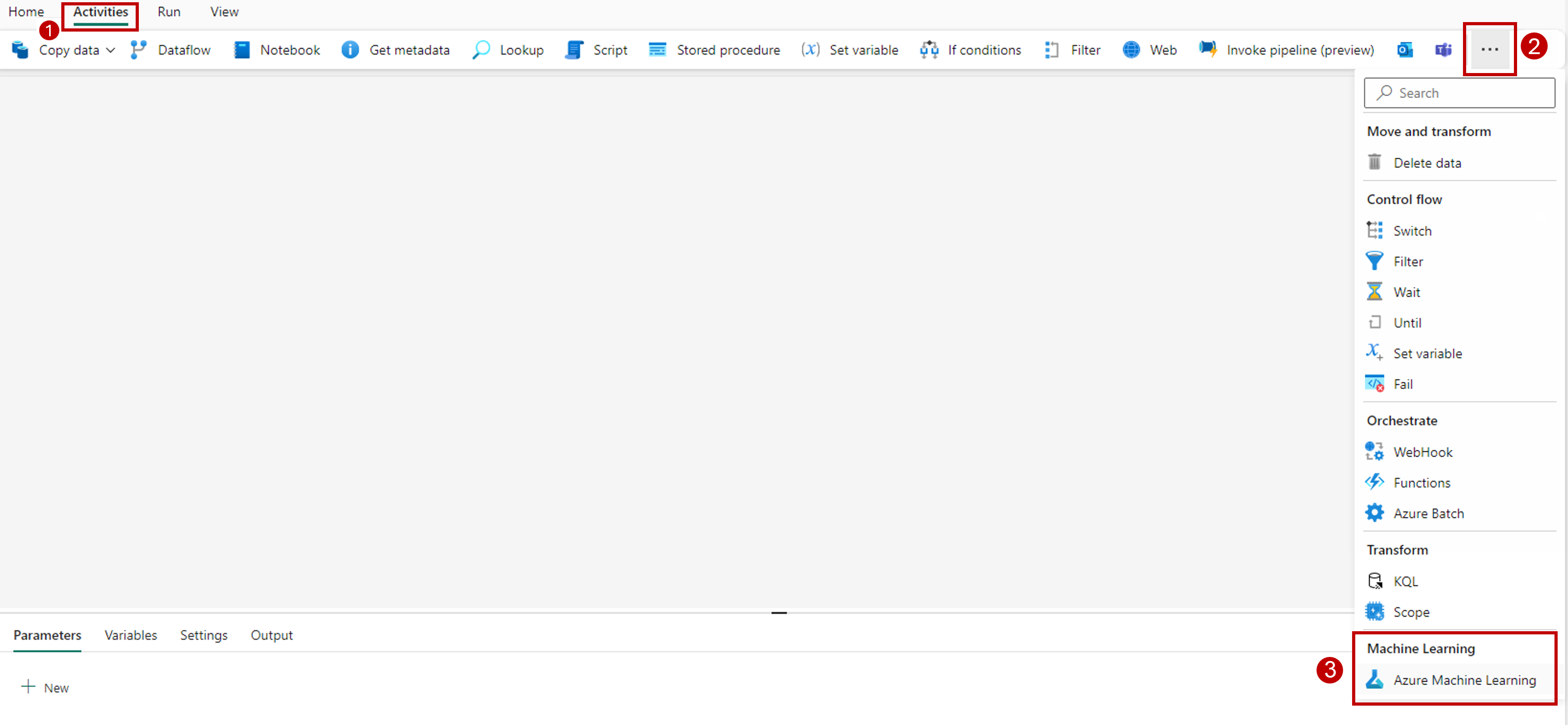
Seleccione la pestaña Actividades en la barra de herramientas del lienzo del diseñador.
Seleccione más opciones al final de la pestaña y seleccione Azure Machine Learning.
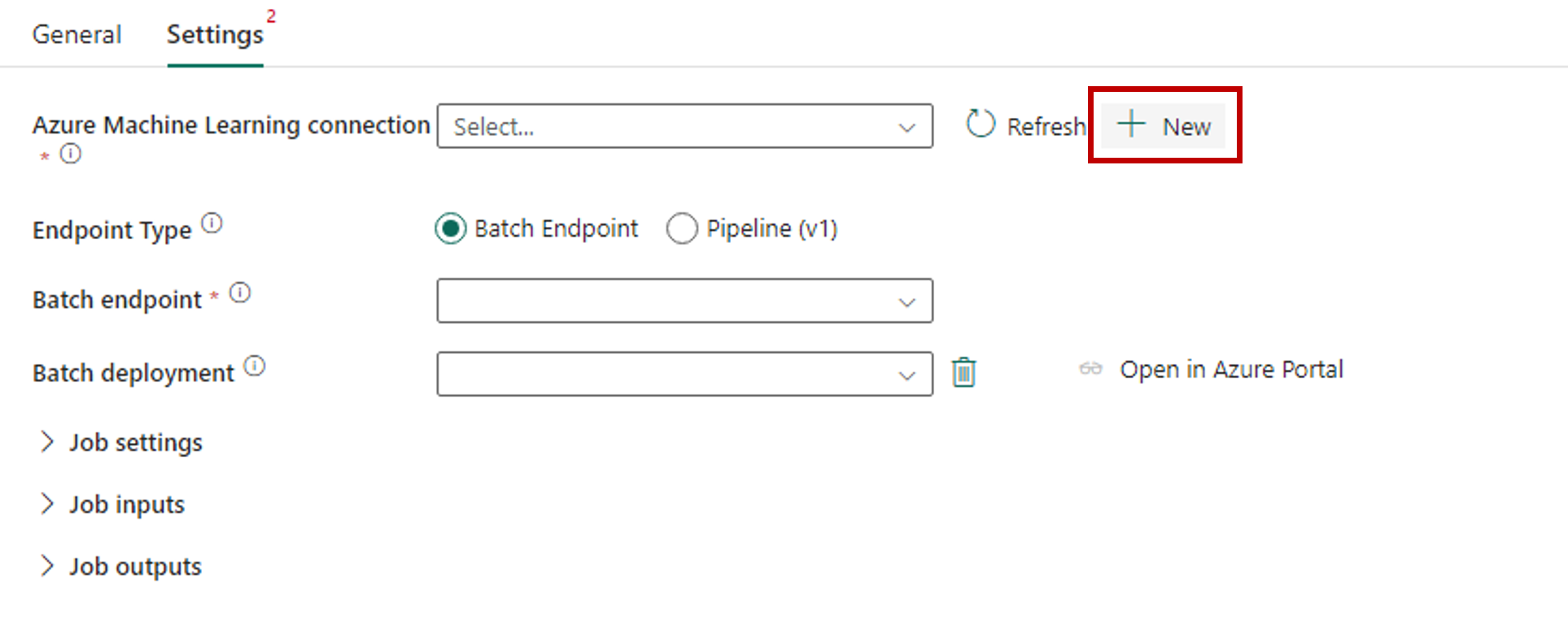
Vaya a la pestaña Configuración y configure la actividad de la siguiente manera:
Seleccione Nueva junto a conexión de Azure Machine Learning para crear una nueva conexión al área de trabajo de Azure Machine Learning que contiene la implementación.
En la sección Configuración de conexión del asistente para creación, especifique los valores del Id. de suscripción, el Nombre del grupo de recursos y el Nombre del área de trabajo donde se implementa el punto de conexión.
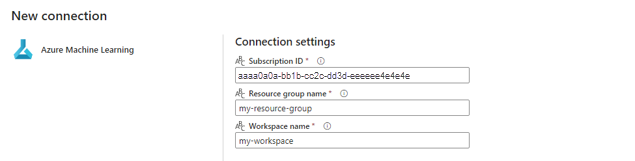
En la sección Credenciales de conexión, seleccione Cuenta de organización como valor del Tipo de autenticación para la conexión. Cuenta de organización usa las credenciales del usuario conectado. Como alternativa, puede usar Entidad de servicio. En la configuración de producción, se recomienda usar una entidad de servicio. Independientemente del tipo de autenticación, asegúrese de que la identidad asociada a la conexión tiene los derechos necesarios para llamar al punto de conexión por lotes que ha implementado.
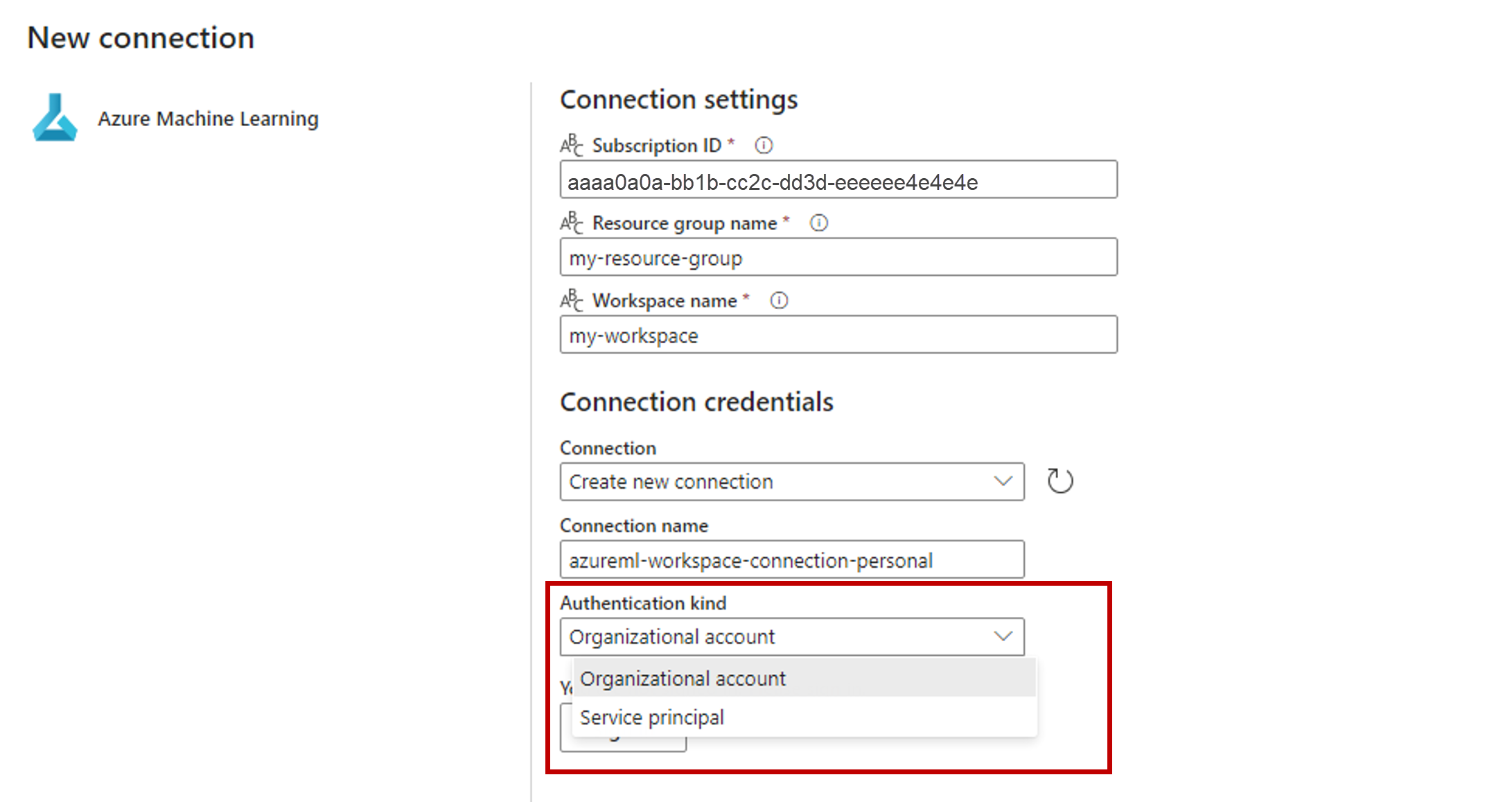
Guarde la conexión. Una vez seleccionada la conexión, Fabric rellena automáticamente los puntos de conexión por lotes disponibles en el área de trabajo seleccionada.
Para Punto de conexión por lotes, seleccione el punto de conexión por lotes al que desea llamar. En este ejemplo, seleccione heart-classifier-....
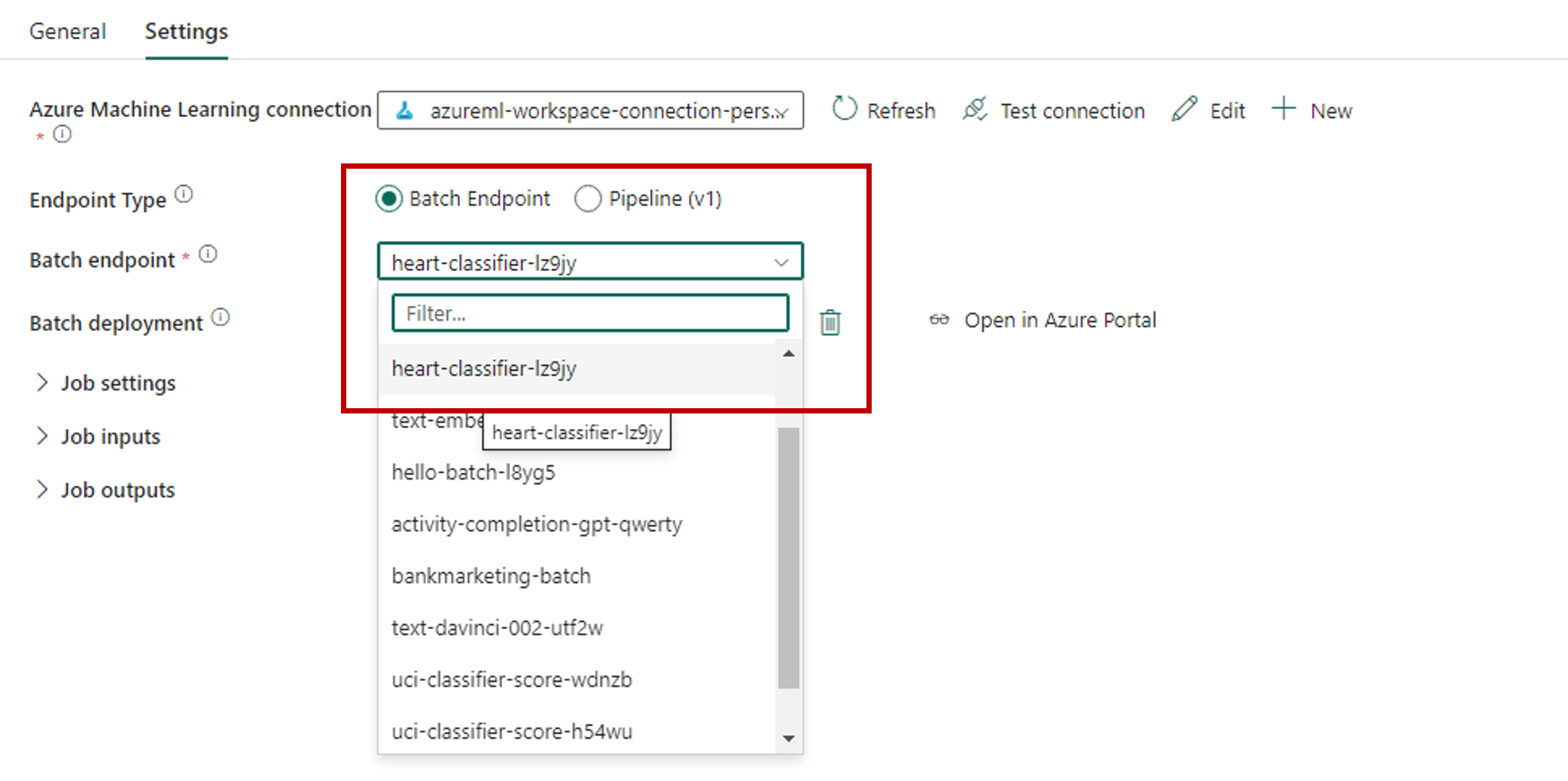
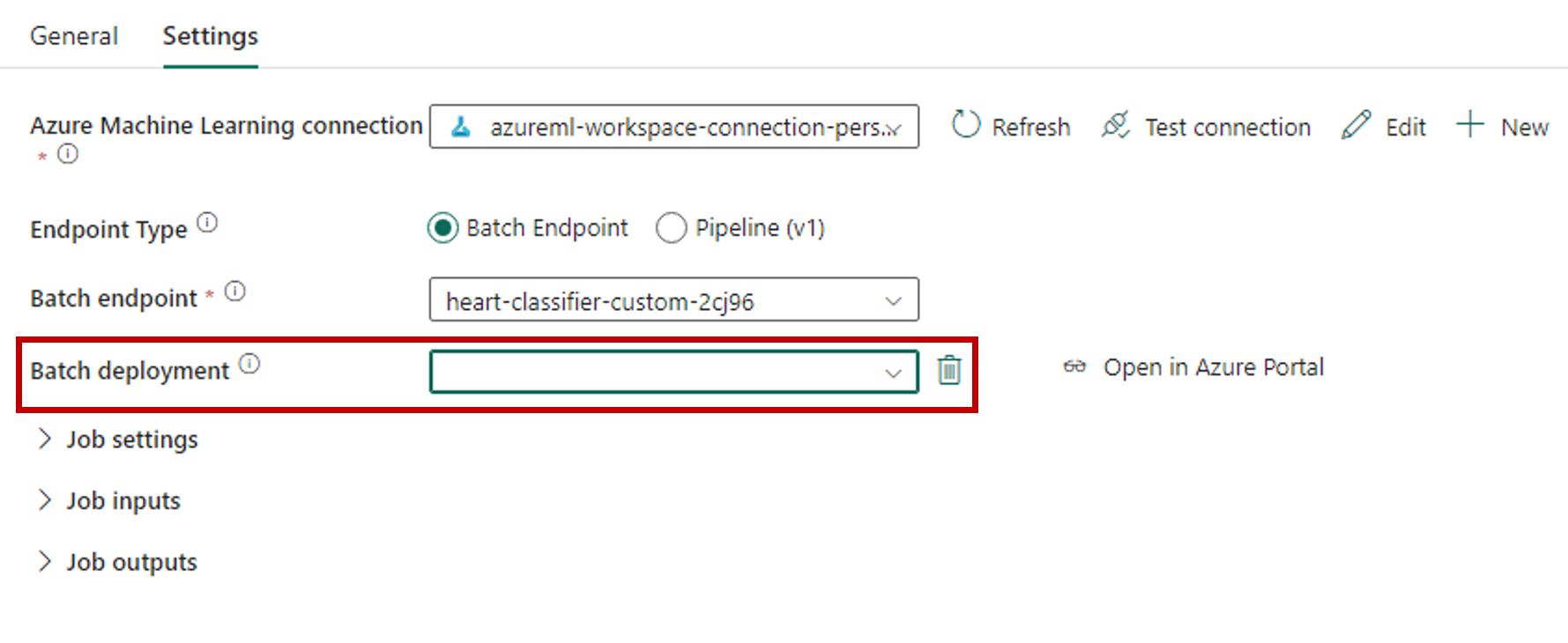
La sección Implementación por lotes se rellena automáticamente con las implementaciones disponibles en el punto de conexión.
Para Implementación por lotes, seleccione una implementación específica de la lista, si es necesario. Si no selecciona una implementación, Fabric invoca la implementación Predeterminada en el punto de conexión, lo que permite al creador del punto de conexión por lotes decidir a qué implementación se llama. En la mayoría de los escenarios, lo más interesante será mantener este comportamiento predeterminado.







Configuración de entradas y salidas para el punto de conexión por lotes
En esta sección, configurará entradas y salidas desde el punto de conexión por lotes. Las entradas a los puntos de conexión por lotes proporcionan datos y parámetros necesarios para ejecutar el proceso. La canalización por lotes de Azure Machine Learning en Fabric admite tanto implementaciones de modelos como implementaciones de canalización. El número y el tipo de entradas que proporcione dependen del tipo de implementación. En este ejemplo, se usa una implementación de modelo que requiere exactamente una entrada y genera una salida.
Para obtener más información sobre las entradas y salidas del punto de conexión por lotes, consulte Descripción de las entradas y salidas en puntos de conexión por lotes.
Configuración de la sección de entradas
Configure la sección Entradas de trabajo como se indica a continuación:
Expanda la sección Entradas de trabajo.
Seleccione Nuevo para agregar una nueva entrada al punto de conexión.
Asigne un nombre a la entrada
input_data. Puesto que usa una implementación de modelos, puede usar cualquier nombre. Sin embargo, para las implementaciones de canalización, debe indicar el nombre exacto de la entrada que espera el modelo.Seleccione el menú desplegable situado junto a la entrada que acaba de agregar para abrir la propiedad de la entrada (nombre y campo de valor).
Escriba
JobInputTypeen el campo Nombre para indicar el tipo de entrada que quiere crear.Escriba
UriFolderen el campo Valor para indicar que la entrada es una ruta de acceso de carpeta. Otros valores admitidos para este campo son UriFile (una ruta de acceso de archivo) o Literal (cualquier valor literal como cadena o entero). Debe usar el tipo correcto que espera la implementación.Seleccione el signo más (+) situado junto a la propiedad para agregar otra propiedad a esta entrada.
Escriba
Urien el campo Nombre para indicar la ruta de acceso a los datos.Escriba
azureml://datastores/trusted_blob/datasets/uci-heart-unlabeled, la ruta de acceso para buscar los datos, en el campo Valor. Aquí se usa una ruta de acceso que conduce a la cuenta de almacenamiento que está vinculada a OneLake en Fabric y a Azure Machine Learning. azureml://datastores/trusted_blob/datasets/uci-heart-unlabeled es la ruta de acceso a los archivos CSV con los datos de entrada esperados para el modelo que se implementa en el punto de conexión por lotes. También puede usar una ruta de acceso directa a la cuenta de almacenamiento, comohttps://<storage-account>.dfs.azure.com.
Sugerencia
Si la entrada es de tipo Literal, reemplace la propiedad
Uripor "Valor".
Si el punto de conexión requiere más entradas, repita los pasos anteriores para cada una de ellas. En este ejemplo, las implementaciones de modelos requieren exactamente una entrada.
Configuración de la sección de salidas
Configure la sección Salidas de trabajo como se indica a continuación:
Expanda la sección Salidas de trabajo.
Seleccione Nueva para agregar una nueva salida al punto de conexión.
Asigne el nombre
output_dataa la salida. Puesto que usa una implementación de modelos, puede usar cualquier nombre. Sin embargo, para las implementaciones de canalización, debe indicar el nombre exacto de la salida que espera el modelo.Seleccione el menú desplegable situado junto a la salida que acaba de agregar para abrir la propiedad de la salida (nombre y campo de valor).
Escriba
JobOutputTypeen el campo Nombre para indicar el tipo de salida que quiere crear.Escriba
UriFileen el campo Valor para indicar que la salida es una ruta de acceso de carpeta. El otro valor admitido para este campo es UriFolder (una ruta de acceso de carpeta). A diferencia de la sección de entrada del trabajo, no se admite Literal (cualquier valor literal como una cadena o un número entero) como salida.Seleccione el signo más (+) situado junto a la propiedad para agregar otra propiedad a esta salida.
Escriba
Urien el campo Nombre para indicar la ruta de acceso a los datos.Escriba
@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv'), la ruta de acceso a donde se debe colocar la salida, en el campo Valor. Los puntos de conexión por lotes de Azure Machine Learning solamente admiten usar rutas de almacenes de datos como salidas. Dado que las salidas deben ser únicas para evitar conflictos, ha usado una expresión dinámica,@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv'), para construir la ruta de acceso.
Si el punto de conexión devuelve más salidas, repita los pasos anteriores para cada una de ellas. En este ejemplo, las implementaciones de modelos producen exactamente una salida.
(Opcional) Configuración de los valores de configuración de trabajo
También puede configurar la Configuración de trabajos agregando las siguientes propiedades:
Para implementaciones de modelos:
| Configuración | Descripción |
|---|---|
MiniBatchSize |
Tamaño del lote. |
ComputeInstanceCount |
Número de instancias de proceso que se van a solicitar desde la implementación. |
Para implementaciones de canalizaciones:
| Configuración | Descripción |
|---|---|
ContinueOnStepFailure |
Indica si la canalización debe detener el procesamiento de nodos después de un error. |
DefaultDatastore |
Indica el almacén de datos predeterminado que se va a usar para las salidas. |
ForceRun |
Indica si la canalización debe obligar a que se ejecuten todos los componentes, incluso si la salida se puede deducir de una ejecución anterior. |
Una vez finalizada la configuración, puede probar la canalización.