Implementación de modelos de aprendizaje automático en Azure
SE APLICA A: Extensión de ML de la CLI de Azure v1Azure ML del SDK de Python v1
Extensión de ML de la CLI de Azure v1Azure ML del SDK de Python v1
Aprenda a implementar el modelo de aprendizaje automático o aprendizaje profundo como un servicio web en la nube de Azure.
Nota
Los puntos de conexión de Azure Machine Learning (v2) proporcionan una experiencia de implementación mejorada y más sencilla. Los puntos de conexión admiten escenarios de inferencia por lotes y en tiempo real. Los puntos de conexión proporcionan una interfaz unificada para invocar y administrar implementaciones de modelos entre tipos de proceso. Consulte ¿Qué son los puntos de conexión de Azure Machine Learning?.
Flujo de trabajo para implementar un modelo
El flujo de trabajo es siempre parecido independientemente de donde implemente el modelo:
- Registre el modelo.
- Prepare un script de entrada.
- Prepare una configuración de inferencia.
- Implemente el modelo localmente para asegurarse de que todo funciona.
- Elija un destino de proceso.
- Implemente el modelo en la nube.
- Pruebe el servicio web resultante.
Para más información sobre los conceptos implicados en el flujo de trabajo de implementación del aprendizaje automático, consulte Administración, implementación y supervisión de modelos con Azure Machine Learning.
Requisitos previos
SE APLICA A: Extensión de ML de la CLI de Azure v1
Importante
Algunos de los comandos de la CLI de Azure de este artículo usan la extensión azure-cli-ml o v1 para Azure Machine Learning. La compatibilidad con la extensión v1 finalizará el 30 de septiembre de 2025. La extensión v1 se podrá instalar y usar hasta esa fecha.
Se recomienda pasar a la extensión ml, o v2, antes del 30 de septiembre de 2025. Para más información sobre la extensión v2, consulte Extensión de la CLI de Azure ML y SDK de Python v2.
- Un área de trabajo de Azure Machine Learning. Para obtener más información, consulte Recursos para crear un área de trabajo.
- Un modelo. En los ejemplos de este artículo se usa un modelo entrenado previamente.
- Una máquina que puede ejecutar Docker, como una instancia de proceso.
Conexión con su área de trabajo
SE APLICA A: Extensión de ML de la CLI de Azure v1
Para ver las áreas de trabajo a las que tiene acceso, use los siguientes comandos:
az login
az account set -s <subscription>
az ml workspace list --resource-group=<resource-group>
Registro del modelo
En una situación común, un servicio de aprendizaje automático implementado necesita los siguientes componentes:
- Recursos que representan el modelo específico que quiere implementar (por ejemplo: un archivo de modelo de PyTorch).
- Código que se va a ejecutar en el servicio que ejecuta el modelo en una entrada determinada.
Azure Machine Learning le permite separar la implementación en dos componentes independientes, de modo que pueda mantener el mismo código y simplemente actualizar el modelo. Definimos el mecanismo por el que se carga un modelo por separado del código como "registrar el modelo".
Al registrar un modelo, se carga el modelo en la nube (en la cuenta de almacenamiento predeterminada del área de trabajo) y, a continuación, se monta en el mismo proceso en el que se ejecuta el servicio web.
En los ejemplos siguientes se muestra cómo registrar un modelo.
Importante
Solo debe usar los modelos que cree u obtenga de un origen de confianza. Debe tratar los modelos serializados como código, porque se han descubierto vulnerabilidades de seguridad en varios formatos conocidos. También, los modelos se pueden entrenar intencionadamente con intenciones malintencionadas para proporcionar resultados inexactos o sesgados.
SE APLICA A: Extensión de ML de la CLI de Azure v1
Los comandos siguientes descargan un modelo y luego lo registran en el área de trabajo de Azure Machine Learning:
wget https://aka.ms/bidaf-9-model -O model.onnx --show-progress
az ml model register -n bidaf_onnx \
-p ./model.onnx \
-g <resource-group> \
-w <workspace-name>
Establezca -p en la ruta de acceso de una carpeta o un archivo que desee registrar.
Para obtener más información sobre az ml model register, vea la documentación de referencia.
Registro de un modelo a partir de un trabajo de entrenamiento de Azure Machine Learning
Si necesita registrar un modelo creado anteriormente por medio de un trabajo de entrenamiento de Azure Machine Learning, puede especificar el experimento, la ejecución y la ruta de acceso al modelo:
az ml model register -n bidaf_onnx --asset-path outputs/model.onnx --experiment-name myexperiment --run-id myrunid --tag area=qna
El parámetro --asset-path hace referencia a la ubicación del modelo en la nube. En este ejemplo, se usa la ruta de acceso de un único archivo. Para incluir varios archivos en el registro del modelo, establezca --asset-path en la ruta de acceso de una carpeta que contiene los archivos.
Para obtener más información sobre az ml model register, vea la documentación de referencia.
Nota:
También puede registrar un modelo desde un archivo local a través del portal de la interfaz de usuario del área de trabajo.
Actualmente, hay dos opciones para cargar un archivo de modelo local en la interfaz de usuario:
- Desde archivos locales, que registrarán un modelo v2.
- Desde archivos locales (según el marco), que registrarán un modelo v1.
Tenga en cuenta que solo los modelos registrados a través de la entrada Desde archivos locales (según el marco) (que se conocen como modelos v1) se pueden implementar como servicios web mediante SDKv1/CLIv1.
Definición de un script de entrada ficticio
El script de entrada recibe los datos enviados a un servicio web implementado y los pasa al modelo. Seguidamente, devuelve la respuesta del modelo al cliente. El script es específico para su modelo. El script de entrada debe entender los datos que el modelo espera y devuelve.
Estas son las dos tareas que debe realizar en el script de entrada:
- Cargar el modelo (mediante una función llamada
init()) - Ejecutar el modelo sobre los datos de entrada (mediante una función llamada
run())
Para la implementación inicial, use un script de entrada ficticio que imprima los datos que recibe.
import json
def init():
print("This is init")
def run(data):
test = json.loads(data)
print(f"received data {test}")
return f"test is {test}"
Guarde este archivo como echo_score.py dentro de un directorio denominado source_dir. Este script ficticio devuelve los datos que le envía, por lo que no usa el modelo. Pero resulta útil para probar que el script de puntuación se está ejecutando.
Definición de una configuración de inferencia
Una configuración de inferencia describe el contenedor de Docker y los archivos que se usarán al inicializar el servicio web. Todos los archivos del directorio de origen, incluidos los subdirectorios, se comprimirán y cargarán en la nube al implementar el servicio web.
La configuración de inferencia siguiente especifica que la implementación del aprendizaje automático usará el archivo echo_score.py del directorio ./source_dir para procesar las solicitudes entrantes y que usará la imagen de Docker con los paquetes de Python especificados en el entorno project_environment.
Puede usar cualquier entorno mantenido de inferencia de Azure Machine Learning como imagen base de Docker al crear el entorno del proyecto. Instalaremos las dependencias necesarias en la parte superior y almacenaremos la imagen de Docker resultante en el repositorio asociado al área de trabajo.
Nota
La carga del directorio de origen de inferencia de Azure Machine Learning no respeta .gitignore ni .amlignore.
SE APLICA A: Extensión de ML de la CLI de Azure v1
Una configuración de inferencia mínima se puede escribir de la siguiente manera:
{
"entryScript": "echo_score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "1"
}
}
Guarde el archivo con el nombre dummyinferenceconfig.json.
Consulte este artículo para obtener una explicación más detallada de las configuraciones de inferencia.
Definición de una configuración de implementación
Una configuración de implementación especifica la cantidad de memoria y los núcleos que necesita el servicio web para ejecutarse. También proporciona detalles de configuración del servicio web subyacente. Por ejemplo, una configuración de implementación permite especificar que el servicio necesita 2 gigabytes de memoria, 2 núcleos de CPU, 1 núcleo de GPU y que desea habilitar el escalado automático.
Las opciones disponibles para una configuración de implementación varían en función del destino de proceso que elija. En una implementación local, lo único que puede especificar es en qué puerto se va a atender el servicio web.
SE APLICA A: Extensión de ML de la CLI de Azure v1
Las entradas del documento deploymentconfig.json se asignan a los parámetros de LocalWebservice.deploy_configuration. En la tabla siguiente se describe la asignación entre las entidades del documento JSON y los parámetros del método:
| Entidad JSON | Parámetro del método | Description |
|---|---|---|
computeType |
N/D | El destino de proceso. Para los destinos locales, el valor tiene que ser local. |
port |
port |
Puerto local en el que se va a exponer el punto de conexión HTTP del servicio. |
Este elemento JSON es un ejemplo de la configuración de implementación que se puede usar con la CLI:
{
"computeType": "local",
"port": 32267
}
Guarde este JSON como un archivo llamado deploymentconfig.json.
Para obtener más información, vea el esquema de implementación.
Implementación del modelo de aprendizaje automático
Ahora está preparado para implementar el modelo.
SE APLICA A: Extensión de ML de la CLI de Azure v1
Reemplace bidaf_onnx:1 por el nombre del modelo y su número de versión.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic dummyinferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Llamada al modelo
Vamos a comprobar que el modelo de eco se implementó correctamente. Debe poder realizar una solicitud de ejecución simple, así como una solicitud de puntuación:
SE APLICA A: Extensión de ML de la CLI de Azure v1
curl -v http://localhost:32267
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Definición de un script de entrada
Ahora es el momento de cargar realmente el modelo. En primer lugar, modifique el script de entrada:
import json
import numpy as np
import os
import onnxruntime
from nltk import word_tokenize
import nltk
def init():
nltk.download("punkt")
global sess
sess = onnxruntime.InferenceSession(
os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model.onnx")
)
def run(request):
print(request)
text = json.loads(request)
qw, qc = preprocess(text["query"])
cw, cc = preprocess(text["context"])
# Run inference
test = sess.run(
None,
{"query_word": qw, "query_char": qc, "context_word": cw, "context_char": cc},
)
start = np.asscalar(test[0])
end = np.asscalar(test[1])
ans = [w for w in cw[start : end + 1].reshape(-1)]
print(ans)
return ans
def preprocess(word):
tokens = word_tokenize(word)
# split into lower-case word tokens, in numpy array with shape of (seq, 1)
words = np.asarray([w.lower() for w in tokens]).reshape(-1, 1)
# split words into chars, in numpy array with shape of (seq, 1, 1, 16)
chars = [[c for c in t][:16] for t in tokens]
chars = [cs + [""] * (16 - len(cs)) for cs in chars]
chars = np.asarray(chars).reshape(-1, 1, 1, 16)
return words, chars
Guarde este archivo como score.py dentro de source_dir.
Observe el uso de la variable de entorno AZUREML_MODEL_DIR para buscar el modelo registrado. Ahora que ha agregado algunos paquetes pip.
SE APLICA A: Extensión de ML de la CLI de Azure v1
{
"entryScript": "score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults",
"nltk",
"numpy",
"onnxruntime"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "2"
}
}
Guarde este archivo como inferenceconfig.json.
Nueva implementación y llamada al servicio
Vuelva a implementar el servicio:
SE APLICA A: Extensión de ML de la CLI de Azure v1
Reemplace bidaf_onnx:1 por el nombre del modelo y su número de versión.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
A continuación, asegúrese de que puede enviar una solicitud post al servicio:
SE APLICA A: Extensión de ML de la CLI de Azure v1
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Elección de un destino de proceso
El destino de proceso que use para hospedar el modelo afectará al costo y la disponibilidad del punto de conexión implementado. Use esta tabla para elegir un destino de proceso adecuado.
| Destino de proceso | Se usa para | Compatibilidad con GPU | Descripción |
|---|---|---|---|
| Servicio web local | Pruebas y depuración | Se usa para pruebas limitadas y solución de problemas. La aceleración de hardware depende del uso de bibliotecas en el sistema local. | |
| Kubernetes de Azure Machine Learning | Inferencia en tiempo real | Sí | Ejecute cargas de trabajo de inferencia en la nube. |
| Azure Container Instances | Inferencia en tiempo real Recomendado solo con fines de desarrollo y pruebas. |
Se usa para cargas de trabajo basadas en CPU a pequeña escala que requieren menos de 48 GB de RAM. No requiere que administre un clúster. Solo es adecuado para los modelos de menos de 1 GB de tamaño. Se admite en el diseñador. |
Nota
Al elegir una SKU de clúster, primero realice el escalado vertical y, luego, el horizontal. Comience con una máquina que tenga el 150 % de la RAM que necesita el modelo, genere un perfil del resultado y busque una máquina que tenga el rendimiento que necesita. Cuando haya aprendido a hacer esto, aumente el número de máquinas para que se adapten a su necesidad de inferencia simultánea.
Nota:
Los puntos de conexión de Azure Machine Learning (v2) proporcionan una experiencia de implementación mejorada y más sencilla. Los puntos de conexión admiten escenarios de inferencia por lotes y en tiempo real. Los puntos de conexión proporcionan una interfaz unificada para invocar y administrar implementaciones de modelos entre tipos de proceso. Consulte ¿Qué son los puntos de conexión de Azure Machine Learning?.
Implementación en la nube
Una vez que haya confirmado que el servicio funciona localmente y ha elegido un destino de proceso remoto, estará listo para la implementación en la nube.
Cambie la configuración de implementación para que se corresponda con el destino de proceso que ha elegido, en este caso Azure Container Instances:
SE APLICA A: Extensión de ML de la CLI de Azure v1
Las opciones disponibles para una configuración de implementación varían en función del destino de proceso que elija.
{
"computeType": "aci",
"containerResourceRequirements":
{
"cpu": 0.5,
"memoryInGB": 1.0
},
"authEnabled": true,
"sslEnabled": false,
"appInsightsEnabled": false
}
Guarde el archivo como re-deploymentconfig.json.
Para más información, consulte esta referencia.
Vuelva a implementar el servicio:
SE APLICA A: Extensión de ML de la CLI de Azure v1
Reemplace bidaf_onnx:1 por el nombre del modelo y su número de versión.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc re-deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Para ver los registros del servicio, use el siguiente comando:
az ml service get-logs -n myservice \
-g <resource-group> \
-w <workspace-name>
Llamada al servicio web remoto
Al implementar de forma remota, es posible que tenga habilitada la autenticación de claves. En el ejemplo siguiente se muestra cómo obtener la clave de servicio con Python para realizar una solicitud de inferencia.
import requests
import json
from azureml.core import Webservice
service = Webservice(workspace=ws, name="myservice")
scoring_uri = service.scoring_uri
# If the service is authenticated, set the key or token
key, _ = service.get_keys()
# Set the appropriate headers
headers = {"Content-Type": "application/json"}
headers["Authorization"] = f"Bearer {key}"
# Make the request and display the response and logs
data = {
"query": "What color is the fox",
"context": "The quick brown fox jumped over the lazy dog.",
}
data = json.dumps(data)
resp = requests.post(scoring_uri, data=data, headers=headers)
print(resp.text)print(service.get_logs())Consulte el artículo sobre aplicaciones cliente para consumir servicios web para obtener más clientes de ejemplo en otros lenguajes.
Configuración de correos electrónicos en el estudio
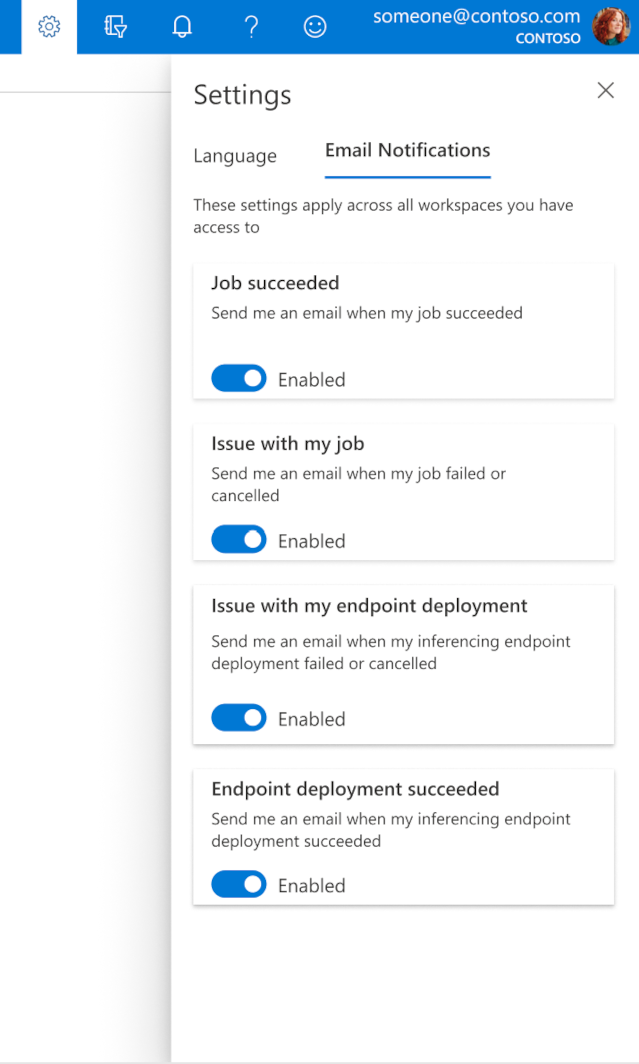
Para empezar a recibir correos electrónicos cuando se complete el trabajo, el punto de conexión en línea o el punto de conexión por lotes, o bien en caso de producirse un problema (errores, cancelación), siga los pasos siguientes:
- En el estudio de Azure ML, seleccione el icono de engranaje para ir a la configuración.
- Seleccione la pestaña Notificaciones por correo electrónico.
- Alterne para habilitar o deshabilitar las notificaciones por correo electrónico para un evento específico.
Descripción del estado del servicio
Durante la implementación del modelo, es posible que vea el cambio de estado del servicio mientras se implementa por completo.
En la tabla siguiente se describen los diferentes estados del servicio:
| Estado de WebService | Descripción | ¿Estado final? |
|---|---|---|
| En transición | El servicio está en proceso de implementación. | No |
| Unhealthy (Incorrecto) | El servicio se ha implementado pero actualmente no se puede acceder a él. | No |
| No programable | El servicio no se puede implementar en este momento debido a la falta de recursos. | No |
| Con error | No se pudo implementar el servicio debido a un error o a un bloqueo. | Sí |
| Healthy | El servicio está en buen estado y el punto de conexión está disponible. | Sí |
Sugerencia
Al realizar la implementación, las imágenes de Docker de los destinos de proceso se crean y se cargan desde Azure Container Registry (ACR). De manera predeterminada, Azure Machine Learning crea una instancia de ACR que usa el nivel de servicio Básico. Si se cambia la instancia de ACR del área de trabajo al nivel Estándar o Prémium, puede reducirse el tiempo que se tarda en compilar e implementar imágenes en los destinos de proceso. Para más información, consulte Niveles de servicio de Azure Container Registry.
Nota
Si va a implementar un modelo en Azure Kubernetes Service (AKS), le recomendamos que habilite Azure Monitor para ese clúster. Esto le ayudará a comprender el estado general y el uso de recursos del clúster. Puede que le resulten de utilidad los siguientes recursos:
- Comprobación de eventos de Resource Health que afectan al clúster de AKS (versión preliminar)
- Introducción a los diagnósticos de Azure Kubernetes Service (versión preliminar)
Si intenta implementar un modelo en un clúster con un estado incorrecto o sobrecargado, se espera que experimente problemas. Si necesita ayuda para solucionar problemas del clúster de AKS, póngase en contacto con el departamento de soporte técnico de AKS.
Eliminar recursos
SE APLICA A: Extensión de ML de la CLI de Azure v1
# Get the current model id
import os
stream = os.popen(
'az ml model list --model-name=bidaf_onnx --latest --query "[0].id" -o tsv'
)
MODEL_ID = stream.read()[0:-1]
MODEL_IDaz ml service delete -n myservice
az ml service delete -n myaciservice
az ml model delete --model-id=<MODEL_ID>
Para eliminar un servicio web implementado, use az ml service delete <name of webservice>.
Para eliminar un modelo registrado del área de trabajo, use az ml model delete <model id>.
Más información sobre la eliminación de un servicio web y la eliminación de un modelo.
Pasos siguientes
- Solución de problemas de implementaciones con errores
- Actualización de servicio web
- Implementación con un solo clic de las ejecuciones de aprendizaje automático automatizado en el Estudio de Azure Machine Learning
- Uso de TLS para proteger un servicio web con Azure Machine Learning
- Supervisión de los modelos de Azure Machine Learning con Application Insights
- Creación de flujos de trabajo de aprendizaje automático controlados por eventos (versión preliminar)