Configure AutoML para entrenar un modelo de previsión de serie temporal con Python (SDKv1)
SE APLICA A:  Azure ML del SDK de Python v1
Azure ML del SDK de Python v1
En este artículo, obtendrá información sobre cómo configurar el entrenamiento de AutoML para modelos de previsión de series temporales con el aprendizaje automático automatizado de Azure Machine Learning en el SDK de Azure Machine Learning para Python.
Para ello, haremos lo siguiente:
- Preparar los datos para el modelado de series temporales.
- Configurar parámetros específicos de las serie temporales en un objeto
AutoMLConfig. - Ejecutar predicciones con los datos de serie temporal.
Para una experiencia con poco código, consulte Tutorial: Previsión de la demanda con aprendizaje automático automatizado para ver un ejemplo de previsión de series temporales con AutoML en Estudio de Azure Machine Learning.
A diferencia de los métodos de series temporales clásicos, en el aprendizaje automático automatizado, los valores de series temporales anteriores se "dinamizan" para convertirse en dimensiones adicionales del regresor, junto con otros indicadores. Este enfoque incorpora varias variables contextuales y su relación entre sí durante el entrenamiento. Dado que varios factores pueden influir en una previsión, este método se adapta bien a los escenarios de previsión reales. Por ejemplo, al prever ventas, las interacciones de las tendencias históricas, la tasa de cambio y el precio son motores conjuntos del resultado de ventas.
Requisitos previos
Para realizar este artículo, necesitará lo siguiente
Un área de trabajo de Azure Machine Learning. Para crear el área de trabajo, consulte Creación de recursos del área de trabajo.
En este artículo se presupone una familiarización con la configuración de un experimento de aprendizaje de automático automatizado. Siga el procedimiento para ver los principales modelos de diseño del experimento de aprendizaje automático automatizado.
Importante
Los comandos de Python de este artículo requieren la versión más reciente del paquete
azureml-train-automl.- Instale el paquete
azureml-train-automlmás reciente en el entorno local. - Para obtener información sobre la última versión del paquete
azureml-train-automl, consulta las notas de la versión.
- Instale el paquete
Datos de entrenamiento y validación
La diferencia más importante entre el tipo de tarea de regresión de previsión y el de regresión en ML automatizado es que se incluye una característica en los datos de entrenamiento que representa una serie temporal válida. Una serie de tiempo normal tiene una frecuencia coherente y bien definida, y un valor en cada punto de un intervalo de tiempo continuo.
Importante
Al entrenar un modelo para la previsión de valores futuros, asegúrese de que todas las características del entrenamiento se pueden usar al ejecutar predicciones para su horizonte previsto. Por ejemplo, al crear una previsión de demanda, incluir una característica para el precio de cotización actual podría aumentar la precisión del entrenamiento de manera exponencial. Sin embargo, si quiere una previsión con un horizonte lejano, no es posible predecir con precisión valores de cotización futuros correspondientes a momentos futuros en la serie temporal y la precisión del modelo podría verse afectada.
Puede especificar datos de entrenamiento y datos de validación independientes directamente en el objeto AutoMLConfig. Obtenga más información sobre AutoMLConfig.
En el caso de la previsión de serie temporal, para la validación solo se usa la validación cruzada de origen variable (ROCV) de manera predeterminada. ROCV divide la serie en datos de entrenamiento y validación con un punto temporal de origen. Al deslizar el origen en el tiempo, se generan subconjuntos de validación cruzada. Esta estrategia conserva la integridad de los datos de la serie temporal y elimina el riesgo de perder datos.
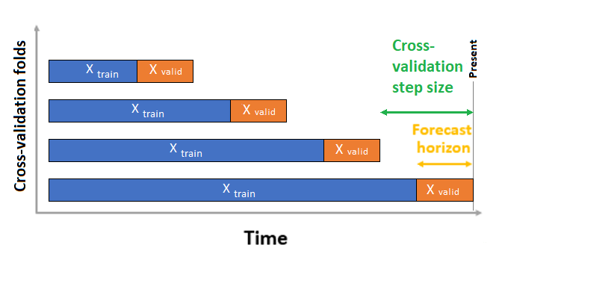
Pase los datos de entrenamiento y validación como un conjunto de datos al parámetro training_data. Establezca el número de iteraciones de validación cruzada con el parámetro n_cross_validations y establezca el número de períodos entre dos iteraciones consecutivas de validación cruzada con cv_step_size. También puede dejar vacío uno o ambos parámetros y AutoML los establecerá automáticamente.
SE APLICA A: Azure ML del SDK de Python v1
automl_config = AutoMLConfig(task='forecasting',
training_data= training_data,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
...
**time_series_settings)
También puede traer sus propios datos de validación. Obtenga más información en Configuración de las divisiones de datos y la validación cruzada en aprendizaje automático automatizado.
Obtenga más información sobre cómo AutoML aplica la validación cruzada para evitar un sobreajuste de los modelos.
Configuración del experimento
El objeto AutoMLConfig define la configuración y los datos necesarios para una tarea de aprendizaje automático automatizado. La configuración de un modelo de previsión es similar a la configuración de un modelo de regresión estándar, pero existen determinados modelos, opciones de configuración y pasos de caracterización que son específicos para los datos de series temporales.
Modelos admitidos
El aprendizaje automático automatizado prueba automáticamente diferentes algoritmos y modelos como parte de la creación del modelo y del proceso de optimización. Como usuario, no hay ninguna necesidad de especificar el algoritmo. En el caso de los experimentos de previsión, los modelos nativos de serie temporal y de aprendizaje profundo forman parte del sistema de recomendaciones.
Sugerencia
Los modelos de regresión tradicionales también se prueban como parte del sistema de recomendaciones para los experimentos de previsión. Consulte una lista completa de los modelos admitidos en la documentación de referencia del SDK.
Parámetros de configuración
Al igual que en un problema de regresión, debe definir los parámetros de entrenamiento estándar como tipo de tarea, número de iteraciones, datos de entrenamiento y número de validaciones cruzadas. Las tareas de previsión requieren los parámetros time_column_name y forecast_horizon para configurar el experimento. Si los datos incluyen varias series temporales, como los datos de ventas de varias tiendas o los datos de energía en distintos estados, el aprendizaje automático automatizado lo detecta automáticamente y establece el parámetro time_series_id_column_names (versión preliminar) automáticamente. También puede incluir parámetros adicionales para configurar mejor la ejecución. Consulte la sección Configuraciones opcionales para obtener más detalles sobre lo que se puede incluir.
Importante
La identificación automática de series temporales se encuentra actualmente en versión preliminar pública. Esta versión preliminar se proporciona sin un contrato de nivel de servicio. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
| Nombre de parámetro | Descripción |
|---|---|
time_column_name |
Se utiliza para especificar la columna de fecha y hora en los datos de entrada utilizada que se usa para compilar la serie temporal y se deduce su frecuencia. |
forecast_horizon |
Define el número de períodos futuros que le gustaría pronosticar. El horizonte está en las unidades de la frecuencia de la serie temporal. Las unidades se basan en el intervalo de tiempo de los datos de entrenamiento (por ejemplo, semanales, mensuales) que debe predecir el pronosticador. |
El código siguiente:
- Usa la clase
ForecastingParameterspara definir los parámetros de previsión que se van a emplear en el entrenamiento del experimento. - Establece
time_column_nameen el campoday_datetimeen el conjunto de datos. - Establece el
forecast_horizonen 50 para predecir el conjunto de pruebas completo.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
freq='W')
Estos valores forecasting_parameters se pasan en el objeto de AutoMLConfig estándar junto con el tipo de tarea forecasting, la métrica principal, los criterios de salida y los datos de entrenamiento.
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
import logging
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=15,
enable_early_stopping=True,
training_data=train_data,
label_column_name=label,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
enable_ensembling=False,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
La cantidad de datos necesarios para entrenar correctamente un modelo de previsión con aprendizaje automático automatizado se ve influida por los valores de forecast_horizon, n_cross_validations y target_lags o target_rolling_window_size especificados al configurar AutoMLConfig.
La fórmula siguiente calcula la cantidad de datos históricos que se necesitarían para construir características de serie temporal.
Datos históricos mínimos necesarios: (2x forecast_horizon) + #n_cross_validations + max(max(target_lags), target_rolling_window_size)
Se genera un Error exception para cualquier serie del conjunto de datos que no reúna la cantidad necesaria de datos históricos para la configuración pertinente especificada.
Pasos de caracterización
En todos los experimentos de aprendizaje automático automatizado se aplican técnicas de escalado automático y normalización a los datos de forma predeterminada. Estas técnicas son tipos de caracterización que ayudan a ciertos algoritmos que son sensibles a las características a diferentes escalas. Más información sobre los pasos de caracterización predeterminados en caracterización en AutoML
Sin embargo, los siguientes pasos solo se realizan para los tipos de tarea forecasting:
- Detectar la frecuencia de muestreo de la serie temporal (por ejemplo, cada hora, cada día, cada semana, etc.) y crear nuevos registros para los momentos ausentes para que la serie sea continua.
- Imputar los valores que faltan en las columnas de destino (copia de los valores nulos hacia adelante) y de característica (con la mediana de los valores de la columna).
- Crear características basadas en los identificadores de serie temporal para habilitar los efectos fijos en las diferentes series.
- Creación de características basadas en el tiempo para ayudar a aprender los patrones estacionales
- Codificar las variables categóricas en cantidades numéricas.
- Detecte las series temporales no estacionarias y diferenciarlas automáticamente para mitigar el impacto de las raíces unitarias.
Para ver la lista completa de las posibles características diseñadas generadas a partir de datos de la serie temporal, consulte Clase TimeIndexFeaturizer.
Nota:
Los pasos de la caracterización del aprendizaje automático automatizado (normalización de características, control de los datos que faltan, conversión de valores de texto a numéricos, etc.) se convierten en parte del modelo subyacente. Cuando se usa el modelo para realizar predicciones, se aplican automáticamente a los datos de entrada los mismos pasos de caracterización que se aplican durante el entrenamiento.
Personalización de la caracterización
También tiene la opción de personalizar los valores de la caracterización para asegurarse de que los datos y las características que se usan para entrenar el modelo de Machine Learning generan predicciones pertinentes.
Las personalizaciones admitidas para tareas forecasting incluyen:
| Personalización | Definición |
|---|---|
| Actualización del propósito de la columna | Invalida el tipo de característica detectado automáticamente para la columna especificada. |
| Actualización de parámetros del transformador | Actualizar los parámetros para el transformador especificado. Actualmente admite Imputer (fill_value y median). |
| Quitar columnas | Especifica las columnas que se van a eliminar de la caracterización. |
Para personalizar las caracterizaciones con el SDK, especifique "featurization": FeaturizationConfig en el objeto AutoMLConfig. Más información sobre caracterizaciones personalizadas.
Nota
La funcionalidad Quitar columnas está en desuso a partir de la versión 1.19 del SDK. Quite columnas del conjunto de datos como parte de la limpieza de datos antes de consumirlos en el experimento de aprendizaje automático automatizado.
featurization_config = FeaturizationConfig()
# `logQuantity` is a leaky feature, so we remove it.
featurization_config.drop_columns = ['logQuantitity']
# Force the CPWVOL5 feature to be of numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeroes.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill mising values in the `INCOME` column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
Si usa Azure Machine Learning Studio para el experimento, consulte Personalización de la caracterización en Studio.
Configuraciones opcionales
Hay más configuraciones opcionales disponibles para las tareas de previsión, como la habilitación del aprendizaje profundo y la especificación de una agregación de ventana con desplazamiento de objetivo. Hay disponible una lista completa de parámetros adicionales en la documentación de referencia del SDK de ForecastingParameters.
Frecuencia y agregación de datos de destino
Use el parámetro de frecuencia freq para ayudar a evitar errores causados por datos irregulares. Los datos irregulares incluyen datos que no siguen una cadencia establecida, como datos diarios o por hora.
En cuanto a los datos que son muy irregulares o en las distintas necesidades empresariales, los usuarios pueden establecer opcionalmente la frecuencia de previsión que quieren (freq), y especificar el valor target_aggregation_function para agregar la columna de destino de la serie temporal. Usar estos dos valores en el objeto AutoMLConfig puede ahorrarle tiempo a la hora de preparar los datos.
Las operaciones de agregación admitidas para los valores de columna de destino incluyen:
| Función | Descripción |
|---|---|
sum |
La suma de los valores de destino |
mean |
La media o promedio de los valores de destino |
min |
El valor mínimo de un destino |
max |
El valor máximo de un destino |
Habilitar el aprendizaje profundo.
Nota
La compatibilidad con DNN para la previsión en el aprendizaje automático automatizado se encuentra en versión preliminar y no es compatible con las ejecuciones locales ni las ejecuciones iniciadas en Databricks.
También puede aplicar el aprendizaje profundo con redes neuronal profundas, o DNN, para mejorar las puntuaciones del modelo. El aprendizaje profundo de ML automatizado permite pronosticar datos de series temporales de variable única y de varias variables.
Los modelos de aprendizaje profundo tienen tres capacidades intrínsecas:
- Pueden aprender de las asignaciones arbitrarias de las entradas a las salidas.
- Admiten varias entradas y salidas.
- Pueden extraer automáticamente patrones en datos de entrada que abarquen secuencias largas.
Para habilitar el aprendizaje profundo, establezca el enable_dnn=True en el objeto AutoMLConfig.
automl_config = AutoMLConfig(task='forecasting',
enable_dnn=True,
...
forecasting_parameters=forecasting_parameters)
Advertencia
Al habilitar DNN para los experimentos creados con el SDK, las mejores explicaciones del modelo se deshabilitan.
Para habilitar DNN para un experimento de AutoML creado en Azure Machine Learning Studio, consulte los procedimientos en la interfaz de usuario de Studio para la configuración del tipo de tarea.
Agregación de ventanas con desplazamiento de objetivo
A menudo, la mejor información que puede tener una previsión es el valor reciente del objetivo. Las agregaciones de ventanas con desplazamiento permiten la incorporación de una agregación gradual de valores de datos como características. La generación y el uso de estas características como datos contextuales extra contribuye a la precisión del modelo de entrenamiento.
Por ejemplo, suponga que desea predecir la demanda de energía. Puede que desee agregar una característica de ventana con desplazamiento de tres días para tener en cuenta los cambios térmicos de los espacios calentados. En este ejemplo, cree esta ventana estableciendo target_rolling_window_size= 3 en el constructor AutoMLConfig.
En la tabla se muestra el diseño de características que se produce cuando se aplica la agregación de ventanas. Las columnas para los valores mínimo, máximo y suma se generan en una ventana deslizante de tres según la configuración definida. Cada fila tiene una nueva característica calculada, en el caso de la marca de tiempo del 8 de septiembre de 2017 4:00 a. m., los valores máximo, mínimo y suma se calculan con los valores de la demanda del 8 de septiembre de 2017, de la 1:00 a. m. a las 3:00 a. m. Esta ventana tiene tres turnos juntos para rellenar los datos de las filas restantes.

Consulte un ejemplo de código de Python que aplica las características para agregar ventanas con desplazamiento de objetivo.
Control de series breves
El ML automatizado considera una serie temporal como serie breve si no hay suficientes puntos de datos para llevar a cabo las fases de entrenamiento y validación del desarrollo del modelo. El número de puntos de datos varía para cada experimento y depende de max_horizon, el número de divisiones de validación cruzada y la longitud de la retrospectiva del modelo, que es el máximo de historial necesario para construir las características de la serie temporal.
El aprendizaje automático automatizado ofrece un control de series breves de manera predeterminada con el parámetro short_series_handling_configuration en el objeto ForecastingParameters.
Para habilitar el control de series breves, también se debe definir el parámetro freq. Para definir una frecuencia por hora, estableceremos freq='H'. Para ver las opciones de cadena de frecuencia, visite la sección Objetos DataOffset de la página de serie temporal de Pandas. Para cambiar el comportamiento predeterminado, short_series_handling_configuration = 'auto', actualice el parámetro short_series_handling_configuration en el objeto ForecastingParameter.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecast_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
short_series_handling_configuration='auto',
freq = 'H',
target_lags='auto')
En la siguiente tabla se resumen las opciones disponibles para short_series_handling_config.
| Configuración | Descripción |
|---|---|
auto |
Valor predeterminado para el control de series cortas. - Si todas las series son cortas, se rellenan los datos. - Si no todas las series son cortas, se anulan las series cortas. |
pad |
Si short_series_handling_config = pad, el aprendizaje automático automatizado agrega valores aleatorios a cada serie breve que se encuentra. A continuación se enumeran los tipos de columna y con qué se rellenan: - Columnas de objetos con NaN - Columnas numéricas con 0 - Columnas booleanas o lógicas con False - La columna de destino se rellena con valores aleatorios con una media de cero y una desviación estándar de 1. |
drop |
Si short_series_handling_config = drop, el aprendizaje automático automatizado quita las series breves, y no se usarán para el entrenamiento ni la predicción. Las predicciones para estas series devolverán NaN. |
None |
No se rellena ni anula ninguna serie |
Advertencia
El relleno puede afectar a la precisión del modelo resultante, ya que estamos introduciendo datos artificiales tan solo para superar el entrenamiento sin errores. Si muchas de las series son breves, puede que también vea algún impacto en los resultados de la capacidad de explicación.
Detección y control de series temporales no estacionarias
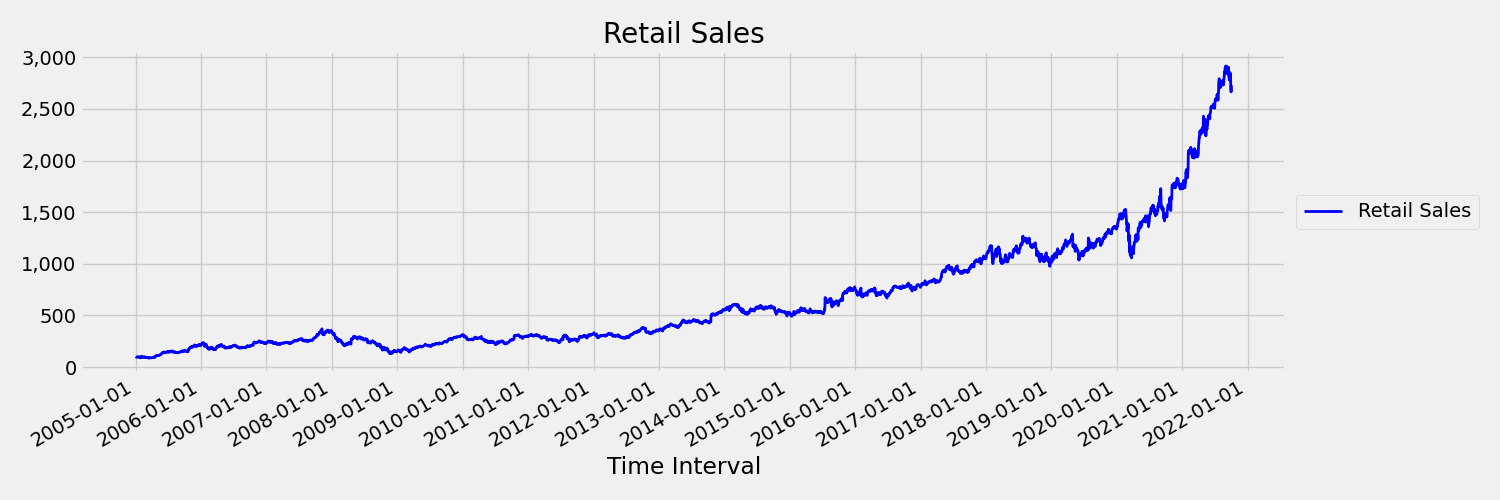
Una serie temporal cuyos momentos (media y varianza) cambian con el tiempo se denomina no fija. Por ejemplo, las series temporales que presentan tendencias estocásticas son no fijas por naturaleza. Para visualizar esto, la imagen siguiente traza una serie que generalmente marca una tendencia hacia arriba. Ahora, calcule y compare los valores medios (promedio) de la primera y la segunda mitad de la serie. ¿Son el mismo equipo? Aquí, la media de la serie en la primera mitad del trazado es menor que en la segunda mitad. El hecho de que la media de la serie dependa del intervalo de tiempo que se está examinando es un ejemplo de los momentos que varían el tiempo. Aquí, la media de una serie es el primer momento.
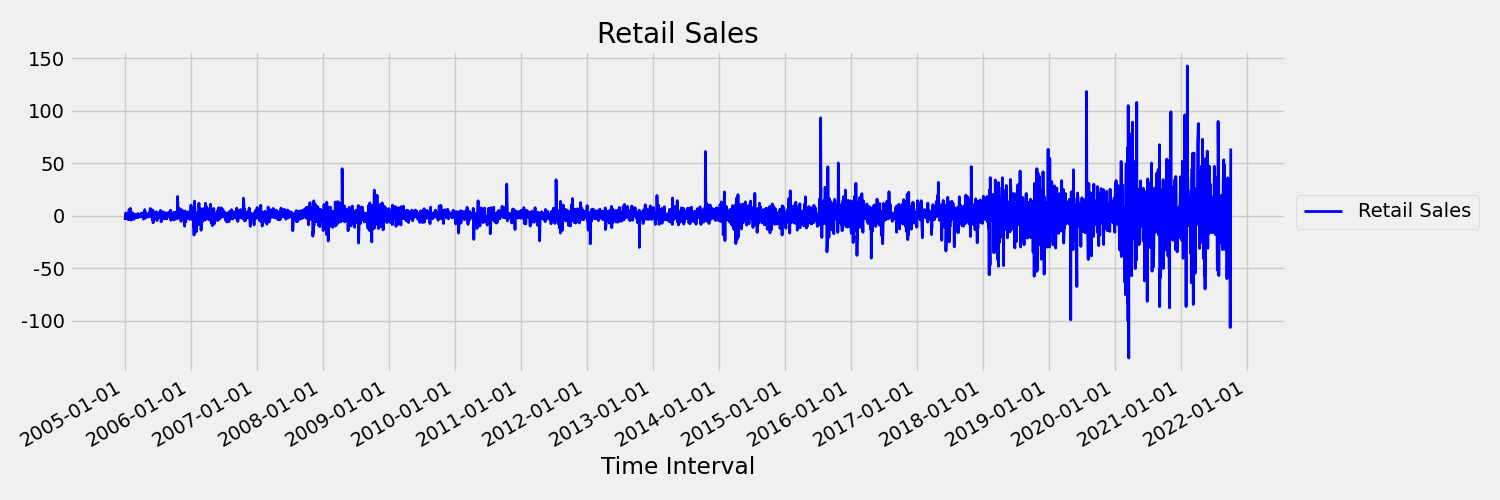
A continuación, examinemos la imagen siguiente, que traza la serie original en las primeras diferencias $x_t = y_t - y_{t-1}$, donde $x_t$ es el cambio en las ventas minoristas y $y_t$ y $y_{t-1}$ representan la serie original y su primer retraso, respectivamente. La media de la serie es casi constante, independientemente del período de tiempo que esté mirando. Este es un ejemplo de una serie temporal fija de primer orden. La razón por la que hemos agregado el primer término de orden es porque el primer momento (media) no cambia con el intervalo de tiempo; no se puede decir lo mismo sobre la varianza, que es un segundo momento.
Los modelos de Machine Learning de AutoML no pueden tratar de forma inherente tendencias estocásticas u otros problemas conocidos asociados a series temporales no estáticas. Como resultado, la precisión de la previsión que se haga fuera de la muestra será "deficiente" si estas tendencias están presentes.
AutoML analiza automáticamente el conjunto de datos de serie temporales para comprobar si es estacionario o no. Cuando se detectan series temporales no estáticas, AutoML aplica automáticamente una transformación de diferenciación para mitigar el efecto de las series temporales no estáticas.
Ejecución del experimento
Cuando tenga el objeto AutoMLConfig listo, puede enviar el experimento. Una vez finalizado el modelo, recupere la iteración con la mejor ejecución.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-forecasting")
local_run = experiment.submit(automl_config, show_output=True)
best_run, fitted_model = local_run.get_output()
Previsión con el mejor modelo
Use la mejor iteración del modelo para pronosticar los valores de los datos que no se usaron para entrenar el modelo.
Evaluación de la precisión del modelo con una previsión gradual
Antes de poner un modelo en producción, debe evaluar su precisión en un conjunto de pruebas que se haya extraído de los datos de entrenamiento. El procedimiento más adecuado es la llamada evaluación gradual, que hace avanzar al pronosticador entrenado en el tiempo sobre el conjunto de pruebas, promediando las métricas de error sobre varias ventanas de predicción para obtener estimaciones estadísticamente sólidas para algún conjunto de métricas elegidas. Lo ideal es que el conjunto de pruebas para la evaluación sea largo en relación con el horizonte de previsión del modelo. De lo contrario, las estimaciones del error de previsión pueden ser estadísticamente ruidosas y, por tanto, menos confiables.
Por ejemplo, supongamos que entrena un modelo en ventas diarias para predecir la demanda hasta dos semanas (14 días) en el futuro. Si se dispone de suficientes datos históricos, se pueden reservar los últimos meses o incluso un año de datos para el conjunto de pruebas. La evaluación gradual comienza generando una previsión a 14 días vista para las dos primeras semanas del conjunto de pruebas. A continuación, el pronosticador se adelanta un cierto número de días en el conjunto de pruebas y se genera otra previsión a 14 días vista a partir de la nueva posición. El proceso continúa hasta que llegue al final del conjunto de pruebas.
Para realizar una evaluación gradual, llame al método rolling_forecast de fitted_model y, a continuación, calcule las métricas deseadas en el resultado. Por ejemplo, supongamos que tiene las características del conjunto de pruebas en un DataFrame de pandas llamado test_features_df y los valores reales del conjunto de pruebas del objetivo en una matriz de numpy llamada test_target. En el ejemplo de código siguiente se muestra una evaluación gradual mediante el error cuadrático medio:
from sklearn.metrics import mean_squared_error
rolling_forecast_df = fitted_model.rolling_forecast(
test_features_df, test_target, step=1)
mse = mean_squared_error(
rolling_forecast_df[fitted_model.actual_column_name], rolling_forecast_df[fitted_model.forecast_column_name])
En este ejemplo, el tamaño del paso para la previsión gradual se establece en uno, lo que significa que el pronosticador se adelanta un periodo, o un día en nuestro ejemplo de predicción de la demanda, en cada iteración. El número total de previsiones devueltas por rolling_forecast depende, pues, de la longitud del conjunto de pruebas y de este tamaño de paso. Para más detalles y ejemplos, consulte la documentación de rolling_forecast() y el cuaderno Previsión a partir de datos de entrenamiento.
Predicción en el futuro
La función forecast_quantiles() permite especificaciones de cuándo se deben iniciar las predicciones, a diferencia del método predict(), que se usa normalmente para las tareas de clasificación y regresión. El método forecast_quantiles() genera de manera predeterminada una previsión de punto o una previsión de media o mediana que no tiene un cono de incertidumbre en torno a ella. Obtenga más información en el cuaderno Previsión fuera del entrenamiento de datos.
En el siguiente ejemplo, primero se reemplazan todos los valores de y_pred con NaN. En este caso, el origen de la previsión está al final de los datos de entrenamiento. Sin embargo, si reemplazó solo la segunda mitad de y_pred con NaN, la función dejó intactos los valores numéricos de la primera, pero realizó la previsión de los valores de NaN de la segunda mitad. La función devuelve tanto los valores previstos como las características alineadas.
También puede usar el parámetro forecast_destination de la función forecast_quantiles() para la previsión de valores hasta una fecha especificada.
label_query = test_labels.copy().astype(np.float)
label_query.fill(np.nan)
label_fcst, data_trans = fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
A menudo, los clientes quieren comprender las predicciones en un cuantil específico de la distribución. Por ejemplo, cuando se usa la previsión para controlar el inventario, como artículos de alimentación o máquinas virtuales para un servicio en la nube. En tales casos, el punto de control suele ser algo parecido a "queremos que el elemento tenga existencias y no esté agotado el 99 % del tiempo". A continuación se muestra cómo especificar qué cuantiles desea ver para las predicciones, como el percentil 50 o 95. Si no especifica un cuantil, como en el ejemplo de código mencionado anteriormente, solo se generan las predicciones del percentil 50.
# specify which quantiles you would like
fitted_model.quantiles = [0.05,0.5, 0.9]
fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Puede calcular métricas del modelo como la raíz del error cuadrático medio (RMSE) o el error porcentual absoluto medio (MAPE) como ayuda para calcular el rendimiento de los modelos. Consulte la sección Evaluación del cuaderno Demanda de uso compartido de bicicletas para obtener un ejemplo.
Una vez que se ha determinado la precisión del modelo global, el siguiente paso más realista es usar este para prever valores futuros desconocidos.
Proporcione un conjunto de datos en el mismo formato que el de prueba (test_dataset) pero con fechas y horas futuras y el conjunto de predicción resultante son los valores previstos para cada paso de la serie temporal. Supongamos que los últimos registros de la serie temporal en el conjunto de datos fueron del 31/12/2018. Para prever la demanda para el día siguiente (o para los períodos que necesite prever, <= forecast_horizon), cree un único registro de serie temporal para cada almacén para el 01/01/2019.
day_datetime,store,week_of_year
01/01/2019,A,1
01/01/2019,A,1
Repita los pasos necesarios para cargar estos datos futuros a una trama de datos y ejecute best_run.forecast_quantiles(test_dataset) para predecir los valores futuros.
Nota
Las predicciones en el ejemplo no se admiten para la previsión con aprendizaje automático automatizado cuando se habilitan target_lags o target_rolling_window_size.
Previsión a escala
Hay escenarios en los que un único modelo de aprendizaje automático no es suficiente y se necesitan varios modelos de aprendizaje automático. Por ejemplo, predecir las ventas de cada tienda de una marca por separado o adaptar una experiencia a usuarios individuales. La creación de un modelo para cada instancia puede dar lugar a mejores resultados en muchos problemas de aprendizaje automático.
La agrupación es un concepto de previsión de series temporales que permite combinar estas para entrenar un modelo individual por grupo. Este enfoque puede ser especialmente útil si tiene series temporales que requieren suavizado o relleno o entidades en el grupo que pueden beneficiarse del historial o las tendencias de otras entidades. Muchos modelos y previsiones de series temporales jerárquicas son soluciones basadas en el aprendizaje automático automatizado para estos escenarios de previsión a gran escala.
Many Models
La solución de muchos modelos de Azure Machine Learning con aprendizaje automático automatizado permite a los usuarios entrenar y administrar millones de modelos en paralelo. El acelerador de soluciones de muchos modelos usa canalizaciones de Azure Machine Learning para entrenar el modelo. En concreto, se utiliza un objeto Pipeline y ParalleRunStep que requieren unos parámetros de configuración específicos establecidos a través de ParallelRunConfig.
En el diagrama siguiente se muestra el flujo de trabajo de la solución de muchos modelos.

En el código siguiente se muestran los parámetros clave que los usuarios necesitan para configurar la ejecución de muchos modelos. Consulte el cuaderno Muchos modelos: ML automatizado para ver un ejemplo de previsión de muchos modelos.
from azureml.train.automl.runtime._many_models.many_models_parameters import ManyModelsTrainParameters
partition_column_names = ['Store', 'Brand']
automl_settings = {"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10, #This needs to be changed based on the dataset. Explore how long training is taking before setting this value
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,}
mm_paramters = ManyModelsTrainParameters(automl_settings=automl_settings, partition_column_names=partition_column_names)
Previsión de series temporales jerárquicas
En la mayoría de las aplicaciones, los clientes tienen la necesidad de comprender sus previsiones en un nivel macro y micro de la empresa. Las previsiones pueden predecir las ventas de productos en diferentes ubicaciones geográficas o comprender la demanda de personal esperada para diferentes organizaciones de una empresa. La capacidad de entrenar un modelo de aprendizaje automático para prever de forma inteligente los datos de la jerarquía es esencial.
Una serie temporal jerárquica es una estructura en la que cada una de las series únicas se organiza en una jerarquía en función de dimensiones como, por ejemplo, la ubicación geográfica o el tipo de producto. En el ejemplo siguiente se muestran datos con atributos únicos que forman una jerarquía. Nuestra jerarquía se define por: el tipo de producto, como auriculares o tabletas; la categoría de producto, que divide los tipos de producto en accesorios y dispositivos; y la región en la que se venden los productos.

Para visualizarlo aún más, los niveles hoja de la jerarquía contienen todas las series temporales con combinaciones únicas de valores de atributo. Cada nivel superior de la jerarquía tiene en cuenta una dimensión menos para definir la serie temporal y agrega cada conjunto de nodos secundarios del nivel inferior a un nodo primario.

La solución de serie temporal jerárquica se basa en la solución de muchos modelos y comparte una configuración similar.
En el código siguiente se muestran los parámetros clave para configurar las ejecuciones de la previsión de series temporales jerárquicas. Consulte el cuaderno Serie temporal jerárquica: ML automatizado para obtener un ejemplo completo.
from azureml.train.automl.runtime._hts.hts_parameters import HTSTrainParameters
model_explainability = True
engineered_explanations = False # Define your hierarchy. Adjust the settings below based on your dataset.
hierarchy = ["state", "store_id", "product_category", "SKU"]
training_level = "SKU"# Set your forecast parameters. Adjust the settings below based on your dataset.
time_column_name = "date"
label_column_name = "quantity"
forecast_horizon = 7
automl_settings = {"task" : "forecasting",
"primary_metric" : "normalized_root_mean_squared_error",
"label_column_name": label_column_name,
"time_column_name": time_column_name,
"forecast_horizon": forecast_horizon,
"hierarchy_column_names": hierarchy,
"hierarchy_training_level": training_level,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,
"model_explainability": model_explainability,# The following settings are specific to this sample and should be adjusted according to your own needs.
"iteration_timeout_minutes" : 10,
"iterations" : 10,
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
}
hts_parameters = HTSTrainParameters(
automl_settings=automl_settings,
hierarchy_column_names=hierarchy,
training_level=training_level,
enable_engineered_explanations=engineered_explanations
)
Cuadernos de ejemplo
Consulte los cuadernos de ejemplo de previsión para ejemplos de código detallados de la configuración de predicciones avanzada, que incluye:
- detección y caracterización de festividades
- validación cruzada de origen variable
- retrasos configurables
- características de agregado en períodos acumulados
Pasos siguientes
- Obtenga más información sobre la Implementación de un modelo de AutoML en un punto de conexión en línea.
- Obtenga más información sobre la Capacidad de interpretación: explicaciones de los modelos en el aprendizaje automático automatizado (versión preliminar).
- Obtenga información sobre cómo AutoML crea modelos de previsión.